计算机视觉领域的基础模型


在计算摄影学的研究和应用中,计算机视觉(Computer Vision)技术扮演了至关重要的角色。计算机视觉不仅帮助我们理解和处理图像和视频数据,还为我们提供了丰富的工具和方法,以提升摄影和图像处理的效果。为了帮助大家更好地理解和应用这些技术,我准备也在星球中介绍更多关于计算机视觉的内容,首先我会引用一些文章,来介绍“计算机视觉领域的基础模型”。
基础模型是计算机视觉中的核心技术,它们通过在大规模数据集上进行训练,能够执行广泛的视觉任务,如分类、目标检测、分割等。这些模型不仅在学术研究中取得了显著的进展,还在工业应用中展示了强大的潜力。例如,通过基础模型,我们可以实现更加精准的图像分割、智能化的图像标注,以及增强现实(AR)和虚拟现实(VR)中的高效图像处理等。
本篇文章主要编译自Joris C.的Foundation Models in Computer Vision: A Kaleidoscope of Possibilities,其内容则主要来自于本文参考文献中的两篇文章。本文将深入探讨这些基础模型的原理、应用和最新进展,希望通过这些内容,能为大家在计算摄影学领域的研究和实践提供新的思路和工具。
广义上看,这些模型的输入不仅限于图像,还可以包括例如文本等其他形式的数据。正如刚才所说,基础模型是在大规模多样化的数据上进行训练的,一旦训练完成,它们就可以作为基础模型,并可以针对与原始训练模型相关的各种下游任务进行适应(例如微调)(Bommasami等,2021)。
这篇文章的贡献有三个方面:
- 引用 (Awais et al., 2023)的框架来展示当前的各种模型。
- 对每个模型,明确其解决的任务,并解释这些任务。
- 根据模型类型,指向最新的研究方向。
下文展示的框架将模型分为四类:
- 传统模型,或仅有图像输入的模型。
- 文本提示模型,或视觉语言模型(VLMs)。
- 视觉提示模型,其中最突出的例子是Meta的“Segment Anything Model”(SAM)。
- 异构模型,即图像是其中一种可能输入方式的模型。
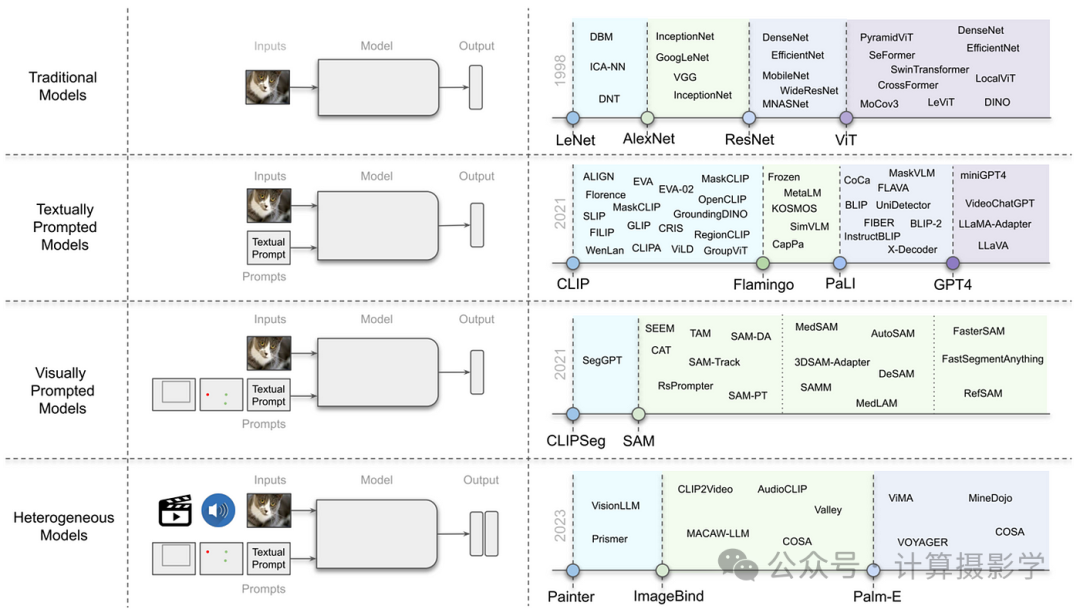
图1: 视觉基础模型的进化 (Awais et al., 2023)
一. 传统模型
传统模型只有图像输入,用于分类、目标检测和分割任务。最先进的模型通常采用Transformer架构,并使用自监督学习(SSL)方法训练。Transformer能够建模整个图像的全局空间依赖性(Dosovitskiy et al., 2021),例如在遥感中提高对不同分辨率图像的泛化能力(Gilbert et al., 2023)。当前主流的架构是视觉Transformer(ViT);(Liu et al., 2022)对更广泛的设计和特定任务的设计进行了综述。
在Transformer架构之上,SSL方法允许利用未标记的数据来提高泛化能力。(Ozbulak et al., 2023)提供了一个很好的基于图像的SSL概述。最近发布的SSL手册提供了更全面的SSL概述;注意,手册中的家族名称与专注于图像的论文有所不同。然而,可以看出,Yann LeCun在编写手册时已经在研究更改进的方法——他参与了最近发布的I-JEPA 方法以及用于掩码图像建模(MIM)的随机位置方法。
尽管如此,通过监督学习预训练的高性能卷积网络(如ConvNeXt)在多个任务上表现优于基于Transformer的架构和自监督学习方法。这是 (Goldblum et al., 2023)最近的“骨干网络之战”研究的结论。观察到的监督预训练的优越性是因为这些模型通常在更大的数据集上进行训练。在相同数据集规模的对比中,SSL模型优于其监督对手。此外,ViT比CNN对预训练数据量和参数数量更敏感。
(Wang et al., 2023)撰写了关于分割的概述;(Li et al., 2023 )则对用于分割的Transformer进行了更具体的综述(参见以前工作的3.3和4.3)。他们从一个类似DETR的元架构出发,回顾了关键技术,并根据方法和相关可能任务区分模型(参见表3)。一个有趣的亮点是Mask DINO,它是一个用于目标检测和分割的统一框架。
最近关于分割的一个令人兴奋的工作是GOSS模型(Hong et al., 2023),它引入并执行“广义开放集语义分割”,参见下图。基本上,它是开放集分割和广义分割的结合(参见SAM)。其目标是识别已知和未知的物体,并为所有物体提供分割掩码。
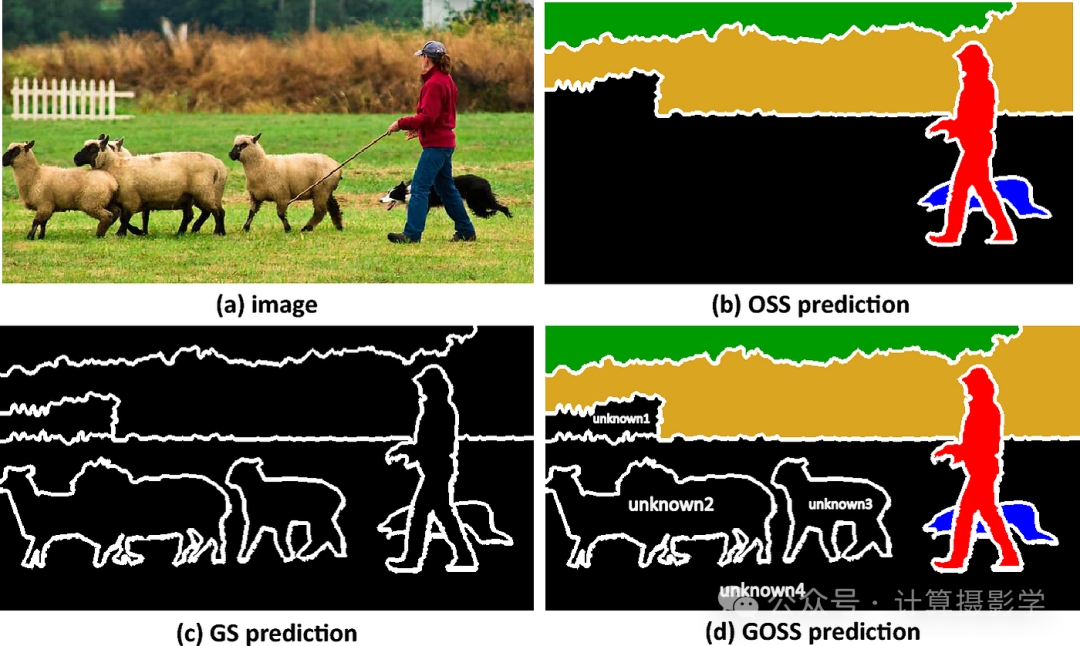
图2:图像分割的不同任务。
对于给定的包含已知(“人”、“狗”和“植被”)和未知对象(“羊”、“栏杆”和“草”)的输入图像a,显示了:
b 开放集语义分割(OSS)通过像素识别,
c 通用分割(GS)通过像素聚类,
以及d 广义开放集语义分割(GOSS)(Hong et al., 2023)
二. VLMs
视觉语言模型(VLMs)或图1中所示的文本提示模型,接受图像和文本输入,但由文本输入提示。在这里,有两个里程碑式的模型是OpenAI的CLIP模型和Flamingo模型。尽管CLIP类型的模型缺乏生成语言的能力(例如用于视觉问答,参见(Alayrac et al., 2022),但它最终成为计算机视觉模型中广泛使用的组件。随后,Flamingo模型为包括大型语言模型(LLM)在内的模型奠定了基础,后者称为生成型VLMs。
2.1 CLIP和类似CLIP的模型
CLIP代表对比语言-图像预训练(Contrastive Language-Image Pre-training)。CLIP的关键贡献在于其能够将不同模态的数据(即文本和图像)映射到一个共享的嵌入空间中。这个共享的多模态嵌入空间使得零样本分类、(简单的)图片描述和图像搜索/检索等任务成为可能。
2.1.1 对比预训练
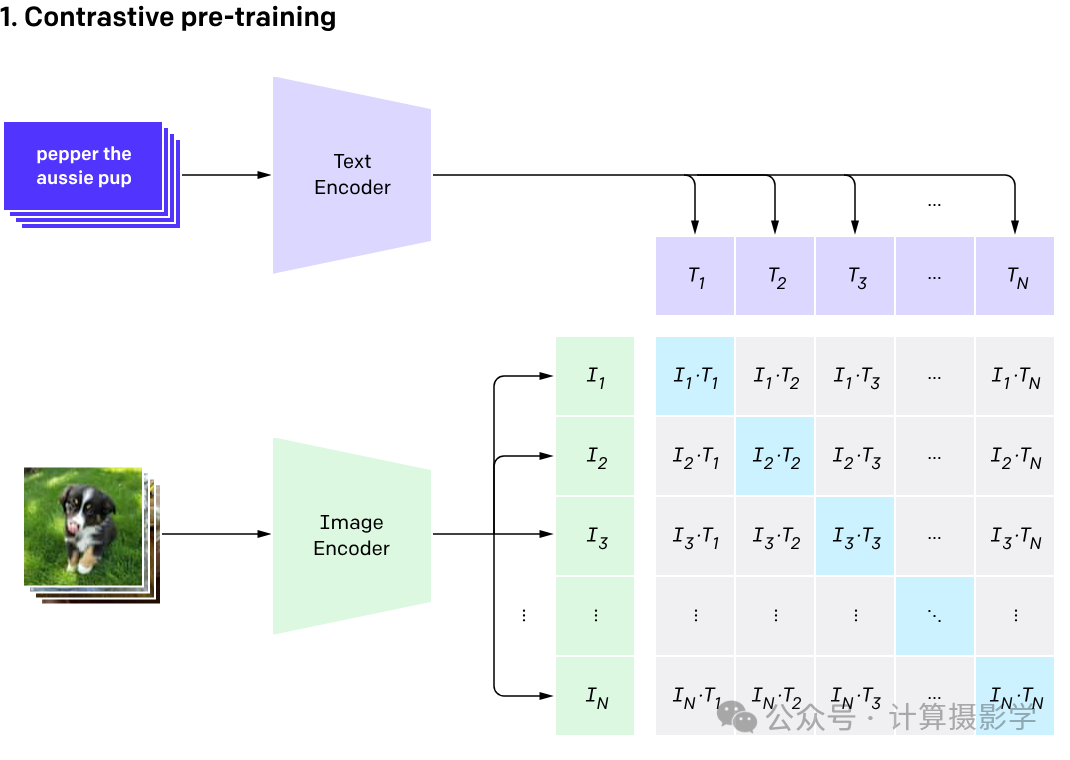
图3: CLIP的对比预训练,使得图像和文本映射到了共享的特征空间 (OpenAI).
其中一个最新利用CLIP的模型是RAM,即识别任意物体模型(Recognize Anything Model)。它的目标是图像分类,即为一张图像预测多个标签。在识别方面,RAM超越了早期的模型,但它并不能在图像中进行定位。然而,它可以与我们稍后会提到的SAM完美配对。
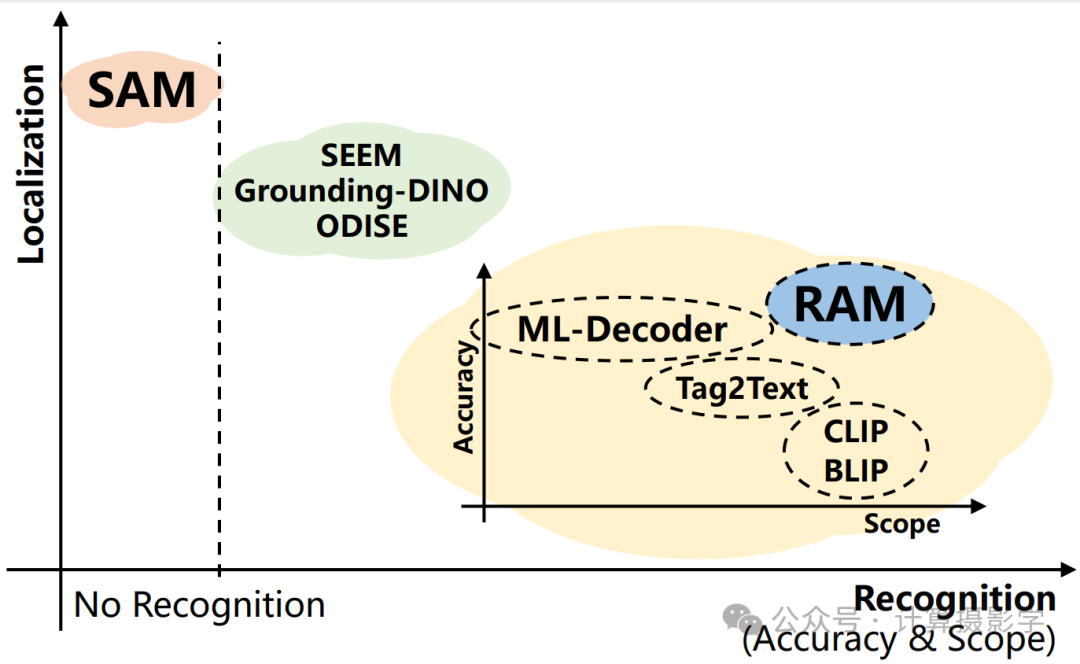
图4:模型在定位与识别方面的能力,并进一步按准确性和范围进行划分。(Zhang et al., 2023)
2.1.2 参考表达对象检测/分割
尽管不是基于CLIP,但Grounding DINO(Liu et al., 2023)却受到了它的启发,可以执行各种对象检测任务。它是为开放集检测(即在未见过的对象上进行测试)而构建的,但在闭集、开放集和参考对象检测任务上大幅超越了GLIP和其他竞争对手。这里提到的闭集对象检测与开放集对象检测相反,类别在训练和测试时都是已知的。而另外一个概念参考对象检测,则是一项任务,这里模型会接收到一个自然语言描述或参考表达,然后基于此检测出对应的对象。就像RAM一样,它也可以与SAM完美配对,我们将在关于SAM的部分详细讨论。

图5:Grounding-DINO的能力概述 (Liu et al., 2023)
最先进的用于参考表达分割任务的模型是GRES。同时,他们还引入了一种新的广义参考表达分割任务,这种任务可以处理任意数量的目标对象。这意味着它不仅可以处理多目标,还可以处理没有明确目标的情况。
2.1.3 开放词汇对象检测/分割
在开放词汇检测/分割中,模型可以识别各种各样的对象类别,即使这些类别在训练时没有见过。OVOD/OVS(开放词汇对象检测/分割)结合了零样本学习和开放集任务的挑战。“开放词汇”意味着对象类别可以扩展或不固定。虽然文本不是必须的输入,但可以选择加入自然语言描述或用户定义的类别。这使得OVOD能够在开放世界场景中检测各种对象。
用于对象检测的参考模型是OWL-ViT (Minderer et al., 2022),采用基于CLIP的训练方法。对于分割任务,目前最先进的是OVSeg(Liang et al., 2023),它基于Mask-adapted CLIP,即使用遮罩输入训练的CLIP变体(参见(Awais 等人,2023)的图4)。另外,还有FC-CLIP,,用于开放词汇全景分割,结合了实例分割和语义分割。(Wu et al., 2023)提供了OVOD和OVSS模型的概述。
2.1.4 生成型视觉语言模型(Generative VLMs)
在CLIP之后,谷歌开发了一个重要的模型,叫做Flamingo。它结合了一个冻结的(即不再修改的)视觉编码器和一个冻结的大型语言模型(LLM),结构类似于下图所示的架构,尽管连接图像和语言这两种模态的结构更加复杂。在这种模型中,视觉编码器通常是CLIP。LLM的使用赋予了VLMs真正的生成能力。这不仅改善了图片描述的性能,还使得所谓的视觉问答(VQA)成为可能,基本上就是能够与图像进行对话。
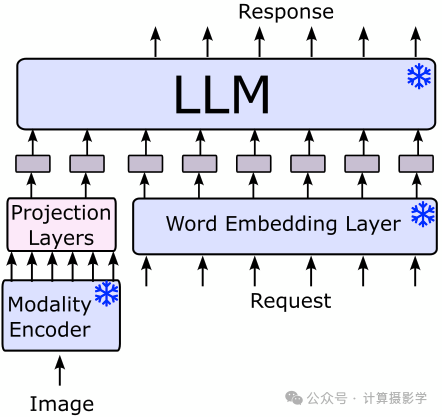
图 6:VLM的架构,使用投影层来弥合模态间的差距。灵感来自(Moon et al., 2023)
当然,最容易接触到的模型是OpenAI的GPT-4V,虽然它是闭源的,我们不知道它的具体架构。然而,微软的报告(Yang et al., 2023) 是一个有趣的阅读材料。最强大的开源模型之一是LLAVA的新版本,它实际上采用了上面展示的架构。它也是少数几个通过人类反馈强化学习(RLHF)训练的模型之一,这种训练方式可以提高性能,并减少幻觉和有害内容。
上述对话式VLM通常不擅长视觉定位任务,它们的突出能力是对整体图像进行推理(Awais et al., 2023)。在这方面,一个独特的工作是LISA,如下所示,它是一个扩展了视觉骨干网(实际上是SAM)的VLM,可以在提示下执行分割任务。在参考分割任务上,它的表现优于同类的X-Decoder和下一类的SEEM。此外,LISA提出了推理分割任务,即在给定复杂和隐含的查询文本时输出一个分割掩码。
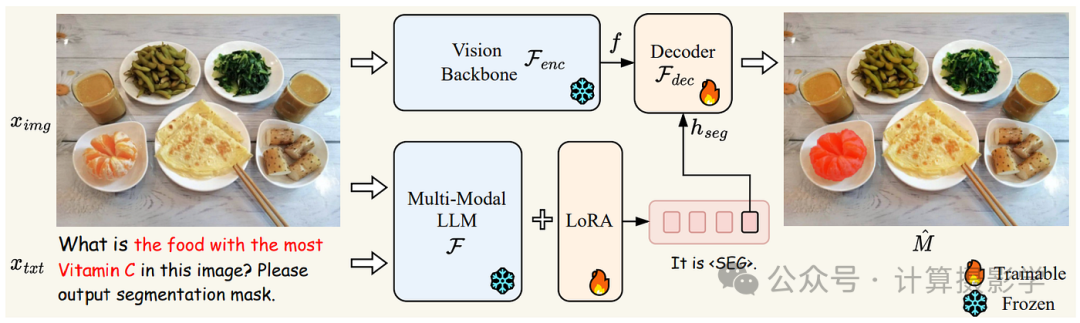
图7: LISA的架构(Lai et al., 2023)
2.2 视觉提示模型
这种类型的模型需要输入一张图像和(最好是)视觉提示(如边界框或点)或文本提示。大多数模型允许多种提示类型。输出根据模型的不同而变化,可以是语义分割掩码、实例分割掩码或一般的分割掩码(如SAM)。这一类别中有四个重要的模型:ClipSeg、SegGPT、SAM和SEEM。其他模型大多是SAM的衍生品。我们将依次介绍前面三个模型,然后看看SEEM及其他基于SAM的架构。这些模型对于辅助标注应用特别有趣。这里介绍的几个模型可以在Roboflow的Python包autodistill中找到。
2.2.1 零样本和少样本分割
CLIPSeg 是一个用于语义分割的模型,它使用你提供的文本提示或原型图像来分割图像。它是为参考分割设计的,即根据文本提示或参考图像来分割图像。前者称为参考表达分割,后者称为参考图像分割。它在提供文本提示时执行零样本分割,在显示原型图像时执行一次分割。尽管新颖,但CLIP并非设计用于学习像素级信息,因为它专注于全局特征(Awais et al., 2023)
接下来是 SegGPT,一个统一解决多样化分割任务的模型,如语义分割、实例分割、部分分割,甚至特殊场景下的分割如航拍图像分割。它可以执行少样本分割,或使用上下文示例来提供掩码,基本上相当于一次分割。Roboflow上也有使用它的实际例子。
Segment Anything Model 基于点、边界框、掩码或文本输入输出分割掩码。SAM实际上执行交互式分割,返回一般的分割掩码;但如果选择好输入,你实际上可以进行语义和/或实例分割。交互式分割涉及用户根据边界框、点、涂鸦或其他提示来指导分割过程。与视觉提示相比,SAM在处理文本提示时的表现较弱。
有几点需要了解。首先,SAM实际上会输出三个不同粒度的分割掩码,但大多数实现只显示其中一个。其次,它也可以在自动模式下运行,通过为图像提供一个点网格,尽管这样你显然对结果的控制较少。如果你没有提供任何输入,它会在后台使用这种方法。最后,在自动模式下,它通常会将图像的一个重要部分添加到背景掩码中,这可能并不总是对你的应用有用。
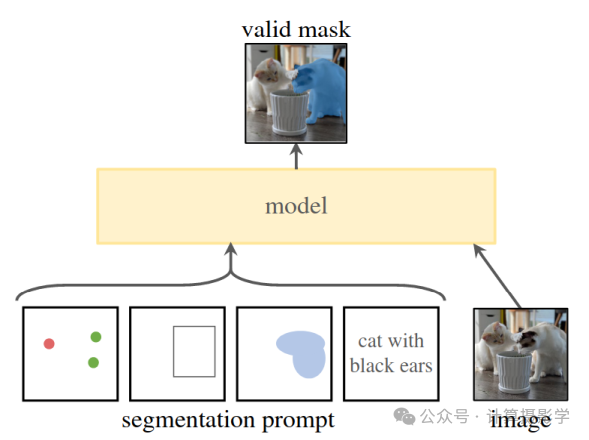
图8: SAM的基于提示的分割(Kirillov et al.)
2.2.2 通用分割
通用分割是指能够适应各种类型的人工提示并处理不同分割任务的过程。在这个领域,有两个强大的模型:SEEM和Semantic SAM。SEEM(Segment Everything Everywhere All at Once)提供了一个通用分割任务的界面,同时支持参考分割和交互式分割。
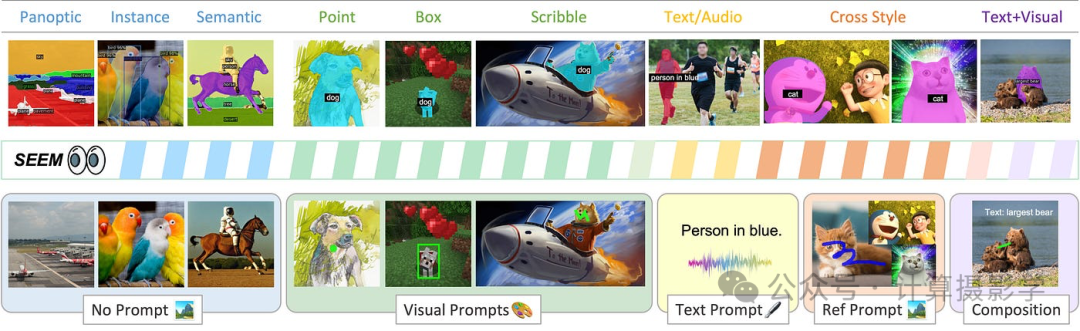
图 9:展示了SEEM的输入(下方)和输出(上方)(来源)
另一个模型是Semantic-SAM,它的目标是在任何尺度上分割和识别任何对象。它提供了与SEEM类似的功能,此外还能输出多达6种不同粒度的分割掩码。这个模型首先通过再现SAM作为一个子任务,并在粒度丰富性、语义感知和质量方面超越了SAM,从而实现了通用分割。
2.2.3 Grounding SAM
在SAM发布后不久,它便与其他新型强大模型结合,以提供视觉定位功能。这项工作由IDEA Research完成,他们称之为 Grounded-Segment Anything。该模型的第一个版本将Grounding Dino与SAM连接起来,这样用户可以通过文本提示模型,基于Grounding Dino生成的边界框来分割所有对象。下面展示了一个示例。

图10: 基于Grouding Dino的Grounding SAM(来源)
目前,使用HQ-SAM的变体在“Segmentation in the Wild”排行榜中名列前茅(至少在零样本分类中),而相关团队发布的第二个版本是RAM-Grounded-SAM,通过在流程中预先添加RAM,不需要任何用户输入即可生成分割结果。

图11: 使用了RAM的RAM-Grounded-SAM(来源).
三. 异构模型
这一类别包含能够接受多种类型输入并生成多种类型输出的模型。它由三个子类别组成,即通用模型、多模态大语言模型(MLLMs,例如Image Bind)和具身模型。最后一种类型在这里不做讨论,将在未来关于智能体的文章中进行介绍。
3.1 通用模型
这类模型旨在解决比分割更广泛的视觉任务。它们在任务定义和输出方面有所不同。第一个是Painter,它执行从分割到去噪或图像增强等任务,其输入是一张图像以及另一张图像和该图像的“解决方案”,有效地实现了上下文视觉学习——类似于SegGPT,它实际上基于Painter。
接下来是Prismer,一个采用专家混合(MoE,即每个任务都有一个特定的基础模型)的方法来执行分割、OCR、边缘检测等任务,然后将这些作为输入传递给LLM的跨模态模块。这样,用户可以生成图像的描述或与输入图像进行对话。
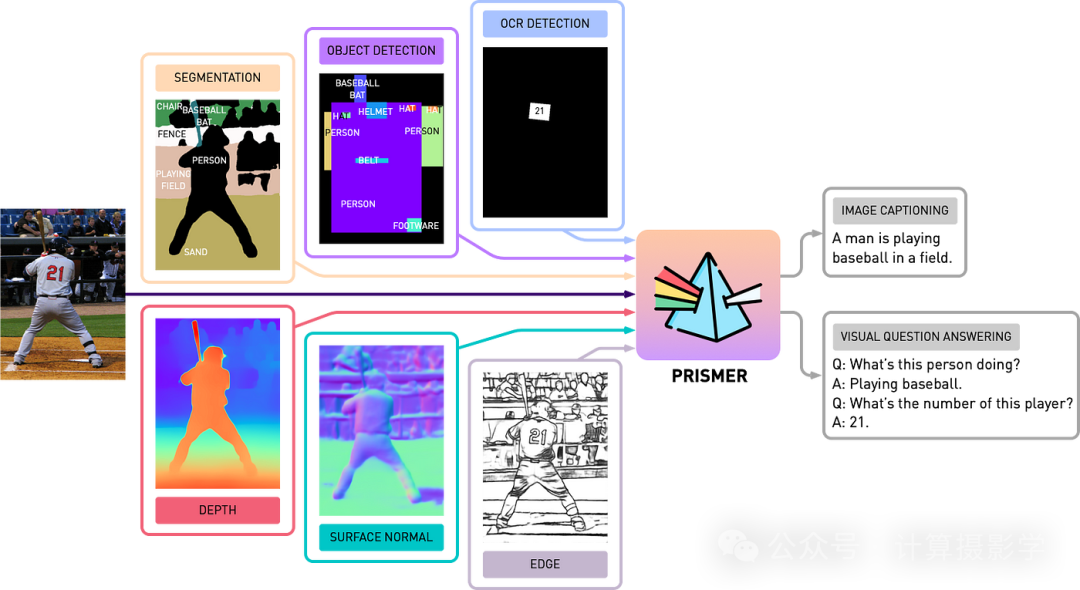
图12: Prismer的架构(来源)
最后一类模型使用大型语言模型(LLM)进行任务编排,即让LLM将任务分配给正确的视觉模型。示例包括VisionLLM 和微软的 TaskMatrix/VisualGPT。这类模型可以处理的任务范围比视觉语言模型(VLM)更广泛,但在视觉语言任务上的表现较差,因为在跨模态时信息会有所丢失。
3.2 多模态大语言模型(MLLM)
在本文中,多模态大语言模型(MLLM)指的是那些至少接受三种不同模态作为输入的模型——文本、图像以及至少一种其他模态。有时,视觉语言模型(VLM)也被称为MLLM。在这方面,一个重要的模型是Meta的ImageBind 及其最近的继任者 AnyMAL。虽然ImageBind使用图像作为中心模态,AnyMAL则将文本作为中心模态,并采用类似于LLAVA的架构,如上图6所示。AnyMAL的输出是文本。
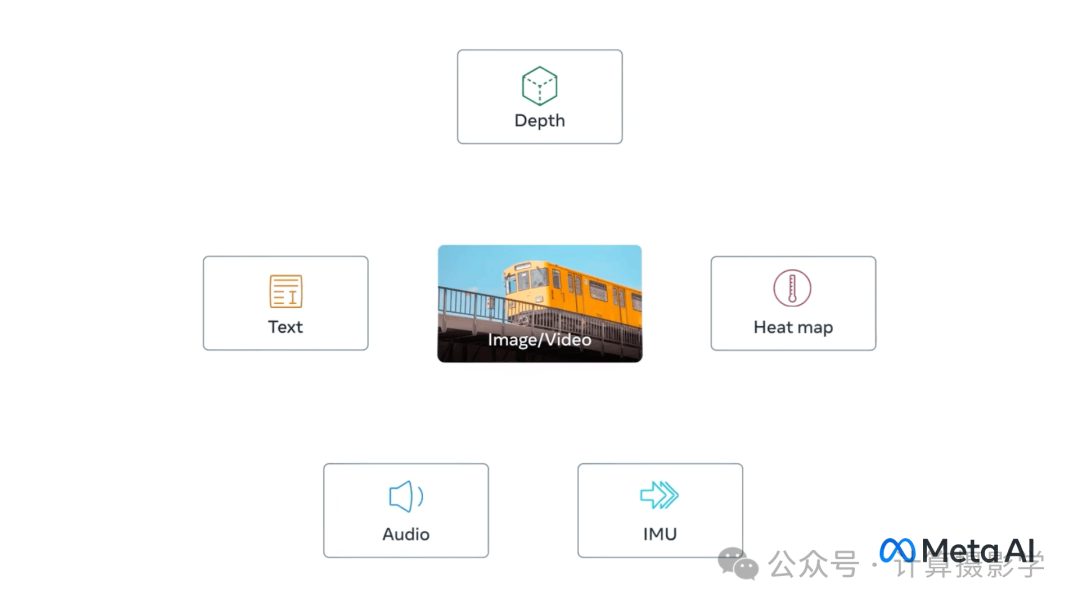
图13:ImageBind结合了7种模态,并以图像作为中心模态 (来源).
多模态能力被NexT-GPT进一步提升,这个模型被描述为一种“任意到任意”的多模态大语言模型(Any-to-Any MLLM)。与AnyMAL一样,这些模态通过投影来连接;实际上,它在投影之前使用ImageBind作为输入端。这里有一个有趣的想法,即使用LLM的输出作为输入,传递给扩散模型以生成答案。
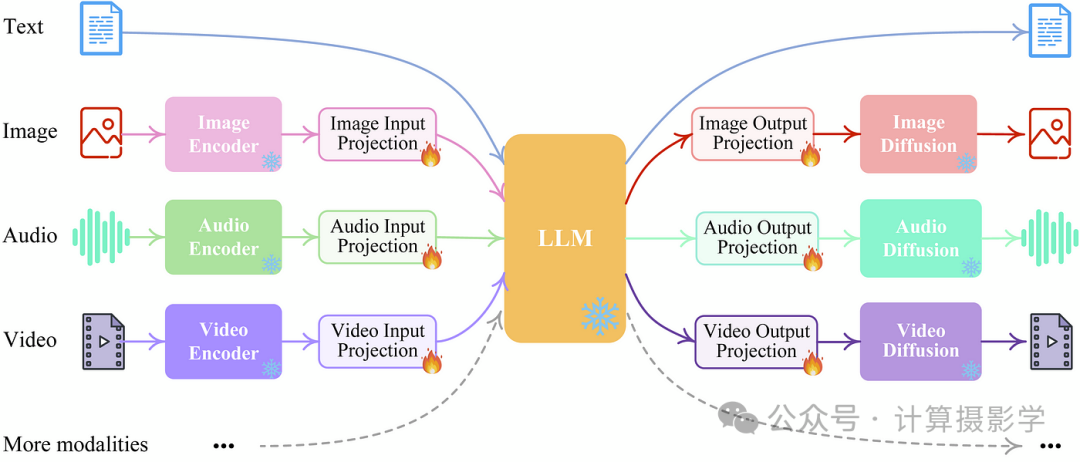
图14:根据Next-GPT,输入和输出多种模态(来源)
一个更独特的模型是Ferret,它提供了使用文本、点和掩码对图像进行提示的能力,并能够将其输出与图像中的具体位置关联。
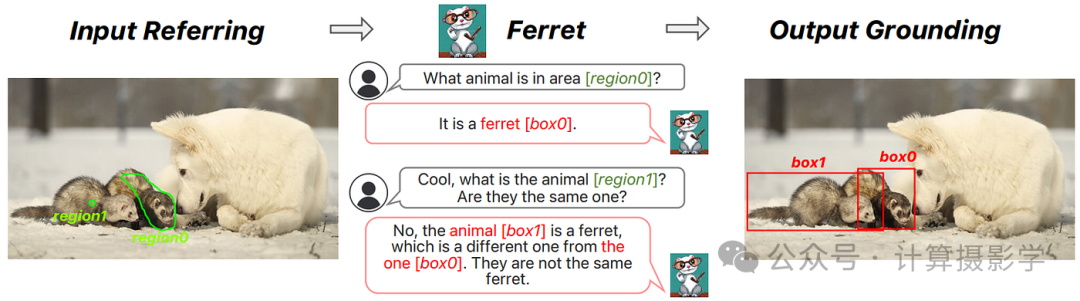
图 15:MLLM的参考和定位能力(You et al., 2023)
正是像Ferret和LISA这样的工作,为VLM在纯视觉任务中的更广泛应用铺平了道路
四. 结论
这篇文章将以图像作为输入的模型分类为传统模型、文本提示模型、视觉提示模型和异构模型。传统模型和视觉提示模型的输出是常规的视觉输出(如掩码),而文本提示模型输出文本,异构模型则基本可以输出任何内容。
展望未来,我看到一个正反馈循环,模型利用大型数据进行训练(例如SAM的数据集),从而实现特定领域的模型以及进一步的泛化。泛化意味着能够处理更多或更抽象的任务,包括VLM在内的模型执行纯视觉任务。
五. 参考资料
- Foundation models in Vision, by (Awais et al., 2023)
- Chip Huygen’s blog post on LMMs: focusses on VLMs and MLLMs
六. 附件-相关任务的定义
本节列出了每个类别提到的所有任务,当然我们没有穷尽所有可能的任务:
6.1 传统模型

6.2 视觉语言模型(VLMs)
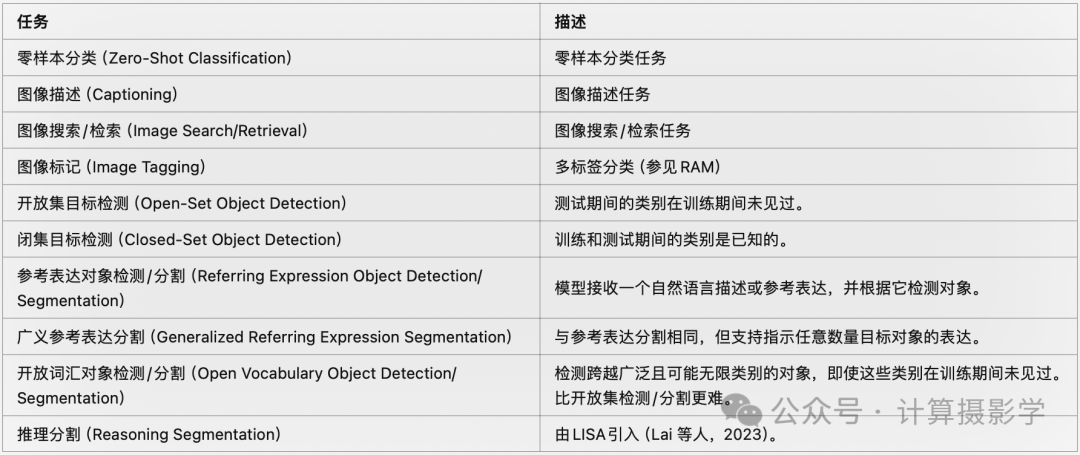
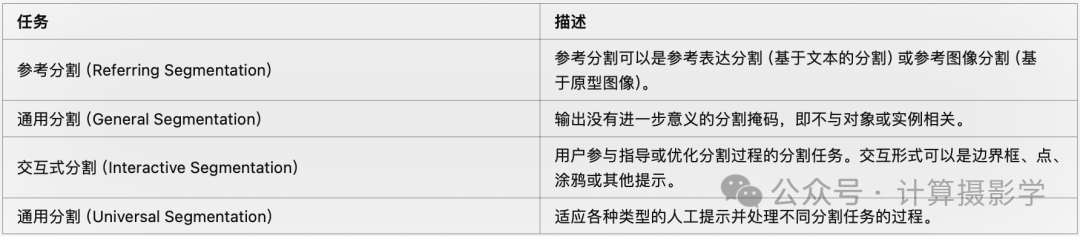
6.3 视觉提示模型
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号