面试官:Java中缓冲流真的性能很好吗?我看未必
原创
面试官:Java中缓冲流真的性能很好吗?我看未必
原创
JavaBuild
发布于 2024-06-16 20:08:54
发布于 2024-06-16 20:08:54
一、写在开头
上一篇文章中,我们介绍了Java IO流中的4个基类:InputStream、OutputStream、Reader、Writer,那么这一篇中,我们将以四个基类所衍生出来,应对不同场景的数据流进行学习。

二、衍生数据流分类
我们上面说了java.io包中有40多个类,都从InputStream、OutputStream、Reader、Writer这4个类中衍生而来,我们以操作对象的维度进行如下的区分:
2.1 文件流
文件流也就是直接操作文件的流,可以细分为字节流(FileInputStream 和 FileOuputStream)和字符流(FileReader 和 FileWriter),我们在上面的已经说了很多了,这里就再赘述啦。
2.2 数组流
所谓数组流就是将内存中有限的数据进行读写操作的流,适应于数据量小,无需利用文件存储,提升程序效率。
我们以ByteArrayInputStream(字节数组输入流)为例:
public class TestService{
public static void main(String[] args) {
try {
ByteArrayInputStream bi = new ByteArrayInputStream("JavaBuild".getBytes());
int content;
while ((content = bi.read()) != -1) {
System.out.print((char) content);
}
// 关闭输入流,释放资源
bi.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}字节数组输出流(ByteArrayOutputStream)亦是如此,它们不需要创建临时文件,直接在内存中就可以完成对字节数组的压缩,加密,读写以及序列化。
2.3 管道流
管道(Pipe)作为一种在计算机内通讯的媒介,无论是在操作系统(Unix/Linux)层面还是JVM层面都至关重要,我们今天提到的通道流就是在JVM层面,同一个进程中不同线程之间数据交互的载体。
我们以PipedOutputStream和PipedInputStream为例,通过PipedOutputStream将一串字符写入到内存中,再通过PipedInputStream读取输出到控制台,整个过程并没有临时文件的事情,数据仅在两个线程之间流转。
public class TestService{
public static void main(String[] args) throws IOException {
// 创建一个 PipedOutputStream 对象和一个 PipedInputStream 对象
final PipedOutputStream pipedOutputStream = new PipedOutputStream();
final PipedInputStream pipedInputStream = new PipedInputStream(pipedOutputStream);
// 创建一个线程,向 PipedOutputStream 中写入数据
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 将字符串 "沉默王二" 转换为字节数组,并写入到 PipedOutputStream 中
pipedOutputStream.write("My name is JavaBuild".getBytes());
// 关闭 PipedOutputStream,释放资源
pipedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
// 创建一个线程,从 PipedInputStream 中读取数据并输出到控制台
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 定义一个字节数组用于存储读取到的数据
byte[] flush = new byte[1024];
// 定义一个变量用于存储每次读取到的字节数
int len = 0;
// 循环读取字节数组中的数据,并输出到控制台
while (-1 != (len = pipedInputStream.read(flush))) {
// 将读取到的字节转换为对应的字符串,并输出到控制台
System.out.println(new String(flush, 0, len));
}
// 关闭 PipedInputStream,释放资源
pipedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
// 启动线程1和线程2
thread1.start();
thread2.start();
}
}2.4 数据流
我们知道在Java中分为基本数据类型和引用类型,我们在做数据的读取与写入时,自然也会涉及到这种情况,比如我们将txt文件中的数字型数据以int类型读取到程序中,这时Java为我们提供了DataInputStream/DataOutputStream类。它们的常用方法为:
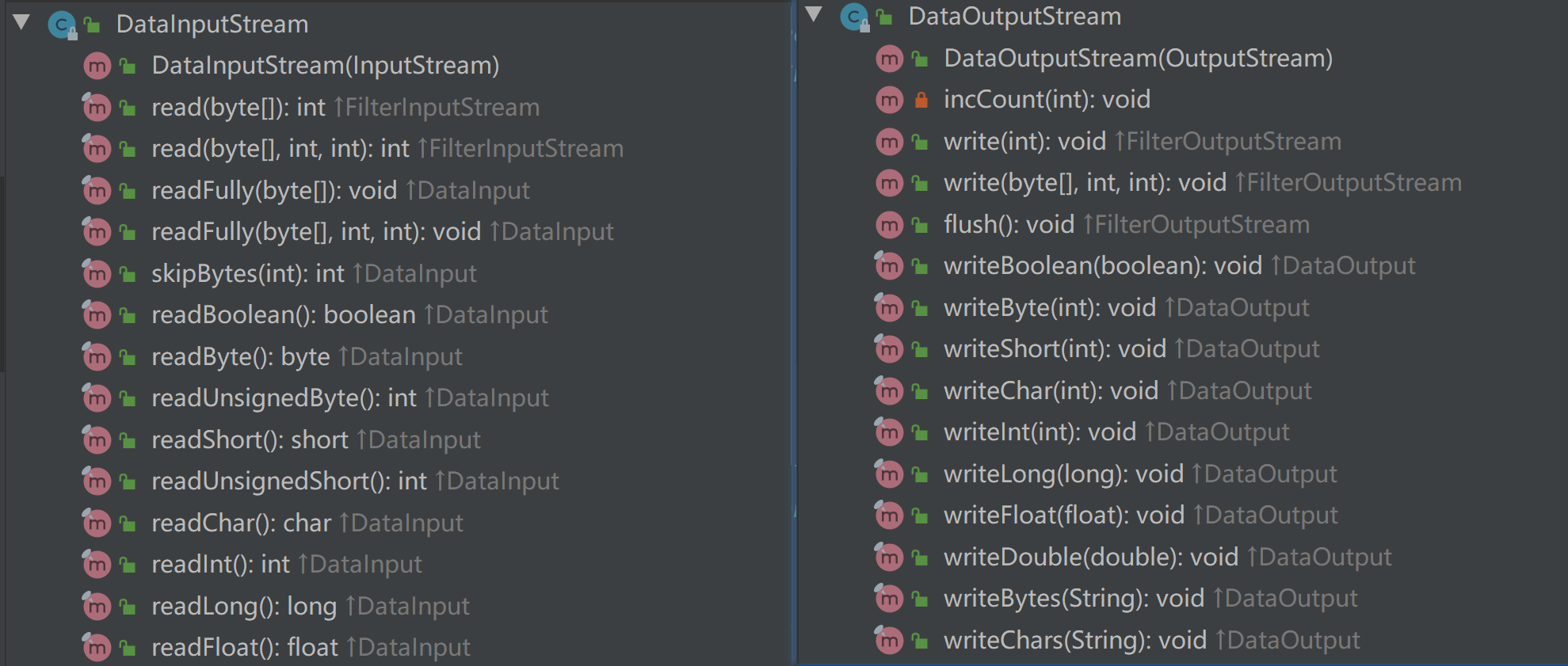
具体使用也相对比较简单:
DataInputStream dis = new DataInputStream(new FileInputStream("input.txt"));
// 创建一个 DataOutputStream 对象,用于将数据写入到文件中
DataOutputStream das = new DataOutputStream(new FileOutputStream("output.txt"));
// 读取四个字节,将其转换为 int 类型
int i = dis.readInt();
// 将一个 int 类型的数据写入到文件中
das.writeInt(1000);2.5 缓冲流
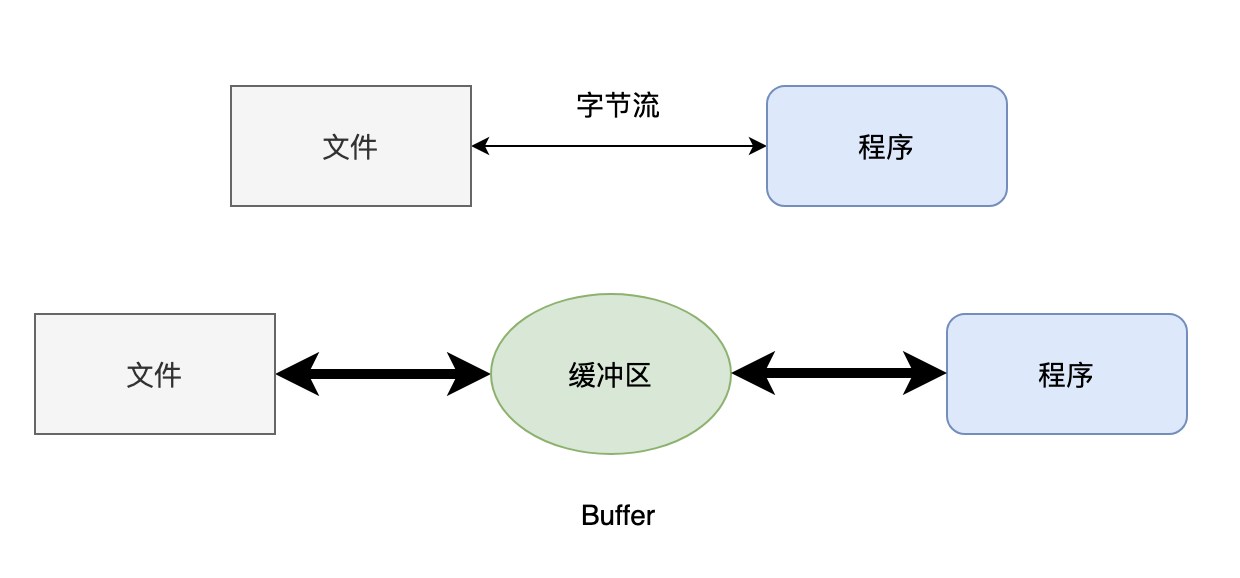
对于数据的处理,CPU速度快于内存,内存又远快于硬盘,在大数据量情况下,频繁的通过IO向磁盘读写数据会带来严重的性能问题,为此Java中提供了一个缓冲流的概念,简单来说就是在内存中设置一个缓冲区,只有缓冲区中存储的数据到达一定量后才会触发一次IO,这样大大提升了程序的读写性能,常用的缓冲流有:BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter。
通过BufferedInputStream的底层源码我们可以看到,其内部维护了一个buf[]数据,默认大小为8192字节,我么也可以通过构造函数进行缓存大小设置。
public
class BufferedInputStream extends FilterInputStream {
// 内部缓冲区数组
protected volatile byte buf[];
// 缓冲区的默认大小
private static int DEFAULT_BUFFER_SIZE = 8192;
// 使用默认的缓冲区大小
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
// 自定义缓冲区大小
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
}至于说缓冲流到底能不能实现性能的提升,我们实践出真知,对于程序员来说所有的理论都不及上手写一写来得有效!这其实也涉及到一个经常被问的面试问题:java中的缓冲流真的性能很好吗?
刚好,我们手头有一本《Java性能权威指南》的PDF版,大小为66MB,我们通过普通的文件流和缓冲流进行文件的读取和复制,看一下耗时对比。
public class TestService{
public static void main(String[] args) throws IOException {
TestService testService = new TestService();
testService.copyPdfWithPublic();
testService.copyPdfWithBuffer();
}
/*通过普通文件流进行pdf文件的读取和拷贝*/
public void copyPdfWithPublic(){
// 记录开始时间
long start = System.currentTimeMillis();
try (FileInputStream fis = new FileInputStream("E:\\Java性能权威指南.pdf");
FileOutputStream fos = new FileOutputStream("E:\\Java性能权威指南Public.pdf")) {
int content;
while ((content = fis.read()) != -1) {
fos.write(content);
}
//使用数组充当缓存时,两者性能差距不大
/*int len;
byte[] bytes = new byte[4 * 1024];
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}*/
fis.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("使用普通文件流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
/*通过缓冲字节流进行pdf文件的读取和拷贝*/
public void copyPdfWithBuffer(){
// 记录开始时间
long start = System.currentTimeMillis();
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("E:\\Java性能权威指南.pdf"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("E:\\Java性能权威指南Buffer.pdf"))) {
int content;
while ((content = bis.read()) != -1) {
bos.write(content);
}
/*int len;
byte[] bytes = new byte[4 * 1024];
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}*/
bis.close();
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("使用缓冲字节流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
}输出:
使用普通文件流复制PDF文件总耗时:221611 毫秒
使用缓冲字节流复制PDF文件总耗时:228 毫秒
然后,我们将注释掉的代码放开,也就是我们采用一个缓存数组,先将数组存储起来后,两者之间的性能差距就没那么明显了。
使用普通文件流复制PDF文件总耗时:106 毫秒
使用缓冲字节流复制PDF文件总耗时:80 毫秒在这种情况下,我们可以看到,甚至于普通的文件流的耗时是小于缓冲流的,所以对于这种情况来说,缓冲流未必一定性能最好。
2.6 打印流
对于System.out.println("Hello World");这句代码我想大家并不陌生吧,我们刚学习Java的第一堂课,老师们都会让我们输出一个Hello World,System.out 实际是用于获取一个 PrintStream 对象,print方法实际调用的是 PrintStream 对象的 write 方法。
public class PrintStream extends FilterOutputStream
implements Appendable, Closeable {
}
public class PrintWriter extends Writer {
}我正在参与2024腾讯技术创作特训营最新征文,快来和我瓜分大奖!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号