Mysql8.0 新特性 窗口函数 公共表表达式

Mysql8.0 新特性 窗口函数 公共表表达式

Java_慈祥
发布于 2024-08-06 14:49:37
发布于 2024-08-06 14:49:37
Mysql8.0 新特性 窗口函数 公共表表达式
MySQL 5.7 到 8.0,Oracle 官方跳跃了 Version 版本号
- 随之而来的就是在 MySQL 8.0 上做了许多重大更新,在往企业级数据库的路上大步前行
- 全新 Data Dictionary 设计,支持 Atomic DDL,全新的版本升级策略,安全和账号管理加强,InnoDB 功能增强等。
- 最突出的一点是多MySQL Optimizer优化 器进行了改进, 不仅在速度上得到了改善,还为用户带来了更好的性能和更棒的体验。
这里就不一一介绍了,就先介绍几个简单常用的窗口函数 公共表表达式, 感觉挺高级常用的,帮助快速开发.
准备工作:
本节操作的表,提供:
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (
`id` int(0) NOT NULL AUTO_INCREMENT COMMENT '主键',
`category_id` int(0) NULL DEFAULT NULL COMMENT '商品类型ID',
`category` varchar(15) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '商品类型',
`name` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '商品名称',
`price` decimal(10, 2) NULL DEFAULT NULL COMMENT '价格',
`stock` int(0) NULL DEFAULT NULL COMMENT '库存',
`upper_time` datetime(0) NULL DEFAULT NULL COMMENT '上架时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 20 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
INSERT INTO `goods` VALUES (1, 2, '户外运动', '登山杖', 59.90, 1500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (2, 1, '女装/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (3, 3, '电子设备', '华为手机', 3200.00, 100, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (4, 2, '户外运动', '山地自行车', 1399.90, 2500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (5, 1, '女装/女士精品', '卫衣', 89.90, 1500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (6, 1, '女装/女士精品', '呢绒外套', 399.90, 1200, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (7, 2, '户外运动', '自行车', 399.90, 1000, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (8, 3, '电子设备', '平板', 2000.00, 300, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (9, 2, '户外运动', '运动外套', 799.90, 500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (10, 3, '电子设备', '显示器', 1000.00, 500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (11, 2, '户外运动', '滑板', 499.90, 1200, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (12, 1, '女装/女士精品', '牛仔裤', 89.90, 3500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (13, 2, '户外运动', '骑行装备', 399.90, 3500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (14, 1, '女装/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (15, 3, '电子设备', '小米手机', 3100.00, 100, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (16, 1, '女装/女士精品', '连衣裙', 79.90, 2500, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (17, 3, '电子设备', '笔记本', 500.00, 1200, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (18, 3, '电子设备', '手机支架', 500.00, 1200, '2020-11-10 00:00:00');
INSERT INTO `goods` VALUES (19, 3, '电子设备', 'U盘', 100.00, 1200, '2020-11-10 00:00:00');窗口函数:
Mysql8.0 开始支持窗口函数 官方地址 隔壁Oracle Db2 好像一直都有...
- 窗口函数也称为OLAP函数
OnLine Analytical Processing 联机分析处理功能很强大,可以帮我们做很多事情. - 窗口函数的作用类似于在查询中对数据进行分组:✨ 但,不同的是分组操作,并不会把分组后的结果合并成一条记录,窗口函数将结果,置于每一条记录中. 可以更加方便的进行实时分析处理。例如,市场分析、创建财务报表、创建计划等日常性商务工作。 让我们快来了解吧!
窗口函数,可以分为 静态窗口函数 动态窗口函数
- 静态窗口函数的窗口大小是固定的,
不会因为记录的不同而不同 - 动态窗口函数的窗口大小会随着
记录的不同而变化
语法结构:
窗口函数 OVER ([PARTITION BY 窗口列清单] ORDER BY 排序列清单 ASC|DESC)
-- 在查询的时候,窗口函数列,就想是一个单独的结果集一样,将查询的结果集单独的进行分组排序,返回的一个新的列,而不会对原SELECT结果集改变.或
窗口函数 OVER 窗口名
WINDOW 窗口名 AS ([PARTITION BY 窗口列清单] ORDER BY 排序列清单 ASC|DESC)
-- 为了可以方便查看|复用,可以在查询 WHERE Group By...之后,WINDOW声明定义窗口, 方便上面SELECT 上窗口函数直接引用;OVER() 关键字指定窗口函数的,范围:
- 若后面括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算。
- 如果不为空,则支持以下4中语法来设置窗口
window_name窗口名partition by 窗口分组order by 窗口排序frame 滑动窗口
- 如果不为空,则支持以下4中语法来设置窗口
- 窗口名: 为窗口设置一个别名,用来标记窗口,如果SQL中针对这个窗口,使用频繁采用别名,可以更加清新方便复用 调用
- Partition by 分组: 按指定字段进行分组,分组后,可以在每个分组中分别执行。
- Order by 排序: 指定窗口函数按照哪些字段进行排序。执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号
- Frame 子句:为分区中的某个子集定义规则,可以用来作为滑动窗口使用
常用窗口函数:
序号函数:
ROW_NUMBER()
- ROW_NUMBER()函数能够对数据中的序号进行顺序显示
-- 窗体函数 ROW_NUMBER();
-- 就相当于窗体中每一行记录,下标行号,表示当前行数据对于窗体的第几行;
SELECT
ROW_NUMBER() OVER() as rownum, -- 设置表查询结果集行号列名 AS rownum;
god.*
FROM Goods AS god;
-- 因为OVER()是设置窗体的,如果什么都没控制则默认是整个结果集是一个窗体;
-- 窗体函数最大的特点是基于 OVER(); 设置窗体大小范围在通过窗口函数进行各种复杂聚合操作,很是方便;
-- 查询每个商品类型进行分组并标记行号
SELECT
ROW_NUMBER() OVER(PARTITION BY category_id) AS rownum, -- 基于商品类型进行分组,ROW——NUMBER()每一个窗口内计算行号;
category_id,category,name,price,stock,upper_time
FROM Goods;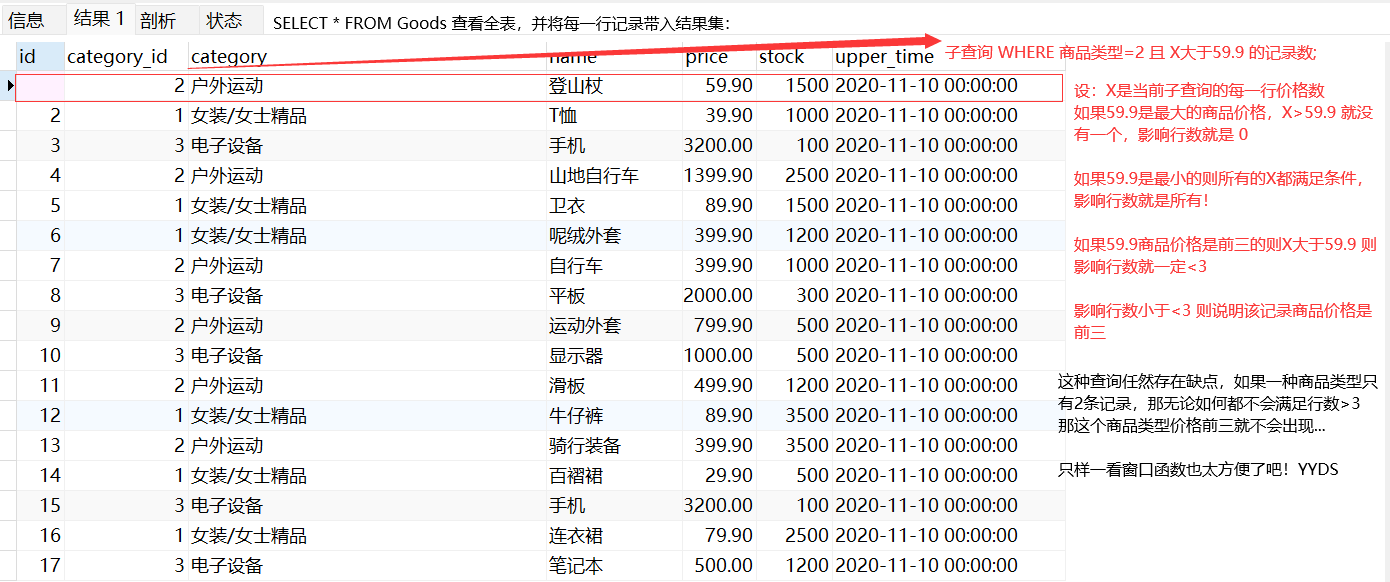
上面应该大致了解了窗体函数:
通过,OVER(…) 可以对结果集进行,分组成为一个个窗口,使用对应的窗口函数,可以对窗口中行进行操作,并将返回结果返回到一个列上
-- 仔细思考ROW_NUMBER还可以做很多事情:
-- 查询每个商品分类价格前三的商品:
SELECT * FROM(
SELECT
-- 基于商品类型进行分组,ROW——NUMBER()每一个窗口内计算行号;
ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS rownum,
category_id,category,name,price,stock,upper_time
FROM Goods
) A
WHERE A.rownum <= 3
-- 子查询,窗口函数根据商品ID进行分组,并通过商品价格进行降序排序,设置行号,行号越小当然就价格约大!
-- 外部查询只需要根据行号 <= 3 就可以知道,商品类型价格排名前三的商品了!太简单了!
窗口函数yyds,如果没有窗口函数,上面查询分类价格前三的商品如何查询呢? 就很复杂了.
-- 外层查询根据SELECT * FROM 表 遍历每一个结果进入子查询:
-- 将每一行的结果带进子查询,查询符合条件的记录数:商品类型一样 且 子查询价格>外层子查询价格
-- 影响行数>3 因为最大的价格影响行数也是最大一点大于三
SELECT * FROM goods g1
WHERE (
SELECT COUNT(1) FROM goods g2
WHERE g2.category_id = g1.category_id AND g2.price > g1.price
) <3
ORDER BY category_id,price DESC -- 最后排个序,方便查看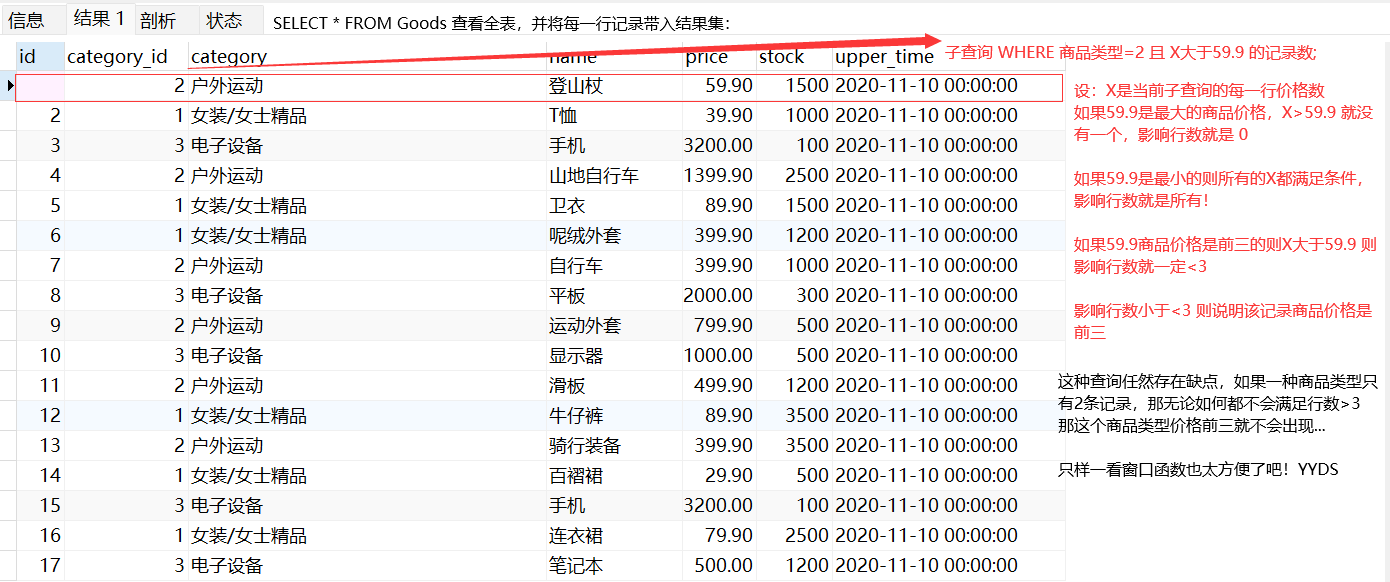
如此一看窗口函数确实方便了很多, 让我们继续深入了解吧!
RANK()
和 ROW_NUMBER() 类型,也是一种序号函数:
RANK()函数能够对序号进行并列排序,并且会跳过重复的序号,比如序号为1、1、3
- 对于排序相同的值,序号是一样的,同时后面的序号会跳过当前的序号. 后面的商品序号是不连续的.
- 业务场景: 比如班级考试,相同分数的同学应该是并列第一,而第三个同学有时候是第二还是第三呢?有的情况下会认为他是第三名就出现了排名:1、1、3
-- 使用RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息
-- 并进行排序:
-- 相同价格的商品并列排序,后面的商品排名跳过.
SELECT *
FROM(
-- RANK 和 ROW_NUMBER 都是排序函数,不同的是排序手法;
SELECT RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods
) A
WHERE category_id = 1 AND row_num <= 4; DENSE_RANK()
DENSE_RANK() 函数和 RANK() 函数类似,相同值的顺序会并列排序,但不同的是,后面的顺序不会跨值,而是继续的顺序下去.
- 业务场景: 班级考试,相同分数的同学应该是并列第一,而第三个同学分数有人认为应该是第二就出现了排名:1、1、2 的情况
SELECT *
FROM(
-- DENSE_RANK
SELECT DENSE_RANK() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num,
id, category_id, category, NAME, price, stock
FROM goods
) A
WHERE category_id = 1 AND row_num <= 4; 分布函数:概率统计
PERCENT_RANK()
**函数是等级值百分比函数。按照如下方式进行计算 ** (rank - 1) / (rows - 1) 这是一种概率统计论中的一种算法, 实际场景使用较少,了解即可😶🌫️
- rank 相当于RANK()函数产生的序号.
- rows 相当于当前窗口的总记录数. count() 函数
- PERCENT_RANK() 通常用来表示,一种概率统计率的计算…
说实话,到现在我都不太明白这个函数,可以用来干什么,算了先学习吧~
-- 计算 "电子设备"类别商品的 PERCENT_RANK 值
SELECT
PERCENT_RANK() OVER(PARTITION BY god.category_id ORDER BY price DESC) AS 'PERCENT_RANK'
-- ,ROUND(PERCENT_RANK() OVER(PARTITION BY god.category_id ORDER BY price DESC)*100,2) AS 'PERCENT_RANK' -- 如果想要展示百分比的话可以使用 ROUND(,);函数进行运算;
,RANK() OVER(PARTITION BY god.category_id ORDER BY price DESC) AS 'RANK'
,COUNT(*) OVER(PARTITION BY god.category_id) AS 'COUNT'
,god.*
FROM Goods god
WHERE category_id = 3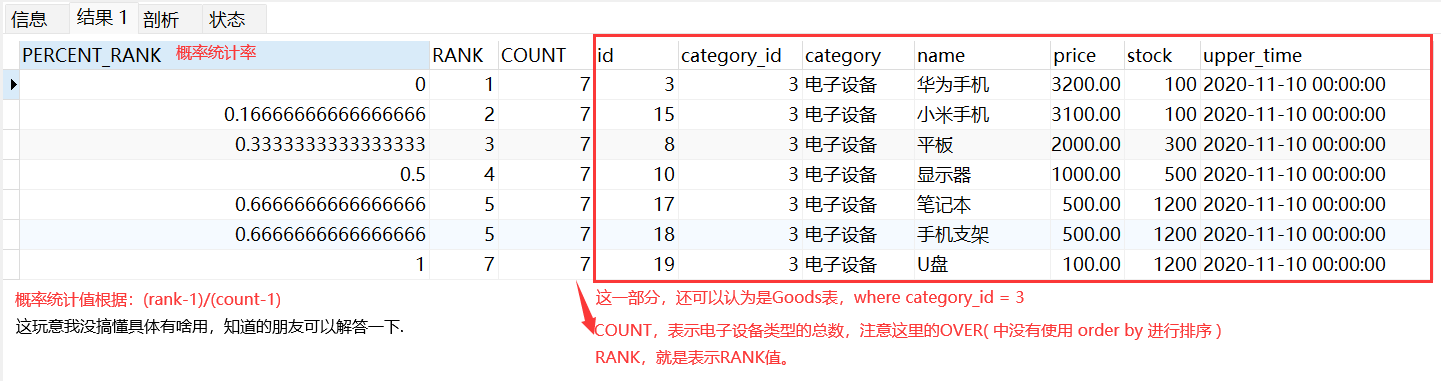
CUME_DIST()
也是一种 概率统计函数,常用于计算,某一之在当前中记录中的随机率 公式: rank/count
业务场景:
- 计算当前商品价格是最贵的概率…
-- 计算 "电子设备"类别商品的价格最大的概率
SELECT
CONCAT(ROUND(CUME_DIST() OVER(PARTITION BY god.category_id ORDER BY price ASC)*100,2),'%') AS '价格是最大的概率'
-- ,CUME_DIST() OVER(PARTITION BY god.category_id ORDER BY price ASC) AS '价格是最大的概率'
,god.*
FROM Goods god
WHERE category_id = 3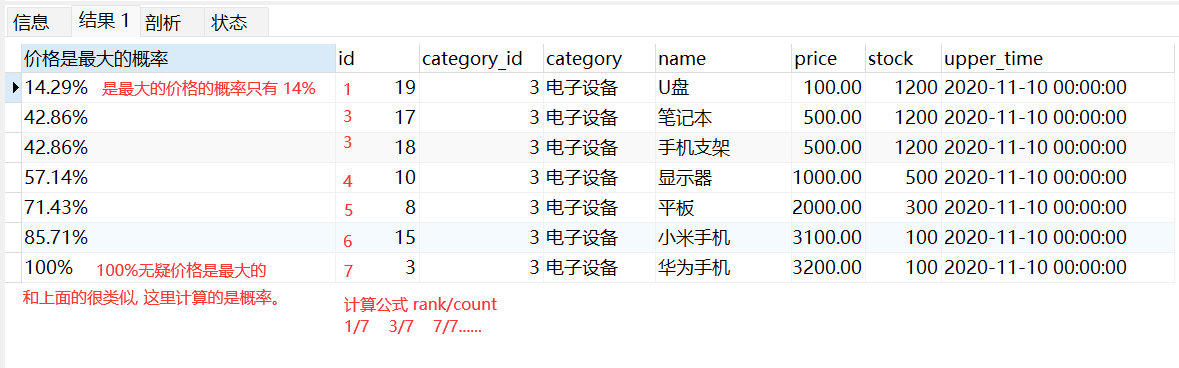
窗口函数聚合函数:
-- 窗口函数聚合函数: SUM()求和、AVG()平局数、COUNT()总记录数、MIN()最小值、MAX()最大值
-- 分组查看电子设备: 求和、平局价格、总计数、最贵商品价格、最便宜商品价格。
SELECT
god.*,
SUM(price) OVER CK1 AS '总价',
AVG(price) OVER CK1 AS '平局数',
MIN(price) OVER CK1 AS '最小值',
MAX(price) OVER CK1 AS '最大值',
COUNT(*) OVER CK1 AS '总记录数' -- OVER(PARTITION BY category_id) 替换OVER CK1 发现如果加上排序,这个统计就会一个个统计;
FROM Goods god
WHERE category_id = 3
WINDOW CK1 AS (PARTITION BY category_id ORDER BY price DESC) -- 或 () 空括号相当于就是OVER();
-- 运行发现这里的聚合函数,如果OVER()中进行了排序,每一行都是与上面的结果进行对比.
-- 如果不加排序,则总数 平均数 ... 都会根据窗口进行计算
#加排序和不加排序的结果集有一点不同,排序会根据每一行进行及以上数据行进行 "聚合操作"
SELECT
god.*,
SUM(price) OVER CK1 AS '总价',
AVG(price) OVER CK1 AS '平局数',
MIN(price) OVER CK1 AS '最小值',
MAX(price) OVER CK1 AS '最大值',
COUNT(*) OVER CK1 AS '总记录数'
FROM Goods god
WHERE category_id = 3
WINDOW CK1 AS (PARTITION BY category_id) -- 或 () 空括号相当于就是OVER();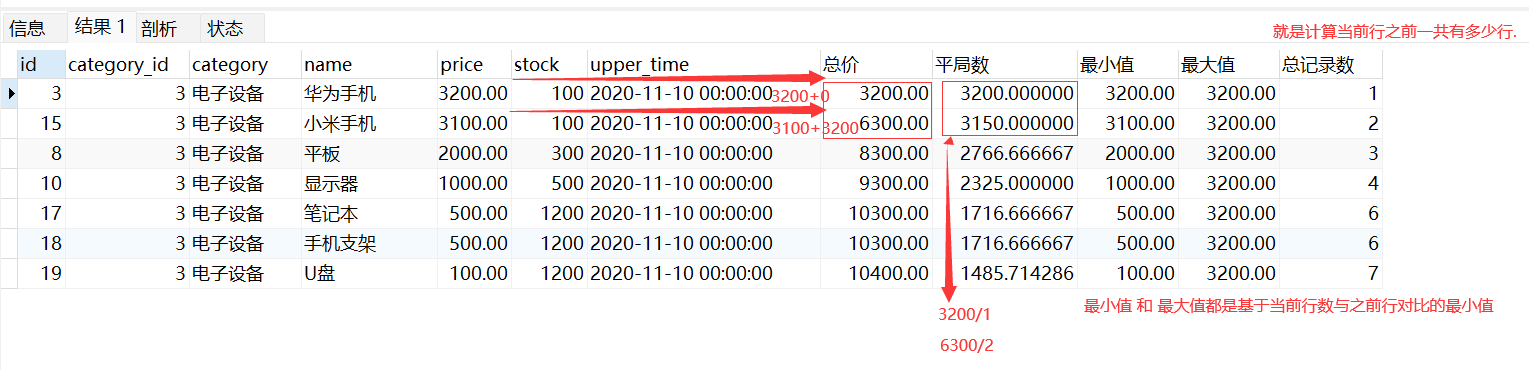
前后函数:✨
ok, 上面的两个函数使用场景估计会很少,但是下面的函数,使用场景应该会很多。比较常用,方便使用且重要:
LAG(expr,n)
返回当前行的前n行的expr的值:
这个函数很重要,它可以完成很多高级的功能,比如获取到,返回当前行的前n行的expr的值
-- LAG(要获取的列,当前行往下第n行数据)
-- 查询 "电子设备"类别的商品,升序排序,并每个商品与前一个商品价格差;
SELECT
god.id,god.category,god.name,god.price
,LAG(price,1) OVER(ORDER BY price ASC) AS '上一个记录price值'
,price - (LAG(price,1) OVER(ORDER BY price ASC)) AS '上一个商品价格差'
FROM Goods god
WHERE category_id = 3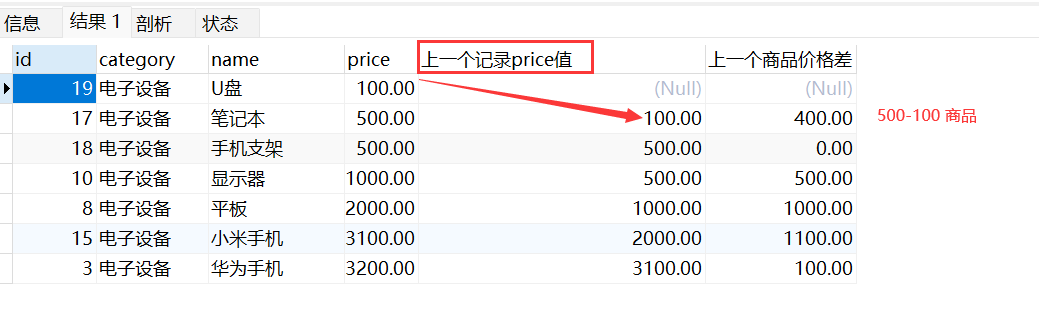
这个函数,很常用,比如商店统计,今天商品出售比昨天多少,对比等情况,这个LAG(,) 就很方便的了…
LEAD(expr,n)
与LAG(,) 相反 返回当前行的后n行的expr的值
-- 获取商品表每个记录下一个记录的值.
SELECT
god.id,god.category,god.name,god.price
,LEAD(price,1) OVER(ORDER BY price ASC) AS '下一个记录price值'
FROM Goods god
WHERE category_id = 3FIRST_VALUE(列)
FIRST_VALUE(列) 函数可以,返回第一条记录的,某个列值
业务场景:
#获取商品价格与最贵的价格差
SELECT
god.id,god.category,god.name,god.price
,FIRST_VALUE(price) OVER(ORDER BY price DESC) AS '最贵的商品价格'
,(FIRST_VALUE(price) OVER(ORDER BY price DESC))-price AS '与最贵商品价格差'
FROM Goods god
WHERE category_id = 3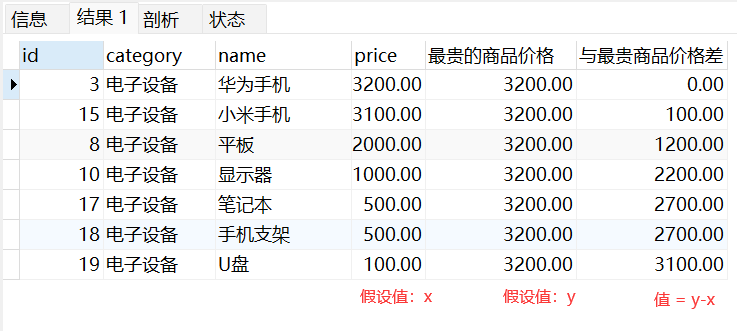
在这里插入图片描述
LAST_VALUE(列)
LAST_VALUE() 函数与FIRST_VALUE() 就想反,它是获取最后一列的值。
#获取商品价格与最贵的价格差 图1
SELECT
god.id,god.category,god.name,god.price
,LAST_VALUE(price) OVER() AS '最贵的商品价格'
,(LAST_VALUE(price) OVER())-price AS '与最贵商品价格差'
FROM Goods god
WHERE category_id = 3
ORDER BY price ASC
#OVER(ORDER BY xx) 中添加了ORDER BY进行排序,会根据当前排序的行数,影响当前窗口函数的窗口大小; 图2
SELECT
god.id,god.category,god.name,god.price
,LAST_VALUE(price) OVER(ORDER BY price DESC) AS '最贵的商品价格'
FROM Goods god
WHERE category_id = 3
ORDER BY price ASC
其他函数:
NTH_VALUE(expr,n)
NTH_VALUE(e,n); 函数返会第n行,e列的数据,和上面的LAG(e,n) 很类似~,不同的是LAG(e,n) 是当前行往下 NTH_VALUE 是基于整个窗口的第n行
实例测试:
-- NTH_VALUE(要获取的列,总窗口第n行数据)
SELECT
god.id,god.category,god.name,god.price
,NTH_VALUE(price,1) OVER(ORDER BY price ASC) AS '第一个记录price值'
,NTH_VALUE(price,2) OVER(ORDER BY price ASC) AS '第二个记录price值'
FROM Goods god
WHERE category_id = 3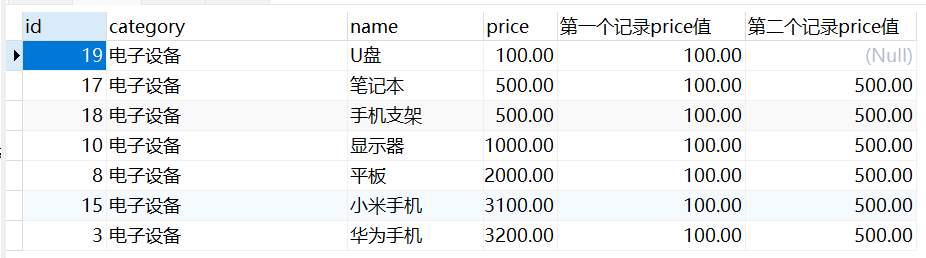
NTILE(n)
NTILE(n); 函数,相当于对于分组后的组,在进行一次划分,数将分区中的有序数据分为n个桶,记录桶编号 n不能为-数,总不能有小于0的桶吧!
实例测试:
#给电子设备中根据序号分为 n 组
SELECT
god.id,god.category,god.name,god.price
,NTILE(1) OVER(ORDER BY price ASC) AS '分区1'
,NTILE(2) OVER(ORDER BY price ASC) AS '分区2'
,NTILE(3) OVER(ORDER BY price ASC) AS '分区3'
,NTILE(8) OVER(ORDER BY price ASC) AS '分区8'
FROM Goods god
WHERE category_id = 3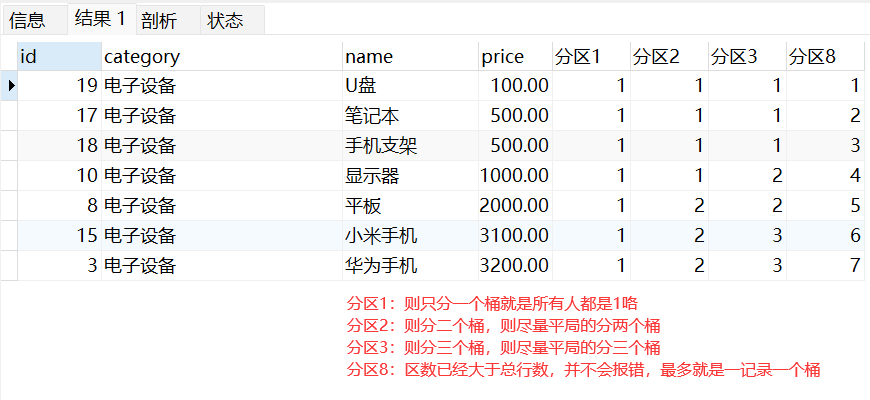
窗口函数小结:
窗口函数,可以通过 OVER() 进行规范,窗口的大小,窗口函数就是对窗口中的数据进行操作的一组函数。
- OVER() 规范了窗口的大小,PATITION 类似于分组,但又不是给数据进行分区一样,规范出窗口大小。
- 还可以通过,ORDER BY 对窗口内的数据进行排序,有时候会影响
窗口函数的结果
窗口函数的执行顺序: ✨
- 窗口函数在:
FROMJOINWHEREGROUP BYHAVING之后执行。 - 在
ORDER BYLIMITSELECTDISTINCT之前执行。
准备工作:

普通共用表表达式
语法结构:
#普通共用表表达式语法结构:
WITH CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;
-- 普通公用表表达式类似于子查询,不过,跟子查询不同的是,它可以被多次引用,而且可以被其他的普通公用表表达式所引用话不多说,直接上案例,来说明问题:
查询部门人数前三个的部门信息
#个人思路
# 每个用户都存在一个部门ID,查询用户表,部门分组,倒排DESC,count数前三个部门,就是人数最多的三个部门;
#常规写法:
-- 1.查询用户表所有部门,每个部门人数count;
SELECT department_id,Count(*) count from employees
GROUP BY department_id
ORDER BY count DESC
LIMIT 0,3 -- 获取部门人数前三个部门
-- 2.子查询,根据部门ID获得前三个部门的信息
SELECT * FROM departments
WHERE department_id IN (
SELECT * from (
SELECT department_id FROM employees
GROUP BY department_id
ORDER BY count(1) DESC
LIMIT 0,3
) aa
)
-- 可能会有人疑问,为啥要在包一个子查询 select * from (...) aa
-- 因为: 刚才执行报错了,This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery' 报错: 8.0版本不支持在 IN (子查询) 中直接写Limit
#普通公用表表达式写法:
WITH depempCount
AS (SELECT department_id FROM employees GROUP BY department_id ORDER BY count(1) DESC LIMIT 0,3)
SELECT dep.*
FROM departments dep INNER JOIN depempCount depc ON dep.department_id = depc.department_id
-- 前两行就是定义一个 共用表表达式,可以把共用表表达式理解为一个根据子查询,获得的一个虚拟表,在查询sql之前通过 WITH 别名 AS () 定义
-- 在查询过程中可以频繁使用,生命周期随着查询结束而结束.
-- 优点:
-- 可以公共使用,还避免了 IN(子查询不能使用Limit的一下特殊语法),感觉还是很nice的刚才在写上面SQL时候突然报错了,This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
- 8.0版本不支持在 IN (子查询) 中直接写Limit,所以又套另一层 (子查询)aa
递归共用表表达式
递归公用表表达式也是一种公用表表达式:
- 只不过,除了普通公用表表达式的特点以外,它还有自己的 特点,就是
可以调用自己
递归共用表表达式语法结构:
-- 语法结构和普通共用表表达式,相差不大,就在在定义:CTE别名之前加一个 RECURSIVE关键字; RECURSIVE(中译:就是递归循环的意思)
WITH RECURSIVE CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;
-- 递归公用表表达式由 2 部分组成
-- 它的子查询分为两种查询, "种子查询" "递归子查询"种子查询
- 种子查询,意思就是获得递归的初始值
- 这个查询只会运行一次,以创建初始数据集,之后递归 查询会一直执行,直到没有任何新的查询数据产生,递归返回.
递归子查询
中间通过关键字 UNION [ALL]进行连接,将返回最终的结果集
实例代码:
针对于我们常用的employees表,包含employee_id,last_name和manager_id三个字段
- 如果a是b 的管理者,那么,我们可以把b叫做a的下属
- 如果同时b又是c的管理者,那么c就是b的下属,是a的下下 属。
- 下面我们尝试用查询语句列出所有具有下下属身份的人员信息。
公用表表达式之前的处理方式:
- 第一步,先找出初代管理者,就是不以任何别人为管理者的人,把结果存入临时表
- 第二步,找出所有以初代管理者为管理者的人,得到一个下属集,把结果存入临时表
- 第三步,找出所有以下属为管理者的人,得到一个下下属集,把结果存入临时表
- 第四步,找出所有以下下属为管理者的人,得到一个结果集
临时表,也类似与 公用表,但它生命周期定义在一次服务会话中,只有服务重启才会进行回收,不然一直存在服务中.相对影响性能
递归共用表表达式
- 用递归公用表表达式中的种子查询,找出初代管理者。字段 n 表示代次,初始值为 1 表示是第一 代管理者
- 用递归公用表表达式中的递归查询,查出以这个递归公用表表达式中的人为管理者的人,并且代次 的值加 1 直到没有人以这个递归公用表表达式中的人为管理者了,递归返回。
- 在最后的查询中,选出所有代次大于等于 3 的人,他们肯定是第三代及以上代次的下属了,也就是 下下属了
WITH RECURSIVE cte
AS
(
-- 种子查询,找到第一代领导
SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100
UNION ALL
-- 递归子查询
-- 自己调用自己 cte 循环递归,并且每次n+1,用来区分员工的等级n越高则级别越低
SELECT a.employee_id,a.last_name,a.manager_id,n+1 FROM employees AS a JOIN cte
ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人
)
SELECT employee_id,last_name FROM cte WHERE n >= 3; -- 最后通过n>3获得所有大领导 中领导 小领导 本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-08-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号