RTX AI Toolkit:AI PC时代创业者必备神器

RTX AI Toolkit:AI PC时代创业者必备神器

GPUS Lady
发布于 2024-07-01 15:20:33
发布于 2024-07-01 15:20:33

在AI PC时代,创业者正迎来前所未有的机遇与挑战。随着人工智能技术的不断进步,如何将先进技术转化为商业价值,已成为创业者们探索的重点。月初,我们介绍了NVIDIA推出NVIDIA RTX AI Toolkit(NVIDIA RTX AI Toolkit发布,解锁Windows应用的AI新时代),这一创新工具集不仅为Windows应用开发者量身打造了一套全面的工具集和SDK,更极大地简化了AI模型的定制、优化和部署过程。RTX AI Toolkit确保无论是在本地还是云端部署,创业者都能获得卓越的AI性能,从而轻松应对各种复杂的AI开发需求。因此,RTX AI Toolkit正逐渐成为创业者们在AI PC时代中的必备神器,助力他们高效实现创新应用的快速落地,走向成功之路。
近期,NVIDIA正式在Github上发布了这套工具入门教程:
https://github.com/NVIDIA/RTX-AI-Toolkit?tab=readme-ov-file。
RTX AI Toolkit是怎样的工具?
NVIDIA RTX AI Toolkit是一套专为Windows应用程序开发者设计的工具和SDK套件,旨在加速AI模型的定制、优化以及在Windows PC上的部署,无论是在云端还是本地PC,只要它们配备了RTX技术。
入门指南
NVIDIA RTX AI Toolkit主要包含两个阶段:模型定制和模型部署。每个阶段都会引导您完成必要的步骤,以便有效地定制和部署您的AI模型。
目前,NVIDIA支持使用PEFT(参数高效微调)技术对大型语言模型(LLM)进行端到端的工作流程定制,例如LoRA(大型语言模型的低秩适应)和QLoRA,在您的RTX PC上进行定制,并使用NVIDIA TensorRT-LLM、ONNX-Runtime、llama.cpp或作为云中的NIM端点进行部署。
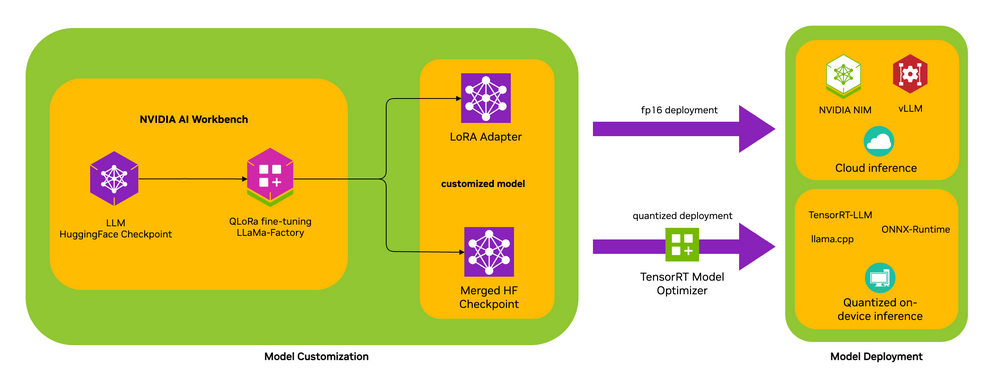
1. 模型定制教程
模型定制教程将指导您如何启动AI Workbench,使用LlamaFactory GUI进行QLoRa微调,并导出量化模型。此外,我们还提供了Jupyter笔记本,用于量化微调模型,以便与TensorRT-LLM一起部署。
https://github.com/NVIDIA/RTX-AI-Toolkit/blob/main/tutorial-llama3-finetune.md
2. 模型部署入门
部署AI模型有两条路径:在设备上或在云中。部署到设备的模型可以实现更低的延迟,并且运行时不需要调用云,但有一定的硬件要求。部署到云中的模型可以支持在任何硬件上运行的应用程序,但会产生持续的运营成本。不同的应用程序可能会选择其中一种或两种路径。RTX AI Toolkit为这两种路径都提供了工具,我们还在教程中提供了在设备和云环境中进行部署的说明。
https://github.com/NVIDIA/RTX-AI-Toolkit/blob/main/llm-deployment/README.md
NVIDIA AI Inference Manager (AIM) SDK为开发者提供了一个统一的界面,用于在多个推理后端(从云到本地PC执行环境)之间协调AI模型的部署。这一功能目前仅对部分早期访问客户开放,现在申请即可获得访问权限。
量化(设备上)推理:对于设备上的推理,支持以下推理路径:
- TensorRT-LLM:支持LoRA适配器
- llama.cpp:支持LoRA适配器
- ONNX Runtime - DML:支持LoRA适配器
FP16(云)推理:对于云部署,支持以下推理路径:
- vLLM:支持LoRA适配器和合并检查点
- NIMs:支持LoRA适配器和合并检查点
通过这些工具和路径,NVIDIA RTX AI Toolkit为Windows应用程序开发者提供了一个全面而灵活的平台,以加速AI模型的定制、优化和部署。无论是在本地设备上实现低延迟推理,还是在云中实现广泛的可访问性,该工具包都能满足开发者的需求,并推动AI在各类Windows应用中的普及和应用。
参考项目:
AI Workbench LLaMa-Factory Project
https://github.com/NVIDIA/workbench-llamafactory
LLaMa-Factory是AI Workbench中的一个重要项目,它提供了一个直观易用的图形用户界面,帮助用户轻松定制和微调大型语言模型(LLM)。通过LLaMa-Factory,用户可以选择不同的预训练模型作为基础,然后利用自己的数据集进行微调,从而创建一个高度个性化的AI模型。这个项目极大地降低了AI模型定制的门槛,使得更多开发者和企业能够根据自己的需求快速构建出适用的AI解决方案。
ChatRTX - Reference RAG Demo
https://github.com/NVIDIA/ChatRTX
ChatRTX是一个基于RTX AI Toolkit构建的参考演示项目,展示了如何使用检索增强生成(RAG)技术来提升对话系统的性能。RAG技术结合了大型语言模型的生成能力与信息检索技术,使得AI对话系统能够更准确地理解用户意图,并给出更加相关和有用的回答。通过ChatRTX Demo,用户可以亲身体验到这种先进AI对话技术的魅力,并了解如何将其集成到自己的应用中。
OpenAI Compatible Web Server
https://github.com/NVIDIA/trt-llm-as-openai-windows
OpenAI Compatible Web Server是一个与OpenAI接口兼容的Web服务器项目。它允许开发者在自己的服务器上部署和运行与OpenAI相似的AI模型,从而提供高效的推理服务。这个项目不仅提供了API接口,使得开发者能够轻松地与AI模型进行交互,还支持多种模型格式和推理引擎,满足了不同场景下的需求。通过搭建这样一个兼容OpenAI的Web服务器,开发者可以更加灵活地控制和管理自己的AI资源。
除了上述官方提供的参考项目外,RTX AI Toolkit还鼓励并支持社区开发者构建自己的项目。这些社区项目涵盖了各个领域,如自然语言处理、图像识别、智能推荐等。通过参与社区项目,开发者可以学习到更多实用的AI技术和应用案例,同时也能够与其他开发者交流和分享经验。这些社区项目不仅丰富了RTX AI Toolkit的生态系统,还为开发者提供了更多创新和合作的可能性。
更多:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号