快手员工薪酬一览表。。


快手面经(强度拉满)
Java的基础数据类型,分别占多少字节
数据类型 | 默认值 | 大小 |
|---|---|---|
boolean | false | 1 比特 |
char | '\u0000' | 2 字节 |
byte | 0 | 1 字节 |
short | 0 | 2 字节 |
int | 0 | 4 字节 |
long | 0L | 8 字节 |
float | 0.0f | 4 字节 |
double | 0.0 | 8 字节 |
HashMap的结构?
JDK 8 中 HashMap 的数据结构是数组+链表+红黑树。
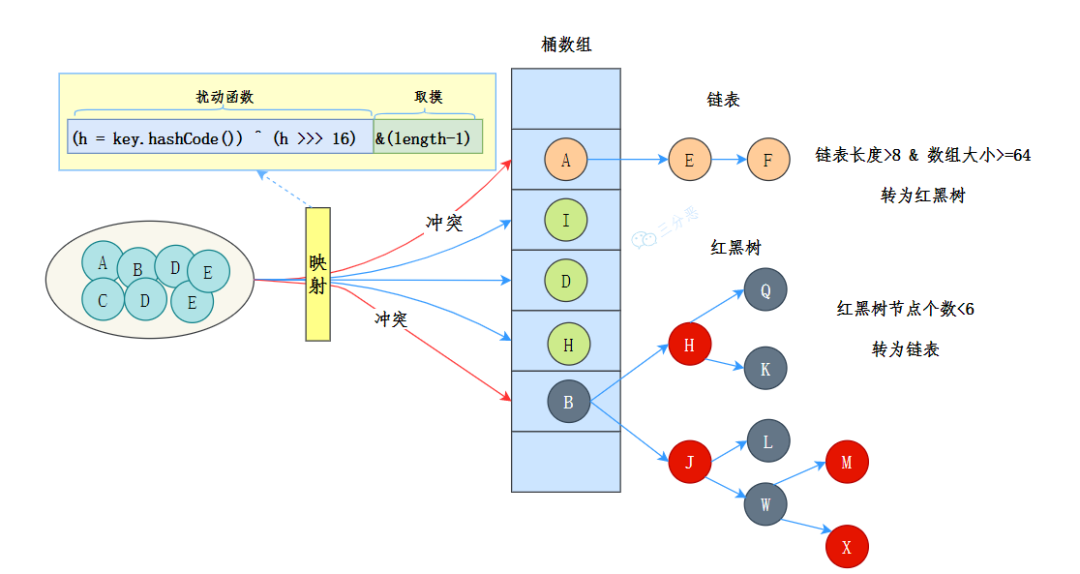
三分恶面渣逆袭:JDK 8 HashMap 数据结构示意图
HashMap的put过程
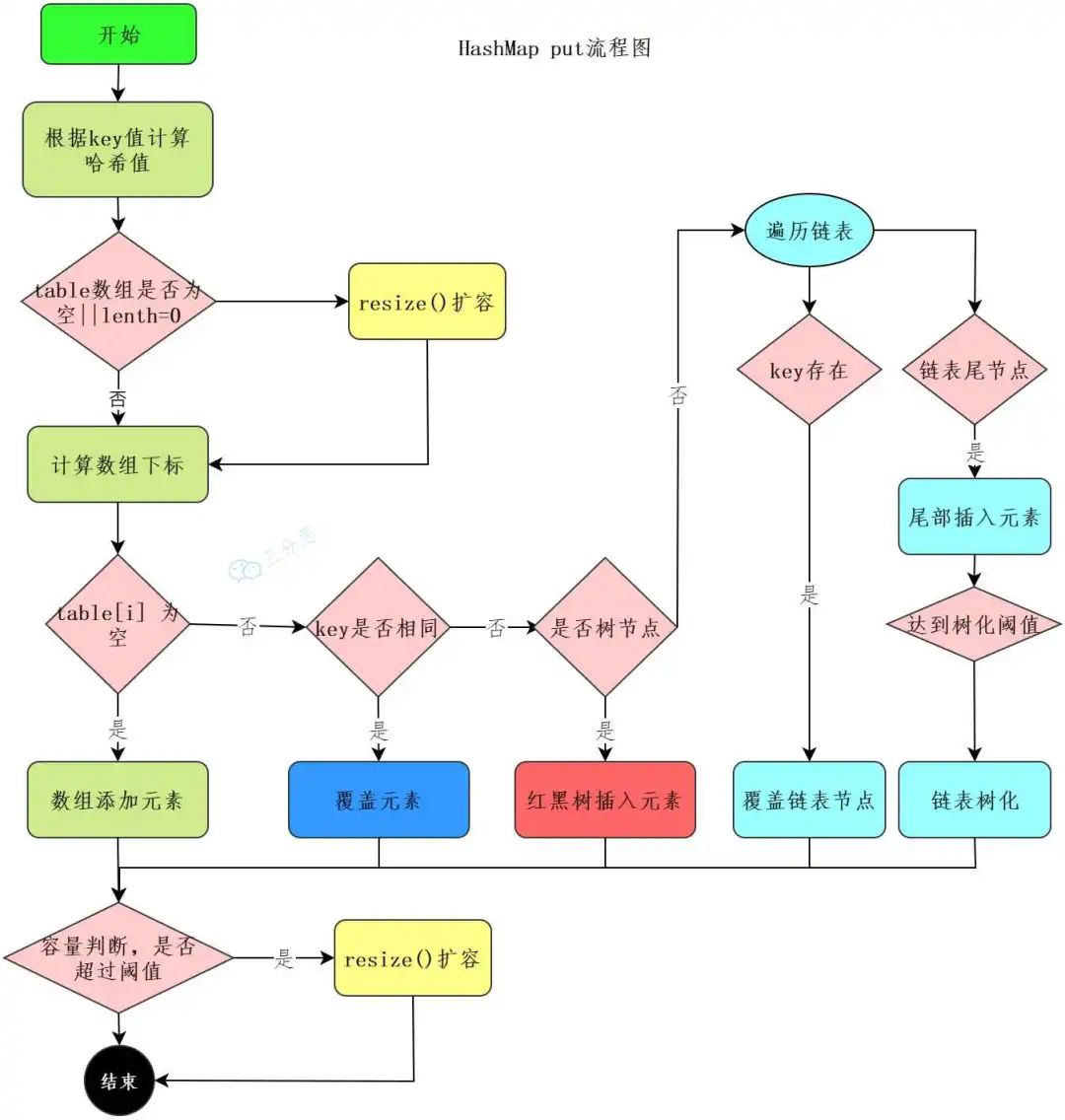
三分恶面渣逆袭:HashMap插入数据流程图
ConcurrentHashMap 对HashMap的优化?
ConcurrentHashMap 是 HashMap 的线程安全版本,使用了 CAS、synchronized、volatile 来确保线程安全。
首先是 hash 的计算方法上,ConcurrentHashMap 的 spread 方法接收一个已经计算好的 hashCode,然后将这个哈希码的高 16 位与自身进行异或运算,这里的 HASH_BITS 是一个常数,值为 0x7fffffff,它确保结果是一个非负整数。
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
比 HashMap 的 hash 计算多了一个 & HASH_BITS 的操作。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
另外,ConcurrentHashMap 对节点 Node 做了进一步的封装,比如说用 Forwarding Node 来表示正在进行扩容的节点。
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
最后就是 put 方法,通过 CAS + synchronized 来保证线程安全。
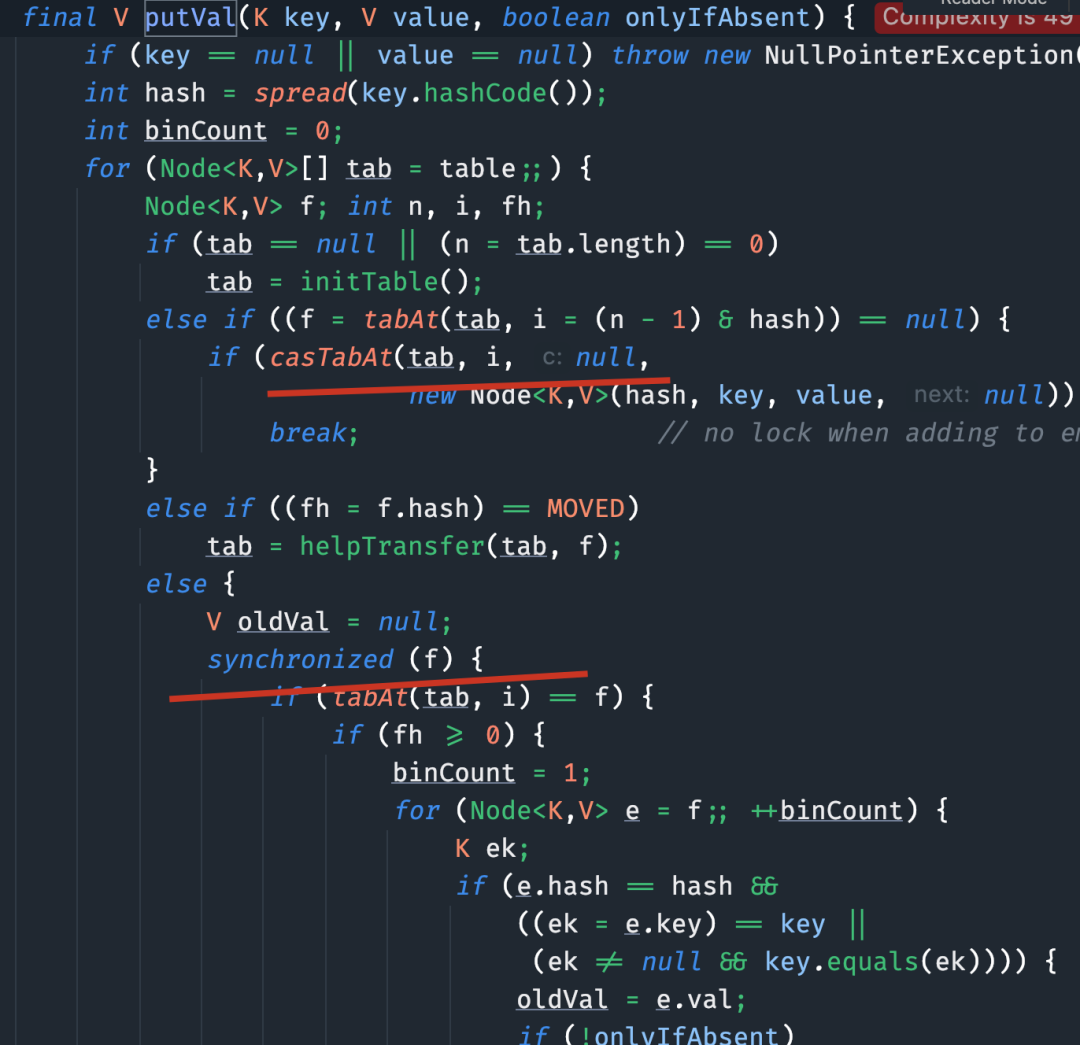
二哥的 Java 进阶之路:ConcurrentHashMap 的源码
ConcurrentHashMap 1.8比1.7的优化在哪里?
ConcurrentHashMap 在 JDK 7 时采用的是分段锁机制(Segment Locking),整个 Map 被分为若干段,每个段都可以独立地加锁。因此,不同的线程可以同时操作不同的段,从而实现并发访问。
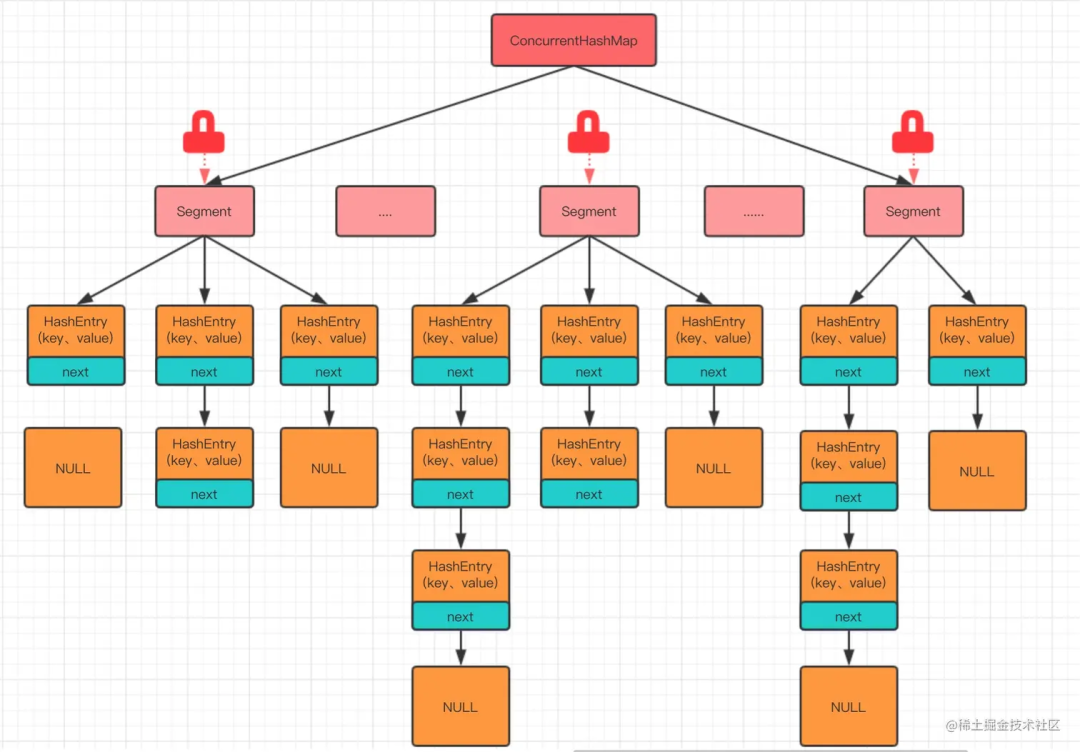
初念初恋:JDK 7 ConcurrentHashMap
在 JDK 8 及以上版本中,ConcurrentHashMap 的实现进行了优化,不再使用分段锁,而是使用了一种更加精细化的锁——桶锁,以及 CAS 无锁算法。每个桶(Node 数组的每个元素)都可以独立地加锁,从而实现更高级别的并发访问。
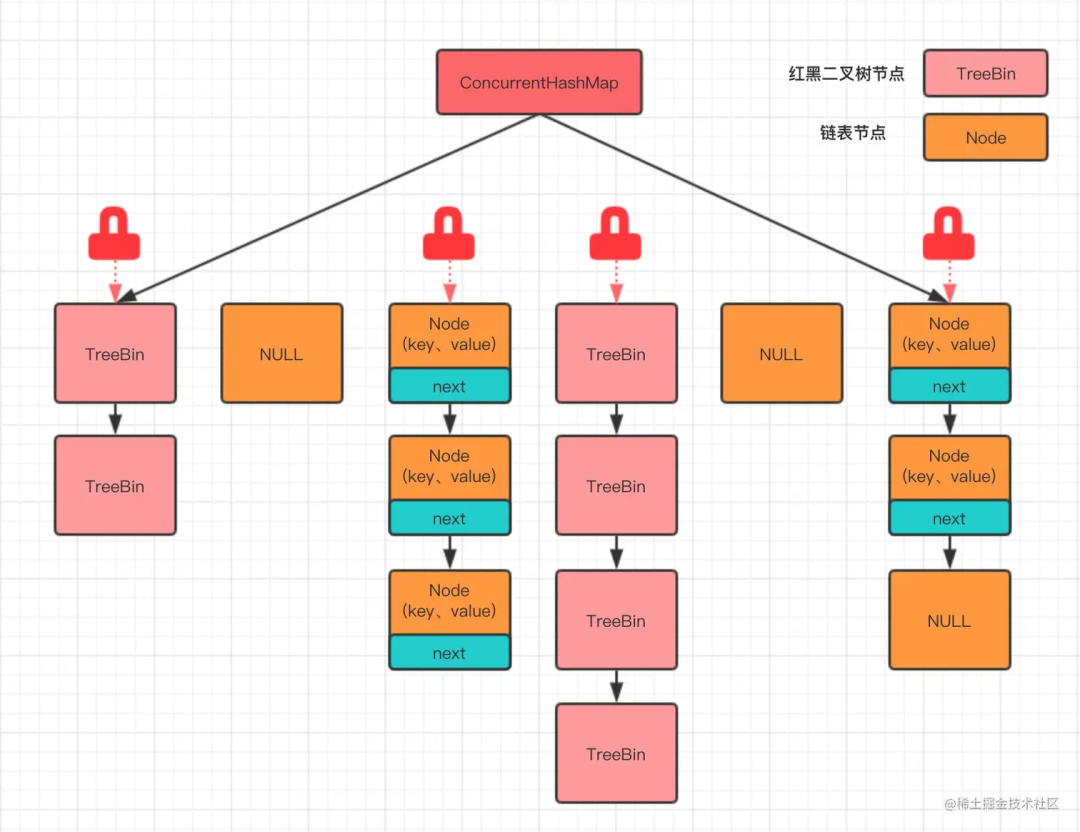
初念初恋:JDK 8 ConcurrentHashMap
同时,对于读操作,通常不需要加锁,可以直接读取,因为 ConcurrentHashMap 内部使用了 volatile 变量来保证内存可见性。
对于写操作,ConcurrentHashMap 使用 CAS 操作来实现无锁的更新,这是一种乐观锁的实现,因为它假设没有冲突发生,在实际更新数据时才检查是否有其他线程在尝试修改数据,如果有,采用悲观的锁策略,如 synchronized 代码块来保证数据的一致性。
你对线程安全的理解是什么?
线程安全是并发编程中一个重要的概念,如果一段代码块或者一个方法在多线程环境中被多个线程同时执行时能够正确地处理共享数据,那么这段代码块或者方法就是线程安全的。
可以从三个要素来确保线程安全:
①、原子性:确保当某个线程修改共享变量时,没有其他线程可以同时修改这个变量,即这个操作是不可分割的。

雷小帅:原子性
原子性可以通过互斥锁(如 synchronized)或原子操作(如 AtomicInteger 类中的方法)来保证。
②、可见性:确保一个线程对共享变量的修改可以立即被其他线程看到。
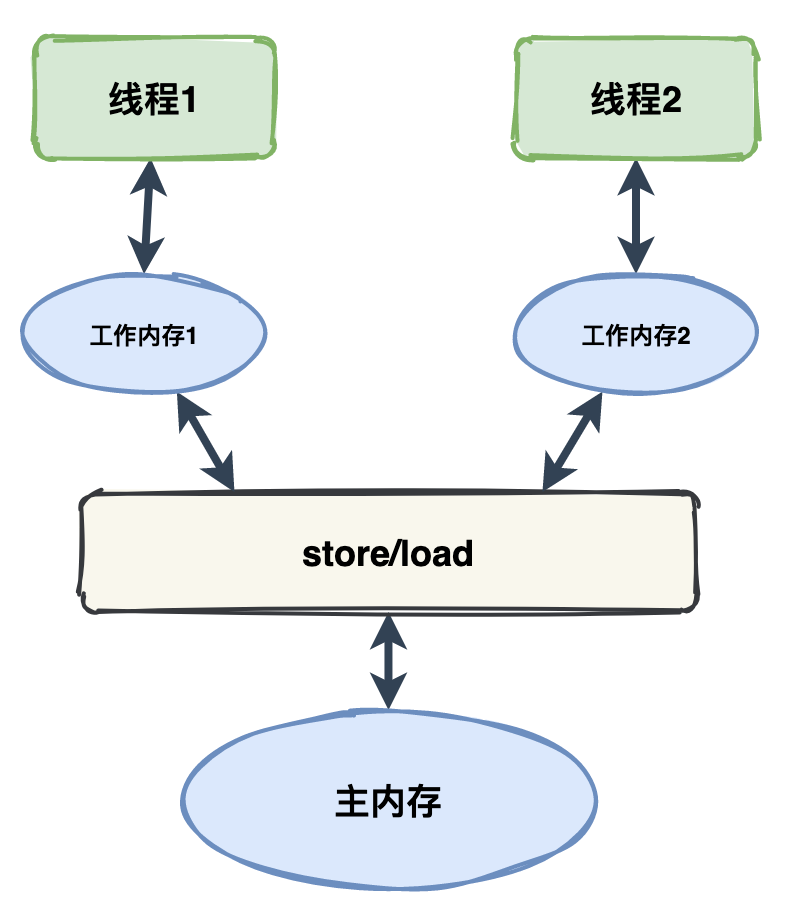
雷小帅:可见性
volatile 关键字可以保证了变量的修改对所有线程立即可见,并防止编译器优化导致的可见性问题。
③、活跃性问题:要确保线程不会因为死锁、饥饿、活锁等问题导致无法继续执行。
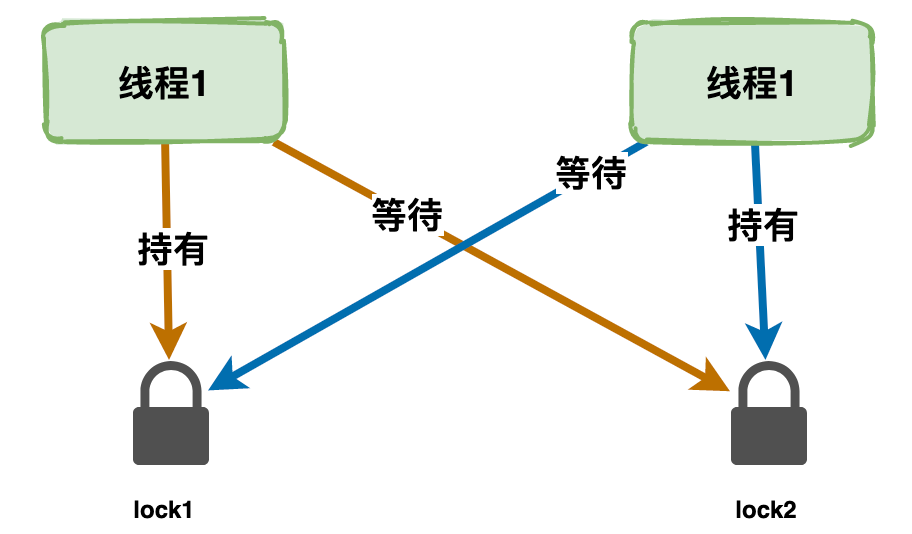
雷小帅:活跃性问题
请说一下Java的内存区域,程序计数器等?
JVM 的内存区域,有时叫 JVM 的内存结构,有时也叫 JVM 运行时数据区,按照 Java 的虚拟机规范,可以细分为程序计数器、虚拟机栈、本地方法栈、堆、方法区等。
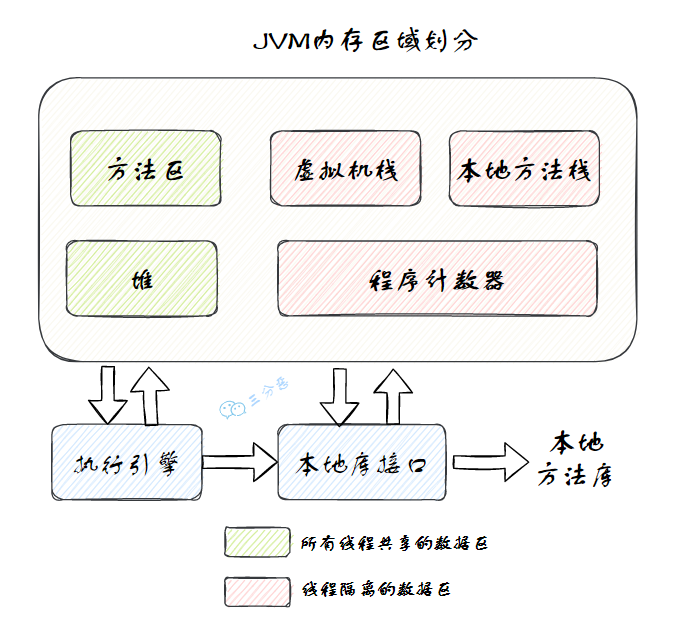
三分恶面渣逆袭:Java虚拟机运行时数据区
介绍一下程序计数器?
程序计数器(Program Counter Register)也被称为 PC 寄存器,是一块较小的内存空间。它可以看作是当前线程所执行的字节码行号指示器。
向线程池中提交任务的过程?
当应用程序提交一个任务时,线程池会根据当前线程的状态和参数决定如何处理这个任务。
- 如果线程池中的核心线程都在忙,并且线程池未达到最大线程数,新提交的任务会被放入队列中进行等待。
- 如果任务队列已满,且当前线程数量小于最大线程数,线程池会创建新的线程来处理任务。
空闲的线程会从任务队列中取出任务来执行,当任务执行完毕后,线程并不会立即销毁,而是继续保持在池中等待下一个任务。
当线程空闲时间超出指定时间,且当前线程数量大于核心线程数时,线程会被回收。
核心线程和最大线程的区别是什么?
①、corePoolSize
定义了线程池中的核心线程数量。即使这些线程处于空闲状态,它们也不会被回收。这是线程池保持在等待状态下的线程数。
②、maximumPoolSize
线程池允许的最大线程数量。当工作队列满了之后,线程池会创建新线程来处理任务,直到线程数达到这个最大值。
核心线程能销毁吗?
核心线程会一直运行,而超出核心线程数的线程,如果空闲时间超过 keepAliveTime,将会被终止,直到线程池的线程数减少到 corePoolSize。
了解OOM吗?
内存泄漏:是指程序在使用完内存后,未能释放已分配的内存空间,导致这部分内存无法再被使用。随着时间的推移,内存泄漏会导致可用内存逐渐减少,最终可能导致内存溢出。

三分恶面渣逆袭:内存泄漏、内存溢出
Java哪些内存区域会发生OOM?为什么?
导致内存溢出(OOM)的原因有很多,比如一次性创建了大量对象导致堆内存溢出;比如说元空间溢出,抛出 java.lang.OutOfMemoryError:Metaspace,比如说栈溢出,如果栈的深度超过了 JVM 栈所允许的深度,将会抛出 StackOverflowError。
你如何排查OOM?
第一步,使用 jps 查看运行的 Java 进程 ID
第二步,使用top -p [pid] 查看进程使用 CPU 和内存占用情况
第三步,使用 top -Hp [pid] 查看进程下的所有线程占用 CPU 和内存情况
第四步,将线程 ID 转换为 16 进制:printf "%x\n" [pid],输出的值就是线程栈信息中的 nid。
例如:
printf "%x\n" 29471,输出 731f。
第五步,抓取线程栈:jstack 29452 > 29452.txt,可以多抓几次做个对比。
在线程栈信息中找到对应线程号的 16 进制值,如下是 731f 线程的信息。线程栈分析可使用 VisualVM 插件 TDA。
"Service Thread" #7 daemon prio=9 os_prio=0 tid=0x00007fbe2c164000 nid=0x731f runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
第六步,使用jstat -gcutil [pid] 5000 10 每隔 5 秒输出 GC 信息,输出 10 次,查看 YGC 和 Full GC 次数。
通常会出现 YGC 不增加或增加缓慢,而 Full GC 增加很快。
或使用 jstat -gccause [pid] 5000 输出 GC 摘要信息。
或使用 jmap -heap [pid] 查看堆的摘要信息,关注老年代内存使用是否达到阀值,若达到阀值就会执行 Full GC。
如果发现 Full GC 次数太多,就很大概率存在内存泄漏了
第八步,使用 jmap -histo:live [pid] 输出每个类的对象数量,内存大小(字节单位)及全限定类名。
第九步,生成 dump 文件,借助工具分析哪个对象非常多,基本就能定位到问题根源了。
使用 jmap 生成 dump 文件:
# jmap -dump:live,format=b,file=29471.dump 29471
Dumping heap to /root/dump ...
Heap dump file created
第十步,dump 文件分析
可以使用 jhat 命令分析:jhat -port 8000 29471.dump,浏览器访问 jhat 服务,端口是 8000。
也可以使用图形化工具分析,如 JDK 自带的 jvisualvm,从菜单 > 文件 > 装入 dump 文件。
或使用第三方式具分析的,如 JProfiler、GCViewer 工具。
或使用在线分析平台 GCEasy。
注意:如果 dump 文件较大的话,分析会占比较大的内存。
在 dump 文析结果中查找存在大量的对象,再查对其的引用。基本上就可以定位到代码层的逻辑了。
请说一下ThreadLocal的作用和使用场景?
ThreadLocal 是 Java 中提供的一种用于实现线程局部变量的工具类。它允许每个线程都拥有自己的独立副本,从而实现线程隔离,用于解决多线程中共享对象的线程安全问题。
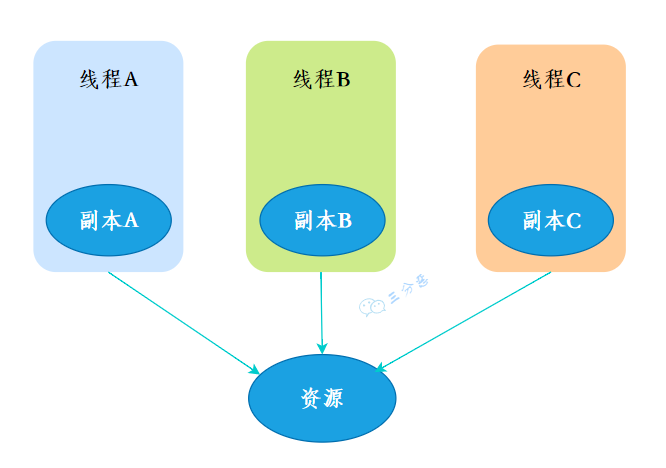
三分恶面渣逆袭:ThreadLocal线程副本
假如在服务层和持久层也要用到用户信息,就可以在控制层拦截请求把用户信息存入 ThreadLocal。
技术派实战源码
这样我们在任何一个地方,都可以取出 ThreadLocal 中存的用户信息。
技术派实战源码
很多其它场景的 cookie、session 等等数据隔离都可以通过 ThreadLocal 去实现。

三分恶面渣逆袭:ThreadLoca存放用户上下文
数据库连接池也可以用 ThreadLocal,将数据库连接池的连接交给 ThreadLocal 进行管理,能够保证当前线程的操作都是同一个 Connnection。
ThreadLocal有什么缺陷?
如果一个线程一直在运行,并且其 ThreadLocalMap 中的 Entry.value 一直指向某个强引用对象,那么这个对象就不会被回收,从而导致内存泄漏。当 Entry 非常多时,可能就会引发更严重的内存溢出问题。

你了解哪些ThreadLocal的改进方案?
在 JDK 20 Early-Access Build 28 版本中,出现了 ThreadLocal 的改进方案,即 ScopedValue。
还有 Netty 中的 FastThreadLocal,它是 Netty 对 ThreadLocal 的优化,它内部维护了一个索引常量 index,每次创建 FastThreadLocal 中都会自动+1,用来取代 hash 冲突带来的损耗,用空间换时间。
private final int index;
public FastThreadLocal() {
index = InternalThreadLocalMap.nextVariableIndex();
}
public static int nextVariableIndex() {
int index = nextIndex.getAndIncrement();
if (index < 0) {
nextIndex.decrementAndGet();
}
return index;
}
Mysql的聚簇索引和非聚簇索引的区别是什么?
聚簇索引不是一种新的索引,而是一种数据存储方式。

三分恶面渣逆袭:聚簇索引和非聚簇索引
在聚簇索引中,表中的行是按照键值(索引)的顺序存储的。这意味着表中的实际数据行和键值之间存在物理排序的关系。因此,每个表只能有一个聚簇索引。例如,在 MySQL 的 InnoDB 存储引擎中,主键就是聚簇索引。
在非聚簇索引中,索引和数据是分开存储的,索引中的键值指向数据的实际存储位置。因此,非聚簇索引也被称为二级索引或辅助索引。表可以有多个非聚簇索引。
Redis的sadd命令时间复杂度是多少?
向指定 Set 中添加 1 个或多个 member,如果指定 Set 不存在,会自动创建一个。时间复杂度为 O(N) ,N 为添加的 member 个数。
Redis的cluster集群如何实现?
在 Redis Cluster 中,数据和实例之间的映射是通过哈希槽(hash slot)来实现的。Redis Cluster 有 16384 个哈希槽,每个键根据其名字的 CRC16 值被映射到这些哈希槽上。然后,这些哈希槽会被均匀地分配到所有的 Redis 实例上。
CRC16 是一种哈希算法,它可以将任意长度的输入数据映射为一个 16 位的哈希值。

三分恶面渣逆袭:槽
参考链接
- 三分恶的面渣逆袭:https://javabetter.cn/sidebar/sanfene/nixi.html
- 二哥的 Java 进阶之路:https://javabetter.cn
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号