LangSmith帮助测试大模型系统


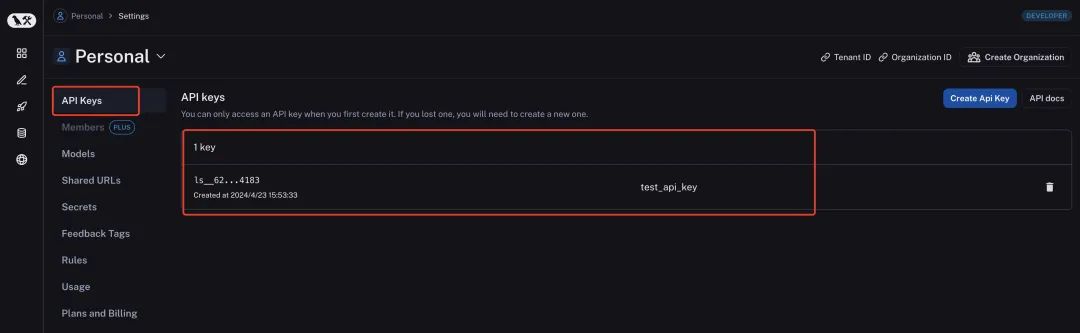
LangSmith是评估大模型能力好坏的评估工具,能够量化评估基于大模型的系统的效果。LangSmith通过记录langchain构建的大模型应用的中间过程,从而能够更好的调整提示词等中间过程做优化。想要使用LangSmith首先进入他的设置页面,https://smith.langchain.com/settings注册一个账号,然后进入API Keys页面创建一个API Keys,我们为例后续演示,这里创建一个test_api_key名字的API Key,如下图所示。
然后我们需要在本地安装LangSmith的依赖包
pip install -U langsmith设置完成后就可以在LangChain代码中加入LangSmith环境变量进行过程数据收集了。需要设置的环境变量有如下四个。
- LANGCHAIN_TRACING_V2:设置LangChain是否开启日志跟踪模式。
- LANGCHAIN_API_KEY:就是上面生成的LangSmith的key。
- LANGCHAIN_ENDPOINT:LangSmith的收集过程数据的API地址
- LANGCHAIN_PROJECT:是要跟踪的项目名称,如果LangSmith平台上还没有这个项目,会自动创建。如果不设置这个环境变量,会把相关信息写到default项目,使用过程中比较建议设置改环境变量。LangSmith中的项目不一定要跟实际团队理解的项目是对应的,这可以理解成是一个分类或者标签。只要在运行LangChain的程序前修改了这个标签,它就会把对应的日志写到修改后的项目下面。常规可以按照环境类型划分、按日期划分,具体看项目实际需求。
为了测试我们依托讯飞星火大模型创建一个继承LangChain的CustomLLMSparkLLM的类(代码在6.2.1章节),依托对应的类我创建了如下的测试代码。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
@File : try.py
@Time : 2024/03/29
@Author : CrissChan
@Version : 1.0
@Site : https://blog.csdn.net/crisschan
@Desc :
'''
import os
##临时设置环境变量
###LANGCHAIN_TRACING_V2是设置LangChain是否开启日志跟踪模式。
os.environ['LANGCHAIN_TRACING_V2']="true"
###LANGCHAIN_API_KEY就是上面生成的LangSmith的key。
os.environ['LANGCHAIN_API_KEY']="ls__626de75e47214de3a9b73ea801774183"
os.environ['LANGCHAIN_ENDPOINT']="https://api.smith.langchain.com"
###LANGCHAIN_PROJECT 是要跟踪的项目名称,如果LangSmith平台上还没有这个项目,会自动创建。如果不设置这个环境变量,会把相关信息写到default项目。这里的项目不一定要跟你实际的项目一一对应,可以理解为分类或者标签。你只要在运行某个应用前改变这一项,就会把相关的日志写到这个下面。
###可以按开发、生产环境分,也可以按日期分等等。
os.environ['LANGCHAIN_PROJECT']="Food"
import warnings
warnings.filterwarnings('ignore')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
from iflytek import SparkLLM
# 构建两个场景的模板
chinese_food_template = """
你是一个经验丰富的中餐厨师,擅长制作中式食物。
下面是需要你来回答的问题:
{input}
"""
western_food_template = """
你是一位经验丰富的西点厨师,擅长制作西点。
下面是需要你来回答的问题:
{input}
"""
# 构建提示信息
prompt_infos = [
{
"key": "food",
"description": "适合回答关于中餐制作方面的问题",
"template": chinese_food_template,
},
{
"key": "bakery",
"description": "适合回答关于西餐制作方面的问题",
"template": western_food_template,
}
]
# 初始化语言模型
llm = SparkLLM(temperature=0.1)
# 构建目标链
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
chain_map = {}
for info in prompt_infos:
prompt = PromptTemplate(
template=info['template'],
input_variables=["input"]
)
print("目标提示:\n", prompt)
chain = LLMChain(
llm=llm,
prompt=prompt,
verbose=True
)
chain_map[info["key"]] = chain
# 构建路由链
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE as RounterTemplate
destinations = [f"{p['key']}: {p['description']}" for p in prompt_infos]
router_template = RounterTemplate.format(destinations="\n".join(destinations))
print("路由模板:\n", router_template)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
print("路由提示:\n", router_prompt)
router_chain = LLMRouterChain.from_llm(
llm,
router_prompt,
verbose=True
)
# 构建默认链
from langchain.chains import ConversationChain
default_chain = ConversationChain(
llm=llm,
output_key="text",
verbose=True
)
# 构建多提示链
from langchain.chains.router import MultiPromptChain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=chain_map,
default_chain=default_chain,
verbose=True
)
# 测试
print(chain.run("如何制作贝果"))
运行后,查看LangSmith如下图所示。
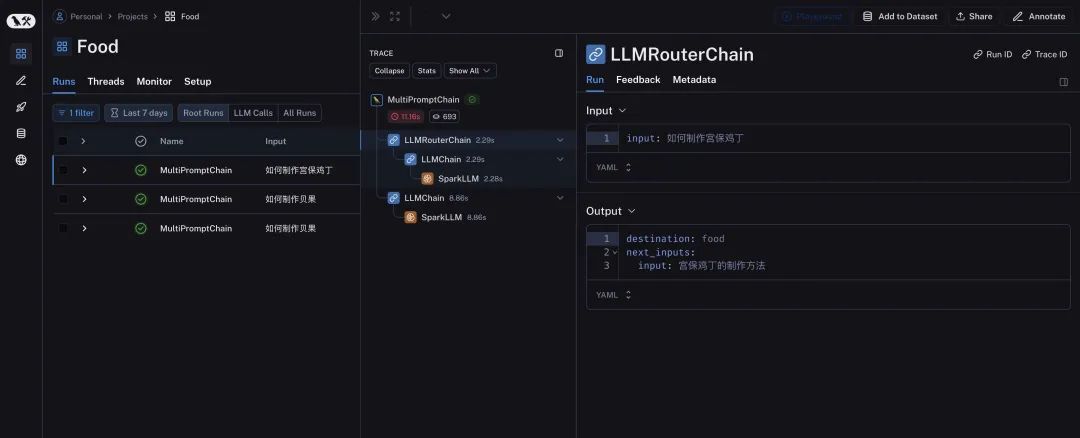
我们可以在LangSmith的页面看到详细的中间过程,可以通过图标进行快速的识别不同模块的作用。我们可以看到每一个处理过程的输入和输出,也方便我们调试和评估结果。
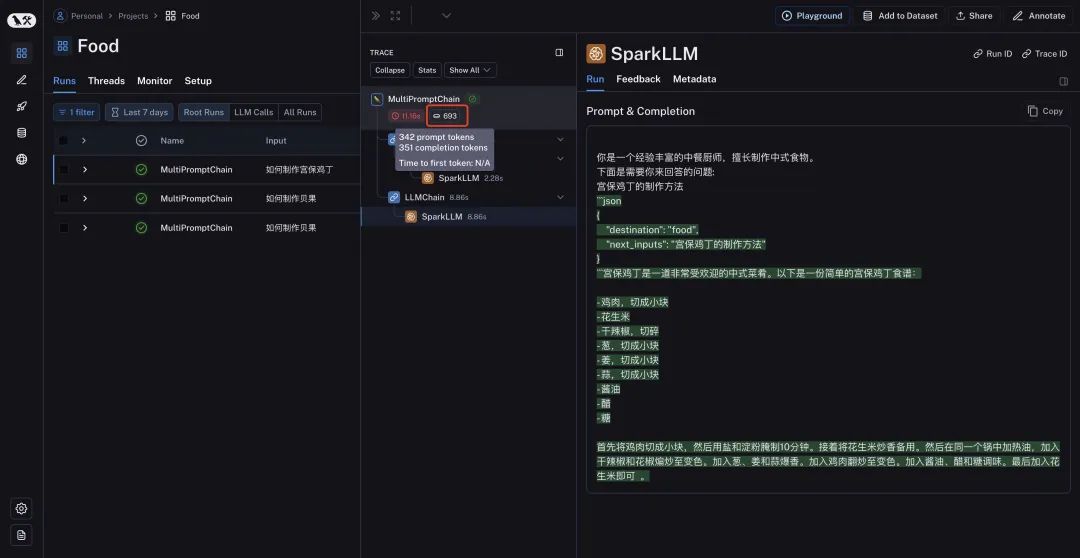
也可以在对应看到Token数量,执行时间等内容。在项目下的列表中,我们多次执行LangChain构建的大模型的应用也可以做横向对比。
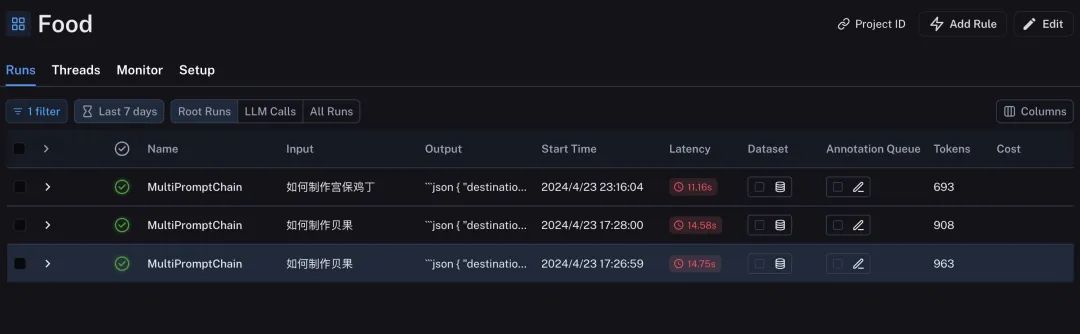
每一次的处理和反馈的Trace都可以展示响应时间和使用的Token数。LangSmith完成了跟踪LangChain构建应用的所有的中间过程,这也为验收或者测试LangChain构建的基于大模型的应用提供了有力的手段。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号