小白用自己游戏本训练方言分类AI识别模型


笔记本型号是Redmi G2021,配置还凑活,5800H,16G, 3050Ti Laptop(4G VRAM),相当一般的配置啦!不过自从英伟达更新了驱动,可以实现RAM充当显存,可训练以及使用的模型就多了很多啦,当然这种类似swap的方式性能还是有点损失的。不过,总比运行不起来强多啦!
数据准备
话说想做这件事许久啦,有时很好奇别人讲的是哪里话,又不好意思问?就萌生了个训练方言识别是哪里人的想法,当然,相比方言意思识别简单超多的还是。这里还是佩服国家队的中国电信,开源了30种方言的大语言模型。于是,我也决定利用开放的数据集训练个分类模型玩玩。
本来想用R-Torch的,发现自己处理的操作太多啦,主要是R语言深度学习真的不是主流。不小心发现了一个开箱即用的,于是,折腾起来:yeyupiaoling/AudioClassification-Pytorch
代码准备
就严格按照作者的python版本等进行的,没有例外,开源软件的版本兼容是令人一言难尽的,所以,能一致尽量完全一致!我是win11,不过git这种操作用的是WSL2进行的。我一般用WSL2操作windows下的目录,这样读写性能损失超多,只是不想文件删除后还不能释放空间(WSL2是个特殊虚拟机)
# 软件安装
conda create -n python=3.8
# pytorch等
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
# mcls
python -m pip install macls -U -i https://pypi.tuna.tsinghua.edu.cn/simple
# 用的repo
git clone https://github.com/yeyupiaoling/AudioClassification-Pytorch.git
cd AudioClassification-Pytorch/
pip install .
# 齐活!
数据下载
经过选择,最终是用了这个KeSpeech,不过后面发现,我直接用的这个repo也是有个方言数据集3dspeaker_data可用的。不过下载一个已经用去几百G的空间,不想再下第二个啦!另外,碍于电脑配置,也用不了那么多数据,这里我还从里面节选了几分之一做训练呢!
测试和训练集的截取划分
我的数据准备过程比较傻瓜,直接用最基本的AI辅助编码写了两个脚本实现的,简单的说就是读取两个文本文件内容,建立两个字典,然后匹配,抽取前1200条数据,生成训练集,再抽取200多用于测试集。明显数据是偏少的。
# every class first 1000
i = 0
dic = {}
fout = open('D:/Projects/dialect/KeSpeech/Metadata/train_audio_path', 'w')
with open('D:/Projects/dialect/KeSpeech/Metadata/phase1.utt2subdialect', 'r') as f:
for line in f:
dialect = line.split('\t')[1]
if dialect not in dic.keys():
dic[dialect] = 1
else:
dic[dialect] += 1
if dic[dialect] > 250 and dic[dialect] <1200:
fout.write(line)
fout.close()
dic_file = dict()
with open('D:/Projects/dialect/KeSpeech/file.txt') as f1:
for line in f1:
if line.endswith('wav\n'):
fi = line.strip().split('/')[3]
dic_file[fi] = line.strip()
# print(fi,dic_file[fi])
# 训练和测试集一个脚本生成的,改了下名字,按说该整个函数的
fout2 = open('D:/Projects/dialect/KeSpeech/Metadata/test_list.txt', 'a')
with open('D:/Projects/dialect/KeSpeech/Metadata/test_audio_path', 'r') as f2:
for line in f2:
file_name = line.split('\t')[0] + '.wav'
if file_name in dic_file.keys():
fout2.write(dic_file[file_name]+'\t' + line.strip().split('\t')[1] +'\n')
else:
print(file_name)
# break
fout2.close()
# label file生成
labels_dict = {0: 'Mandarin', 3: 'Northeastern', 2: 'Jiang-Huai',
3: 'Southwestern', 4: 'Jiao-Liao', 5: 'Beijing', 6: 'Zhongyuan',
7: 'Ji-Lu', 8: 'Lan-Yin'}
with open('D:/Projects/dialect/AudioClassification-Pytorch/dataset/label_list.txt', 'w', encoding='utf-8') as f:
for i in range(len(labels_dict)):
f.write(f'{labels_dict[i]}\n')
这里还对标签做了替换,因为标签只能是数字。
sed -i s/'Mandarin'/0/g test_list.txt
sed -i s/'Northeastern'/1/g test_list.txt
sed -i s/'Mandarin'/0/g s/'Northeastern'/1/g s/'Jiang-Huai'/2/g test_list.txt
sed -i s/'Jiang-Huai'/2/g test_list.txt
sed -i s/'Southwestern'/3/g test_list.txt
sed -i s/'Jiao-Liao'/4/g test_list.txt
sed -i s/'Beijing'/5/g test_list.txt
sed -i s/'Zhongyuan'/6/g test_list.txt
sed -i s/'Ji-Lu'/7/g test_list.txt
sed -i s/'Lan-Yin'/8/g test_list.txt
完成这些,把文件放入新建的dataset文件夹,就可以愉快地训练啦,可以断点续训练的哦!点赞!
训练
特征提取
这是第一步,耗时并不多python extract_features.py --configs=configs/cam++.yml --save_dir=dataset/features
漫长的训练
前后大概花了三天时间,每个两到三个小时的样子。也是一条命令的事!python train.py
评估效果
虽然初次训练结果不好,至少,成功获得了人生第一个语音分类模型,还是极开心的,感谢作者!
python eval.py --configs=configs/cam++.yml
[2024-06-05 20:41:03.545426 INFO ] utils:print_arguments:14 - ----------- 额外配置参数 -----------
[2024-06-05 20:41:03.545426 INFO ] utils:print_arguments:16 - configs: configs/cam++.yml
[2024-06-05 20:41:03.545426 INFO ] utils:print_arguments:16 - resume_model: models/CAMPPlus_Fbank/best_model/
[2024-06-05 20:41:03.545426 INFO ] utils:print_arguments:16 - save_matrix_path: output/images/
[2024-06-05 20:41:03.545426 INFO ] utils:print_arguments:16 - use_gpu: True
[2024-06-05 20:41:03.545426 INFO ] utils:print_arguments:17 - ------------------------------------------------
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:19 - ----------- 配置文件参数 -----------
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:22 - dataset_conf:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:25 - aug_conf:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - noise_aug_prob: 0.2
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - noise_dir: dataset/noise
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - speed_perturb: True
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - volume_aug_prob: 0.2
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - volume_perturb: False
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:25 - dataLoader:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - batch_size: 39
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - drop_last: True
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - num_workers: 4
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - do_vad: False
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:25 - eval_conf:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - batch_size: 39
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - max_duration: 10
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - label_list_path: dataset/label_list.txt
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - max_duration: 3
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - min_duration: 0.5
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - sample_rate: 16000
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:25 - spec_aug_args:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - freq_mask_width: [0, 8]
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - time_mask_width: [0, 10]
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - target_dB: -20
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - test_list: dataset/test_list.txt
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - train_list: dataset/train_list.txt
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - use_dB_normalization: True
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - use_spec_aug: True
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:22 - model_conf:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - num_class: None
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:22 - optimizer_conf:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - learning_rate: 0.001
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - optimizer: Adam
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - scheduler: WarmupCosineSchedulerLR
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:25 - scheduler_args:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - max_lr: 0.001
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - min_lr: 1e-05
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - warmup_epoch: 5
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - weight_decay: 1e-06
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:22 - preprocess_conf:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - feature_method: Fbank
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:25 - method_args:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - num_mel_bins: 80
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:27 - sample_frequency: 16000
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:22 - train_conf:
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - enable_amp: False
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - log_interval: 10
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - loss_weight: None
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - max_epoch: 60
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:29 - use_compile: False
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:31 - use_model: CAMPPlus
[2024-06-05 20:41:03.576924 INFO ] utils:print_arguments:32 - ------------------------------------------------
[2024-06-05 20:41:03.576924 WARNING] trainer:__init__:74 - Windows系统不支持多线程读取数据,已自动关闭!
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
CAMPPlus [1, 9] --
├─FCM: 1-1 [1, 320, 98] --
│ └─Conv2d: 2-1 [1, 32, 80, 98] 288
│ └─BatchNorm2d: 2-2 [1, 32, 80, 98] 64
│ └─Sequential: 2-3 [1, 32, 40, 98] --
│ │ └─BasicResBlock: 3-1 [1, 32, 40, 98] 19,648
│ │ └─BasicResBlock: 3-2 [1, 32, 40, 98] 18,560
│ └─Sequential: 2-4 [1, 32, 20, 98] --
│ │ └─BasicResBlock: 3-3 [1, 32, 20, 98] 19,648
│ │ └─BasicResBlock: 3-4 [1, 32, 20, 98] 18,560
│ └─Conv2d: 2-5 [1, 32, 10, 98] 9,216
│ └─BatchNorm2d: 2-6 [1, 32, 10, 98] 64
├─Sequential: 1-2 [1, 512] --
│ └─TDNNLayer: 2-7 [1, 128, 49] --
│ │ └─Conv1d: 3-5 [1, 128, 49] 204,800
│ │ └─Sequential: 3-6 [1, 128, 49] 256
│ └─CAMDenseTDNNBlock: 2-8 [1, 512, 49] --
│ │ └─CAMDenseTDNNLayer: 3-7 [1, 32, 49] 39,520
│ │ └─CAMDenseTDNNLayer: 3-8 [1, 32, 49] 43,680
│ │ └─CAMDenseTDNNLayer: 3-9 [1, 32, 49] 47,840
│ │ └─CAMDenseTDNNLayer: 3-10 [1, 32, 49] 52,000
│ │ └─CAMDenseTDNNLayer: 3-11 [1, 32, 49] 56,160
│ │ └─CAMDenseTDNNLayer: 3-12 [1, 32, 49] 60,320
│ │ └─CAMDenseTDNNLayer: 3-13 [1, 32, 49] 64,480
│ │ └─CAMDenseTDNNLayer: 3-14 [1, 32, 49] 68,640
│ │ └─CAMDenseTDNNLayer: 3-15 [1, 32, 49] 72,800
│ │ └─CAMDenseTDNNLayer: 3-16 [1, 32, 49] 76,960
│ │ └─CAMDenseTDNNLayer: 3-17 [1, 32, 49] 81,120
│ │ └─CAMDenseTDNNLayer: 3-18 [1, 32, 49] 85,280
│ └─TransitLayer: 2-9 [1, 256, 49] --
│ │ └─Sequential: 3-19 [1, 512, 49] 1,024
│ │ └─Conv1d: 3-20 [1, 256, 49] 131,072
│ └─CAMDenseTDNNBlock: 2-10 [1, 1024, 49] --
│ │ └─CAMDenseTDNNLayer: 3-21 [1, 32, 49] 56,160
│ │ └─CAMDenseTDNNLayer: 3-22 [1, 32, 49] 60,320
│ │ └─CAMDenseTDNNLayer: 3-23 [1, 32, 49] 64,480
│ │ └─CAMDenseTDNNLayer: 3-24 [1, 32, 49] 68,640
│ │ └─CAMDenseTDNNLayer: 3-25 [1, 32, 49] 72,800
│ │ └─CAMDenseTDNNLayer: 3-26 [1, 32, 49] 76,960
│ │ └─CAMDenseTDNNLayer: 3-27 [1, 32, 49] 81,120
│ │ └─CAMDenseTDNNLayer: 3-28 [1, 32, 49] 85,280
│ │ └─CAMDenseTDNNLayer: 3-29 [1, 32, 49] 89,440
│ │ └─CAMDenseTDNNLayer: 3-30 [1, 32, 49] 93,600
│ │ └─CAMDenseTDNNLayer: 3-31 [1, 32, 49] 97,760
│ │ └─CAMDenseTDNNLayer: 3-32 [1, 32, 49] 101,920
│ │ └─CAMDenseTDNNLayer: 3-33 [1, 32, 49] 106,080
│ │ └─CAMDenseTDNNLayer: 3-34 [1, 32, 49] 110,240
│ │ └─CAMDenseTDNNLayer: 3-35 [1, 32, 49] 114,400
│ │ └─CAMDenseTDNNLayer: 3-36 [1, 32, 49] 118,560
│ │ └─CAMDenseTDNNLayer: 3-37 [1, 32, 49] 122,720
│ │ └─CAMDenseTDNNLayer: 3-38 [1, 32, 49] 126,880
│ │ └─CAMDenseTDNNLayer: 3-39 [1, 32, 49] 131,040
│ │ └─CAMDenseTDNNLayer: 3-40 [1, 32, 49] 135,200
│ │ └─CAMDenseTDNNLayer: 3-41 [1, 32, 49] 139,360
│ │ └─CAMDenseTDNNLayer: 3-42 [1, 32, 49] 143,520
│ │ └─CAMDenseTDNNLayer: 3-43 [1, 32, 49] 147,680
│ │ └─CAMDenseTDNNLayer: 3-44 [1, 32, 49] 151,840
│ └─TransitLayer: 2-11 [1, 512, 49] --
│ │ └─Sequential: 3-45 [1, 1024, 49] 2,048
│ │ └─Conv1d: 3-46 [1, 512, 49] 524,288
│ └─CAMDenseTDNNBlock: 2-12 [1, 1024, 49] --
│ │ └─CAMDenseTDNNLayer: 3-47 [1, 32, 49] 89,440
│ │ └─CAMDenseTDNNLayer: 3-48 [1, 32, 49] 93,600
│ │ └─CAMDenseTDNNLayer: 3-49 [1, 32, 49] 97,760
│ │ └─CAMDenseTDNNLayer: 3-50 [1, 32, 49] 101,920
│ │ └─CAMDenseTDNNLayer: 3-51 [1, 32, 49] 106,080
│ │ └─CAMDenseTDNNLayer: 3-52 [1, 32, 49] 110,240
│ │ └─CAMDenseTDNNLayer: 3-53 [1, 32, 49] 114,400
│ │ └─CAMDenseTDNNLayer: 3-54 [1, 32, 49] 118,560
│ │ └─CAMDenseTDNNLayer: 3-55 [1, 32, 49] 122,720
│ │ └─CAMDenseTDNNLayer: 3-56 [1, 32, 49] 126,880
│ │ └─CAMDenseTDNNLayer: 3-57 [1, 32, 49] 131,040
│ │ └─CAMDenseTDNNLayer: 3-58 [1, 32, 49] 135,200
│ │ └─CAMDenseTDNNLayer: 3-59 [1, 32, 49] 139,360
│ │ └─CAMDenseTDNNLayer: 3-60 [1, 32, 49] 143,520
│ │ └─CAMDenseTDNNLayer: 3-61 [1, 32, 49] 147,680
│ │ └─CAMDenseTDNNLayer: 3-62 [1, 32, 49] 151,840
│ └─TransitLayer: 2-13 [1, 512, 49] --
│ │ └─Sequential: 3-63 [1, 1024, 49] 2,048
│ │ └─Conv1d: 3-64 [1, 512, 49] 524,288
│ └─Sequential: 2-14 [1, 512, 49] --
│ │ └─BatchNorm1d: 3-65 [1, 512, 49] 1,024
│ │ └─ReLU: 3-66 [1, 512, 49] --
│ └─StatsPool: 2-15 [1, 1024] --
│ └─DenseLayer: 2-16 [1, 512] --
│ │ └─Conv1d: 3-67 [1, 512, 1] 524,288
│ │ └─Sequential: 3-68 [1, 512] --
├─Linear: 1-3 [1, 9] 4,617
===============================================================================================
Total params: 7,180,841
Trainable params: 7,180,841
Non-trainable params: 0
Total mult-adds (M): 552.44
===============================================================================================
Input size (MB): 0.03
Forward/backward pass size (MB): 41.22
Params size (MB): 28.72
Estimated Total Size (MB): 69.98
===============================================================================================
[2024-06-05 20:41:06.114035 INFO ] trainer:evaluate:476 - 成功加载模型:models/CAMPPlus_Fbank/best_model/model.pth
100%|██████████████████████████████████████████████████████████████████████████████████| 58/58 [00:25<00:00, 2.24it/s]
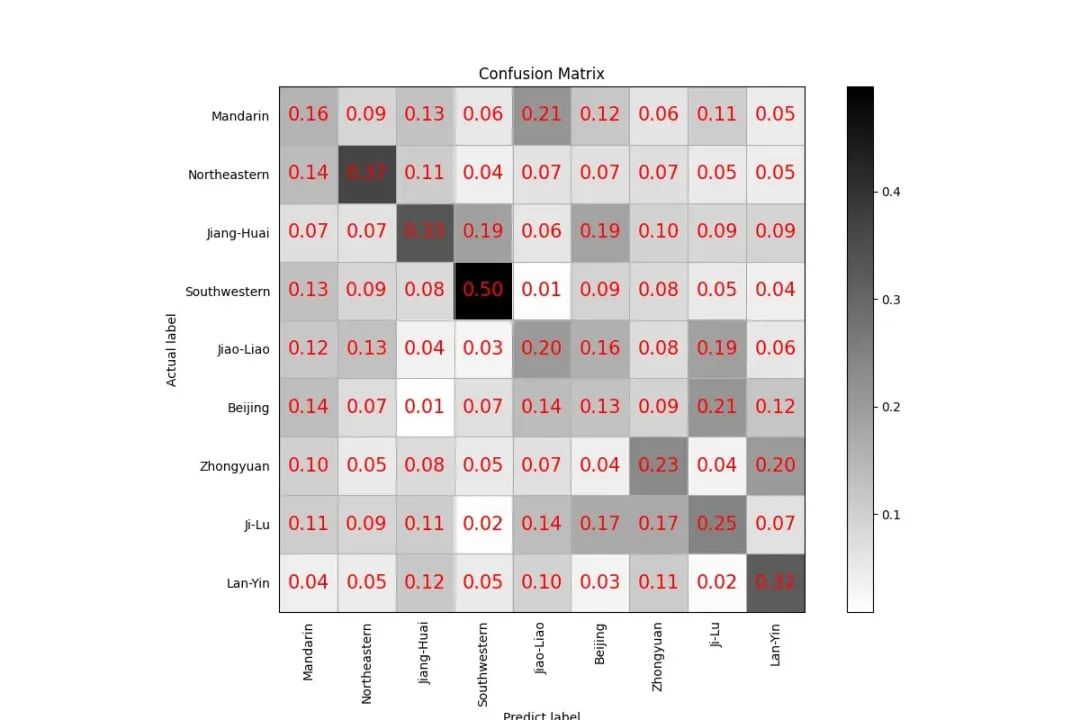
评估消耗时间:28s,loss:3.31887,accuracy:0.26412
训练的准确度,测试集试了下,过拟合太太太严重啦,主要是训练数据不够,另外就是数据比例可能和实际不一样吧,前者是主要原因。
阅读原文,直达github代码仓库。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号