国产五大模型之一MiniMax 使用国内首个MOE架构
原创
国产五大模型之一MiniMax 使用国内首个MOE架构
原创
存内计算开发者
发布于 2024-05-21 15:26:12
发布于 2024-05-21 15:26:12
阿里被曝2024年面向AIGC的第二次大手笔投资来了——加注大模型赛道独角兽Minimax,领投至少6亿美元。
彭博社消息称,新一轮融资或将使MiniMax估值超25亿美元。目前阿里和红杉已承诺将参与本轮融资,其余跟投者还在洽谈中,相关条款可能会有所调整。除阿里外,腾讯、米哈游、IDG资本、高瓴都曾投资过。当前估值达25亿美元。
Minimax是谁?
MiniMax 成立于 2021 年 12 月,由商汤科技前副总裁闫俊杰创立。公司致力于开发先进的人工智能技术,特别是在大型语言模型(LLMs)领域。其技术核心是开发的 ABAB 大模型,这是一个基于 MoE(Mixture of Experts)架构的模型,旨在通过集成多个专家网络来提高模型的扩展性和效率。MoE 架构允许模型在处理复杂任务时拥有更大的参数量,同时保持较高的计算效率。MiniMax 的 ABAB6 模型是国内首个采用 MoE 架构的大语言模型,它在单位时间内能够训练更多的数据,显著提升了模型的性能和效率。MiniMax 提供多种基于其大模型的产品与服务,包括但不限于 MiniMax API 开放平台、海螺 AI 和星野等。这些产品服务于聊天对话、内容生成、语音合成、情感分析等多种场景,满足不同行业和应用的需求。MiniMax 不断推动其大模型技术的发展,例如,其 ABAB6 模型在处理复杂任务方面进行了显著改进,提供了更好的多模态理解和多语言支持。
Minimax使用的大语言模型架构是国内发布的首个MoE架构,全称专家混合(Mixture-of-Experts),是一种集成方法,其中整个问题被分为多个子任务,并将针对每个子任务训练一组专家。MoE 模型将覆盖不同学习者(专家)的不同输入数据。2024 年 4 月 17 日,MiniMax 正式推出abab 6.5 系列模型。abab 6.5 系列包含两个模型:abab 6.5 和 abab 6.5s。abab 6.5 包含万亿参数,支持 200k tokens 的上下文长度;abab 6.5s 跟 abab 6.5 使用了同样的训练技术和数据,但是更高效,支持 200k tokens 的上下文长度,可以 1 秒内处理近 3 万字的文本。在各类核心能力测试中,abab 6.5开始接近 GPT-4、 Claude-3、 Gemini-1.5 等世界上最领先的大语言模型。
核心能力测试
我们用业界标准的开源测试集来测试两个模型,在知识、推理、数学、编程、指令遵从等维度上和行业领先的语言模型进行了对比。
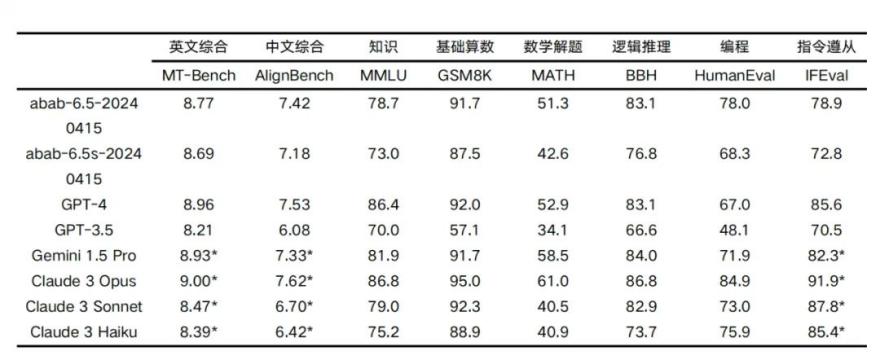
在 891 次测试中,abab 6.5 均能正确回答。
MoE架构 由于训练和部署大型模型造成的庞大开销,研究人员一直致力于探索使用混合专家(MoE)架构来提高大型模型的效率。这在大型模型中尤为明显,MoE通过选择性激活不同的网络组件,优化计算资源并提高性能。在这方面的开创性工作可以在GShard模型中看到[42],它为大规模多语种语言模型引入了MoE的使用,在翻译任务中展示了相当大的改进。Switch Transformers[22]进一步完善了这个概念,通过扩展MoE方法,在视觉理解上实现了前所未有的模型大小和训练效率。此外,BASE Layers[43]探索了将MoE集成到来自变换器的双向编码器表示中,进一步突显了MoE增强语言理解任务的潜力。MoE在生成模型中的应用也得到了探索,其中GLaM[44]是一个显著的例子,展示了MoE处理多样化和复杂生成任务的能力。在本文中,我们主要探索使用MoE架构构建统一的大型多模态模型。模型大小和性能可以在不增加计算需求的情况下得到增强。
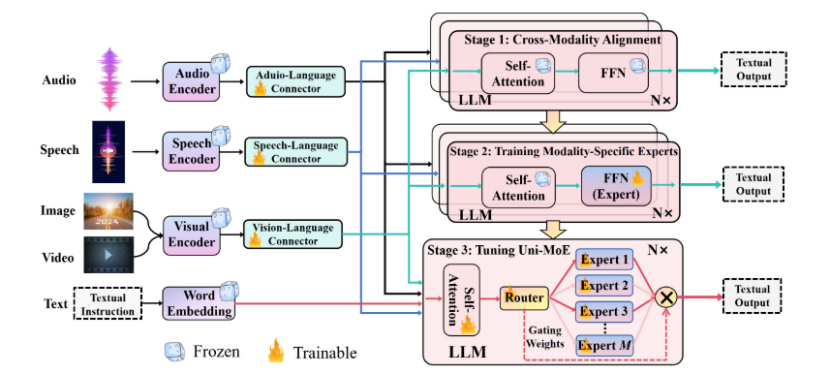
图 2 展示了设计的 Uni-MoE 的示意图,展示了其全面的设计,包括用于音频、语音和视觉的编码器以及各自的模态连接器。这些连接器的作用是将各种模态输入转换为统一的语言空间。然后,我们在核心 LLM 块内集成了 MoE 架构,这对于提高训练和推理过程的效率至关重要,因为只激活部分参数。这是通过实施稀疏路由机制实现的,如图 2 底部所示。Uni-MoE 的整个训练过程被分为三个不同的阶段:跨模态对齐、训练模态特定专家和使用多样化的多模态指令数据集调整 Uni-MoE。在接下来的小节中,我们将详细探讨 Uni-MoE 的复杂架构和渐进式训练方法。
为了发挥不同专家的独特能力,提高多专家协作的效率,并增强整个框架的泛化能力,我们为Uni-MoE的逐步发展引入了一种渐进式训练策略。算法1概述了旨在实现集成基于MoE的MLLM架构的全面三阶段训练协议。在随后的陈述中,我们将详细说明每个训练阶段的目标和具体内容。
Uni-MoE训练过程
第一阶段:跨模态对齐。在初始阶段,我们的目标是建立不同模态和语言之间的连接。我们通过构建连接器来实现这一目标,这些连接器将各种模态数据转换为语言空间中的软标记。这里的主要目标是最小化生成熵损失。如图2的上半部分所示,LLM被优化以生成跨模态输入的描述,只有连接器接受训练。这种方法确保了所有模态在统一的语言框架内无缝集成,便于LLM相互理解。
第二阶段:训练模态特定专家。这一阶段集中于通过针对特定跨模态数据的专门训练来发展单模态专家。目标是提高每个专家在其各自领域内的熟练程度,从而提高MoE系统在多样化多模态数据上的整体性能。同时保持生成熵损失作为主要训练指标,我们定制FFN以更密切地与目标模态的特性对齐。
第三阶段:调整Uni-MoE。最后阶段涉及将第二阶段中调整过的专家权重集成到MoE层中。然后,我们继续使用混合多模态指令数据共同微调MLLM。训练进程的进展,如损失曲线所示,反映在图3中。比较MoE配置之间的分析显示,在第二阶段经过精炼的专家实现了更快的收敛,并在混合模态数据集上显示出更强的稳定性。此外,在涉及复杂混合模态数据的场景中,包括视频、音频、图像和文本,采用四个专家的模型显示出比两个专家的模型更低的损失变异性和更一致的训练性能。与使用辅助平衡损失相比,Uni-MoE显示出更好的收敛性,后者导致整体训练损失波动,并没有显示出明显的收敛。
本次训练通过集成混合专家【MoE】架构来扩展大型多模态模型的能力,通过新的三阶段的训练方式,专门用于提高uni-moe在多模态训练中的稳定性能和泛化性能,优于配备相同配置的传统MoE架构。
存内计算:
MoE模型是当前深度学习和人工智能研究的前沿领域之一,多模态大模型发展除了模型架构不断优化以提升模型处理能力以及效率,算力架构的优化对深度学习和人工智能的发展至关重要,存内计算架构真正做到存算融合,在存储单元内实现计算的模式相较于传统冯诺伊曼架构,减少了数据来回搬运,算力提升20X,尤其适应大规模的并行计算如深度学习。
知存科技凭借率先量产商用的领先技术实力,成为全球存内计算领域的佼佼者。知存科技成立于2017年,由研发出全球首颗支持多层神经网络存内计算芯片的郭昕婕博士担任首席科学家。2022年,知存科技WTM2101芯片正式推向市场,赋能百万级终端实现AI能力的提升和应用的推广,成为全球首颗大规模量产商用的存内计算芯片。
AI时代,存内计算超越摩尔,将成为人工智能时代的新型算力架构。
总结:
国产大模型齐头并进的当下,在单位时间内,提升模型的处理能力以及效率,同时降低算力成本,或成大模型竞争的核心,因此对模型架构优化以及算力架构更新提出更高要求。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号