一次利用大模型完成Jacoco code coverage报告合并的尝试

一次利用大模型完成Jacoco code coverage报告合并的尝试

Criss@陈磊
发布于 2024-07-12 16:06:50
发布于 2024-07-12 16:06:50
prompt
最近学习了pseudo写prompt,一直没有机会尝试,刚好最近在讨论Jacoco覆盖率合并的事情,因此就想用大模型试试,prompt如下:
You major at merge cover report by jacoco.Both reports are for different versions of the same project.
你的主要任务就是合并由Jacoco生成的代码覆盖报告,两个报告都是针对同一个项目不同版本的代码。两个文件就是两个输入的report1、report2的对应文件
下面是一些如何处理的为代码:
def same_line_fc(report1,report2):
# report2 is nearly cover report
# comparte two coverage reports.You find line number of the same line that the the html class is nc in report2 and fc in report1.
# the line number of report2 append to a list
# the same line is the same java code,not the line number.
#the line number append to a list
def merge_coverage_reports(report1, report2):
# Merge two coverage reports
same_list_number = same_line_fc(report1, report2)
# change report2's html the line in the same_list_number html class to fc.And return the new report2
print(merge_coverage_reports(report1, report2))
大模型反馈
我把两个html上传到了大模型,在通过上面的prmopt想得到最终的结果,其实要是这样每次合并都需大模型成本也很高。但是没想到的是大模型直接给我了一个处理代码,而不是结果。
from bs4 import BeautifulSoup
def same_line_fc(report1_content, report2_content):
soup1 = BeautifulSoup(report1_content, 'html.parser')
soup2 = BeautifulSoup(report2_content, 'html.parser')
# 获取所有行
lines1 = soup1.find_all('span', class_='fc')
lines2 = soup2.find_all('span', class_='nc')
same_line_numbers = []
# 创建一个字典来保存每行代码和对应的行号
lines_dict1 = {line.get_text(): line['id'] for line in lines1}
lines_dict2 = {line.get_text(): line['id'] for line in lines2}
# 找到在report1中为fc,而在report2中为nc的行
for code_line, line_id in lines_dict1.items():
if code_line in lines_dict2:
same_line_numbers.append(lines_dict2[code_line].replace('L', ''))
return same_line_numbers
def merge_coverage_reports(report1_content, report2_content):
same_list_number = same_line_fc(report1_content, report2_content)
soup2 = BeautifulSoup(report2_content, 'html.parser')
# 修改report2中相应行的类
for line_number in same_list_number:
line_span = soup2.find('span', id=f'L{line_number}')
if line_span:
line_span['class'] = 'fc'
return str(soup2)
# 读取HTML文件内容
with open('./to/report1.html', 'r', encoding='utf-8') as file1:
report1_content = file1.read()
with open('./to/report2.html', 'r', encoding='utf-8') as file2:
report2_content = file2.read()
# 合并报告
merged_report_content = merge_coverage_reports(report1_content, report2_content)
# 输出合并后的报告
output_path = './to/merged_report.html'
with open(output_path, 'w', encoding='utf-8') as file_out:
file_out.write(merged_report_content)
print(f"Merged report saved to {output_path}")
我也没修改直接案列就用了,结果也是出奇的好。
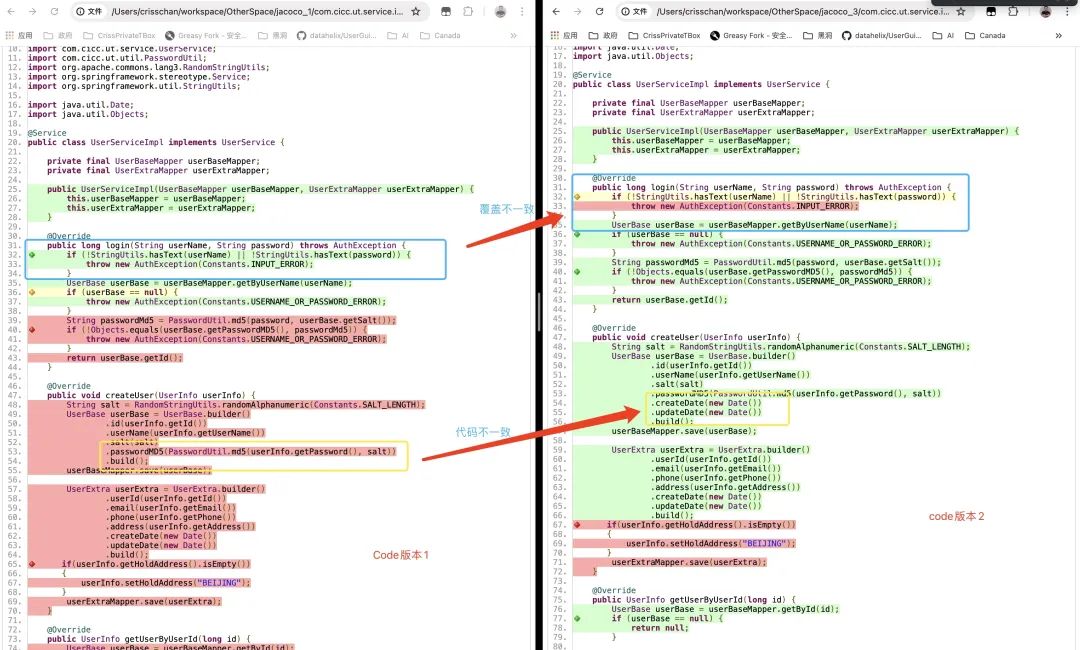
合并后的截图如下:

特别注意
其实如上的合并在Jacoco的解决原理上并不科学,一些合并前是红色,合并后是绿色的代码也并不一定是合理的以及正确的,这有可能只是一种视觉上的合并而不是真正意义上的Code Coverage的合并,但是大模型的这次利用给我开启了新的思路。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号