「LLM天花板」如何利用神奇咒语让语言模型超越人类
原创

学习李宏毅老师课程记录,文章为个人笔记,以及相关论文阅读的扩展总结
语言模型已经从工具进化到工具人,怎么使用这个工具人?
1、Prompt工程:
提供清楚的指令,额外的信息,包括背景context等,让模型更清楚任务。
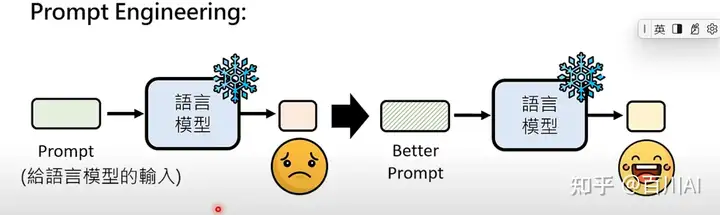
在不训练模型的情况下,强化语言模型的方法:
1.1 方法一:使用“神奇咒语”来强化语言模型的能力
a) “神奇咒语1”:Chain of Thought 叫模型思考。
即在询问模型答案之前,让模型认真思考等prompt,输出结果真的就要好。 这里有一个问题点:不同的模型神奇咒语是不一样的,怎么针对一个新的模型搜索出神奇咒语呢,如果有少量样本,怎么在few-shot上效果更好呢?见还在手写Prompt,自动Prompt搜索超越人类水平

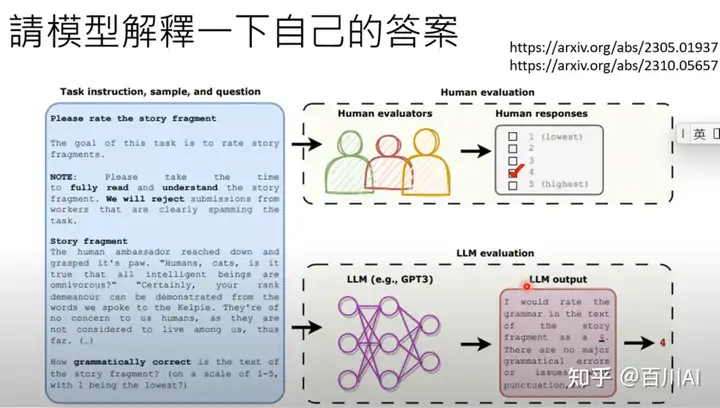
b) “神奇咒语2”:请模型解释一下自己的答案。
Can Large Language Models Be an Alternative to Human Evaluation?
让LLM解释答案过程中,以ChatGPT为例,解释的时候他甚至会提及具体的句子和标准,来说明打分的依据,这也是为什么解释能够提升准确。
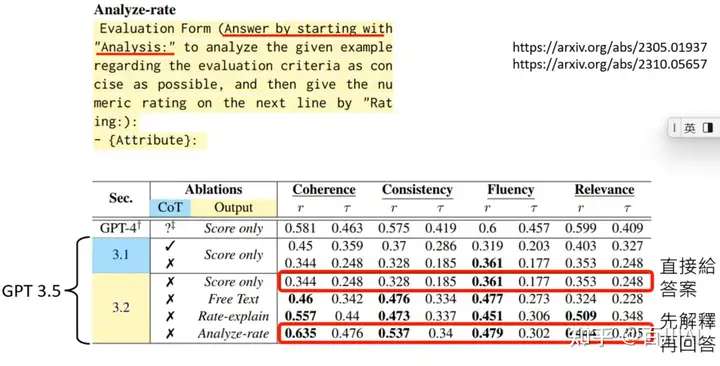
上图中的实验结果,解释之后的性能更好。
c) “神奇咒语3”:emotional prompts,对模型情绪勒索(emotional stimuli)
做法很有意思,如图就是在prompt后加入“这真的对我很重要”。猜测可能真实语料中这种情况下,回答者的答案也往往会深思熟虑后回答,正确率更高,但是这对语言模型来说是一个偏置,他是机器,如果让他在任何情况下都尽力回答,也是一个有意思的方向。
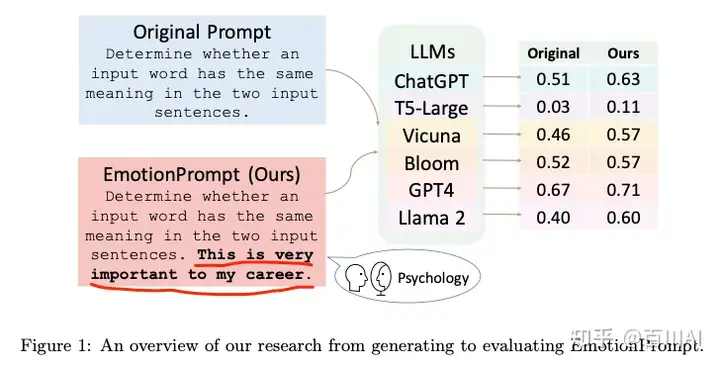
文章来源:Large Language Models Understand and Can Be Enhanced by Emotional Stimuli
d) 其他的一些咒语
这篇文章详细说明的LLM的使用方法:Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4。讲真,有点火鸡科学家,但是真的有用,不过风险是有可能对你的模型不适用。下面是一些使用Principle:
1)不用对模型太礼貌。 2)明确告诉模型做什么,不用告诉模型不做什么。 3)如果做得好的话给你小费:居然是有用的。。。 4)如果你做的不好会给你惩罚:居然也有用。。。 5)避免偏见和刻板印象,也是有用的。
e) 用AI来找“神奇咒语”;
1)强化学习:通过一个语言模型来生成prompt,然后输入到LLM生结果,在通过自动评估反馈奖励。
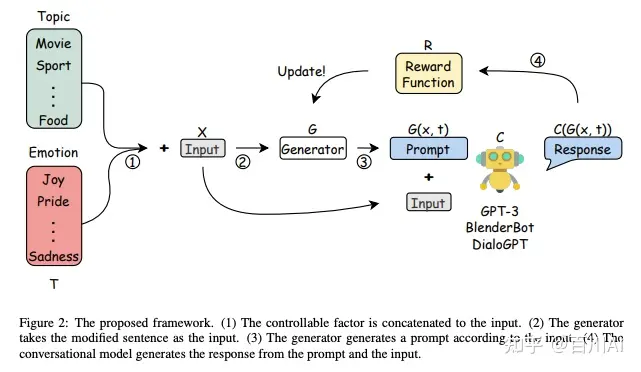
Learning to Generate Prompts for Dialogue Generation through Reinforcement Learning
2)语言模型蒙特卡洛搜索:通过蒙特卡洛搜索+语言模型来寻找最优的prompt,见:
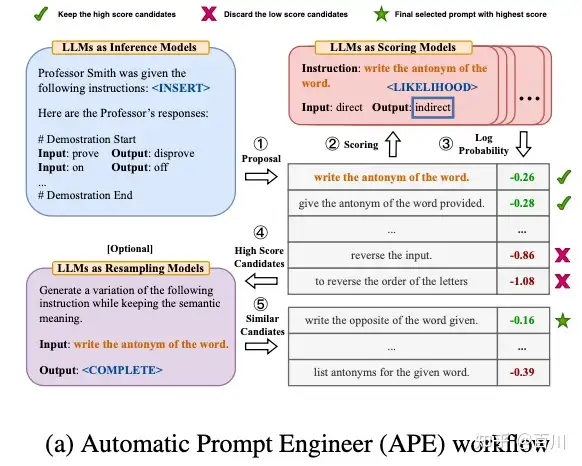
详细见还在手写Prompt,自动Prompt搜索超越人类水平
“神奇咒语”并不一定对所有模型都有用,对同一模型的不同版本也可能没用,比如上面文章的咒语,后来文章LARGE LANGUAGE MODELS AS OPTIMIZERS发现在PaLM上效果不好,搜索出新的咒语:
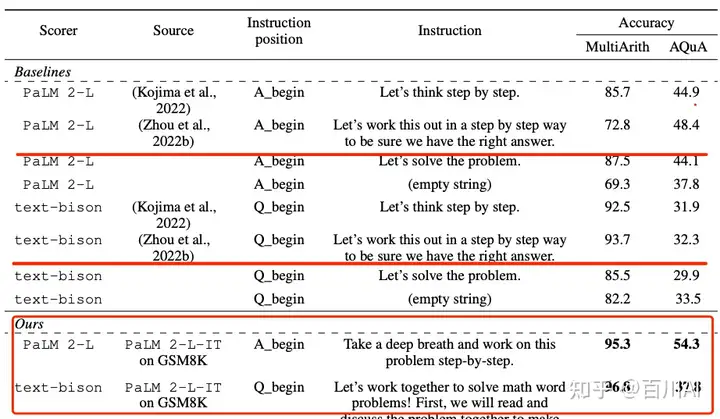
1.2 提供更详细的输入信息
a) 把前提讲清楚: 背景信息等。
b) 提供生成式AI原本不清楚的资讯: 可以是文本、文档、甚至一些文件。
c) 提供范例 in-context learning
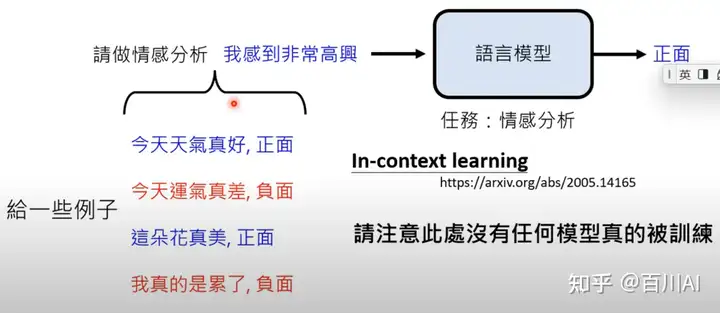
这篇文章分析了范例学习:Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?,给范例提供错误的标签,结果模型输出结果并未改变。结论是模型并没有学习到范例,改变范例标签不会影响语言模型输出,范例知识促进模型理解任务。
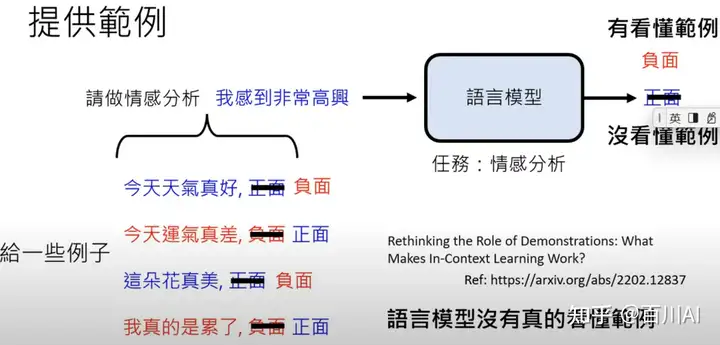
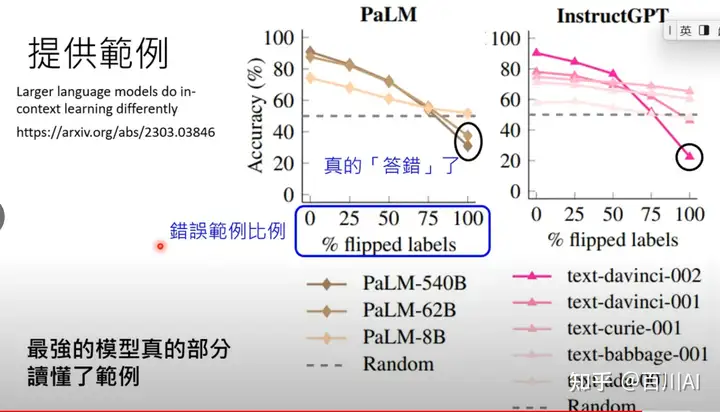
而随着语言模型发展,后面文章Larger language models do in-context learning differently发现,模型真的学到了范例标签,不仅理解了任务,给错误的标签,预测标签也是‘错误’(但其实是正确)
但是老师对ChatGPT进行了测试,然后测试确实也没有理解范例标签。这里也说明,prompt中的解释要和常识相似,效果才会更好。

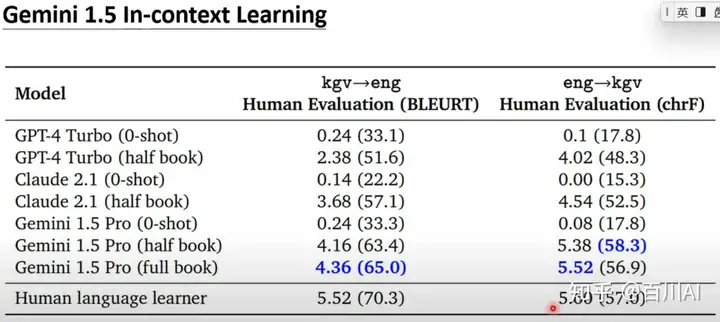
Gemini 1.5 in-context learning的语言翻译案例:将教科书和词典作为context+翻译语句输入到llm时候,能够明显提高翻译准确率,甚至和人类相差不远。
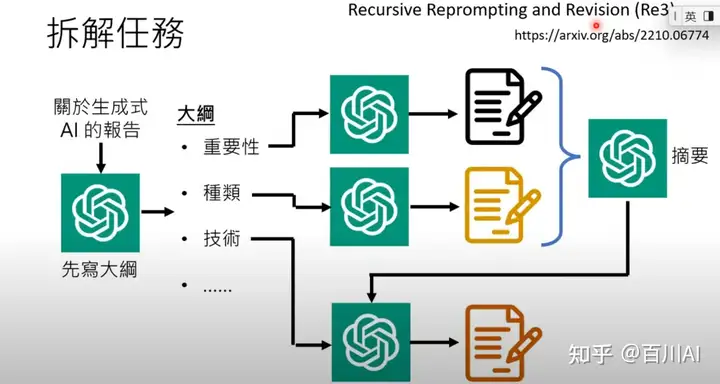
1.3 拆解任务
Generating Longer Stories With Recursive Reprompting and Revision
如果任务复杂,可以拆解为多步骤,以写长篇小说为例,先写大纲,然后写前面章节,然后根据前面已有章节生成摘要指导后面章节生成(保证连贯性)。
模型反思:https://www.youtube.com/watch?v=m7dUFlX-yQI%29
1.4 多专家模型融合
不同的模型分工不同的角色,同时不同角色的语言模型会针对任务做优化,例如专门写代码的模型。
- 训练自己的模型
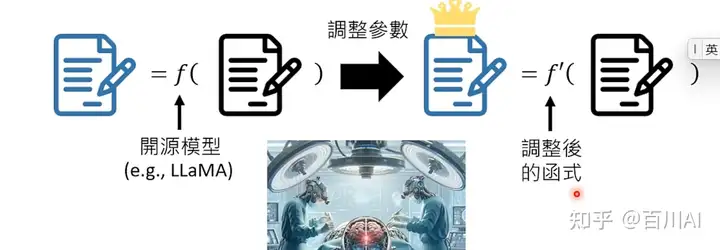
开源模型基础上训练自己的模型
Reference
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号