深入腾讯云TBDS:大规模HDFS集群优化实战

深入腾讯云TBDS:大规模HDFS集群优化实战

腾讯QQ大数据
发布于 2024-06-03 11:18:04
发布于 2024-06-03 11:18:04

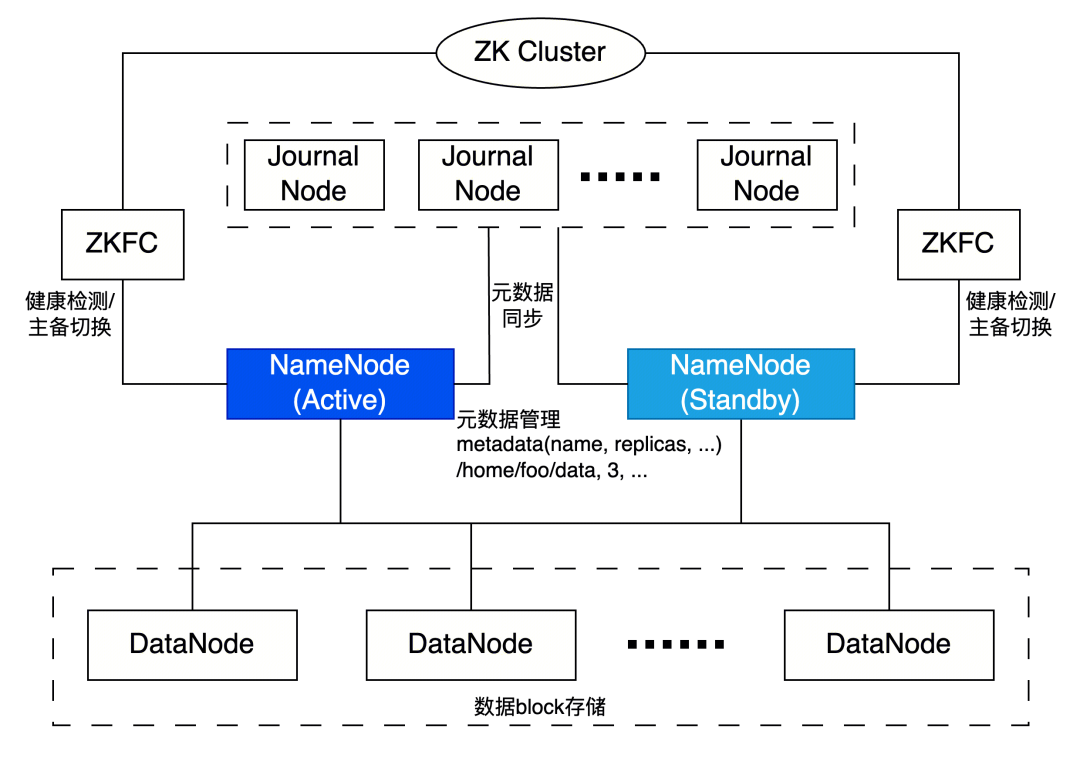
HDFS被设计用来在大规模的廉价服务器集群上可靠地存储大量数据, 并提供高吞吐的数据读取和写入,具备高可用、高容错、高吞吐、低成本、数据本地性等特点。在集群元数据规模不超过8亿且节点数不超过1000时,HDFS可保持稳定的较低RPC响应延迟,以满足客户的特定业务生产场景。
图一
如上HDFS架构所示,随着存储数据的积累理论上可以不断扩容DataNode节点,但元数据仍是由单一的NameNode进行管控。数据爆发式的增长和计算需求的提升,单一的HDFS集群往往难以满足高并发、低延迟的计算需求。需要对集群进行持续地横向拓展和优化。
HDFS在腾讯微信、腾讯广告、腾讯金融等产品和业务领域有着广泛应用,节点规模可达10万级、存储规模达EB级,在应用实践中做了针对性的改善。腾讯云TBDS是腾讯大数据能力的私有云产品化,结合内部实践和典型客户的具体情况,对HDFS做了系统的优化。
01、集群横向扩容
单个ActiveNameNode在大规模集群的局限性主要体现在:
1. 数据规模受限,NameNode内存使用和元数据量正相关,具有内存瓶颈。
2. 稳定性受影响,元数据量越大,GC频率越高,客户场景中曾出现CMS GC的promotion fail场景,导致CMS GC进入长时间的串行Full GC,影响外部访问。
3. 故障隔离性差,单一NameNode负载高会影响全局。
而纵向拓展NameNode内存,也会带来其他问题:内存加载服务启动时间长、大堆调试困难不易优化、Full GC时间长易导致整体服务不可用。因此需要进行NameNode的横向扩容。
扩容方案
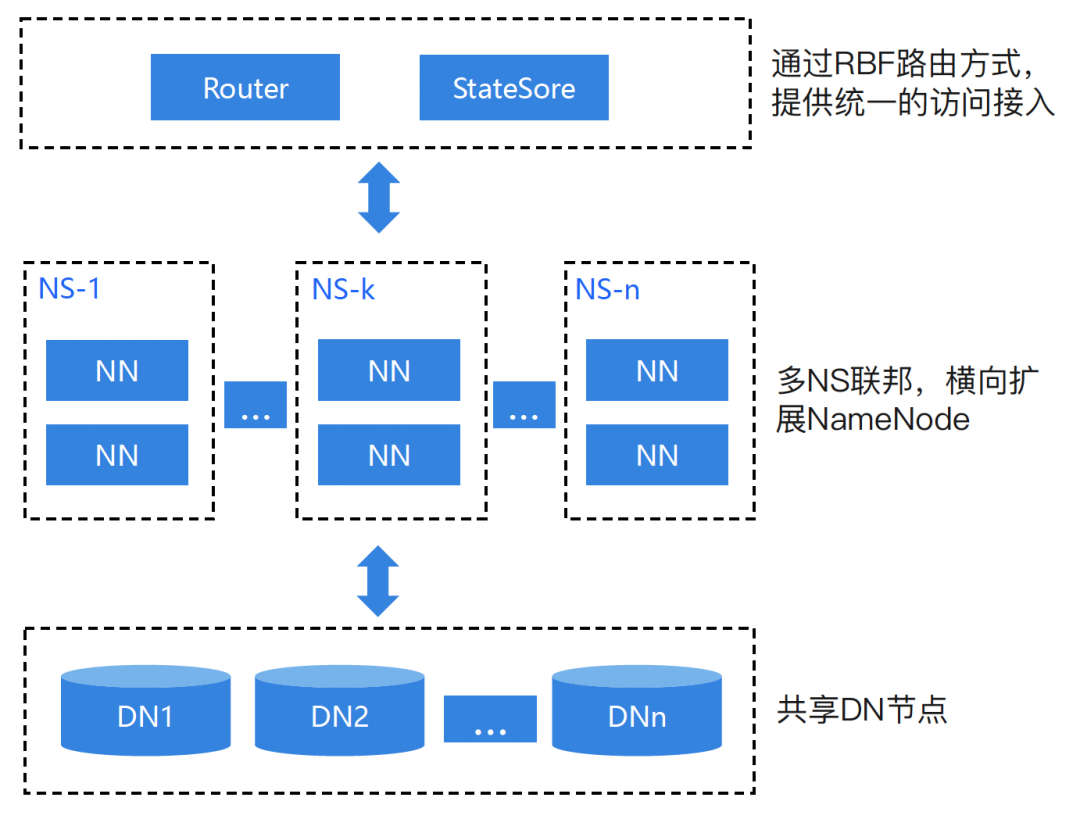
多NS联邦共享DN
图二
基于HDFS Federation特性,同一ClusterID下注册多套NameNode,每套都有唯一的NameService和Block Pool负责分管一部分元数据。
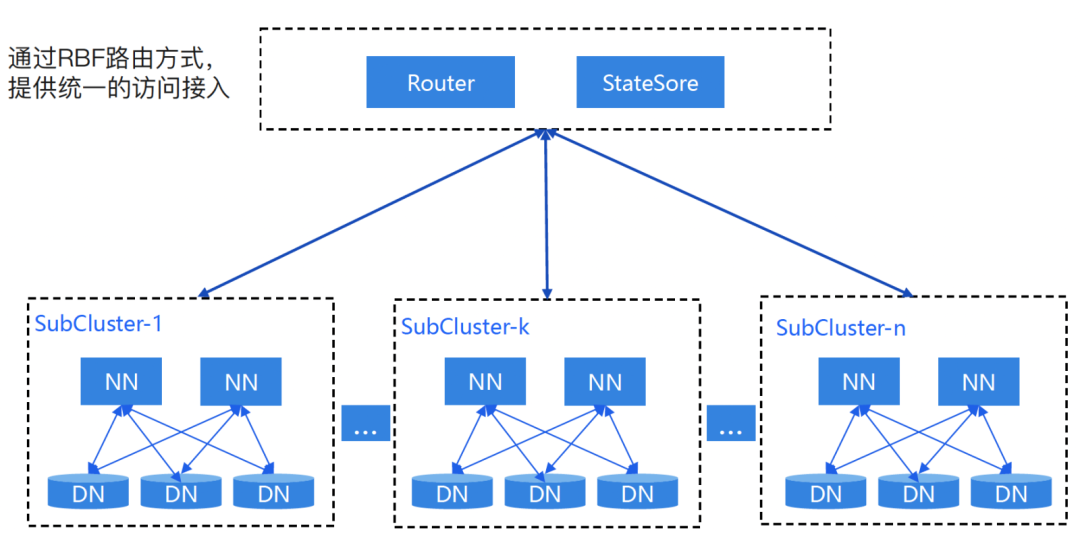
多NS独立集群联邦
图三
独立HDFS集群分管不同的业务数据,实现降低单集群的元数据量。

图四
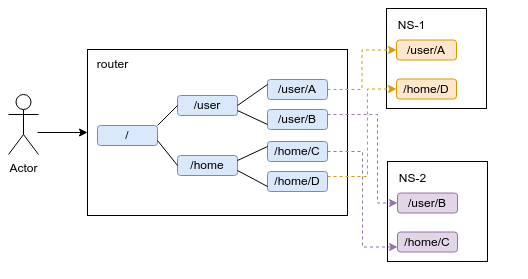
在两套联邦方案中,为了让客户端业务无感知,我们都需要通过Router(HDFS Router-based Federation)来对外提供统一的HDFS访问视图。
图五
确保每个NS对应的目录都相互独立且没有子目录的重叠,然后Router层进行同名路径路由表映射,这样客户访问HDFS时,无需指定特定的HDFS schema,只需要访问Router即可转发到对应NS进行目录访问。
Router的优化
Router作为方案中的核心组件,承接着Client端所有请求以及NameNode返回的元数据信息,其性能将影响服务整体质量。
常见的有用NameNodeProxy轻量化服务替换Router,NameNodeProxy可提供统一的NameSpace、具备路由请求、Quota限制等能力。但其不支持认证、单一目录不支持子集群多NameService挂载以及可支持的操作不全面等问题,并不适用于客户真实生产场景。
为了进一步优化Router本身性能,在腾讯云TBDS产品中将Router的响应请求异步化,解耦同步等待时间以提升Router的吞吐量。
参考NameNode RPC response异步化原理的两个重要逻辑:
- 请求挂起返回。
- editlog call推送到队列执行。
Router异步化过程如下:
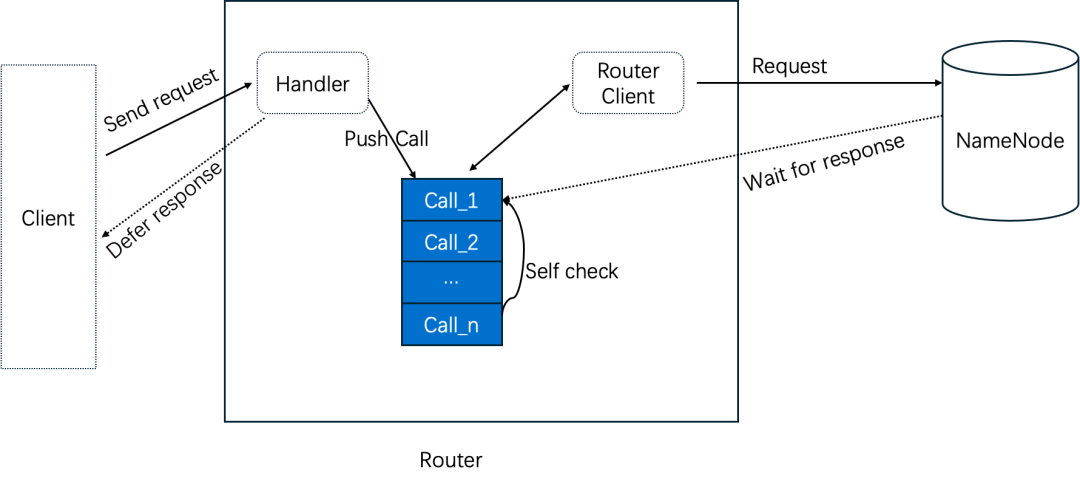
图六
1. 类似NameNode异步化过程,将client请求推送到一个call queue队列。
2. Router Client发送请求给NameNode之后,进入wait阶段。
3. NameNode处理完后,触发notify唤起call队列线程检查,并返回结果。
4. 另从NameNode返回的是protobuf序列化数据,对于大部分请求而言,不需要protobuf反解,可以直接下推给Client → Router这里,以减少内存消耗。
通过Router联邦横向扩容后累积元数据可达30亿+,并且对外的Router rpc请求仍能保持毫秒级响应。
02、读写性能优化
基于联邦的横向扩容方案可以满足数据规模和集群规模的增长,但是随着客户的业务拓展,Router管控下的单个子集群访问请求也会不断提升。在这类生产场景中往往会出现NameNode RPC请求响应慢,极端情况下某个RPC请求需要等待好几分钟的情况,而NameNode日志中存在大量同一类型日志:
INFO namenode.FSNamesystem (FSNamesystemLock.java:readUnlock(194)) - FSNamesystem read lock held for 237962 ms viaRPC变慢的根源在于部分请求长时间持有FSNamesystemLock全局锁,导致其他请求无法及时响应。
NameNode全局锁机制
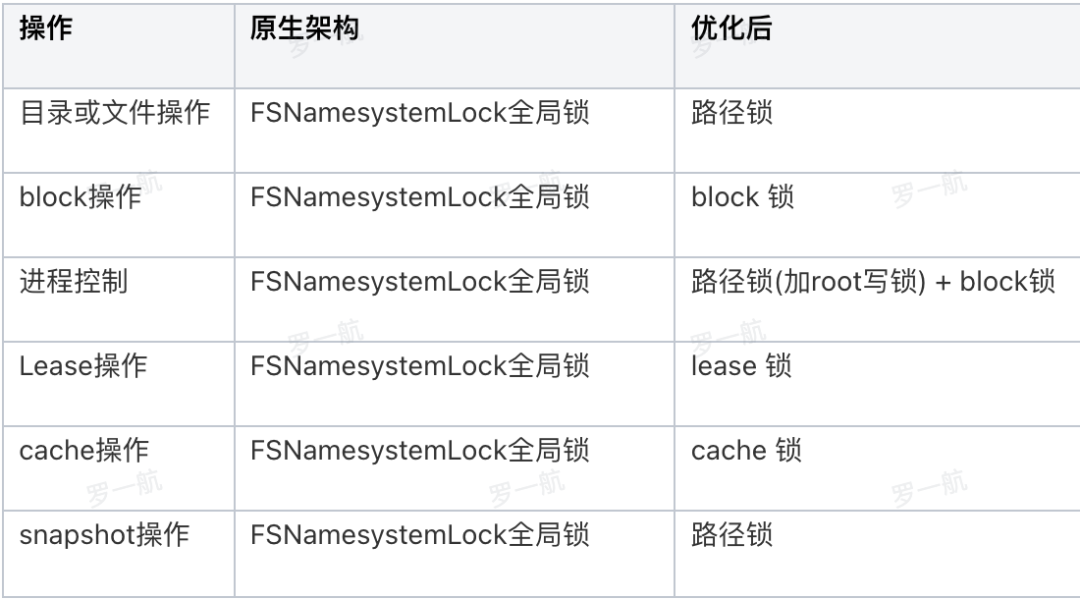
FSNamesystemLock主要管理集群的目录树、数据块以及节点信息,NameNode通过这把全局锁来控制并发读写。优点锁模型简单、外部依赖少,劣势是制约性能提升,尤其是集群规模和业务请求量增长,锁的持有范围和影响也越大。尽管社区也通过editlog异步化、DU请求采用分段锁等一系列措施来优化读写性能,但并未从根本上解决锁的影响,对于大规模集群难以满足生产场景。因此我们需要一套完善的拆锁方案
拆锁方案
定义分区写锁,不同文件归属于不同分区。写操作时先获取全局锁,然后找到对应分区获取分区锁,并释放全局锁。通过减少全局锁时间跨度,约提升25%写性能。
而我们在腾讯云TBDS产品中采用了树型锁,不仅针对写、也对读操作进行了更细粒度的锁拆分,可以更有效地提升读写性能。
自研拆锁的设计原则
- 锁用来保护数据,而非保护流程。
- 对于有transaction语义的流程,需要用单独的锁来保护,且尽量保证没有高耗时操作。
- 每个INode都用一把锁保护,操作该INode时需要加相应读写锁 更细粒度的锁替代FSNamesystemLock全局锁,详细参考:
图七
例如路径锁分配(蓝色为读锁,红色为写锁):
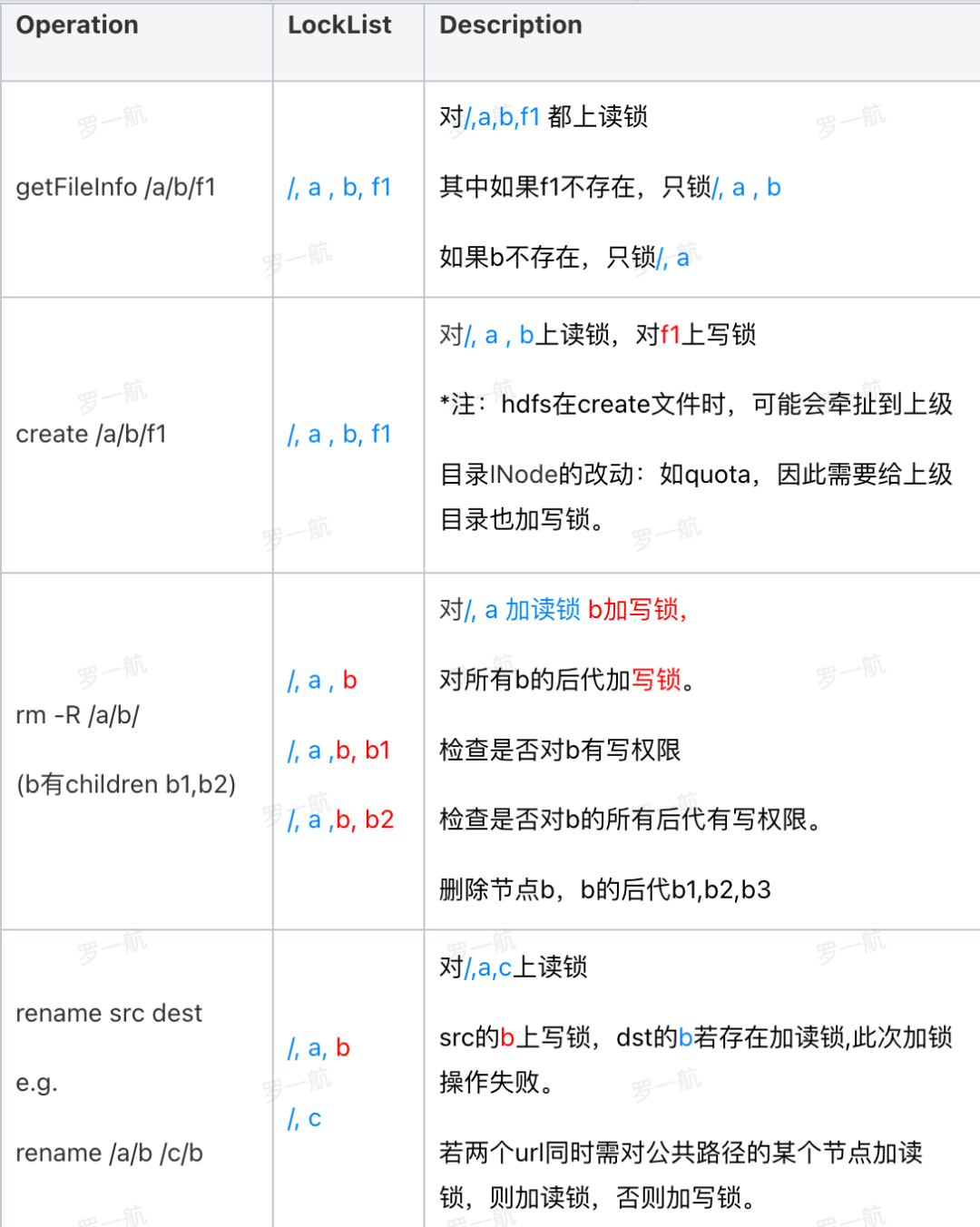
图八
若每个INode都一个INode lock,10亿INode(每个锁100B),预计占用90GB堆内存,易引发内存膨胀,因此我们在腾讯云TBDS产品中设计了LockPool避免锁对象空间浪费。
LockPool 的设计
据统计,非所有INode都会在短时间内被访问
1. 首先通过inodeid作为key在LockPool查找。
2. 若存在对应的key,refCount自增1,直接退出。
3. 若不存在,LockPool中创建一个lock实例。
4. 另单独的Evictor线程循环检查poolSize是否超过高水位,若没有则await等待signal或超时重新判断,若超过则进行evit操作,去除无用的lock,直至低水位。
拆锁效果
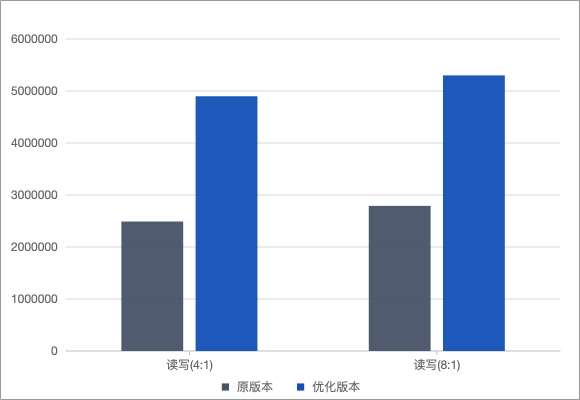
图九
分别在读写(4:1)和读写(8:1)的场景下进行测试,优化版本的性能约为原生架构的2倍。在客户现场上线优化版本后,RPC请求的平均延时从数百ms以上降低至10ms以内,请求队列中排队请求数从平均5000以上降低至100以内。
03、应急场景服务快速恢复
在真实的客户生产环境中,当偶发遇到机房断电、机器异常等极端紧急场景时,如何在这类应急场景中如何快速恢复服务显得尤为重要。尽管社区在最新的版本中已经做了大量的重启优化工作,但鉴于生产环境的稳定性和业务的适配性,客户的Hadoop集群也无法直接升级。我们通过分析HDFS重启机制,实现重启速度的合理优化。
HDFS重启速度主要受限于:
- NameNode串行加载fsimage;大规模集群下该文件可达几十G。
- 批量启动DataNode携带大量full block report,引发块汇报风暴,导致NameNode无响应。
- DataNode本身block数量多,加载block信息时间长。
组件重启速度优化方案
针对重启速度主要受限阶段,我们提供了如下的优化方案:
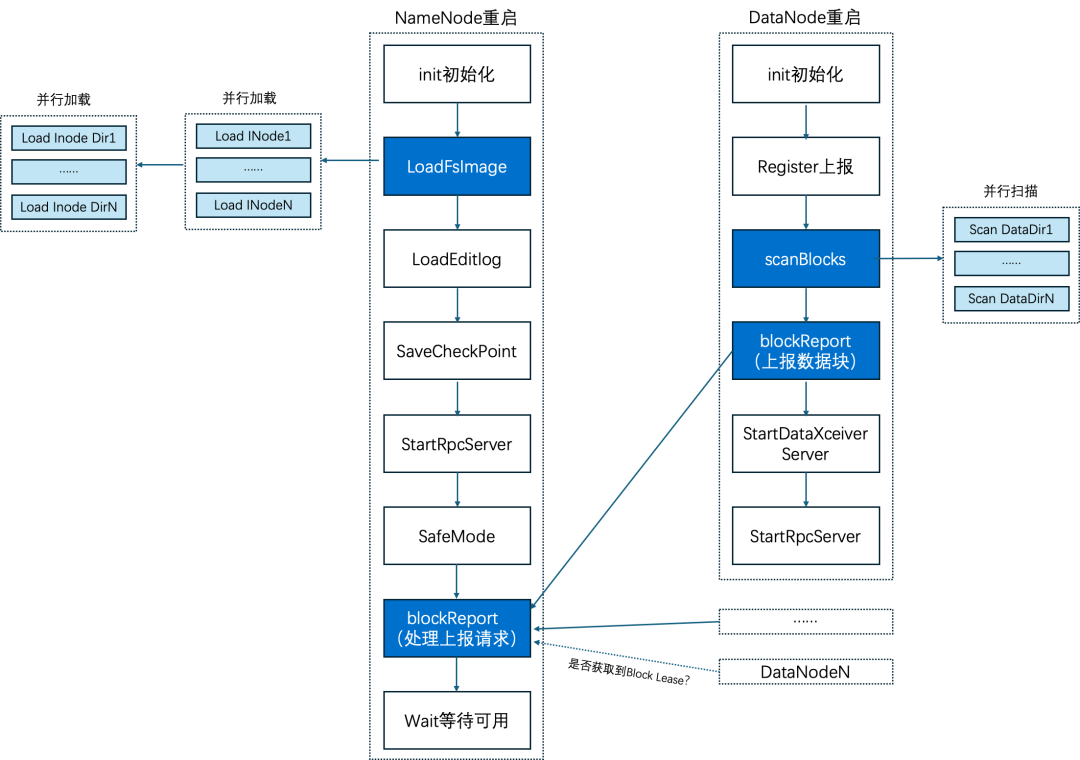
图十
1. 优化FsImage的加载方式,由串行改成并行
这是因为FsImage本身主要由INODE和INODE_DIR构成,而这两部分内部信息其实是完全独立的(分别记录目录树和父子节点间的信息关系)。可以直接将其进行拆分,形成INODE_SUB_SECTION和INODE_SUB_DIR_SECTION,设计多个线程分别消费不同的SUB_SECTION,实现并行快速加载。
2. 通过ForkJoinPool框架来并行加载block信息
DataNode的数据目录也是彼此独立的,基于线程池并行扫描数据目录实现快速加载block信息。
3. 引入Block Report Lease,避免DataNode集中式进行FBR
在BR Lease机制下,只有那些获得了NameNode所授予的BR Lease的DataNode节点,才能进行块汇报。Lease具有过期时间和分配数限制,从而可按需调整,限制FBR的总量。
基于上述这些优化,在现网应急场景机器恢复时间从数几小时可缩减至20分钟内。
04、客户实践
考虑到客户数据具有业务隔离性,具备新建集群的先天条件,且需要故障隔离和慢节点不影响全局的诉求。
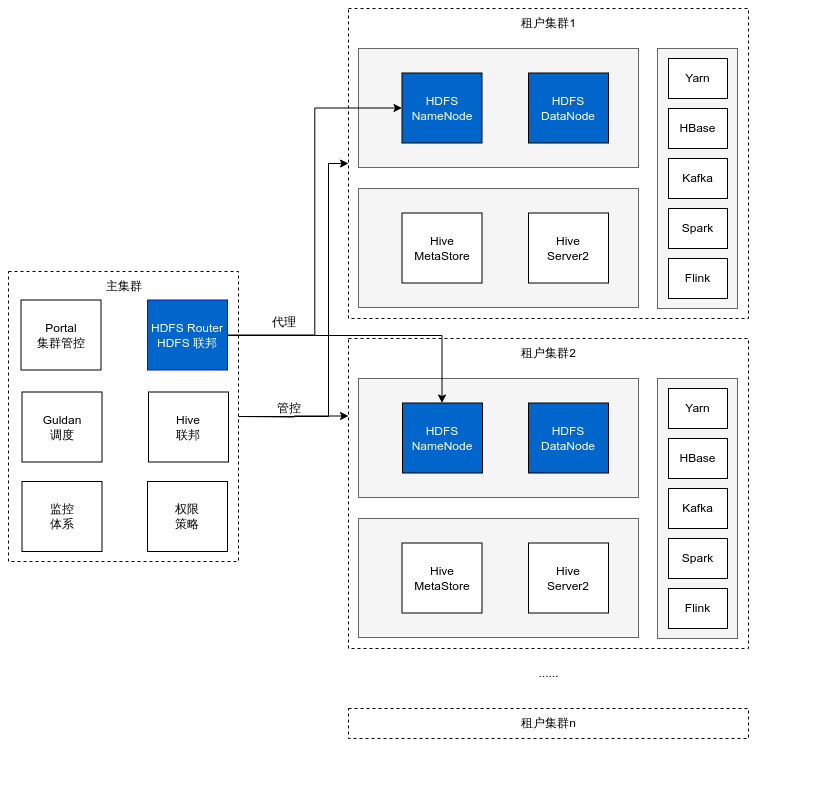
图十一
某国有大行采用我们NameNode拆锁优化版本HDFS搭建了多套租户TBDS集群,并基于多NameService独立集群联邦方案代理不同存储计算集群。该部署架构下不仅租户集群本身的读写性能得到成倍提升,并且集群规模和数据规模得到了极大拓展,累积元数据可达30亿+,对外的Router RPC请求仍能保持毫秒级响应。而在应急运维场景中,也能实现数十分钟级别内的服务快速恢复。
05、未来展望
腾讯云TBDS集群拓展性上支持Router按业务扩容,在确保提升集群整体的规模基础上且不损失性能。性能上可进一步优化HDFS NameNode的元数据存储,将元数据分解下沉至外部存储。也可针对DataNode本身全局锁进行拆分,从数据节点优化集群性能,综合考虑磁盘容量、处理线程数基于瞬时监控指标优化DataNode读调度。
未来更多的考虑存储成本和海量存储计算速度,全新一代数据湖仓一体化智能引擎TBDS可通过存算分离架构,将存储和计算独立分开部署,各自以分片的方式保证其自身的可扩展性。存储层可支持HDFS、标准对象存储等,基于统一的计算加速层为计算引擎提供服务。
06、参考
1️⃣https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-hdfs/Federation.html
2️⃣https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-hdfs-rbf/HDFSRouterFederation.html
(复制链接到浏览器打开)
关注腾讯云大数据公众号
邀您探索数据的无限可能

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号