如何设计一个分布式实时数据同步系统
原创
如何设计一个分布式实时数据同步系统
原创
用户6879030
发布于 2024-06-05 10:52:28
发布于 2024-06-05 10:52:28
- 可以直接看微信公众号文章:https://mp.weixin.qq.com/s/Sm5pM9iy9YN9S8vBQhRvlw
- 同时github上赏我一个star吧:https://github.com/mgtv-tech/redis-GunYu
- 也可以同时关注我微信公众号,有很多优质文章:【技术闲聊吧】
为什么要自研,使用开源方案不行吗?
我们调研了业界主流的几个工具,都有一些无法满足我们需求的地方,如redis-shake要求源redis和目的redis分片必须对称,不支持高可用,xpipe不支持拓扑变化等等。所以,我们自研了redis-GunYu来实现这些需求。
下面我们对比了这几个主流工具和redis-GunYu的差异:
功能点 | redis-shake/v2 | DTS(alibaba) | xpipe | redis-GunYu |
|---|---|---|---|---|
断点续传 | Y(无本地缓存) | Y | Y | Y |
支持分片不对称 | N | Y | N | Y |
拓扑变化 | N | N | N | Y |
高可用 | N | N | Y | Y |
数据一致性 | 最终 | 弱 | 弱 | 最终(分片对称) + 弱(不对称) |
redis-GunYu还有一些其他优化点,如
- 对稳定性影响更小
- 复制优先级:可用指定优先从从库进行复制或主库复制
- 对RDB中的大key进行拆分同步
- 数据安全性
- 本地缓存支持数据校验
- 对redis限制更少
- 支持源和目标端不同的redis部署方式
- 兼容源和目的redis不同版本
- 运维更加友好
- 数据过滤:可以对某些正则key,db,命令等进行过滤
- API:可以通过http API进行运维操作,如强制全量复制,同步状态,暂停同步等等
- 监控:监控指标更丰富,如时间与空间维度的复制延迟指标
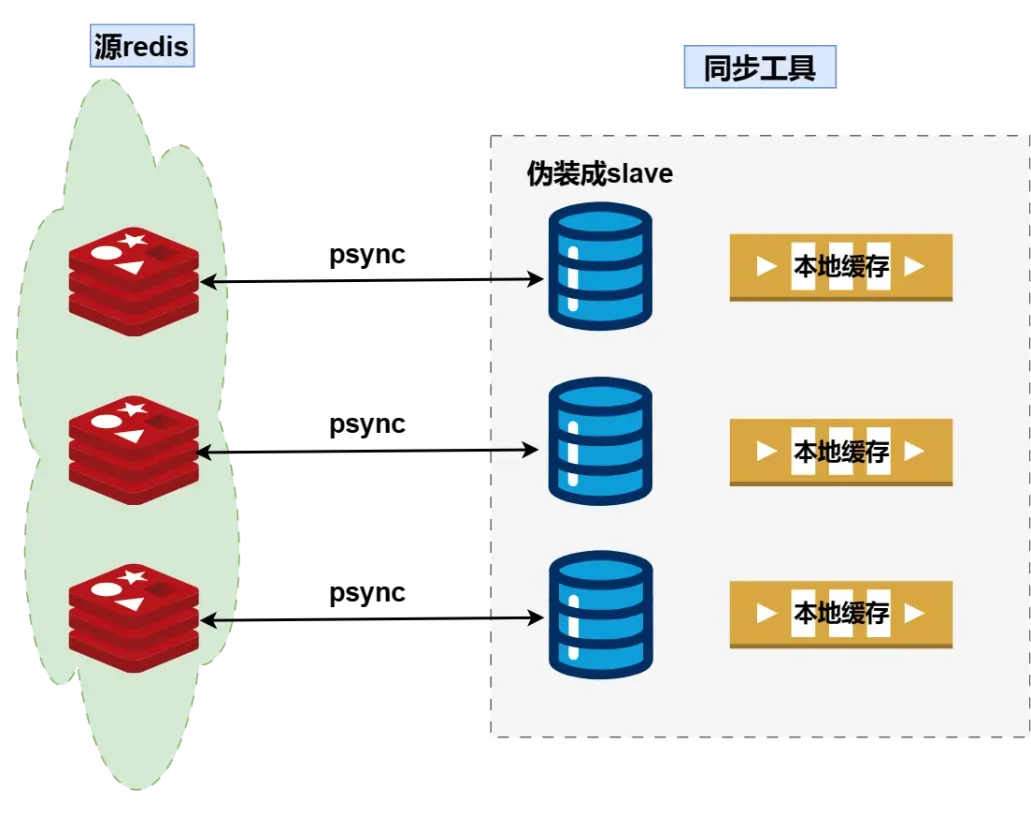
架构
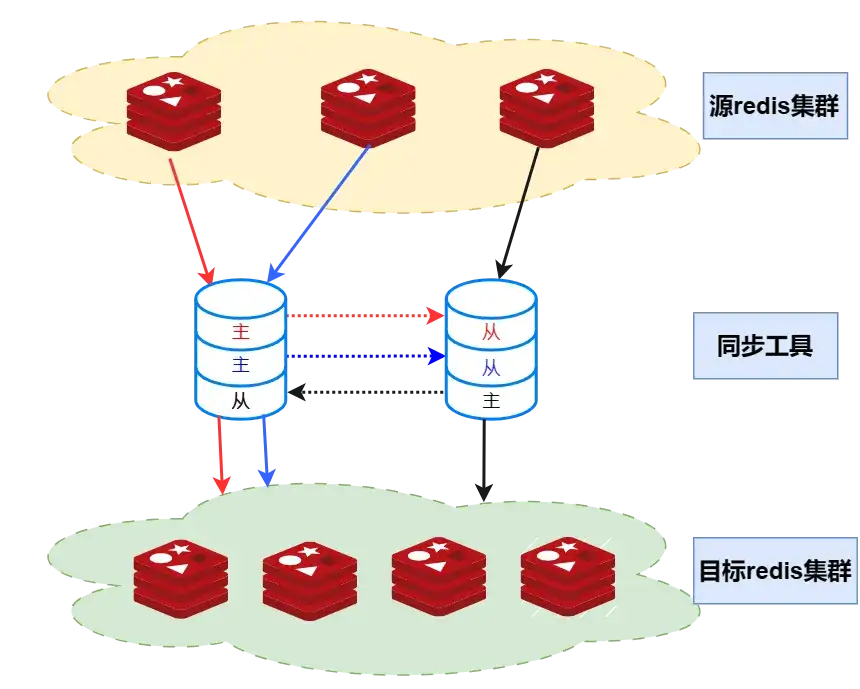
如上图所示,源redis集群有3个节点,目标redis集群是4个节点;同步工具集群由2个节点组成:
- 每个节点都会有3个同步模块(因为源redis有3个分片),互为主备,P2P对等结构,将工具故障带来的影响降到最低。
- 两个同步节点各自3个同步模块会独立进行选举,选出最新数据的节点为leader,其他节点为followers,followers从leader同步数据;如果leader节点故障,则最新数据的follower选举成为leader。
同步模块的内部实现
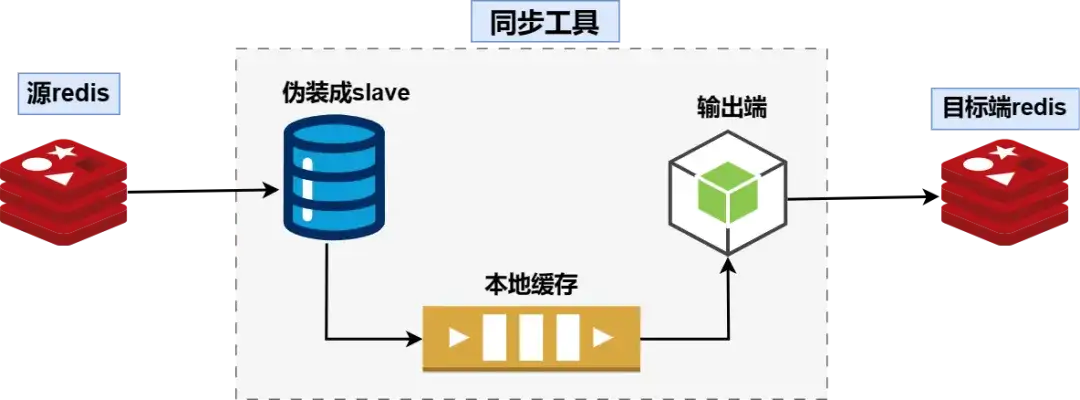
每个同步模块都分如下三个子模块
- 输入端:伪装成redis slave,从源redis节点(主节点或从节点)同步数据
- 通道端:即本地缓存,缓存RDB和AOF数据
- 输出端:从本地缓存读取数据写入到目标端redis主库
输入端和输出端暂时只支持redis,后续会扩展到消息队列、对象存储和数据库
集群
高可用
我们希望同步工具本身是高可用的,一个节点故障,其他节点可以接管其任务,继续提供服务。 同时,针对每个源redis节点,必须保证只有一个节点进行数据同步,否则数据就可能不一致,所以要选举出一个节点为leader,只有leader才能同步数据。 在分布式系统中,选举的实现通常分为两种
- 协商式:
- 最新数据投票
- 适用于有状态服务
- 选举时间长
- 抢占式:
- 先到先服务
- 适用于无状态服务
- 选举时间短
然而redis同步工具的选举有自己的特点
- 半状态化:有状态(缓存数据),但数据并不重要
- 选举时间:越快越好
那么redis-GunYu该用哪种方式呢?
我们结合了两种实现方式,对其优缺点进行了取舍。如下图,有3个同步节点组成一个集群,同时依赖etcd集群辅助进行选举。
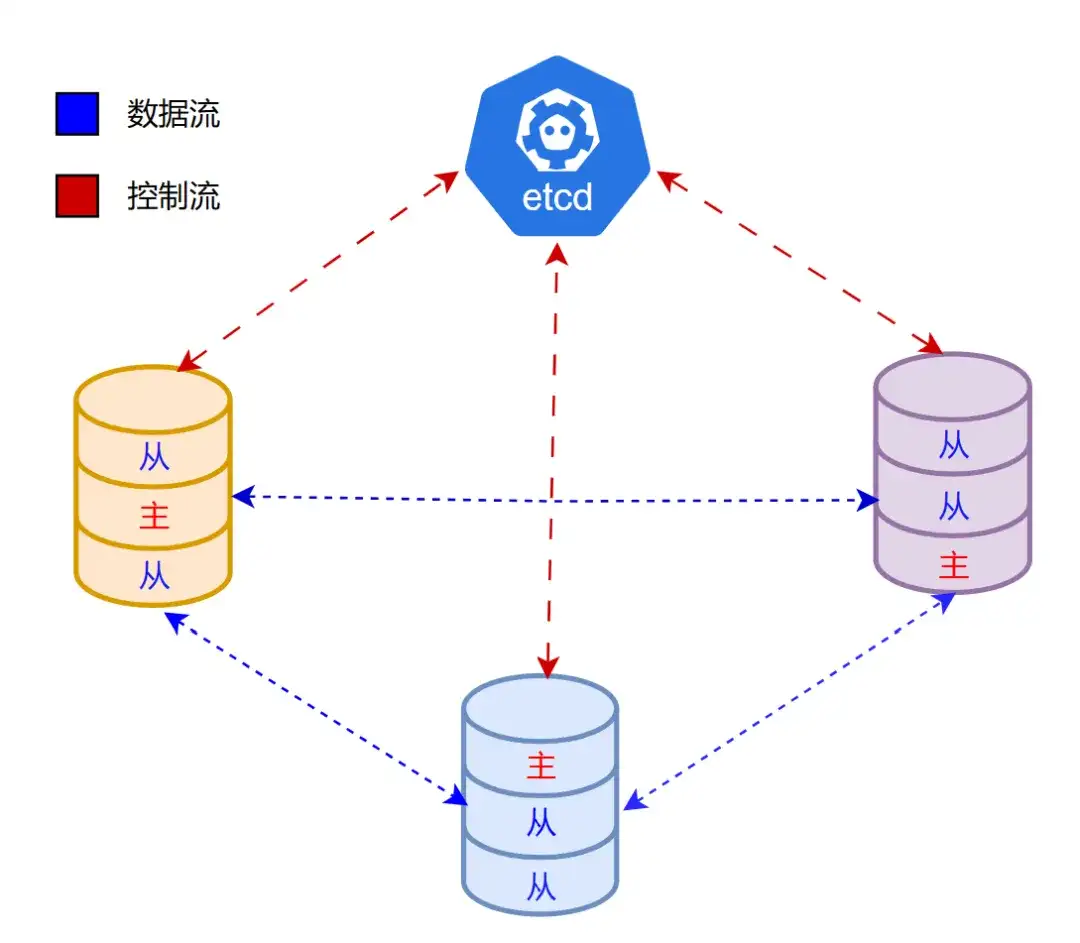
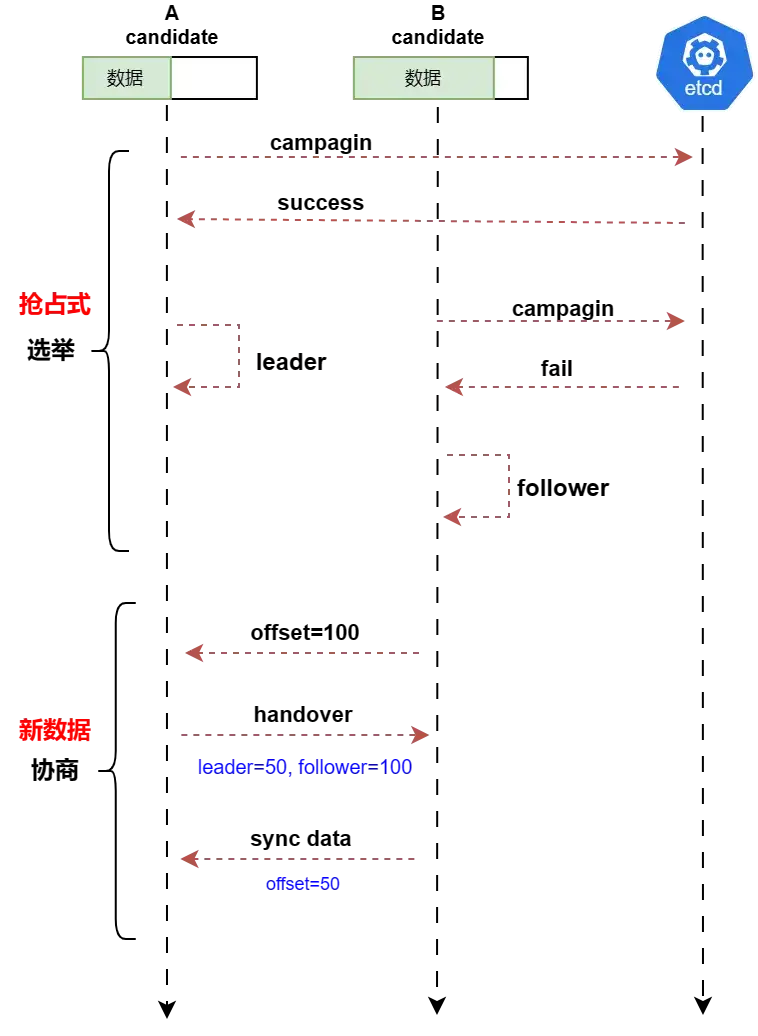
如果1个节点故障,那么其他2个节点会进入选举流程,如下图,A先发起竞选,所以A成功了,A暂时成为领导者(leader),但B以跟随者(follower)身份连接到leader后,leader检查到B的数据更新,则会将领导权移交给节点B。
为什么要这么设计呢?
我们先思考下几个问题:
- 同步工具主从节点之间的数据延迟有多大?
- 是快速继续服务重要还是最新数据重要?
- 1秒钟能从redis源端同步多少数据?
先进行抢占式选举:
- 能够减少选举时间,快速选出leader
- 同步工具主从延迟很低;就算抢占式选举出的leader数据不是最新的,由于同步的速度非常快,也会马上追上最新源端数据
再以数据新旧进行协商:
- 如果选出的leader数据落后很多,那么其他拥有更新数据的节点连接到leader后,leader会将领导权移交给最新数据的follower。所以如果新leader无法在瞬间追上源redis节点的数据,也会被其他节点抢夺leader权,这样就降低了源和目的redis数据差异
关于脑裂
试想一下,如果执行一条INCR操作,存在两个leader,那么这条操作就会被执行两次。还有更极端的情况,如下图所示,针对同一个key做SET、DEL、SET操作,如果两个leader,那么可能一个先执行了,另一个leader执行到DEL就退出了,那么这个key就被永远删除了。所以,要避免同时存在两个leader的情况发生。
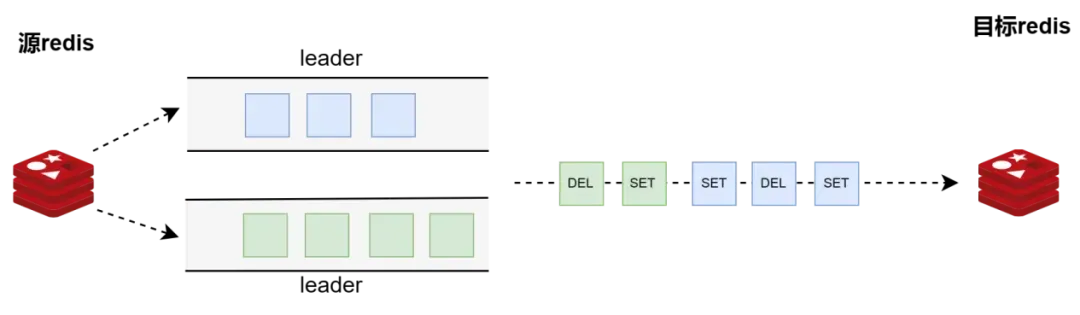
在实现上,每个leader都有一个租期,leader要定期去etcd续租,否则,租期就会过期,即失去领导权。 如下图,租期为3秒,则每隔1秒续租一次,如果失败重试一次,再失败则租期失效,集群重新进入选举状态。

拓扑感知
在实际生产环境中,会对redis cluster进行扩容、缩容、槽位迁移、主从切换等操作,这些操作都会导致拓扑结构的变化,而我们要感知到这些变化以更改同步的策略,下面几种情况需要调整策略:
- 如前面所讲,每一个源redis节点,都会有一个对应的同步模块,扩容、缩容都会增加redis节点,那么同步模块就要相应增加或减少
- 如果用户指定从源redis集群的主节点进行同步,主从切换后,我们要能够切换到新主节点上。
- 我们的一致性策略是和拓扑相关的,如果拓扑结构变化,要检查是否需要切换一致性策略。
本地缓存
先看看本地缓存的几个需求
- 数据管理
- RDB和AOF数据的管理
- 读写RDB和AOF数据
- 超过容量限制,回收缓存数据
- 数据监控
- 读、写监控指标
- 数据安全
- 数据校验
- 损坏数据处理
- 数据持久化策略
缓存数据的组织
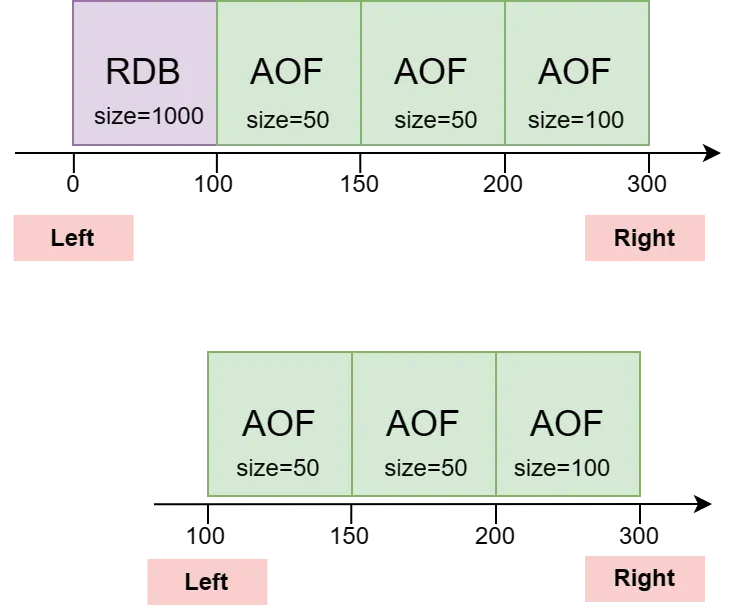
每一个同步模块都对应一个缓存管道,管道由RDB和AOF有序地排列组成。实现中,用[left, right)区间来描述管道的数据范围,left表示最老数据,right表示最新数据;每个AOF和RDB都有自己的left和right来表示其所拥有的数据范围。AOF的left是AOF文件数据的起始偏移量(对应源redis节点的数据偏移),right等于left+AOF大小RDB比较特殊,left表示为0,right表示redis创建RDB文件时的当前快照偏移量。
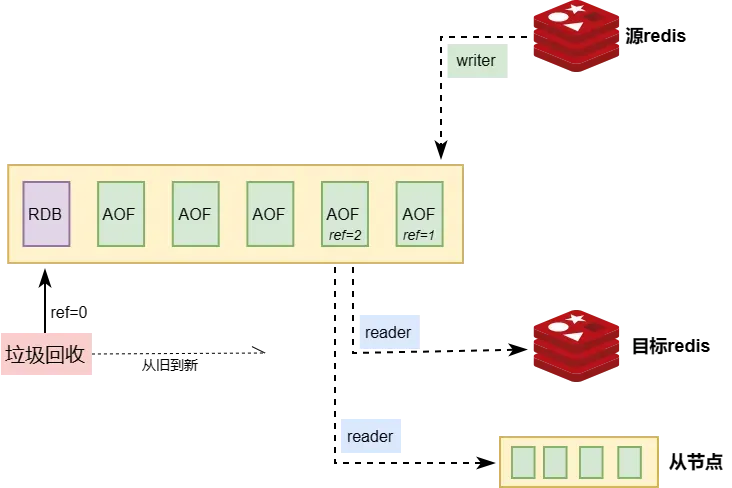
垃圾回收与读写
如果缓存数据量超过最大限制的阈值,则会触发垃圾回收,删除掉较老的RDB或AOF,将缓存数据量降低到阈值之下。redis-GunYu会优先回收老数据,但如果数据文件有被引用(正在读写),则停止回收,等待引用为0再启动回收。
持久化策略
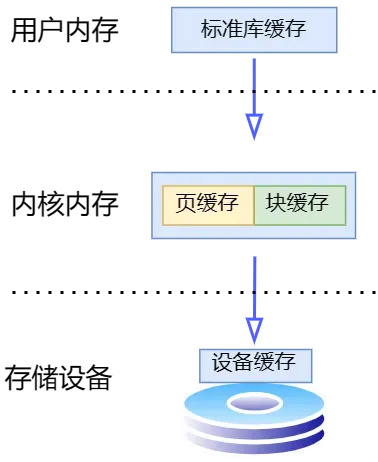
一个IO操作的IO栈是非常深的,从用户态到内核态,再到设备本身,都要经过一层层的缓存,每一个缓存都可能在程序崩溃、OS故障、机器断电等异常情况下丢失数据。而缓存的存在又是架构抽象和设备管理的必然产物,正如名言***“计算机科学中的所有问题都可以通过增加一个间接层来解决”***说的一样。\
下图展示了一个IO操作要经过的缓存(页缓存和块缓存物理上是指向同一内存的)。为了提高读写性能,缓存有自己的持久化策略,不会因为用户每次调用write都会将数据写入到磁盘,否则对于写操作来说,就会造成严重的写放大。例如内存页大小是8KB,而我们一条命令的大小可能是10B,如果写入10B的数据,马上就持久化到磁盘,就会实际造成8KB数据的写入,带来了严重的写放大,增加了写入延迟,同时也会缩短磁盘使用寿命。所以,我们要在性能和数据安全上做取舍,不能每次有数据写入都进行持久化。而对于缓存数据,真正造成丢失了也没有太大问题,重新从redis同步就可以了,只是会增加全量同步的风险。\
所以我们支持几种持久化策略,由用户自己选择:
- 由操作系统决定
- 定时持久化和脏数据大小满足一个条件即持久化
- 每次写入都持久化
数据校验
任何存储数据的设备都可能有损坏或故障的可能,如磁盘坏块,内存位翻转等等,所以我们需要对数据进行校验,以确保不会将错误的数据回放到目标端。如果CRC校验失败,则会丢弃本地缓存,重新从源端redis同步最新数据。
输入端
输入端模块会伪装成redis 从库(slave),通过RESP协议从源redis节点同步数据。
为了支持断点续传,所以要记录已经同步数据的位置(称为偏移量, offset),下次启动同步流程,则接着上次已同步的位置继续同步。
而这个同步位置,记录在目标redis节点上,每次启动要从目标redis获取偏移量,然后和本地缓存进行比较,具体比较过程如下:

- 如果 目标offset < 本地缓存最老数据(left) :丢弃本地缓存,使用目标端偏移量进行同步
- 如果 本地缓存最老数据(left) < 目标offset < 本地缓存最新数据(right) :使用本地缓存最新偏移量进行同步
- 如果 本地缓存最新数据(right) < 目标offset :丢弃本地缓存,使用目标端偏移量进行同步
实际情况要复杂一些,需要考虑一些其他因素,如同步偏移量是否在源端reids的缓存区,复制ID变化问题,本地缓存数据与目标端redis数据的间隔过大,本地缓存垃圾回收等问题。
输出端
输出端分为三个步骤,解析RDB和AOF数据、处理数据、回放数据到目标端redis。
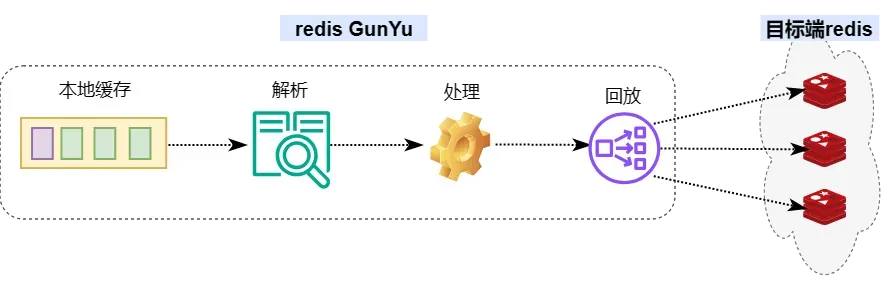
数据解析
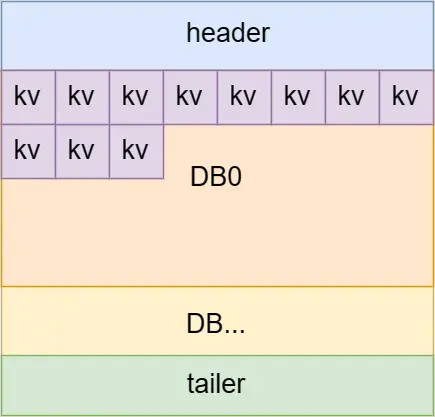
RDB数据格式 :
RDB数据布局如下图,
- 头部区域描述魔数,版本等
- 接下来是每个DB的key value分布
- 最后是尾部,用来记录CRC值
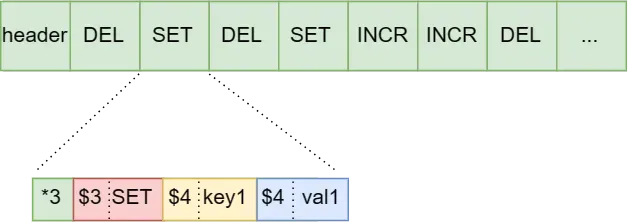
AOF数据格式
AOF类似数据库的WAL(write append log)文件,由一个个操作日志组成,每个日志按照类似TLV方式进行编码(type length value)。
第一个字符是类型,再是数据大小,最后是数据本身。
如下图SET操作日志
- *表示数组,3表示有3个元素
- \$表示字符串,3表示字符串长度
所以这条日志是描述一个数组,有3个元素,分别表示为SET、key1、val1。
数据处理
数据处理主要对数据进行过滤,替换,如
- 按照命令过滤
- 按照前缀key过滤
- 过滤特殊命令:如过滤cluster,flushdb等命令(slot不对称flushdb不应该进行回放)
后面还会支持插件这种更为灵活的处理方式。
数据回放
数据回放是最为复杂的(将数据回写到目标端redis集群),要考虑的点非常多
- 如何保证一致性?
- 如何优化回放性能?
- 如何批量进行回放
- 以什么方式将数据回放到目标端redis
- 大key怎么回放
如何保证一致性
当源和目的redis集群的槽位对称时,每个目标redis节点都会维护一个单独的偏移量,分别记录源redis节点的数据偏移量;redis-GunYu将AOF命令和偏移量更新一起打包发送到目标端,这样保证数据一致性。下图中每个同步模块从自己的缓存队列中读取AOF数据,然后打包发送到目标端(图中红色方块为更新偏移量信息,绿色方块是AOF数据)。
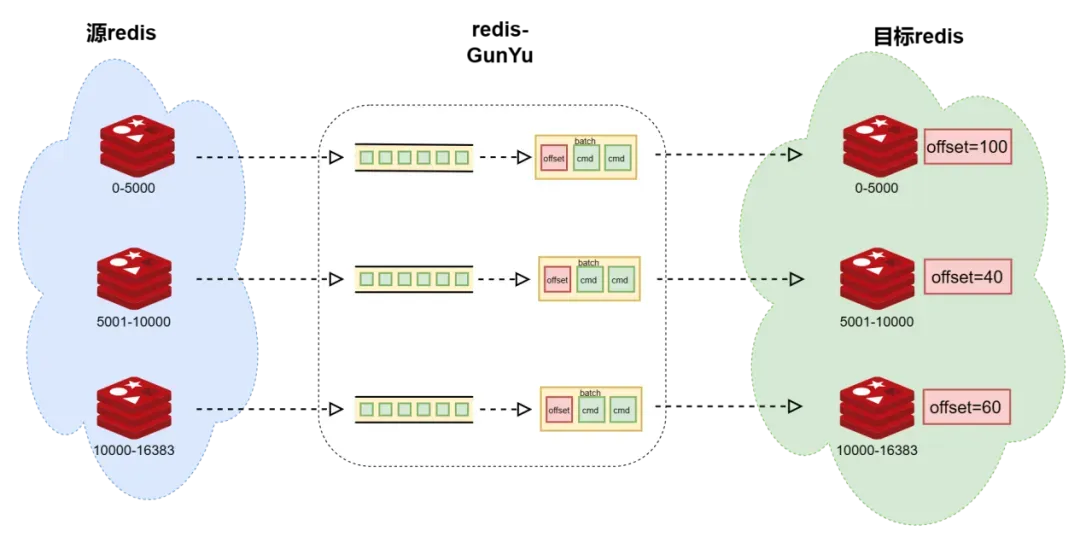
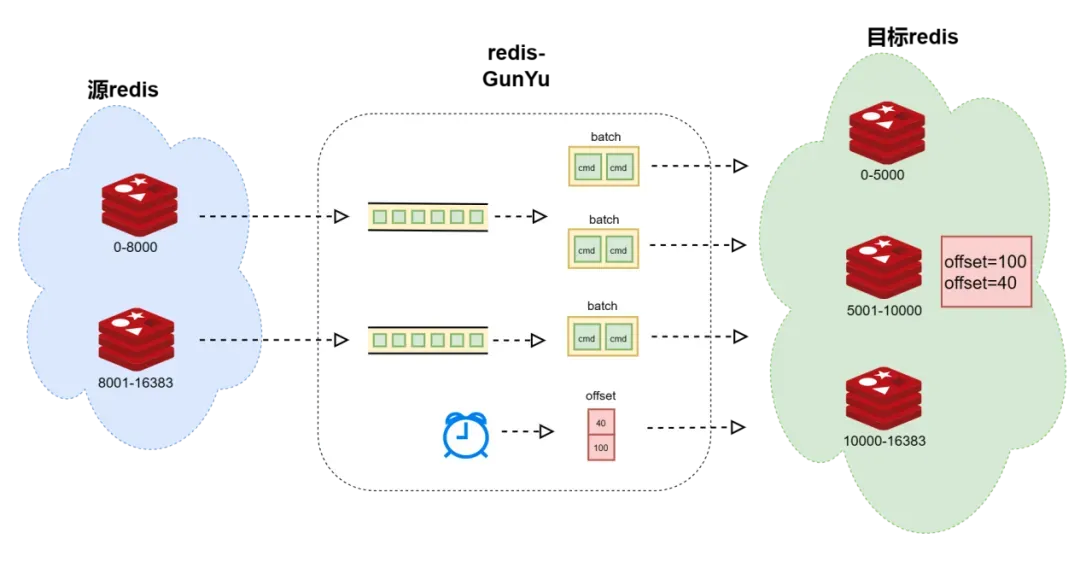
当源和目的redis集群的槽位不对称时,整个目标redis集群维护一个偏移量,包含源redis节点的数据偏移量;
将发往同一个目标redis节点的命令打包一起发送,而偏移量则定期更新。
所以,如果同步程序崩溃,则有可能导致多回放数据,对于非类幂等操作则会导致数据不一致;当然正常退出是不会有这种问题的。
实际情况还考虑了一些其他场景,如偏移更新时机,回放性能,重定向和错误处理等等。
如何提高回放性能
我们希望在保证数据一致性的前提下,尽可能地提高回放性能,所以会对数据进行并发回放,同时也如前面所讲,会进行打包发送,在回放性能和低延迟之间进行平衡。
- 对于RDB,数据之间是没有依赖关系的,则可以并发回放数据
- 而AOF的操作日志,数据之间会有依赖关系,无法进行并发回放,必须保证回放的有序性。但是我们可以将其打包,一起发送到目标端,以减少网络传输带来的消耗。打包发送同时考虑打包策略,打包多少命令,打包命令的时间跨度,字节数,同时要考虑和偏移更新、事务的处理要保持兼容。不同的业务对延迟的敏感程度不一样,所以这些都要求可配置,以满足不同需求。
这是逻辑上的一些优化,同时还有一些语言机制的优化,如缓存的复用,锁的优化等。
如何进行回放
对于RDB数据的回放,我们会优先尝试使用restore命令进行回放,这样可以确保较好地性能,restore回放失败再尝试拆分成redis命令地形式进行回放。但有些情况例外,需要将数据结构拆分成命令形式进行回放,如
- 某些特殊数据结构,如FUNCTION
- 源和目标redis版本不一致,对于某些数据结构不兼容
- 数据结构太大
这块的处理是比较繁琐的,每个数据结构都要支持拆分成非restore命令进行回放,还要考虑源和目的版本,不同版本之间的命令兼容性等等。
可观测性
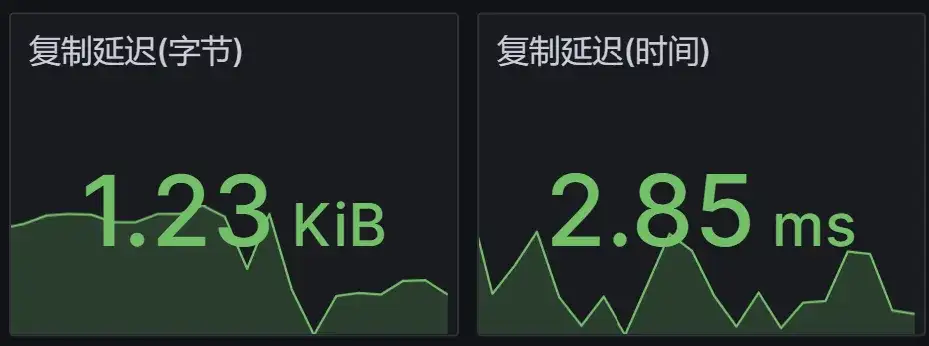
回放模块的可观测性也比较丰富,需要监控命令的数量、打包指标、失败指标、发送偏移、ack偏移,以及时间和空间上的同步延迟。若配置文件启用了时间同步延迟,则会在源redis端写入一个特殊的key,然后回放模块会检测到这个key,发送前会计算时间差以表示回放延迟,这样,通过监控就能看出源和目标redis集群的数据延迟。 下图为空间和时间上的同步延迟指标
最后
本文中,我们自顶向下了解了redis-GunYu实时同步工具的实现原理,如何摄取数据,缓存数据,处理数据,再到回放数据,以及工具本身的高可用实现。redis-GunYu还有很多需要完善、优化的地方,欢迎大家提交issue和PR。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号