将RAG与CoT结合起来的技术,RAT减轻长文本生成出现的幻觉问题

将RAG与CoT结合起来的技术,RAT减轻长文本生成出现的幻觉问题

www.tangshuang.net
发布于 2024-05-03 13:57:29
发布于 2024-05-03 13:57:29
在过去的经验中,我们知道,CoT(思维链)模式可以降低大模型幻觉。简单讲,CoT就是让大模型按照步骤循序渐进(think step by step)地进行推理,而非直接一次给出答案,这种方式能让大模型在给出答案中将长链演算推理,变成具有规划性质的逐步迭代推导,因此,在一些逻辑推理性强的场景下能明显提升其效果。
但从另一个角度去思考,LLM的幻觉中有很大一部分是虚构事实,而这些情况的发生,总是因为用于训练大模型的知识不够实时,而无法提供符合客观事实的生成。而RAG(检索增强生成)技术则可以很好的解决这一问题,它通过检索外部知识,以增强LLM回复的可靠性。但是,RAG总是一次性提供相关信息,它很难预测后续的生成过程中,哪些是依据RAG提供的“事实”信息的。
基于上述思考,北京大学和相关机构的研究者们提出了一种新的尝试:通过外部知识的帮助(RAG),可以减轻中间推理过程(CoT)中的幻觉。并提出了RAT技术,RAT=CoT+RAG。发表论文《RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation》(https://arxiv.org/pdf/2403.05313)
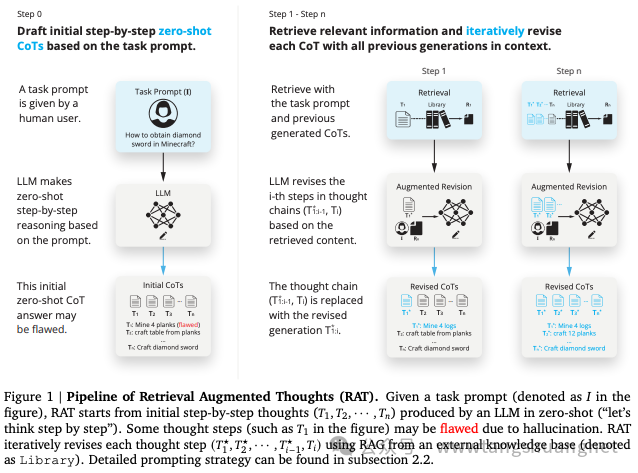
上图示意了RAT的基本思路和原理。在没有CoT的情况下,命中事实概率低,在加入RAT的情况下,大幅提升命中事实概率。
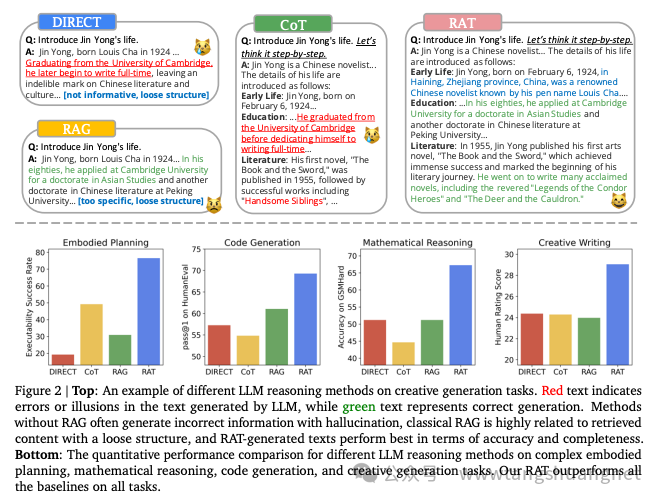
在一系列基准测试下,RAT的表现都有明显的优势。
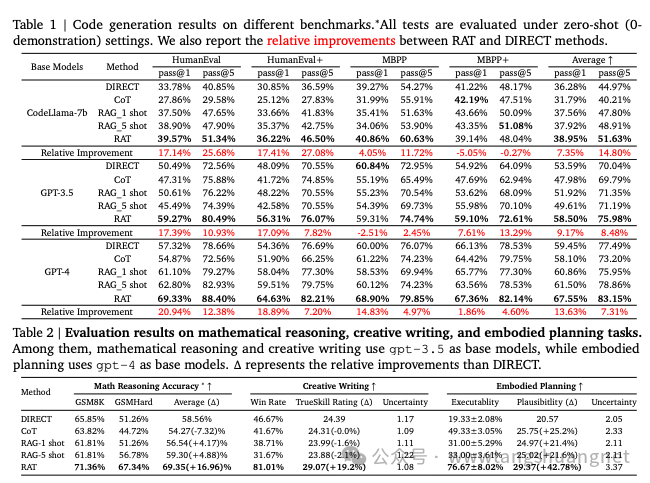
从论文的解释来看,我们有理由相信,RAT技术能明显提示大模型的质量。但是,其中的一些限制也很明显:依赖RAG的质量,性能下降,CoT本身的准确性也对最终的结果有重要影响。
另外,对于我们应用层开发的同学,我们都知道RAG是应用层的技术,而CoT是prompt触发机制(单轮),如何去实现RAT呢?流程主要为3阶段:
- 生成初始prompt1以用于CoT
- 基于初始答案拆分后的step生成RAG检索的prompt2
- 把前两步的结果整合为修订后的prompt3,并让LLM给出最终结果
prompt1 = """
尝试用逐步的思考来回答这个问题\指令,并使答案更具结构化。
使用 `\n\n` 来将答案分成几个段落。
直接响应指令。除非被要求,否则不要在答案中添加额外的解释或介绍。
"""
prompt2 = """
我想验证给定问题的内容准确性,特别是最后几句话。
请用相应的问题总结内容。
这个总结将被用作必应搜索引擎的查询。
查询应该简短,但需要足够具体,以确保必应能够找到相关知识或页面。
您还可以使用搜索语法,使查询足够简短和清晰,以便搜索引擎能够找到相关的语言数据。
尽量使查询与内容中的最后几句话尽可能相关。
**重要**
直接输出查询。除非被要求,否则不要在答案中添加额外的解释或介绍。
"""
prompt3 = """
我想根据在维基百科页面上学到的相关文本来修订答案。
你需要检查答案是否正确。
如果你在答案中发现了错误,请修订答案使其更好。
如果你发现有些必要的细节被忽略了,请根据相关文本添加这些细节,以使答案更加可信。
如果你发现答案是正确的且不需要添加更多细节,请直接输出原始答案。
**重要**
尽量保持修订后答案的结构(多个段落及其子标题),使其更具结构性以便理解。
用 `\n\n` 字符分隔段落。
直接输出修订后的答案。除非被要求,否则在修订后的答案中不要添加额外的解释或声明。
"""你可以通过开源代码来自己测试其效果 https://craftjarvis.github.io/RAT/。
我们也可以基于workflow来自己搭建这个流程,通过应用层的设计来实现相同的效果。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-27,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号