《书生大模型实战营第3期》入门岛 学习笔记与作业:Python 基础知识

《书生大模型实战营第3期》入门岛 学习笔记与作业:Python 基础知识

流川疯
发布于 2024-07-26 12:35:23
发布于 2024-07-26 12:35:23
Python 简介

官网:
文档:
包管理:
python 环境配置可以参考本人系列博客:
- python开发简介:【集成开发环境 IDE】
- python开发简介:【Conda,Pip】虚环境搭建、配置
- python开发简介:【jupyter notebook】实战配置
- python开发简介: 编码规范与工程基础实践
- 使用 jupyter hub /lab搭建机器学习工作台
- 使用跨平台的visual studio code 进行python 开发
(综合内容老版本)
其实Python 的环境配置在所有编程技术栈中是相对简单的,由于conda,pip 的存在。古早c++, Java 程序员入职第一周基本周报都是写做环境配置,Python基本只要一天就能搞定。
本文主要由以下四大块内容组成:
- Python(Miniconda)的安装
- Python基础语法
- Numpy基础(选修)
- vscode 远程连接InternStudio开发机打断点调试 python 程序
1 安装Python
TIPS: InternStudio开发机已经为大家准备好了conda环境,不需要再安装。【云平台开箱即用非常重要!】
这部分是为了给那些想在自己电脑上配置环境来练手的,已经装好了的可以跳过哈。
推荐直接安装miniconda(anaconda也可以)来安装python,这样方便管理开发环境。
1.1 什么是conda?
Conda是一个开源的软件包管理系统和环境管理系统,它主要用于安装多个版本的软件包及其依赖关系,并能轻松地在它们之间切换。以下是关于Conda的详细介绍:
1.1.1 功能与作用:
- 包管理:Conda可以帮助用户轻松地安装、更新和卸载各种软件包。它提供了一个庞大而丰富的社区仓库——Anaconda仓库,内含数千个优化过并经过验证的常见Python软件包,也包含其他编程语言(如R)的工具。
- 环境管理:使用Conda,用户可以创建独立且隔离的开发环境,为每个项目或应用程序设置不同的版本或配置文件,确保它们之间不会相互干扰,对于处理不同的依赖关系非常重要。
- 跨平台支持:Conda适用于Windows、Mac和Linux,使在不同平台上共享代码变得更加容易,避免由于系统差异导致的问题。
1.1.2 常用命令:
conda list:列出当前conda环境所链接的软件包。conda create:创建一个新的conda环境。例如,conda create -n myenv python=3.8会创建一个名为myenv的新环境,并指定Python版本为3.8。conda activate:激活一个已存在的conda环境。conda deactivate:退出当前激活的环境。conda install:在当前激活的环境中安装包。conda update:更新包或conda本身到最新版本。conda remove:从当前环境中卸载包。conda env list:显示所有已创建的环境。
1.1.3 适用性:
Conda不仅为Python程序创建,也可以打包和分发其他软件,并且支持多种编程语言,包括Python、R、Ruby、Lua、Scala、Java、JavaScript、C/C++等。它被广泛用于数据分析、科学计算和机器学习领域,提供了简单而强大的工具来创建、部署和维护这些领域所需的环境。总的来说,Conda是一个在数据分析和软件开发领域非常有用的工具,特别是当需要管理多个项目和不同版本的依赖时,Conda可以大大简化环境和依赖管理的复杂性。
1.2 Python安装与学习环境准备
如果在本地想搭建python环境练手的话,可以安装miniconda。(开发机已经准备好conda环境,无需重复安装)
1.2.1 下载miniconda
miniconda和anaconda都可以通过官网下载,也可以去清华源下载。
清华源miniconda下载链接: 清华大学开源软件镜像站 | Tsinghua Open Source Mirror(建议选择python3.9以上的版本,比如Miniconda3-py310_24.5.0)
1.2.2 安装miniconda
windows可以通过图形化的安装程序直接完成安装记得在最后一步把miniconda加入环境变量
如何换源让pip或conda安装包更快?(在境外的同学可以跳过此步骤) python的包管理pip与conda的源服务器均在境外,安装包的时候常常会碰到下载慢的情况。这时我们可以把pip与conda的源替换为国内的镜像,下面我们将刚刚安装好的环境替换为清华源。我们需要进入命令行开始进行换源,Windows可以直接打开miniconda powershell promt。
首先将 pip替换为清华源,只需要一条命令。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple接着我们来给conda替换成清华源。各系统都可以通过修改用户目录下的 .condarc 文件来修改镜像源。Windows 用户无法直接创建名为 .condarc 的文件,可先执行 conda config --set show_channel_urls yes 生成该文件之后再修改。在用户目录找到.condarc 文件后,使用文本编辑器打开,将下面的内容复制进去并保存。
channels: - defaults show_channel_urls: true default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
deepmodeling: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/接着在命令行中运行 conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
1.2.3 创建一个python练习专属的conda虚拟环境
本次教程会需要用到jupyter和numpy,所以安装完miniconda后我们还需要安装jupyter lab和numpy。
打开miniconda powershell prompt或者终端,首先我们先创建一个虚拟环境并用Pip安装jupyter lab和numpy。
conda create -n python-tutorial python=3.10
conda activate python-tutorial
pip install jupyter lab
pip install numpy本关卡的示例代码与闯关作业均为notebook(ipynb)格式,你们需要自行去github clone或者直接打包下载。下载好后我们激活环境并启动jupyter lab,然后再notebook中打开教程的两个代码文件。就可以开始本次的学习了。
conda activate python-tutorial
jupyter lab2: Python基础
参考本人博客:
或者官方教材
3: Numpy基础
参考本人博客:
- NLP开源工具包与云服务提供商
- 基础库 ---- NumPy
- 基础库 ---- Pandas
- 基础库 ---- Pandas(练习篇)
- 基础库 ---- SciPy
- 基础库 ---- matplotlib
- 机器学习 ---- Gensim
- 机器学习 ---- Scikit-learn
- 深度学习 ---- TensorFlow
- 深度学习 ---- Keras
- 深度学习 ---- Pytorch
或者官方教材
4 使用vscode连接开发机进行python debug
VSCode是由微软开发一款轻量级但功能强大的代码编辑器,开源且完全免费。它拥有丰富的插件生态系统、跨平台支持、以及内置的Git控制功能,为开发者提供了高效便捷的编码体验。
4.1 什么是debug?
当你刚开始学习Python编程时,可能会遇到代码不按预期运行的情况。这时,你就需要用到“debug”了。简单来说,“debug”就是能再程序中设置中断点并支持一行一行地运行代码,观测程序中变量的变化,然后找出并修正代码中的错误。而VSCode提供了一个非常方便的debug工具,可以帮助你更容易地找到和修复错误。
4.2 使用本地Vscode连接InternStudio开发机
首先需要安装Remote-SSH插件
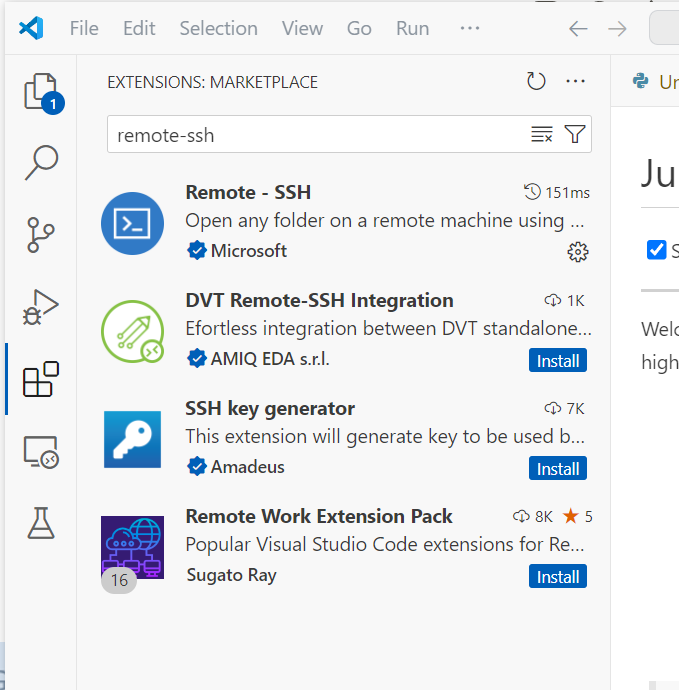
安装完成后进入Remote Explorer,在ssh目录下新建一个ssh链接
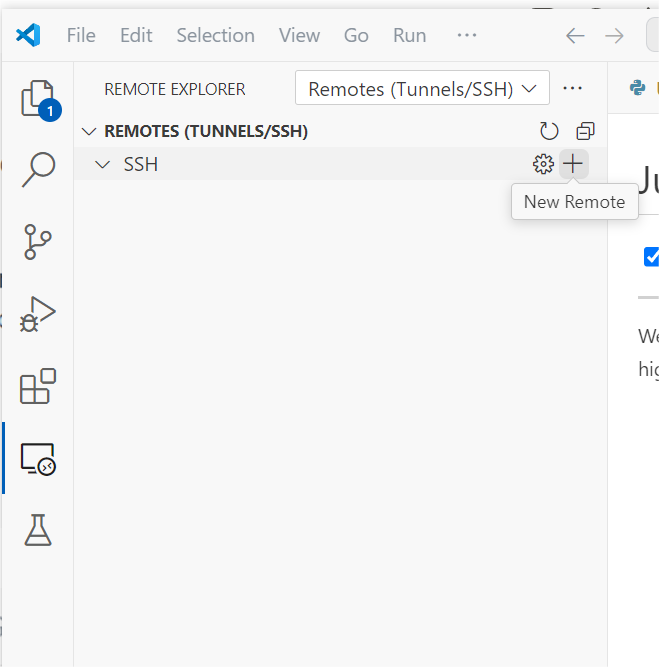
此时会有弹窗提示输入ssh链接命令,回车后还会让我们选择要更新那个ssh配置文件,默认就选择第一个就行(如果你有其他需要的话也可以新建一个ssh配置文件)。

开发机的链接命令可以在开发机控制台对应开发机"SSH连接"找到,复制登录命令到vscode的弹窗中然后回车,vscode就会开始链接InternStudio的服务器,记得此时切回去复制一下ssh的密码,待会会用到。
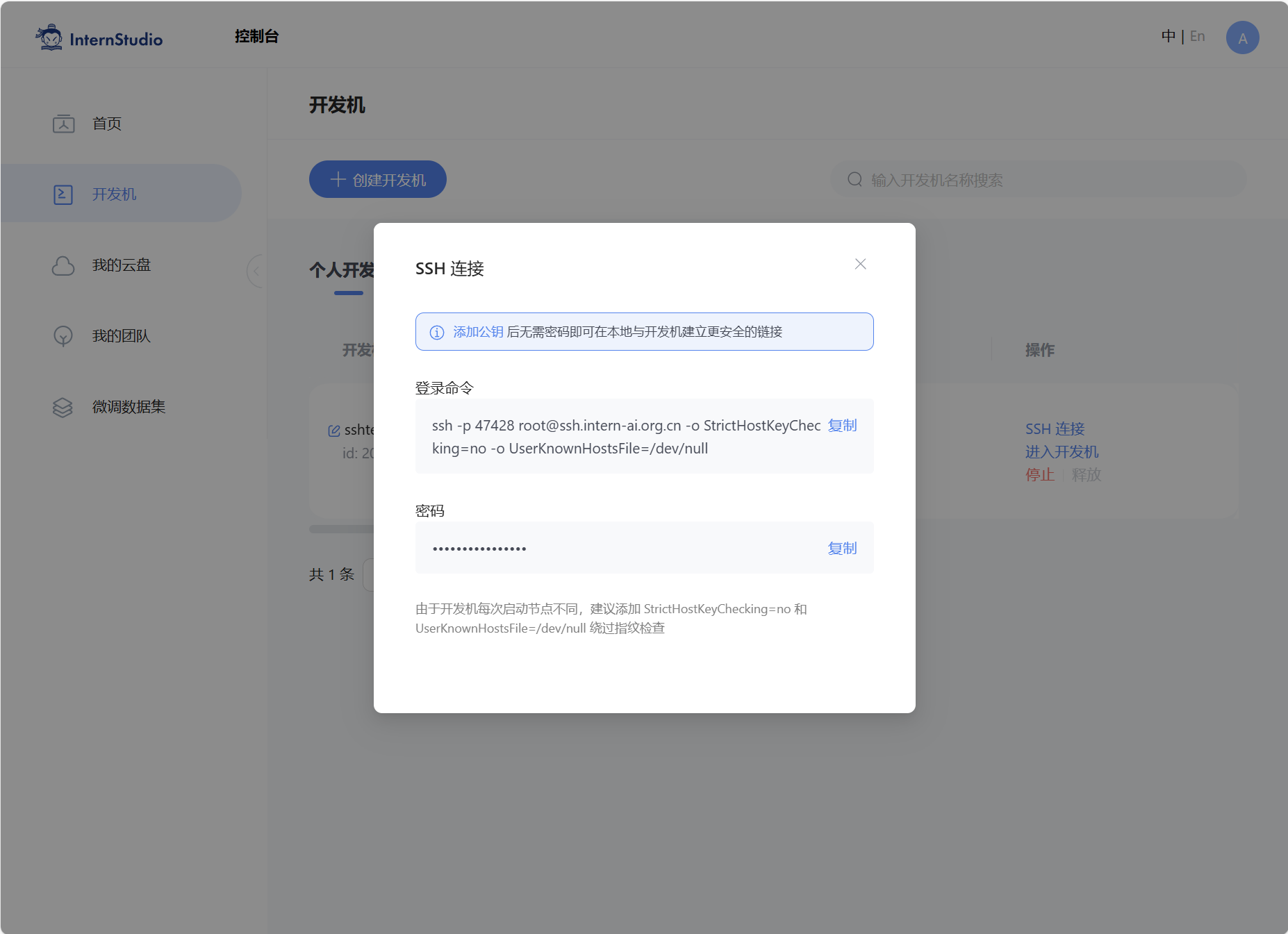
(下面这一步,和文档顺序有点不一样)

在新的弹窗中将ssh密码粘贴进去然后回车。随后会弹窗让选择远程终端的类型,这边我们的开发机是linux系统,所以选择linux就好。

首次连接会进行一些初始化的设置,可能会比较慢,还请耐心等待。后面打开文件夹的时候可能会再需要输入密码,可以一直开着开发机的控制台不要关掉以备不时之需。
看到左下角远程连接已经显示ssh连接地址SSH:ssh.intern-ai.org.cn,说明我们已经连接成功了。然后我们就可以像在本地使用vscode一样愉快的使用vscode在开发机上进行任何操作了。
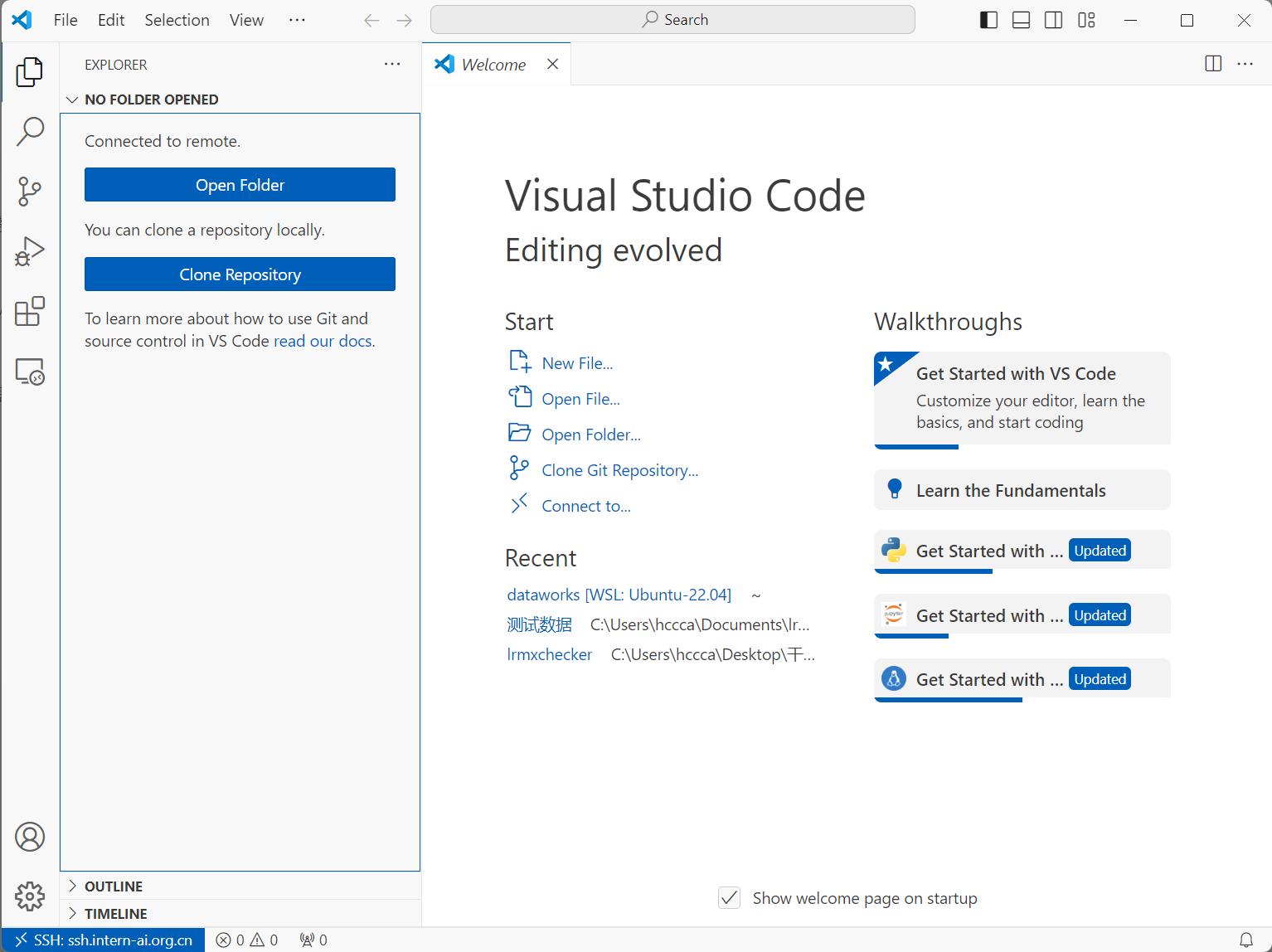
连接成功后我们打开远程连接的vscode的extensions,在远程开发机上安装好python的插件,后面python debug会用到。也可以一键把我们本地vscode的插件安装到开发机上。

4.3 在Vscode中打开终端
单击vscode页面下方有一个X和!的位置可以快速打开vscode的控制台,然后进入TERMINAL。
TIPS:右上方的+可以新建一个TERMINAL。
4.4 使用Vscode进行Python debug的流程
4.4.1 debug单个python文件
Step1.打开文件夹
在VSCode中打开直接打开root文件夹,或者你想要debug的Python文件所在的文件夹。这里可能会需要再次输入密码。下面我们以打开root文件夹为例。单击Open Folder或者左上角菜单File->Open Folder。
这边我们新建一个文件夹,写一个简单的python程序来做debug演示。
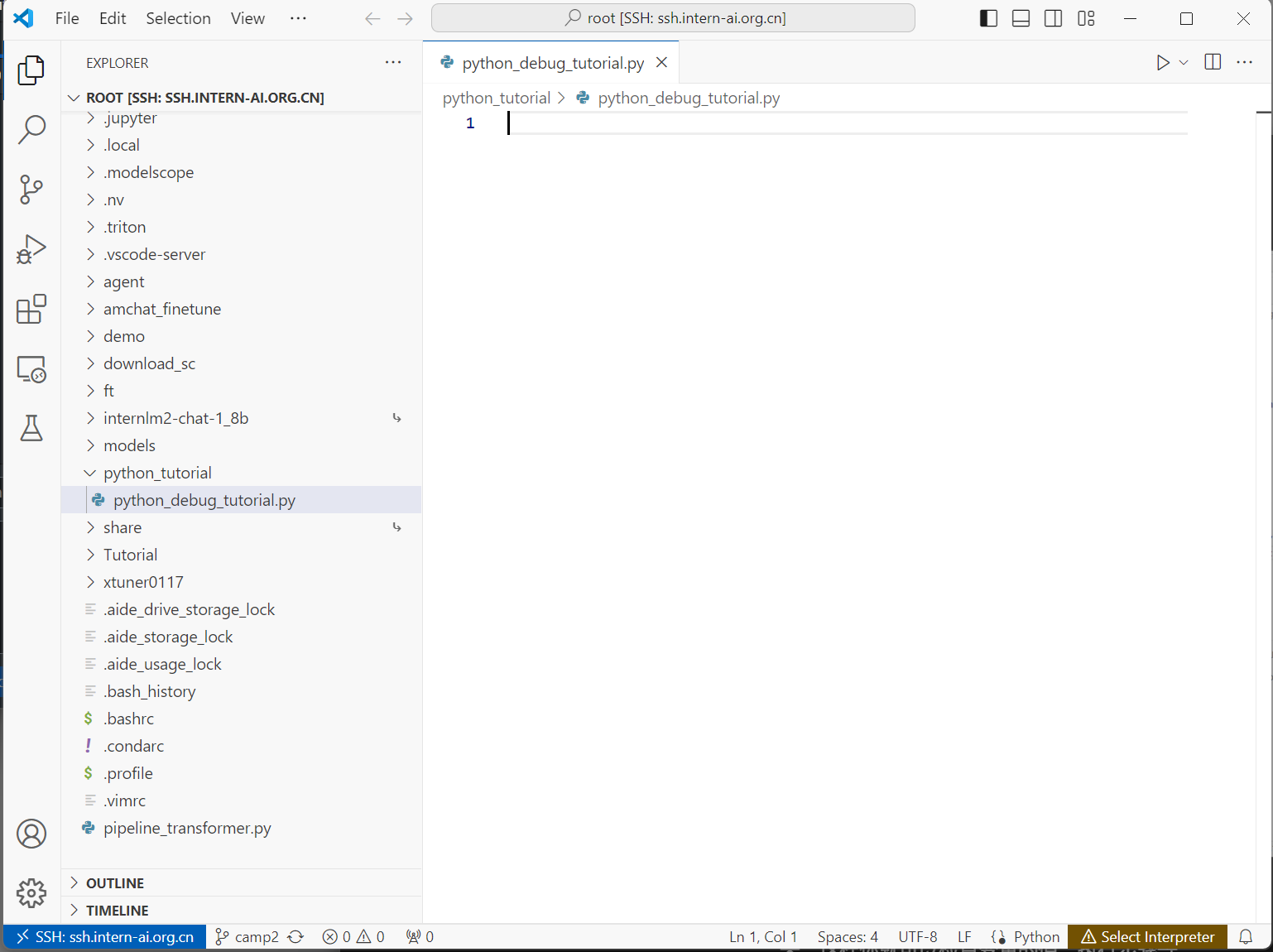
def add_numbers(a,b,c):
sum = 0#这里其实覆盖了python自带的sum方法。
sum +=a
sum +=b
sum +=c
print("The sum is ",sum)
if __name__ =='__main__':
x,y,z = 1,2,3
result = add_numbers(x,y,z)#图中代码这里写成1,2,3了
print("The result of sum is ",result)新建python文件后我们如果想要运行,首先需要选择解释器。单击右下角的select interpreter,vsconde会自动扫描开发机上所有的python环境中的解释器。这里我们只要选conda中的base就行了,后面各位如果要使用其他虚拟环境就在这选择对应的解释器就可以。
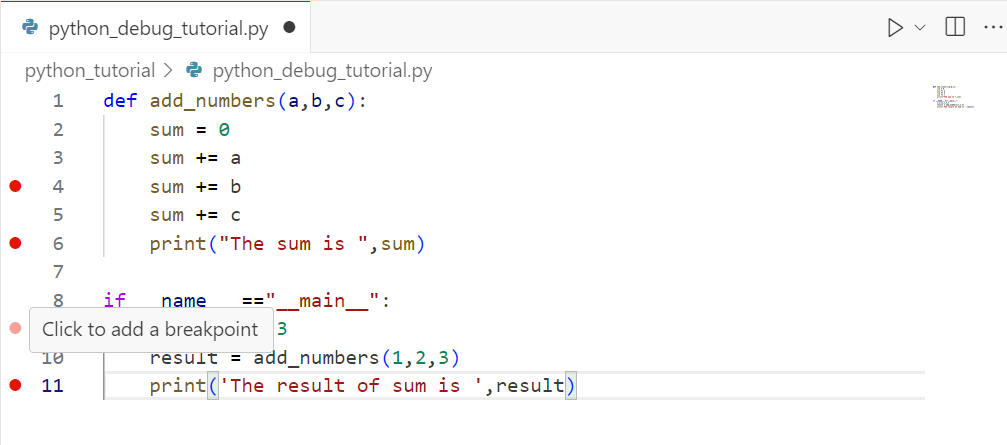
Step2.设置断点
在代码行号旁边点击,可以添加一个红点,这就是断点(如果不能添加红点需要检查一下python extension是否已经正确安装)。当代码运行到这里时,它会停下来,这样你就可以检查变量的值、执行步骤等。
Step3.启动debug
点击VSCode侧边栏的“Run and Debug”(运行和调试),然后点击“Run and Debug”(开始调试)按钮,或者按F5键。
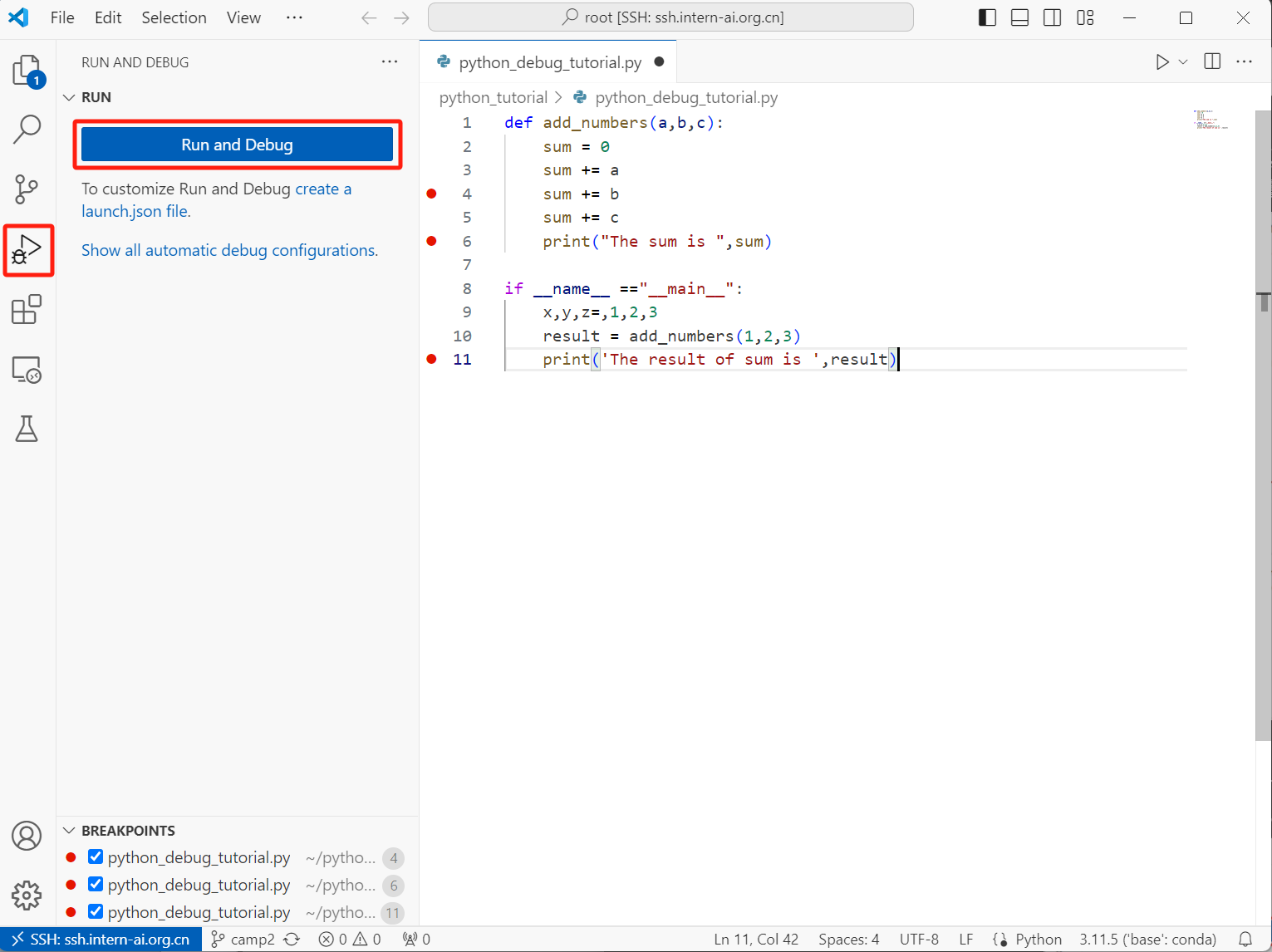
单击后会需要选择debugger和debug配置文件,我们单独debug一个python文件只要选择Python File就行。然后你的代码会在达到第一个断点之前运行,在第一个断点处停下来。
Step4.查看变量
当代码在断点处停下来时,你可以查看和修改变量的值。在“Run and Debug”侧边栏的“Variables”(变量)部分,你可以看到当前作用域内的所有变量及其值。
Step5.单步执行代码
你可以使用“Run and Debug”侧边栏顶部的按钮来单步执行代码。这样,你可以逐行运行代码,并查看每行代码执行后的效果。

在这里插入图片描述
debug面板各按钮功能介绍:
1: continue: 继续运行到下一个断点2: step over:跳过,可以理解为运行当前行代码,不进入具体的函数或者方法。3: step into: 进入函数或者方法。如果当行代码存在函数或者方法时,进入代码该函数或者方法。如果当行代码没有函数或者方法,则等价于step over。4: step out:退出函数或者方法, 返回上一层。5: restart:重新启动debug6: stop:终止debug
Step6.修复错误并重新运行
如果你找到了代码中的错误,可以修复它,然后重新运行debug来确保问题已经被解决。
通过遵循以上步骤,你可以使用VSCode的debug功能来更容易地找到和修复你Python代码中的错误。可以自己编写一个简单的python脚本,并尝试使用debug来更好的理解代码的运行逻辑。记住,debug是编程中非常重要的一部分,所以不要怕花时间在这上面。随着时间的推移,你会变得越来越擅长它!
4.4.2 在vscode使用命令行进行debug
很多时候我们要debug的不止是一个简单的python文件,而是很多参数,参数中不止会有简单的值还可能有错综复杂的文件关系,甚至debug一整个项目。这种情况下,直接使用命令行来发起debug会是一个更好的选择。
4.4.2.1 vscode设置
vscode支持通过remote的方法连接我们在命令行中发起的debug server。首先我们要配置一下debug的config。
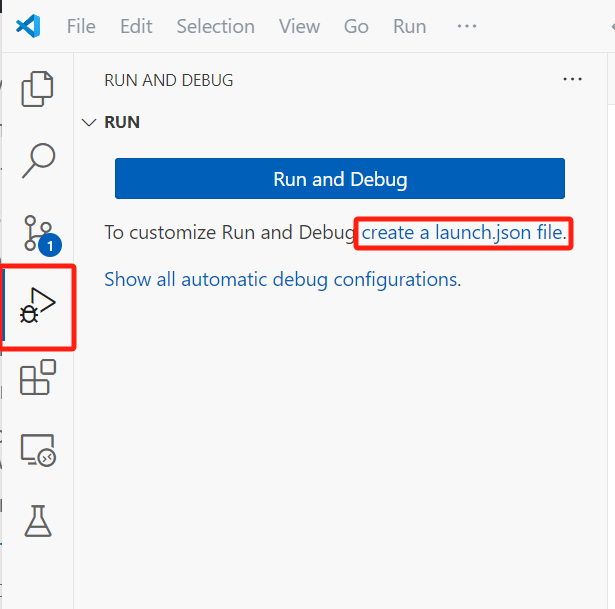
还是点击VSCode侧边栏的“Run and Debug”(运行和调试),单击"create a lauch.json file"
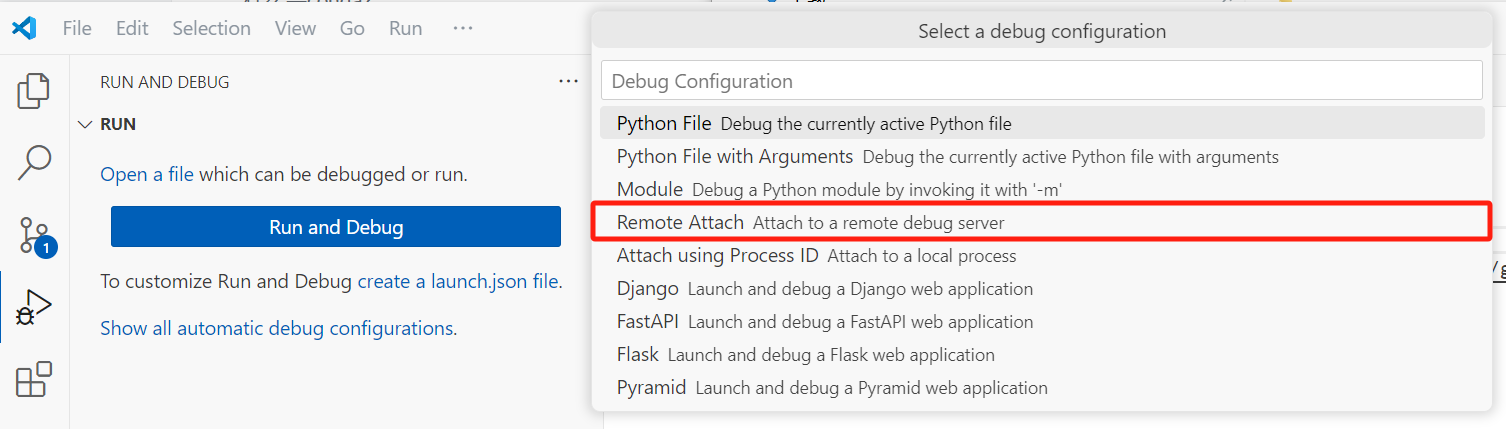


选择debugger时选择python debuger。选择debug config时选择remote attach就行,随后会让我们选择debug server的地址,因为我们是在本地debug,所以全都保持默认直接回车就可以了,也就是我们的server地址为localhost:5678。
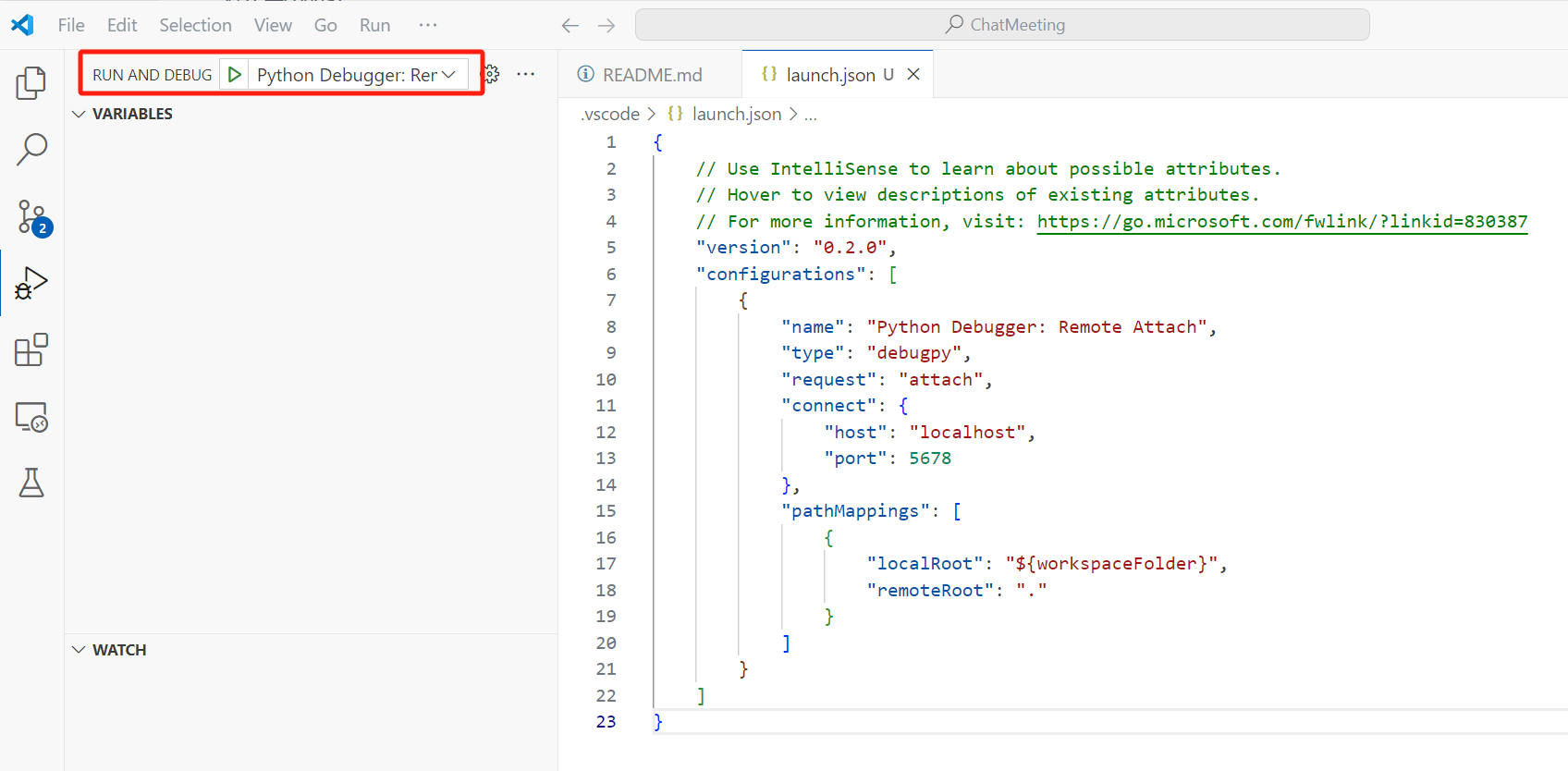
配置完以后会打开配置的json文件,但这不是重点,可以关掉。这时我们会看到run and debug界面有变化,出现了debug选项。
4.4.2.2 debug命令行
现在vscode已经准备就绪,让我们来看看如何在命令行中发起debug。如果没有安装debugpy的话可以先通过pip install debugpy安装一下。
python -m debugpy --listen 5678 --wait-for-client ./myscript.py./myscript.py可以替换为我们想要debug的python文件,后面可以和直接在命令行中启动python一样跟上输入的参数。记得要先在想要debug的python文件打好断点并保存。--wait-for-client参数会让我们的debug server在等客户端连入后才开始运行debug。在这就是要等到我们在run and debug界面启动debug。
先在终端中发起debug server,然后再去vscode debug页面单击一下绿色箭头开启debug。

在这里插入图片描述
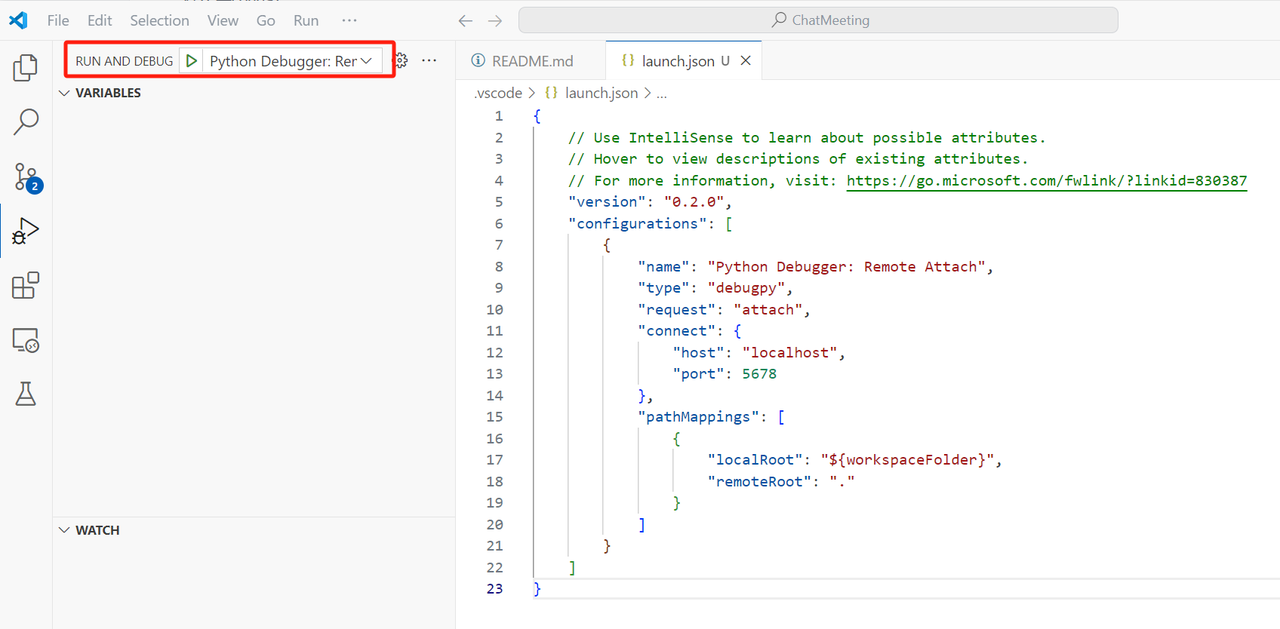
接下来的操作就和上面一样了。

4.4.2.3 使用别名简化命令
这边有个不方便的地方,python -m debugpy --listen 5678 --wait-for-client这个命令太长了,每次都打很麻烦。这里我们可以给这段常用的命令设置一个别名。
在linux系统中,可以对 ~/.bashrc 文件中添加以下命令
alias pyd='python -m debugpy --wait-for-client --listen 5678'然后执行
作业
任务概览
任务类型 | 任务内容 | 预计耗时 |
|---|---|---|
闯关任务 | Python实现wordcount | 15mins |
闯关任务 | Vscode连接InternStudio debug笔记 | 15mins |
闯关作业总共分为两个任务,两个任务均完成视作闯关成功。
请将作业发布到知乎、CSDN等任一社交媒体,将作业链接提交到以下问卷,助教老师批改后将获得 50 算力点奖励!!!
提交地址:https://aicarrier.feishu.cn/share/base/form/shrcnZ4bQ4YmhEtMtnKxZUcf1vd
任务一
请实现一个wordcount函数,统计英文字符串中每个单词出现的次数。返回一个字典,key为单词,value为对应单词出现的次数。
Eg:
Input:
"""Hello world!
This is an example.
Word count is fun.
Is it fun to count words?
Yes, it is fun!"""Output:
{'hello': 1,'world!': 1,'this': 1,'is': 3,'an': 1,'example': 1,'word': 1,
'count': 2,'fun': 1,'Is': 1,'it': 2,'to': 1,'words': 1,'Yes': 1,'fun': 1 }TIPS:记得先去掉标点符号,然后把每个单词转换成小写。不需要考虑特别多的标点符号,只需要考虑实例输入中存在的就可以。
text = """
Got this panda plush toy for my daughter's birthday,
who loves it and takes it everywhere. It's soft and
super cute, and its face has a friendly look. It's
a bit small for what I paid though. I think there
might be other options that are bigger for the
same price. It arrived a day earlier than expected,
so I got to play with it myself before I gave it
to her.
"""
def wordcount(text):
pass为了实现这个wordcount函数,我们首先需要去除字符串中的标点符号,并将所有字母转换为小写(可选,但为了简化比较通常这样做)。然后,我们可以使用空格分割字符串以获取单词列表,并使用字典来统计每个单词出现的次数。
以下是实现这一功能的Python代码:
import re
from collections import defaultdict
def wordcount(text):
# 去除标点符号并转换为小写
cleaned_text = re.sub(r'[^\w\s]', '', text.lower())
# 分割字符串为单词列表
words = cleaned_text.split()
# 使用defaultdict来简化字典的创建过程
word_counts = defaultdict(int)
# 统计每个单词出现的次数
for word in words:
word_counts[word] += 1
# 将defaultdict转换为普通字典(如果需要)
return dict(word_counts)
# 示例输入
text = """
Got this panda plush toy for my daughter's birthday,
who loves it and takes it everywhere. It's soft and
super cute, and its face has a friendly look. It's
a bit small for what I paid though. I think there
might be other options that are bigger for the
same price. It arrived a day earlier than expected,
so I got to play with it myself before I gave it
to her.
"""
# 调用函数并打印结果
word_dict = wordcount(text)
print(word_dict)
# 调用函数并打印结果
word_dict = wordcount(input_text)
print(word_dict)注意:由于输入字符串中包含换行符和多个空格,我们在去除标点符号后直接使用split()方法分割字符串。另外,由于我们使用了defaultdict(int),当访问字典中不存在的键时,它会自动将其初始化为0,从而简化了计数过程。最后,我们将defaultdict对象转换为普通字典(如果需要的话)。
但是,请注意,由于函数会将所有字符转换为小写,并且会忽略标点符号,所以输出字典中的键(即单词)可能与输入字符串中的实际单词略有不同。例如,‘Hello’在输出字典中变为’hello’,'world!‘变为’world’(因为没有包含感叹号)。
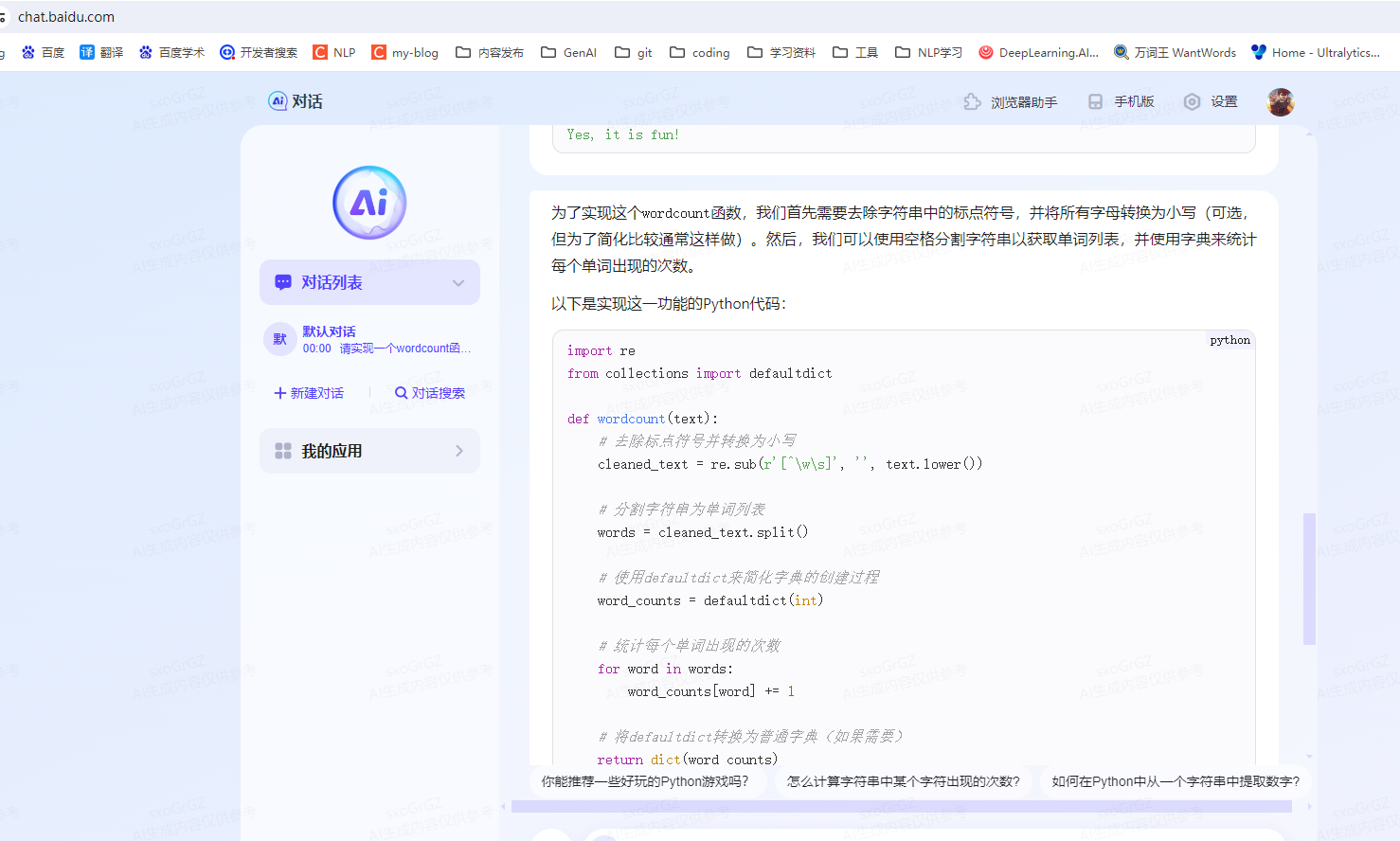
任务二
请使用本地vscode连接远程开发机,将上面你写的wordcount函数在开发机上进行debug,体验debug的全流程,并完成一份debug笔记(需要截图)。
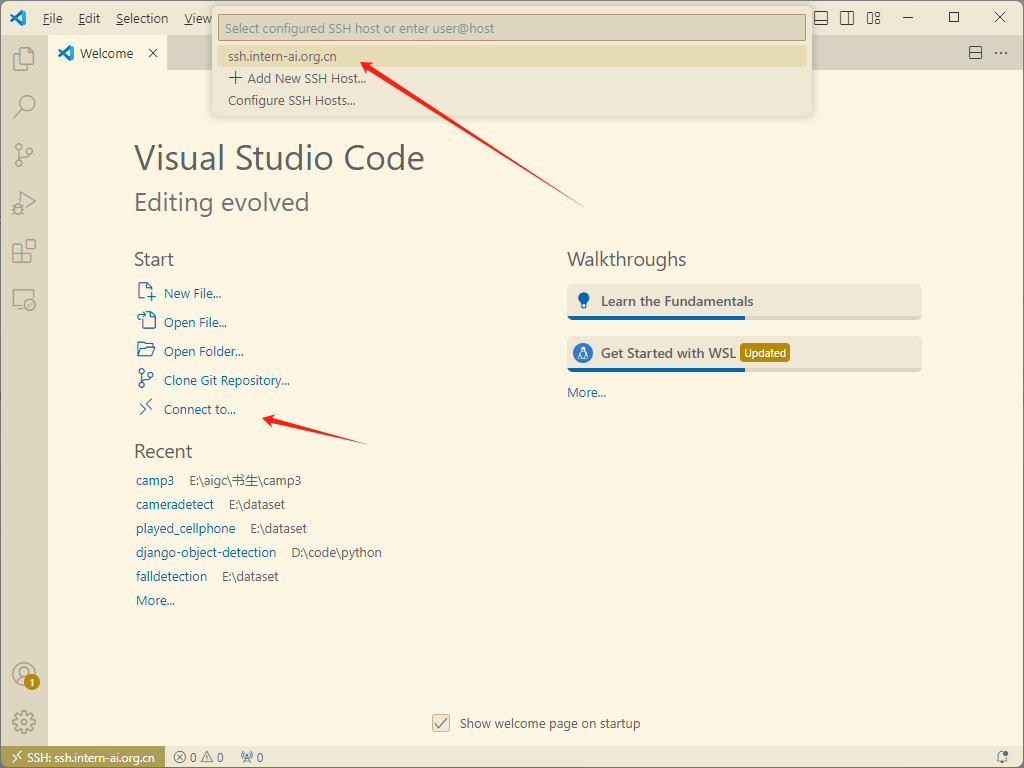
或者打开文件夹,输入password 后
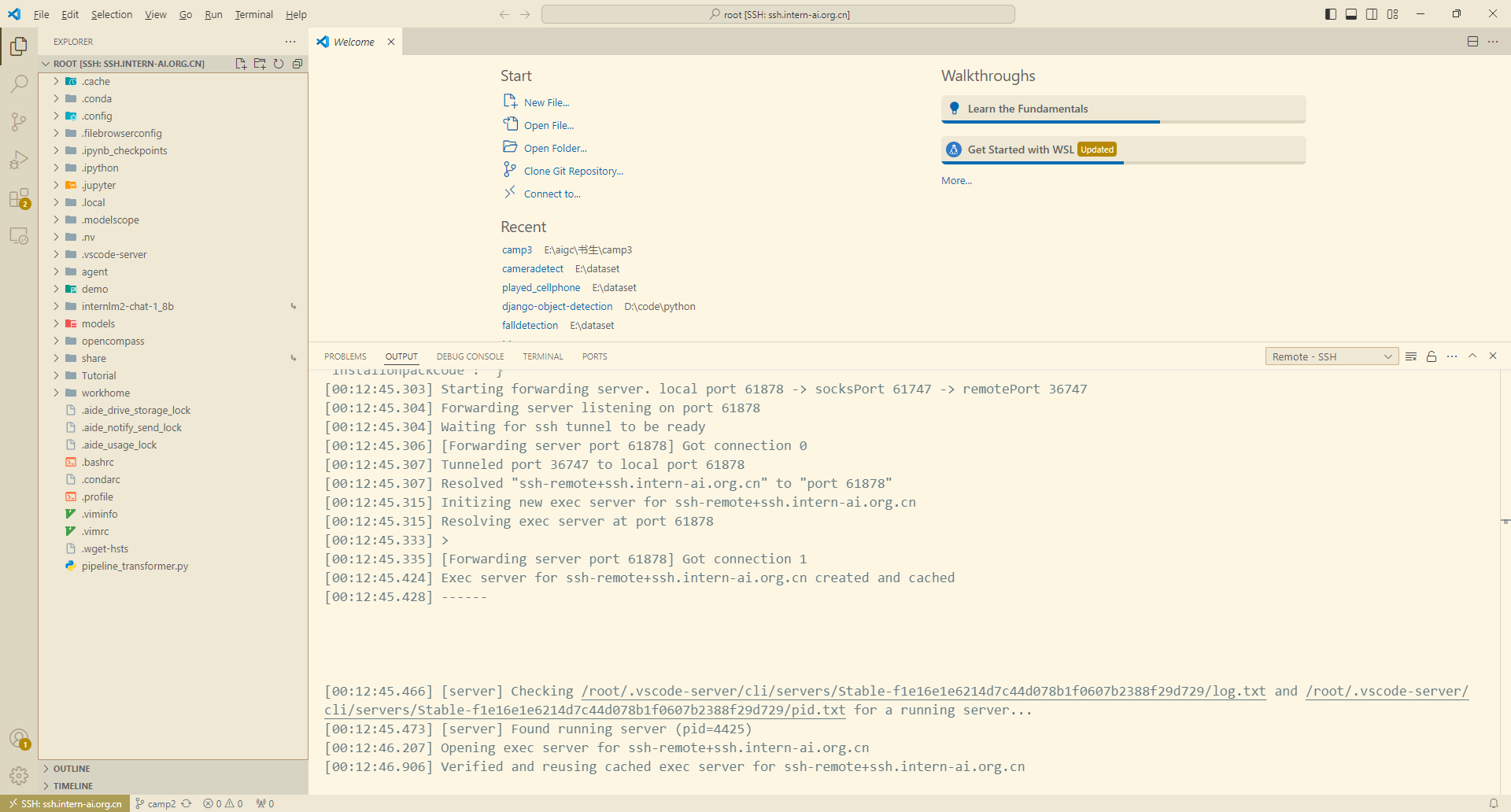
debug 是程序员的基本功!!!

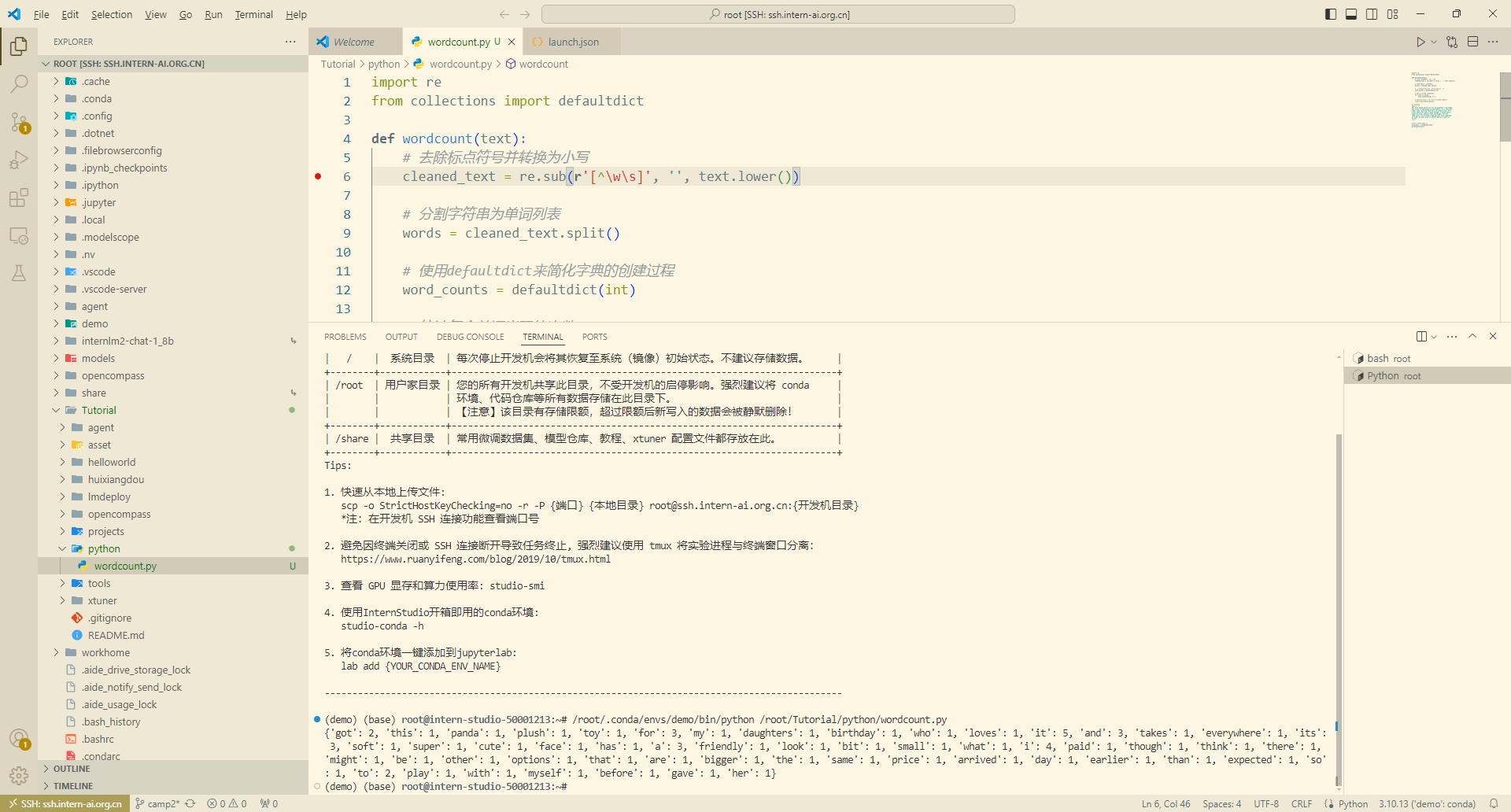
result 如下
(demo) (base) root@intern-studio-50001213:~# /root/.conda/envs/demo/bin/python /root/Tutorial/python/wordcount.py
{'got': 2, 'this': 1, 'panda': 1, 'plush': 1, 'toy': 1, 'for': 3, 'my': 1, 'daughters': 1, 'birthday': 1, 'who': 1, 'loves': 1, 'it': 5, 'and': 3, 'takes': 1, 'everywhere': 1, 'its': 3, 'soft': 1, 'super': 1, 'cute': 1, 'face': 1, 'has': 1, 'a': 3, 'friendly': 1, 'look': 1, 'bit': 1, 'small': 1, 'what': 1, 'i': 4, 'paid': 1, 'though': 1, 'think': 1, 'there': 1, 'might': 1, 'be': 1, 'other': 1, 'options': 1, 'that': 1, 'are': 1, 'bigger': 1, 'the': 1, 'same': 1, 'price': 1, 'arrived': 1, 'day': 1, 'earlier': 1, 'than': 1, 'expected': 1, 'so': 1, 'to': 2, 'play': 1, 'with': 1, 'myself': 1, 'before': 1, 'gave': 1, 'her': 1}其他学习内容
python AI 环境配置
- python开发简介:【集成开发环境 IDE】
- python开发简介:【Conda,Pip】虚环境搭建、配置
- python开发简介:【jupyter notebook】实战配置
- python开发简介: 编码规范与工程基础实践
- 使用 jupyter hub /lab搭建机器学习工作台
- 使用跨平台的visual studio code 进行python 开发
(综合内容老版本)
pyspark 的 word count 怎么写呢?
>>> textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt")
>>> wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word,1)).reduceByKey(lambda a, b : a + b)
>>> wordCount.collect()下面简单解释一下上面的语句。
textFile包含了多行文本内容,textFile.flatMap(labmda line : line.split(" “))会遍历textFile中的每行文本内容,当遍历到其中一行文本内容时,会把文本内容赋值给变量line,并执行Lamda表达式line : line.split(” “)。line : line.split(” “)是一个Lamda表达式,左边表示输入参数,右边表示函数里面执行的处理逻辑,这里执行line.split(” "),也就是针对line中的一行文本内容,采用空格作为分隔符进行单词切分,从一行文本切分得到很多个单词构成的单词集合。这样,对于textFile中的每行文本,都会使用Lamda表达式得到一个单词集合,最终,多行文本,就得到多个单词集合。textFile.flatMap()操作就把这多个单词集合“拍扁”得到一个大的单词集合。
然后,针对这个大的单词集合,执行map()操作,也就是map(lambda word : (word, 1)),这个map操作会遍历这个集合中的每个单词,当遍历到其中一个单词时,就把当前这个单词赋值给变量word,并执行Lamda表达式word : (word, 1),这个Lamda表达式的含义是,word作为函数的输入参数,然后,执行函数处理逻辑,这里会执行(word, 1),也就是针对输入的word,构建得到一个tuple,形式为(word,1),key是word,value是1(表示该单词出现1次)。
程序执行到这里,已经得到一个RDD,这个RDD的每个元素是(key,value)形式的tuple。最后,针对这个RDD,执行reduceByKey(labmda a, b : a + b)操作,这个操作会把所有RDD元素按照key进行分组,然后使用给定的函数(这里就是Lamda表达式:a, b : a + b),对具有相同的key的多个value进行reduce操作,返回reduce后的(key,value),比如(“hadoop”,1)和(“hadoop”,1),具有相同的key,进行reduce以后就得到(“hadoop”,2),这样就计算得到了这个单词的词频。
参考文献
大模型实战营 地址
本人学习系列笔记
第二期
- 《书生·浦语大模型实战营》第1课 学习笔记:书生·浦语大模型全链路开源体系
- 《书生·浦语大模型实战营》第2课 学习笔记:轻松玩转书生·浦语大模型趣味 Demo
- 《书生·浦语大模型实战营》第3课 学习笔记:搭建你的 RAG 智能助理(茴香豆)
- 《书生·浦语大模型实战营》第4课 学习笔记:XTuner 微调 LLM:1.8B、多模态、Agent
- 《书生·浦语大模型实战营》第5课 学习笔记:LMDeploy 量化部署 LLM 实践
- 《书生·浦语大模型实战营》第6课 学习笔记:Lagent & AgentLego 智能体应用搭建
- 《书生·浦语大模型实战营》第7课 学习笔记:OpenCompass 大模型评测实战
第三期
入门岛
课程资源
第三期 学院闯关手册
第三期 作业提交
第二期 学员手册
算力平台
课程文档
课程视频
代码仓库
优秀项目展示与学习
论文
其他参考
原始文档
https://github.com/InternLM/Tutorial/blob/camp3/docs/L0/Linux/readme.md
本人博客:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-07-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号