应用决策树生成【效果好】【非过拟合】的策略集


决策树在很多公司都实际运用于风险控制,之前阐述了决策树-ID3算法和C4.5算法、CART决策树原理(分类树与回归树)、Python中应用决策树算法预测客户等级和Python中调用sklearn决策树。
本文介绍应用决策树生成效果好,非过拟合的策略集。
一、什么是决策树
决策树:通过对已知样本的学习,一步一步将特征进行分类,从而将整个特征空间进行划分,进而区分出不同类别的算法。
我们在逻辑判断中用到的思想if, else if ,else, then,其实就是决策树的思想。
二、决策树中专有名词理解
1.根节点:包含数据集中所有数据集合的节点,即初始分裂节点。
2.叶节点/终端节点:最终的决策结果(该节点不再进行划分),被包含在该叶节点的数据属于该类别。
3.内部节点:非根节点和叶节点的节点,该节点包含数据集中从根节点到该节点所有条件的数据集合。根据内部节点的判断条件结果,其对应的数据集合被分到两个或多个子节点中。
4.父节点:划分出子节点的节点。
5.子节点:由父节点根据某一规则分裂而来的节点。
6.节点的深度:节点与决策树根节点的距离,如根节点的子节点的深度为1.
7.决策树的深度:所有叶子节点的最大深度。
借用CART决策树原理(分类树与回归树)中的简单决策树说明以上名词,用图形展示如下:
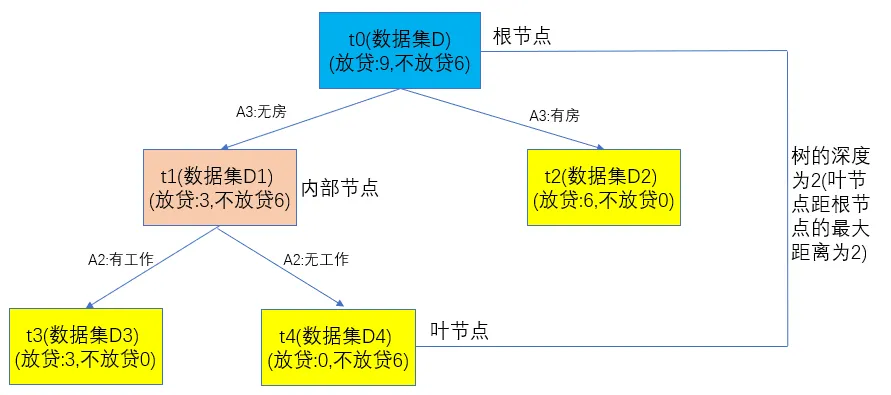
其中蓝色数据框表示根节点,橘色数据框表示内部节点,黄色数据框表示叶节点,这颗树的深度为叶节点距根节点的最大距离,即为2。
三、应用决策树算法生成规则集
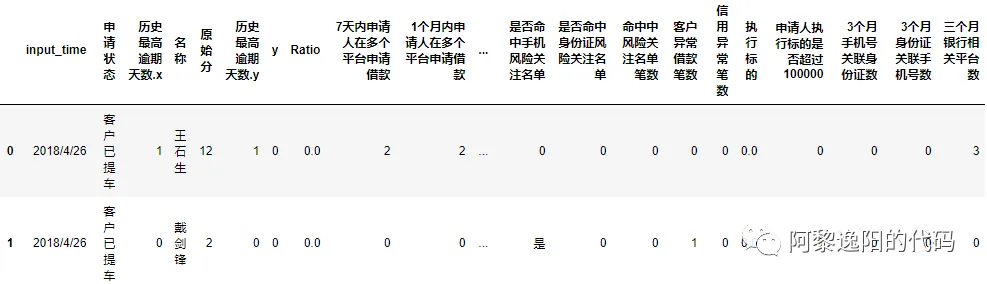
项目背景:由于公司发展车贷业务,需要判断新进来的申请人有多大的概率会逾期,根据逾期的概率和资金的松紧程度决定是否放贷。 现在有一批历史上是否违约的客户样本数据(由于数据涉及安全问题,也是职业操守要求,故此数据不是原始数据,是经过处理的)。 想根据这批历史数据训练决策树,生成规则集划分样本空间。从而决定新申请人是通过、转人工核验还是拒绝。 1 导入数据 用pandas库导入待建模的csv格式数据。 import os import numpy as np import pandas as pd os.chdir(r'F:\公众号\4.决策树和随机森林') date = pd.read_csv('testtdmodel1.csv', encoding='gbk') 注:由于数据中存在中文,如果不使用encoding对编码进行申明会报如下错误: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 2: invalid start byte 把endcoding的值设置为gb18030或gbk可以解决此类问题,成功导入数据。 2 看下数据基本情况 2.1 用head函数看下数据表头和前几行数据 我选择看前两行的数据,如果括号里为空默认展示前五行的数据,可以根据需要把2改为你想展示的行数。也可以用tail函数展示后几行数据。 data.head(2) 结果:
2.2 用value_counts函数观测因变量y的数据分布 在信贷中,有些客户因为忘记了还款日期、或者资金在短期内存在缺口(不是恶意不还),可能会导致几天的逾期,在催收后会及时还款。 故一般不把历史逾期不超过x天(根据公司的实际业务情况和数据分析结果得出)的客户定义为坏客户(这里的坏不是坏人的意思,纯粹指逾期超过x天的客户)。 在本文把逾期超过20天的客户标签y定义为1(坏客户),没有逾期和逾期不超过20天的客户标签y定义为0(好客户)。 data.y.value_counts() 得到结果:
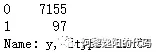
本文总计样本数量为7252,其中7155个样本是好客户,97个样本是坏客户。说明0和1的分布很不均匀,我们统计一下占比:
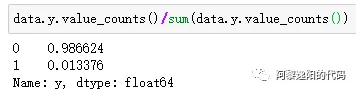
发现0的占比达到了98.6%,1的占比不到2%。
3 把数据集拆分成训练集和测试集
接着把数据集拆分成训练集和测试集,一部分用于训练,一部分用于验证,代码如下:
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(date, date.y, test_size=0.3)
x_col = date.columns[6:]
Xtrain_f = Xtrain[x_col]
Xtest_f = Xtest[x_col]
Xtrain_date = Xtrain_f.copy()
Xtrain_date['y'] = Ytrain
Xtest_date = Xtest_f.copy()
Xtest_date['y'] = Ytest
print(Xtrain_date.shape, Xtest_date.shape)
得到结果:
(5076, 40) (2176, 40)
4 定义从决策树生成规则集的函数
接着定义决策树生成规则集的函数,代码如下:
from sklearn.tree import tree
def Get_Rules(clf,X):
n_nodes = clf.tree_.node_count
children_left = clf.tree_.children_left
children_right = clf.tree_.children_right
feature = clf.tree_.feature
threshold = clf.tree_.threshold
value = clf.tree_.value
node_depth = np.zeros(shape=n_nodes, dtype=np.int64)
is_leaves = np.zeros(shape=n_nodes, dtype=bool)
stack = [(0, 0)]
while len(stack) > 0:
node_id, depth = stack.pop()
node_depth[node_id] = depth
is_split_node = children_left[node_id] != children_right[node_id]
if is_split_node:
stack.append((children_left[node_id], depth+1))
stack.append((children_right[node_id], depth+1))
else:
is_leaves[node_id] = True
feature_name = [
X.columns[i] if i != _tree.TREE_UNDEFINED else "undefined!"
for i in clf.tree_.feature]
ways = []
depth = []
feat = []
nodes = []
rules = []
for i in range(n_nodes):
if is_leaves[i]:
while depth[-1] >= node_depth[i]:
depth.pop()
ways.pop()
feat.pop()
nodes.pop()
if children_left[i-1]==i:#当前节点是上一个节点的左节点,则是小于
a='{f}<={th}'.format(f=feat[-1],th=round(threshold[nodes[-1]],4))
ways[-1]=a
last =' & '.join(ways)+':'+str(value[i][0][0])+':'+str(value[i][0][1])
rules.append(last)
else:
a='{f}>{th}'.format(f=feat[-1],th=round(threshold[nodes[-1]],4))
ways[-1]=a
last = ' & '.join(ways)+':'+str(value[i][0][0])+':'+str(value[i][0][1])
rules.append(last)
else:
if i==0:
ways.append(round(threshold[i],4))
depth.append(node_depth[i])
feat.append(feature_name[i])
nodes.append(i)
else:
while depth[-1] >= node_depth[i]:
depth.pop()
ways.pop()
feat.pop()
nodes.pop()
if i==children_left[nodes[-1]]:
w='{f}<={th}'.format(f=feat[-1],th=round(threshold[nodes[-1]],4))
else:
w='{f}>{th}'.format(f=feat[-1],th=round(threshold[nodes[-1]],4))
ways[-1] = w
ways.append(round(threshold[i],4))
depth.append(node_depth[i])
feat.append(feature_name[i])
nodes.append(i)
return rules
5 训练决策树生成规则集
接着应用训练集数据训练决策树,并生成规则集,代码如下:
#训练一个决策树,对规则进行提取
clf = tree.DecisionTreeClassifier(max_depth=3, min_samples_leaf=50)
X = Xtrain_f
y = Ytrain
clf = clf.fit(X, y)
Rules = Get_Rules(clf,X)
Rules
得到结果:
['一度关联节点个数<=6.5 & 1个月内关联P2P网贷平台数<=1.5 & 是否命中身份证风险关注名单<=0.5:4152.0:30.0',
'一度关联节点个数<=6.5 & 1个月内关联P2P网贷平台数<=1.5 & 是否命中身份证风险关注名单>0.5:337.0:9.0',
'一度关联节点个数<=6.5 & 1个月内关联P2P网贷平台数>1.5 & 3个月内借款人手机申请借款平台数<=5.5:70.0:0.0',
'一度关联节点个数<=6.5 & 1个月内关联P2P网贷平台数>1.5 & 3个月内借款人手机申请借款平台数>5.5:262.0:13.0',
'一度关联节点个数>6.5 & 二度风险名单占比<=0.045 & 1个月内借款人手机申请借款平台数<=3.5:71.0:1.0',
'一度关联节点个数>6.5 & 二度风险名单占比<=0.045 & 1个月内借款人手机申请借款平台数>3.5:68.0:5.0',
'一度关联节点个数>6.5 & 二度风险名单占比>0.045:52.0:6.0']
6 生成规则集数据框
接着把规则集变成数据框,代码如下:
# 生成规则数据框
df = pd.DataFrame(Rules)
df.columns = ['allrules']
df['Rules'] = df['allrules'].str.split(':').str.get(0)
df['good'] = df['allrules'].str.split(':').str.get(1).astype(float)
df['bad'] = df['allrules'].str.split(':').str.get(2).astype(float)
df['all'] = df['bad']+df['good']
df['bad_rate'] = df['bad']/df['all']
df = df.sort_values(by='bad_rate',ascending=False)
del df['allrules']
df
得到结果:
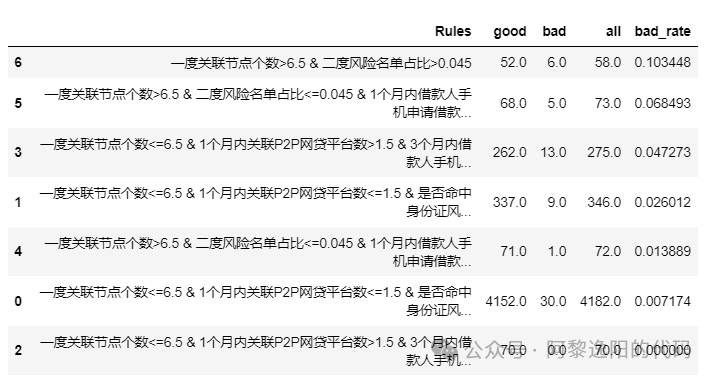
可以发现每一行对应一个规则集,列对应好坏样本数,坏样本率等指标。 7 生成可视化决策树 为了验证生成的规则集是否正确,我们把决策树展示出来,代码如下: import graphviz from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split dot_data = tree.export_graphviz(clf, out_file = None, feature_names = x_col, class_names = ['good', 'bad'], filled = True, rounded = True ) graph = graphviz.Source(dot_data.replace('helvetica', '"Microsoft YaHei"'), encoding='utf-8') graph 得到结果:
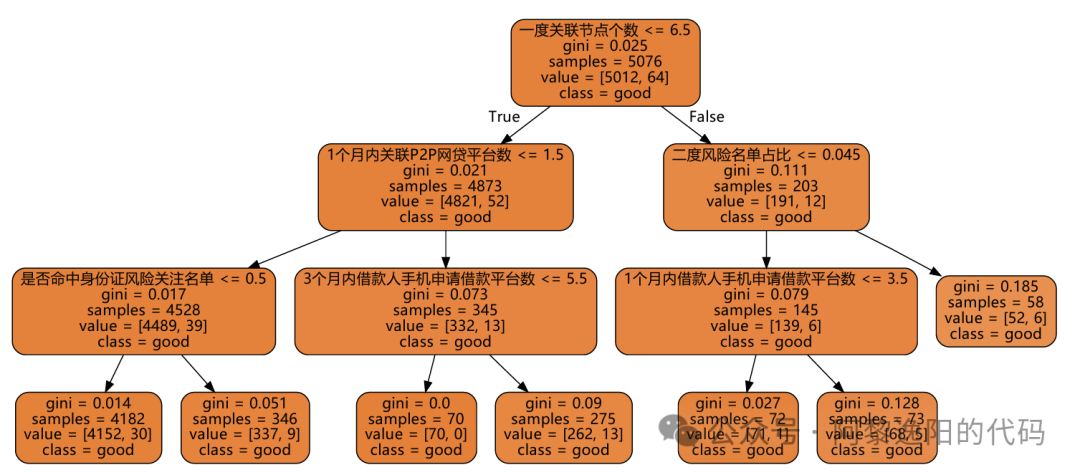
可以发现结果是一致的。 8 合并训练集和测试集规则数据 接着定义函数,生成训练集和测试集组合规则合并数据,代码如下: def rule_date(df, Xtest_date): ''' df:决策树生成的规则对应的好坏数量及占比 Xtest_date:测试集数据,包含X和y ''' df = df Xtest_date = Xtest_date rule_list = [] good_list = [] bad_list = [] for i in range(len(df.Rules)): new_date = Xtest_date.copy() rule_list.append(df.Rules[i]) for j in df.Rules[i].split('&'): j = '`' + j.replace(' ', '').replace("<", "`<").replace(">", "`>") new_date = new_date.query(j) good_list.append(new_date['y'].value_counts()[0]) bad_list.append(new_date['y'].value_counts()[1]) df_test = pd.DataFrame({'Rules':rule_list, 'good_test':good_list, 'bad_test':bad_list}) df_test['all_test'] = df_test['good_test'] + df_test['bad_test'] df_test['bad_rate_test'] = df_test['bad_test']/df_test['all_test'] df_all = pd.merge(df, df_test, on='Rules') return df_all df_all = rule_date(df, Xtest_date) 得到结果:
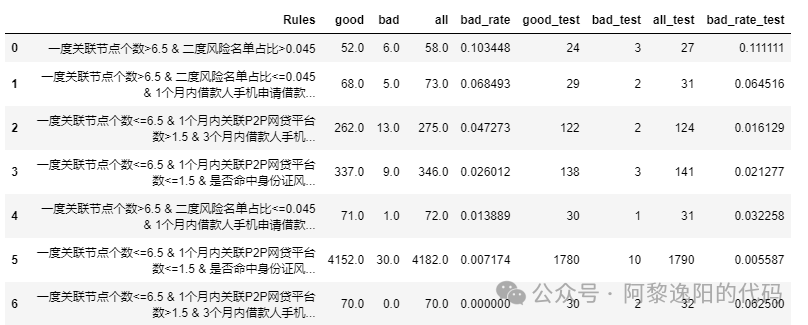
9 筛选效果好的规则 最后筛选想要的规则集,代码如下: df_all_f = df_all[df_all['bad_rate']>=0.06] df_all_f 得到结果:

可以发现筛选后的规则集坏样本率超过整体坏样本率3倍,且训练集和测试集差距不大。 这里可以根据公司的业务情况,自定义函数保留想要的规则集。
参考文献
https://mp.weixin.qq.com/s/fErTOjdVm28FL5zl_aUBbQ
https://gitcode.csdn.net/65e844861a836825ed78c4c5.html
https://blog.csdn.net/crossoverpptx/article/details/131305937
https://baike.baidu.com/item/%E5%86%B3%E7%AD%96%E6%A0%91/10377049?fr=ge_ala本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号