Presto CBO统计元数据
原创

背景
Presto:2012年秋季Facebook内部开始研发,2013年正式对外开源。Presto是Facebook用于补充和替代Hive的产品,主要用于实时场景的交互式数据分析。相比于Hive的SQL on Hadoop,Presto不与Hadoop(MapReduce计算/HDFS存储)的框架模型绑定,其设计目标是SQL on Everything。
Presto是典型Master-Slave架构:主要由Coordinator和Worker两个进程组件构建。客户端将SQL提交到Coordinator(协调器),Coordinator进行SQL语法检查、语义分析以及并行查询计划生成(拆分Stages),Scheduler(调度器)将查询计划分配到保存表数据的各个Worker(工作进程),并调度及监督SQL语句的执行过程。
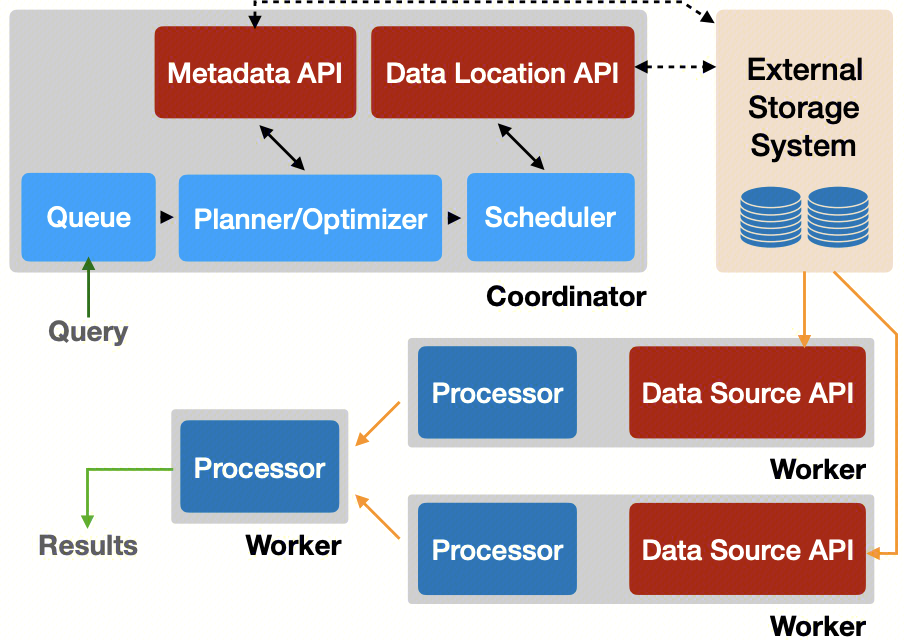
整体架构
统计信息
TableStatistics 统计信息,参考:com.facebook.presto.spi.statistics.TableStatistics
字段 | 字段名称 |
|---|---|
rowCount | 行数量 |
totalSize | 数据文件大小 |
columnStatistics | 字段统计信息,Map<String,ColumnStatistics> |
ColumnStatistics 字段统计信息
字段 | 字段名称 |
|---|---|
nullsFraction | null字段值的比例 |
distinctValuesCount | 不同字段值的个数统计 |
dataSize | 字段读取的数据文件大小 |
range | 字段的区间范围:最大值和最小值 |
Presto基于ConnectorMetadata#getTableStatistics获取元数据信息,目前仅Hive Connector、Iceberg Connector支持获取元数据的统计信息,统计信息用于树节点Visitor遍历时进行CBO优化。
- Hive统计元数据:调用HiveStatisticsProvider#getTableStatistics方法,底层调用对应Metastore Client RPC接口,包括 getTableStatistics、getPartitionStatistics;
- Iceberg统计元数据:基于TableScan#planFiles 列出元数据文件,对元数据文件遍历操作,获取统计信息。
ANALYZE执行
ANALYZE table_name [ WITH ( property_name = expression [, ...] ) ]统计元数据执行:调用LogicalPlanner#createAnalyzePlan,执行StatisticsAggregationPlanner#createStatisticsAggregation,基于Presto Operator算子实现,扩展StatisticsWriterOperator算子执行元数据统计,通过StatisticsWriterOperator#getComputedStatistics计算统计元数据,统计操作对应逻辑算子StatisticsWriterNode。
- 表统计信息:调用RowExpression执行countFunction 统计表记录数,并基于AggregationNode.Aggregation汇总;
- 字段统计信息:分别调用ColumnStatisticsAggregation 执行聚合操作;
统计元数据获取:Presto基于ConnectorMetadata#getTableStatistics获取元数据信息,目前仅Hive Connector、Iceberg Connector支持获取元数据的统计信息,统计信息用于树节点Visitor遍历的CBO优化:
- Hive统计元数据:调用HiveStatisticsProvider#getTableStatistics方法,底层调用对应Metastore Client RPC接口,包括 getTableStatistics、getPartitionStatistics;
- Iceberg统计元数据:基于TableScan#planFiles 列出元数据文件,对元数据文件遍历操作,获取统计信息;
统计元数据更新:MetadataManager#finishStatisticsCollection 控制元数据统计更新操作,仅Hive Connector实现元数据统计执行,调用HiveMetadata#finishStatisticsCollection实现。底层调用Hive Metastore RPC接口:updateTableStatistics、updatePartitionStatistics。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号