手机上的 GPT-4V 级多模态大型语言模型!

手机上的 GPT-4V 级多模态大型语言模型!

AIGC 先锋科技
发布于 2024-08-19 16:14:09
发布于 2024-08-19 16:14:09

近年来,多模态大型语言模型(MLLMs)的爆发性增长已经从根本上改变了AI研究和产业的前景,为作者揭示了迈向下一个AI里程碑的光明道路。然而,由于运行具有大量参数和巨大计算成本的MLLM的成本高昂,使得其在大规模实际应用中面临巨大挑战。最为突出的挑战来自于运行具有大量参数和巨大计算成本的MLLM的高昂成本。因此,大部分的MLLM需要部署在高性能云端服务器上,这极大地限制了它们的应用范围,例如移动设备、离线、能源敏感和隐私保护场景。 在这篇论文中,作者提出了MiniCPM-V,这是一个系列的端侧设备上高效部署的MLMs。通过在架构、预训练和对齐中集成最新的MLLM技术,最新一代的MiniCPM-Llama3-V 2.5 具有几个显著的特点: (1)强大的性能,在11个流行基准测试中超越了GPT-4V-1106,Gemini Pro和Claude 3的性能,这展示了MiniCPM-V在OpenCompass上的最新性能; (2)强大的OCR(光学字符识别)能力且具有1.8M像素的高分辨率图像感知,在任何缩放比例下; (3)可信行为且低虚幻率,这意味着它可以可靠地执行预定的任务; (4)支持30多种语言的多语言支持; (5)高效在手机上的部署,这使MiniCPM-V成为了端设备上的MLLM部署的一个代表例子。 更重要的是,MiniCPM-V可以被视为一个具有前景的趋势的典型示例:(图1)实现可用性能(如GPT-4V)水平的模型大小正在迅速减小,同时端侧计算能力正在快速增长。 这共同表明,部署在端设备上的GPT-4V水平MLLM越来越可行,未来将解锁更多实际应用场景。
1 Introduction
随着多模态大型语言模型(MLLM)的快速发展,作者的理解、推理和交互能力在多个模态下有了显著提升。这不仅从根本上改变了AI研究和发展的新格局,而且为向下一个AI里程碑迈进提供了一扇诱人的窗户。然而,当前的MLLM在实际应用中仍存在很大的局限性。其中一个最突出的挑战是,目前大多数MLLM参数数量庞大,计算负担重,导致大多数MLLM只能部署在高性能云服务器上,从而产生大量的能源消耗和碳排放。这一限制极大地限制了潜在的应用范围,如在移动设备、敏感能源场景、没有稳定网络连接的离线场景以及个人和工业用户的隐私/安全保护场景等。
考虑到这些局限,越来越多的人对探索更高效、轻量级的MLLM产生了兴趣,这些模型可以在终端设备上运行。终端场景涵盖了更广泛的设备,包括移动电话、个人电脑、车辆和机器人等,这些设备普及在作者的日常生活中,且计算能力正在迅速提升。终端MLLM因为应用范围更广、计算效率更高、离线行为更强大以及隐私/安全保护更好,因此能够为实际应用提供有前景的解决方案。
然而,开发具有强大功能的终端MLLM是一项具有挑战性的任务,因为参数和推理计算预算受到了显著限制。因此,作者需要更加谨慎地进行架构设计和训练秘诀,以充分释放终端MLLM的潜在性能。在本文中,作者提出了MiniCPM-V,这是一系列可以在终端设备上部署的MLLM。MiniCPM-V的原则是实现性能和效率的良好平衡,在实际应用中这是一个更重要的目标。到目前为止,在2024年,作者已经发布了三个模型:
(1)2月,作者推出了MiniCPM-V 1.0 2B,这是第一个专门为手机设计的MLLM。(2)4月,MiniCPM-V 2.0 2B introduced,超越了强有力的较大的MLLM,如Owen-VL 9B [7],CogVLM 17B [102]和Yi-VL 34B [108]。这个迭代还引入了对高分辨率图像输入的支持,并展示了有前途的OCR功能。
(3)最近在5月,作者发布了MiniCPM-Llama3-V 2.5 8B,该模型在OpenCompass评估中超越了强大的GPT-4V-1106,Gemini Pro和Claude 3。
值得注意的是,此模型具有强大的OCR能力、高分辨率图像感知、可信赖的行为、多语言支持和高效的终端部署优化。
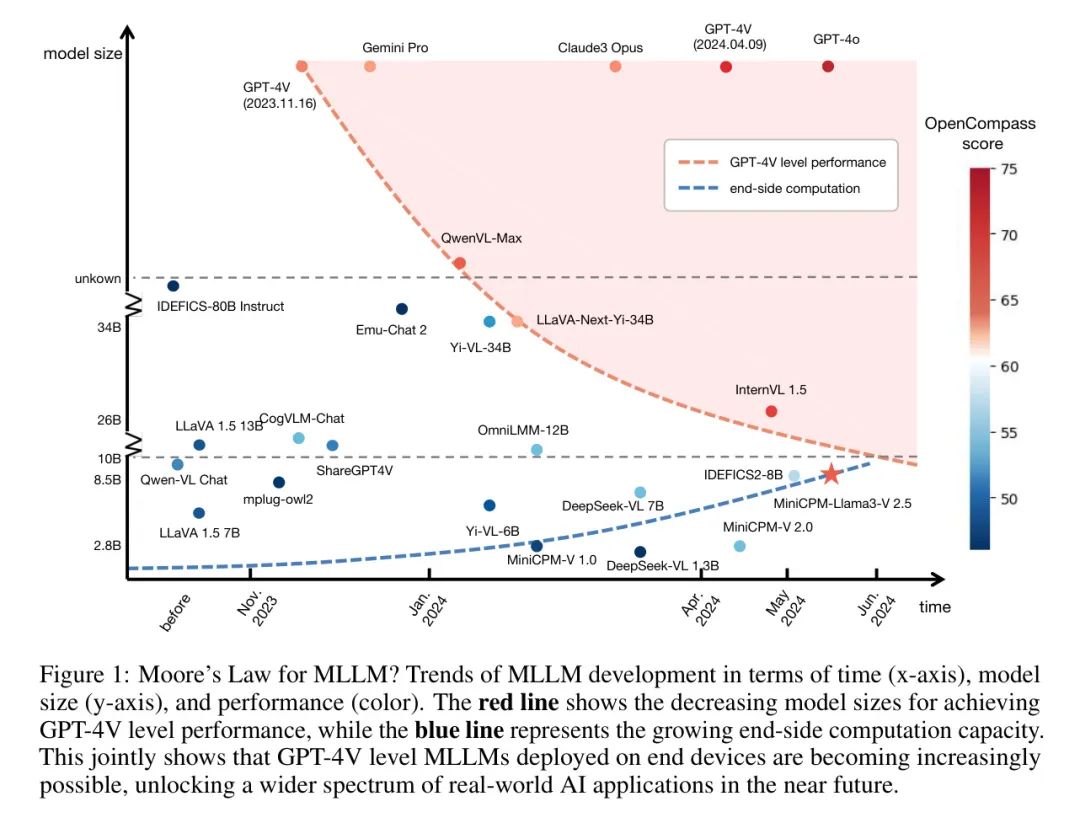
更重要的是,MiniCPM-V 可被视为一种有前途趋势的代表性例子。图1 总结了 MLLM 近期的发展情况,包括性能、参数和发布时间。作者观察到一条有趣的趋势,类似于莫尔定律 [103],用红线表示:达到 GPT-4V 水平性能的模型的尺寸正在随着时间的推移迅速减小。这种现象可能被称为 MLLM 的“莫尔定律”。同时,诸如手机和个人电脑等终端设备的计算能力也在稳步提高(由蓝线定性描绘)。这两种趋势的汇聚表明,可以在终端设备上部署具有可用性(例如 GPT-4V 水平)的 MLLM,将在不久的将来带来更广泛的可能性,并使更多的应用场景受益。从人类技术发展的历史角度来看,这一趋势也可以被视为是人类追求现有技术的最小化,这在其他科技领域曾多次见证。例如,在航天领域,最新的 SpaceX Raptor 2 火箭发动机可以实现 2,256 kN 的强大推力,质量为 1.6 吨,而 20 年前,RD-0750 火箭发动机只能实现 1,413 kN 的推动力,质量超过 4 吨 [104]。
MiniCPM-V 系列技术。在这篇文章中,作者将以最新的 MiniCPM-Llama3-V 2.5 为例,系统地介绍 MiniCPM-V 系列和其背后的关键技术:
- 领先性能。 MiniCPM-Llama3-V 2.5 在 OpenCompass 集锦的 11 个流行基准测试上,其性能优于 GPT-4V-1106、Gemini Pro 和 Claude 3。这是共同贡献于其架构、数据和训练配方精心设计的结果,作者将在以下内容中详细介绍。
- 强大的 OCR 能力。 MiniCPM-Llama3-V 2.5 在 OCRBench 上的成绩优于 GPT-4V、Gemini Pro 和 Qwen-VL-Max。它还支持高实用性的功能,例如表格转换为 Markdown 和全面 OCR 内容转录。这些主要归功于任何比例下,高达 1.8M 像素的高分辨率(例如 1344 × 1344)图像感知技术 [107]。
- 值得信赖的行为。 基于来自 RLAIF-V [112] 和 RLHF-V [111] 技术,通过 AI/人类反馈将 MLLM 行为进行对齐,MiniCPM-Llama3-V 2.5 表现出更高的可信赖性,在 Object HalBench 上的幻觉率比 GPT-4V-1106 低。
- 多语言支持。 从 VisCPM [41] 的研究中获得启发,将多语言 LLM 的集成显著降低了低资源语言中对多模态训练数据的高度依赖。借助这一基础,高质量的多语言多模态指令调优有助于 MiniCPM-Llama3-V 2.5 将其多模态能力扩展到超过 30 种语言。
- 高效的终端部署。 作者系统地集成了一系列终端优化技术,包括量化、内存优化、编译优化和 NPU 加速,使得 MiniCPM-Llama3-V 2.5 能够高效地在终端设备上部署。
作者希望MiniCPM-V系列能为揭示端侧MLLMs的潜力提供示例,并帮助吸引更多关注推动该方向的研究。遵循MLLM的莫尔定律,作者相信将会出现 increasingly强大的端侧MLLM,这些MLLM的尺寸将逐渐减小,为设备带来高效、安全和可靠的AI服务。
本工作的贡献可以概括如下:
(1)作者引入并开源了MiniCPM-V,一系列实现了性能和效率良好平衡的高效端侧MLLM。
(2)作者研究推动了MLLM向规模性能效率平衡的关键技术,揭示了这些技术的潜力。
(3)作者总结了MLLM发展的莫尔定律,并以MiniCPM-V的具代表性示例实证分析了这一趋势。
2 Related Works
多模态语言模型(MLLMs)的发展显著提高了MLLM的进展。Flamingo首次提出将预训练的视觉编码器与Chinchilla 70B LMLM相连接,并在一系列视觉语言任务上证明了MLLM的零样本和少样本能力。随着ChatGPT的出现,许多开源模型,包括BLIP-2,Kosmos-1,MiniGPT-4,LLaVA,VPGTrans等都被提出。其中,大多数是建立在与现有的预训练LLM,如Llama和Vicuna类似的基础之上的,而Kosmos-1试图从头开始训练LLM。后来,研究行人继续扩展MLLMs的功能范围并改善其视觉感知能力。Kosmos-2,CogVLM,Shikra和NeXT-Chat进一步将其本地化能力集成到使用pix2seq范式或与检测/分割模型连接的MLLM中。Qwen-VL-Chat,Yi-VL,DeepSeek-VL和InternVL更多关注通过高分辨率输入,更多的训练数据和更好的数据比例等不同的技术提高模型能力的改进。
在终端端的多模态大量语言模型。MLLMs的大量参数在训练和部署过程中导致了过高的计算成本,大大限制了其广泛的应用。最近,人们倾向于构建具有较少参数的小型LMLM。这些模型的代表是Phi [], Gemma [], MobileLLM [], MiniCPM []等。这些模型的大小恰到好处,使得它们可以适用于终端设备,如个人计算机甚至移动电话。在优化的训练策略下,终端LMLM,如MiniCPM 2B可以实现与强大的7B模型,如Llama2-7B [102] comparable的性能。类似的现象也出现在LMLM中。例如,Mini-Gemini [58]和PaliGemma [11]是基于Gemma 2B [8]构建的,而MobileVLM V2是基于MobileLlama [25]构建的。然而,终端LMLM的较小参数数量提出了重大的挑战,以构建具有强大能力的模型。MiniCPM-V系列旨在通过在架构、训练、推理和部署方面进行仔细设计来解决关键的瓶颈问题,推动终端LMLMs的潜力。
3 Model Architecture
在本节中,作者提出了MiniCPM-V模型架构,总体上勾勒出其结构和自适应高分辨率视觉编码方法。MiniCPM-V系列的设计哲学是在性能和效率之间实现良好的平衡,这是一个更实际的目标,适用于更广泛的实际应用场景。这一目标在架构设计、训练、推理和部署等各个层面得到实现。
Overall Structure
图3:模型结构。(a)整体结构 表示模型结构,包括视觉编码器、共享压缩层和LLM。(b)自适应视觉编码 处理高低分辨率输入图像的多种方面比。
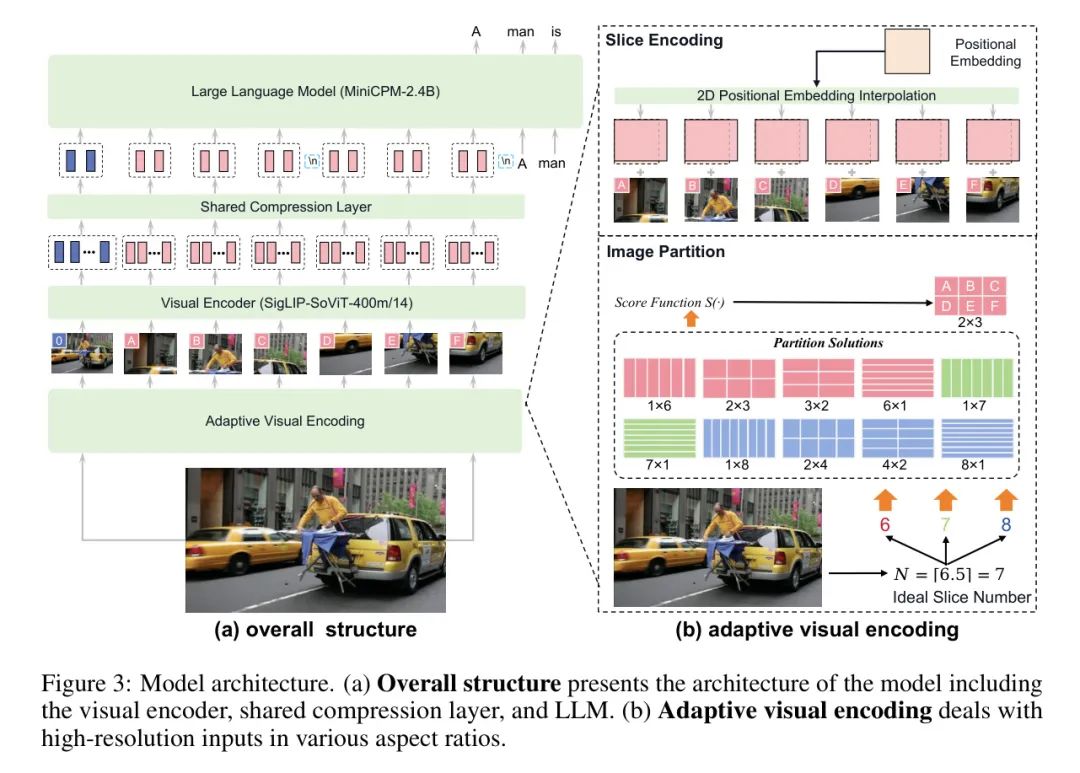
模型包括三个关键模块:视觉编码器、压缩层和LLM。输入图像首先由视觉编码器编码,利用自适应视觉编码方法。具体而言,作者使用SigLIP SoViT-400m/14 [115] 作为视觉编码器。视觉标记随后由压缩层压缩,该压缩层采用感知重采样结构,包括一层的交叉注意力。最后,压缩后的视觉标记,与文本输入一起输入到LLM进行条件文本生成。### 自适应视觉编码
近年来,人们越来越认识到视觉编码在MLLM性能中的基础作用,尤其是在细节能力方面,如OCR。有效性方面,一个好的视觉编码策略应同时尊重输入图像的底层比例和保留足够的视觉细节(高分辨率)。效率方面,图像编码过程中的视觉标记数量应适中,以便在终端设备上实现。为此,作者利用提出自适应视觉编码方法的自适应视觉编码方法。
图像分割。处理具有不同方面比的High-Resolution图像,将图像划分为切片,每个切片更好匹配ViT预训练设置的分辨率和方面比。具体而言,作者首先根据输入图像大小计算理想切片数。给定一个具有分辨率为 的图像,ViT在具有分辨率为 的图像上进行预训练,理想切片数为。然后,从集合中选择一组合和的行和列。一个好的划分应该使切片与ViT预训练设置匹配良好。为此,作者使用一个得分函数评估每个潜在的划分:
其中,是和与和的乘积之比的对数。这个得分函数用于评估基于图像大小的一对一匹配。
作者选择所有候选中得分最高的分区:
其中是在中可能的的组合。然而,当是一个质数时,可行的解可以限制为和。因此,作者另外引入和,并设。在实际中,作者设定,支持最多1.8百万像素(例如,13441344分辨率)的编码。尽管作者可以容纳更多图像切片来支持更高的分辨率,但作者故意 impose 这个分辨率上限,因为它已经很好地覆盖了大多数实际应用场景,并且进一步提高编码分辨率在性能和开销方面的收益微小。
切片编码。虽然图像分区可以确保切片与ViT预训练设置之间有很好的匹配,但每个切片的大小并不精确等于。为了将切片输入到ViT,作者首先按比例调整每个切片,使结果区域的面积大小匹配ViT预训练区域大小 。这种调整有助于防止编码的patch数量与ViT预训练设置之间的显著差异。随后,作者调整ViT的位置嵌入以适应切片的比例。这涉及将ViT的1D嵌入 Reshape 为2D格式,其中位置嵌入的数量。然后,作者通过2D插值调整以适应每个切片的尺寸。作者也包括原始图像作为额外的切片,以提供关于整个图像的整体信息。
分词压缩。在视觉编码之后,每个切片被编码为1024个标记(token),十个切片可以总共产生超过10k的标记。为了处理这个高标记计数的场景,作者使用了一个压缩模块,包括一层交叉注意力(cross-attention)和一定数量的 Query ,且2D位置受[7]中提供的启发。在实践中,每个切片的视觉标记被压缩为MiniCPM V1&2中的64个 Query ,以及MiniCPM-Llama3-V 2.5中的96个标记,都是通过这一层实现的。与具有竞争性能的其他MLLMs相比,MiniCPM-V系列中视觉标记数量明显较少,使得在GPU内存消耗、推理速度、首标记延迟和功耗方面都有更出色的效率,这使得MiniCPM-V系列更适合应用于更广泛的应用场景和社区。
空间模式(spatial schema)。为了表示每个切片相对于整个图像的位置,作者受到[9]启发,额外引入了空间模式。作者首先用两个特殊标记(和)将每个切片的标记封装起来,然后用特殊的标记“n”将切片与不同行分离开来。
4 Training
模型训练分为三个阶段:预训练阶段、有监督的微调阶段和 RLAIF-V 阶段。接下来作者将介绍训练方法。
Pre-training
在此阶段,作者使用大规模的图像文本对进行MLLM预训练。此阶段的主要目标是使视觉模块(即视觉编码器和压缩层)与LLM的输入空间对齐,并学习基础的多模态知识。预训练阶段 further 分为 3个阶段。
第一阶段。阶段的任务是 Warm up ,主要连接视觉编码器与 LLM。
(1)可训练模块。作者在第一阶段随机初始化压缩层,并在此阶段训练此模块,保持其他参数冻结。视觉编码器的分辨率设置为 224224,与视觉编码器在预训练阶段设置的分辨率相同。
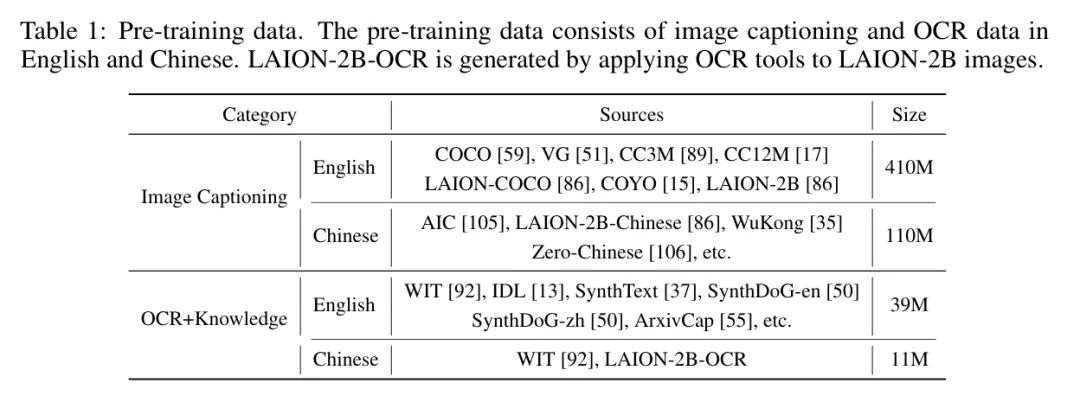
(2)数据。为了 Warm up 压缩层,作者随机从表1中的图像描述数据中选择20亿数据。执行数据清理,以去除关联较差和形式错误的文本数据,确保数据质量。
第二阶段。在压缩层的 Warm up 训练之后,阶段的任务是扩展预训练视觉编码器的输入分辨率。
(1)可训练模块。在第二阶段,作者将图像分辨率从 224224 扩展到 448448。整个视觉编码器被训练,其他参数保持冻结。
(2)数据。为了扩展预训练分辨率,作者从表1中的图像描述数据中额外选择20亿数据。
第三阶段。在扩展视觉编码器的主要输入分辨率之后,作者最终使用自适应视觉编码策略训练视觉模块,这种策略可以进一步适应任何比例的高分辨率输入。
(1)可训练模块。在第三阶段训练中,压缩层和视觉编码器都用于适应语言模型嵌入空间。LLM 保持冻结,以避免来自相对低质量预训练数据的干扰。
(2)数据。与之前仅使用图像描述数据的不同阶段不同,在高质量预训练阶段,作者还可以引入 OCR 数据来增强视觉编码器的 OCR 能力。
图像描述更新。网络中的图像文本对可能包含质量问题,如内容非流利,语法错误和安全词语重复等。这类低质量数据可能导致训练动态不稳定。为了解决这个问题,作者引入了一个辅助模型,用于低质量的图像文本对重写。重写模型以原始描述为输入,并将其转换为问答对。此过程中得到的答案被采纳为更新的描述。在实践中,作者使用 GPT-4 [14] 对少数种子样进行标注,然后将这些 seed 样用于 LLM 重写任务的微调。
数据打包。不同数据源的样本长度通常不同。样本长度的变异在批量中会导致内存使用效率低下,并增加内存溢出(OOM)错误的风险。为了处理这个问题,作者将多个样本打包为一个具有固定长度的序列。通过截断序列的最后样本,作者确保了序列长度的统一,有助于更一致的内存消耗和计算效率。同时,作者修改了序列 ID 和注意力 Mask ,以避免不同样本之间的干扰。在作者的实验中,数据打包策略可以带来 2 到 3 倍的加速预训练阶段。
多语言泛化。跨多个语言的多模态能力对于为更广泛的社区用户提供服务至关重要。传统解决方案需要大量多模态数据的收集和清洗,以及为目标语言进行训练。幸运的是,最近的 VisCPM [41] 研究发现在多语言多模态能力的传递可以通过强大的多语言LLM 双向器高效地实现。这种解决方案极大地减轻了低资源语言中依赖多模态数据的重担。在实践中,作者仅对英语和中文多模态数据进行预训练,然后进行轻量但高质量的面向目标语言的监督微调,以使其与目标语言对齐。尽管其简洁性,作者发现生成的 MiniCPMLama3-V 2.5 在超过 30 种语言中实现了与显著更大 MLLMs 相当的良好性能。
Supervised Fine-tuning
在学习预训练能力之后,作者在高质量的视觉问答数据集上进行有监督微调(SFT),以进一步从人类标注中学习知识和交互能力。
可训练模块。与预训练阶段主要使用来自网络的爬取数据相比,SFT阶段主要利用由人类标注者或强大的模型(例如GPT-4)标注的高质量数据集。因此,在SFT阶段,作者解除了所有模型参数,以更好地利用数据并学习丰富的知识。
2:SFT数据用于MiniCPM-V系列。第1和2部分的数据在SFT阶段依次合并。第1部分主要关注增强模型的基本识别能力,而第2部分旨在增强在生成详细响应和遵循人类指示时的先进能力。
数据。最近的研究表明,训练结束时产生的数据对塑造模型的能力和响应风格更重要。作者将SFT数据分为两部分。第1部分主要关注增强模型的基本识别能力,而第2部分针对在生成详细响应和遵循人类指示时的能力进行优化。具体而言,第1部分数据包括具有相对较短响应长度的传统问答/描述数据集,这有助于提高模型的基本识别能力。相比之下,第2部分涵盖具有复杂交互的文本或多媒体语境中的长篇响应的数据集。在SFT阶段,这两部分数据被合并并顺序输入模型。对于MiniCPM-Llama3-V 2.5,作者从最近的Cauldron数据集中集成200万的数据用于多模态知识增强,并使用90万来自36种语言的多语言数据来增强多语言对话能力。
Rlaif-V
MLLMs通常容易陷入幻觉问题,生成对输入图像没有实际事实依据的响应[111]。这个问题极大地限制了MLLM的广泛应用,尤其是在高风险场景下,例如自动驾驶和辅助视觉障碍者。为了解决幻觉问题,作者采用了最近提出的RLAIF-V[112]方法(图4),关键是获取可扩展的高质量反馈来自开源模型进行直接偏好优化(DPO)[82]。
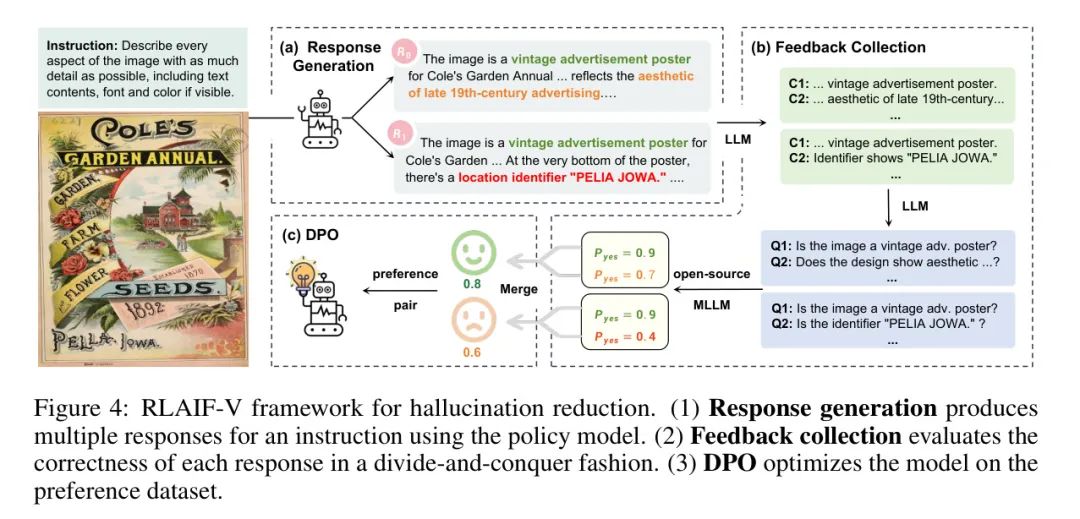
响应生成。RLAIF-V的第一步是使用策略模型为一个给定的指令生成多个响应。具体而言,对于一个等待对齐的模型M,作者使用采样解码(with high temperatures)从M中采样10个响应 。使用策略模型M进行响应生成的几个优点:(1)反馈收集和学习可以更好地关注可信度,因为可以避免来自多个MLLM的不同文本风格。(2)反馈学习更有效,因为直接收集策略模型上的偏好分布。
反馈收集。由于开源MLLMs通常比专有模型弱,因此从中收集高质量反馈具有挑战性。为了解决这个问题,RLAIF-V采用了一种分治法进行响应评分。具体而言,每个响应 都使用Llama-3 8B将其划分为原子论点 ,其中原子论点的正确性更容易评估。然后,作者将每个论点转换为 yes/no 问题,并使用开源MLLM对每个论点进行评分。在实践中,作者采用OmniLMM 12B对MiniCPM-V 2.0评分,并采用LLaVA-NeXT-Yi 34B对MiniCPM-Llama3-V 2.5评分。响应 的最终得分由给出,其中是不合法原子论点数量。
直接偏好优化(DPO)。收集高质量AI反馈后,作者通过DPO方法进行偏好学习。DPO算法需要训练偏好对,其中一个样本 更喜欢另一个样本 。为了组成偏好数据集,作者从每个响应集 中随机采样对,并根据它们的相对分数确定。最后,作者构建一个由3K个独特图像组成的6K个偏好对偏好学习数据集。
5 端侧部署
在本节中,作者研究了将 MiniCPM-V 部署在端侧设备上的情况。首先,作者介绍了部署所带来的挑战,然后提出了端侧部署的基本和高级实践。最后,作者分析了并讨论了不同设备上的评估结果。
Challenges
由于热扩散、尺寸限制和功耗等因素,端设备(如智能手机和电脑)通常面临资源限制挑战。作者将终端设备与高性能服务器进行对比,以识别出终端部署MLLM(端侧机器学习)的主要挑战:
内存限制:高性能服务器通常具有大量的内存容量,通常超过100GB甚至1TB。相比之下,移动设备上的可用内存通常在12GB到16GB之间,这对MLLM的部署可能不足以使用。
CPU/GPU速度限制:智能手机上的CPU整体处理速度明显较慢。例如,Snapdragon 8 Gen 3具有8个CPU核心,而高性能服务器如Intel Xeon Platinum 8580具有60个CPU核心。同样,移动设备上的GPU并不如服务器上的GPU强大。例如,Qualcomm Adreno 750只有6 TFLOPS,而NVIDIA 4090可以达到83 TFLOPS。
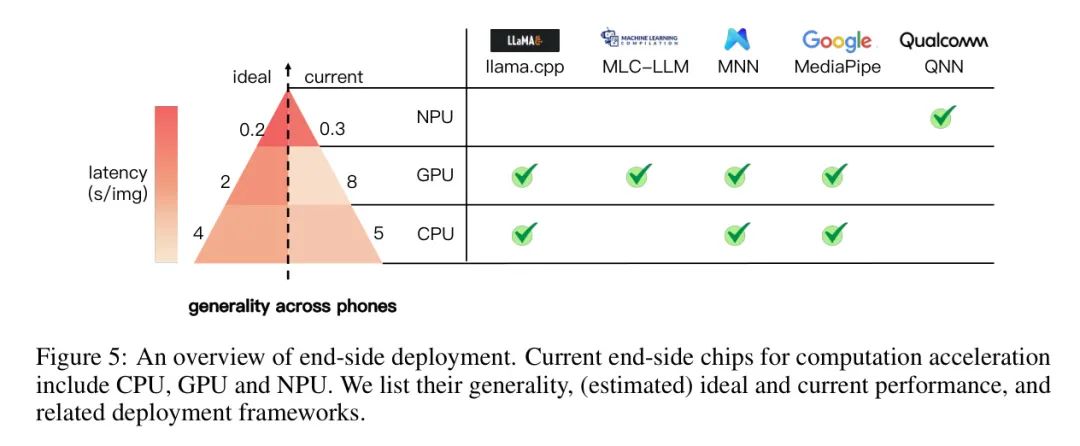
为了在端设备上部署MLLM,作者首先对模型进行量化以降低内存成本,并在不同的框架上将部署结果进行实证调查。量化。量化是一种广泛使用的技术,可以降低内存消耗。量化模型的主要思路是用统一的缩放因子将多个权重压缩到一个较窄的范围内,然后进行离散化。
⑤GPU使用情况及其对部署算法的影响。由于GPU使用情况的普遍性,作者优先采用GPU进行部署。然后,作者将量化和GPU部署结合在小米14 Pro(骁龙8 Gen 3)上,该设备可以达到64.2秒的文本编码延迟和1.3个标记/秒的文本解码速度(如图6所示)。然而,对于用户来说,这些速度仍然不可接受。
Advanced Practice
为了提高用户体验,作者研究了一系列先进技术,包括内存使用优化、编译优化、配置优化和GPU加速。
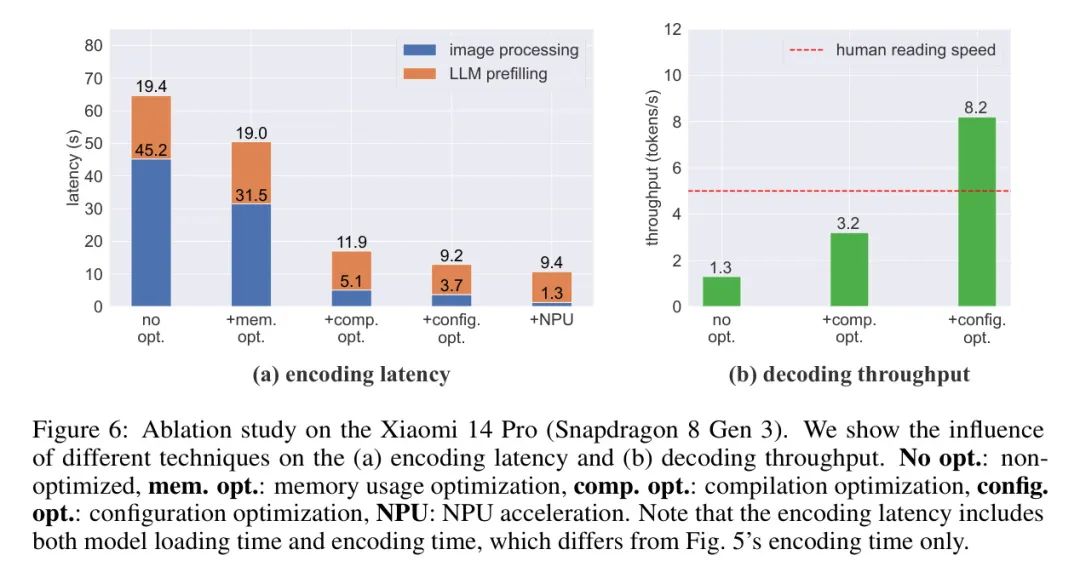
内存使用优化。实验结果显示,如果没有特定的优化,移动设备上的推理速度可能会因为有限的内存资源而成为瓶颈。为了解决这个问题,作者探索了内存使用优化的策略。作者没有同时将ViT和LLM加载到内存中,而是采用了分步加载的方法。具体来说,作者首先加载ViT进行视觉编码,然后加载LLM进行视觉和文本标记编码。通过释放LLM占用的大量内存,作者可以在ViT编码过程中避免频繁的换页(进出),从而提高程序效率。如图6(a)所示,这种优化技术使图像处理时间从45.2秒减少到31.5秒。
编译优化。作者发现,直接在目标设备上编译模型可以显著提高编码延迟和解码吞吐量。这可以归因于编译和目标设备指令集架构之间的更好一致性。如图6所示,这项优化工作取得了令人满意的结果。编码延迟从50.5秒减少到17.0秒,解码吞吐量从1.3个标记/秒提高到3.2个标记/秒。
图6:在小米14 Pro(骁龙8 Gen 3)上的超割离 study。作者展示了不同技术对(a)编码延迟和(b)解码吞吐量的影响。无优:未优化,mem.优:内存使用优化,comp.优:编译优化,config.优:配置优化,NPU:GPU加速。请注意,编码延迟包括模型加载时间和编码时间,这与图5中的编码时间有所不同。
配置优化。作者观察到,llama.cpp框架的单个默认配置可能不适合不同类型的端设备。为了最大限度地提高推理速度,作者设计了一个自动参数搜索算法,该算法动态确定最合适的配置(例如,将计算任务分配到不同的CPU核心)。通过配置优化,作者可以实现良好的改进。具体来说,解码吞吐量从3.2个标记/秒增加到令人印象深刻的8.2个标记/秒,超过了人类阅读速度。GPU加速。上述技术主要针对CPU部署。另一个有前途的途径是利用其他芯片类型,如GPU和NPU。尽管GPU有潜力,但作者发现在作者的实验中,当前用于移动设备GPU的框架并未优化或兼容到能够在CPU上实现更好的结果。因此,作者考虑使用新的专用硬件,也就是近几年来引入的新一代、专门用于加速AI应用的神经处理单元(NPU)。一些智能手机已经配备了NPU,这些NPU被认为是更适合解决计算瓶颈的。
在实践中,作者主要利用NPU加速视觉编码。具体来说,作者将ViT的后端框架更改为QNN,同时保留llama.cpp的后端组件用于LLM部分。对于配备了高通NPU的手机,这项优化将视觉编码时间从3.7秒减少到1.3秒,如图6(a)所示。
Results.
分析.为全面评估MiniCPM-Llama3-V 2.5在各种端侧设备上的性能,作者在图7中提供了在小米14 Pro(Snapdragon 8 Gen 3),vivo X00 Pro(MediaTek Dimensity 9300)和Macbook Pro(M1)上的测试结果。得益于部署优化技术,MiniCPM-Llama3-V 2.5可以在移动设备和个人电脑上高效运行,实现可接受的延迟和吞吐量。例如,利用小米14 Pro的NPU,使其达到与Mac M1相似的编码速度。此外,几乎所有设备的吞吐量与人类阅读速度相当或更高。
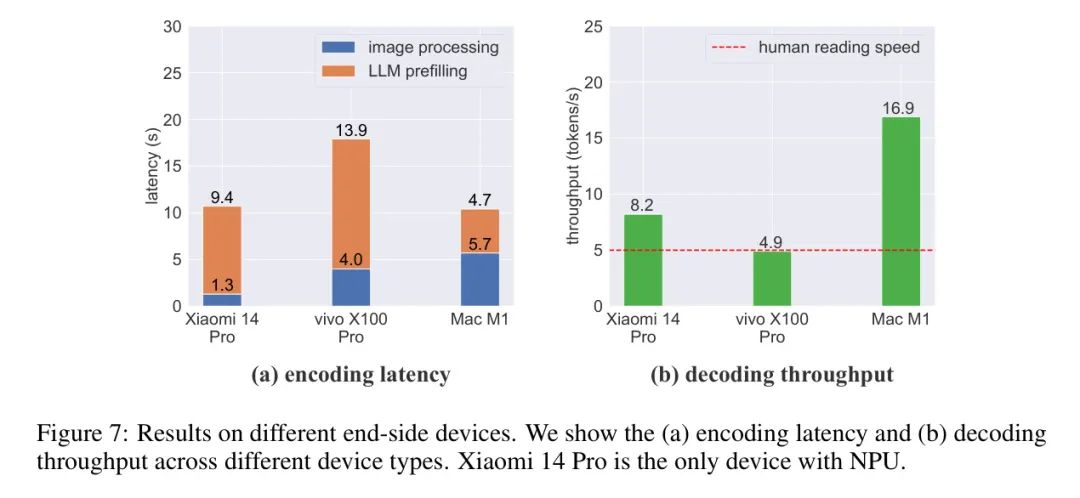
讨论.通过分析图7,可以明显看出当前的计算瓶颈主要源于LLM预填充,这主要涉及为LLM进行图像和文本标记。值得探索的研究方向包括开发更高效且使用较少视觉标记的视觉编码方法,并更好地利用GPU/NPU加速LLM编码。随着对端侧MLLM的重视以及对GPU/NPU加速技术的快速发展,作者相信与端侧MLLM的实时交互即将实现。
6 Experiments
在本节中,作者对MiniCPM-V系列进行了深入评估。
MiniCPM-V Series
作者在MiniCPM-V系列中发布了3个模型,包括MiniCPM-V 1.0、MiniCPM-V 2.0和MiniCPM-Llama3-V 2.5。如表3所示,MiniCPM-V 1.0在对预训练阶段1&2和SFT进行训练时,没有使用自适应视觉编码和RLAIF-V。对于MiniCPM-V 2.0,作者包括了所有的训练阶段以及自适应视觉编码策略,以进一步提高性能。在MiniCPM-Llama3-V 2.5中,作者采用了Llama3-Instruct 8B作为基础LLM。
实验设置

基准测试。作者对覆盖视觉问答、多模态对话、知识推理、OCR和虚构内容的主要基准进行全面的评估。(1)通用基准测试。作者采用OpenCompass [26]作为通用评估指标,它是一个集合了11种流行的多模态基准测试的综合数据,包括MME [33], MMBench [63], MMMU [113], MathVista [71], LLaVA Bench [62],等等。作者还报告了在RealWorldQA上的结果,以评估模型的实际空间理解能力。(2)OCR基准测试。作者采用三个常用的OCR能力评估基准,包括OCRBench [64], TextVQA [91]和DocVQA [74]。(3)虚构内容基准测试。作者还包括了Object HalBench [85; 111]来评估模型的可信赖度。
基准。作者与不同系列中的强大基准进行了比较:对于作者开源的模型,作者与包括Yi-VL-6B/34B [108], Qwen-VL-Chat [7], DeepSeek-VL-7B [68], TextMonkey [65], CogVLM-Chat-17B [102], CogVLM2-Llama3-19B [102], Idefics2-8B [52], Bunny-Llama-3-8B [39], XTuner-Llama
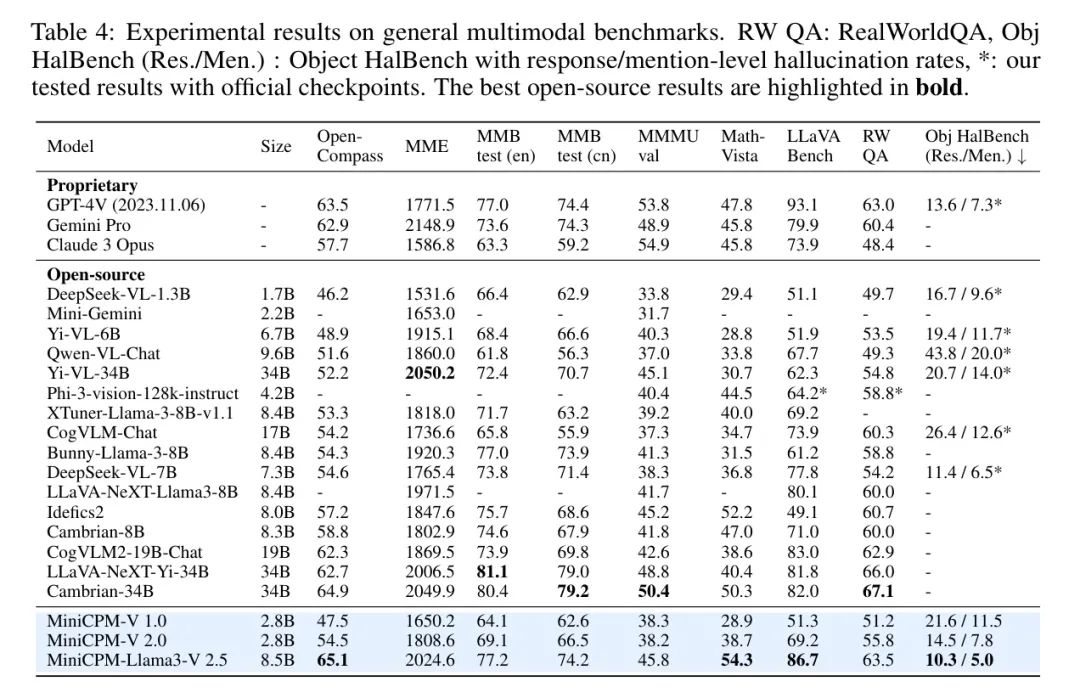
与强大的专有模型相比,如GPT-4V-1106和Gemini Pro,MiniCPM-Llama3-V 2.5在OpenCompass基准测试上取得了更好的性能,而且参数数量显著减少。此外,MiniCPM-Llama3-V 2.5在Object HalBench上的幻觉率也低于GPT-4V-1106,表明其在实际应用中的可靠性。
具有2亿参数的较小MiniCPM-V在与其他2亿至3亿参数的模型相比,实现了显著更好的性能,甚至可以与基于Llama3的8亿参数的MLLM(如Bunny-Llama-3-8B)相媲美。
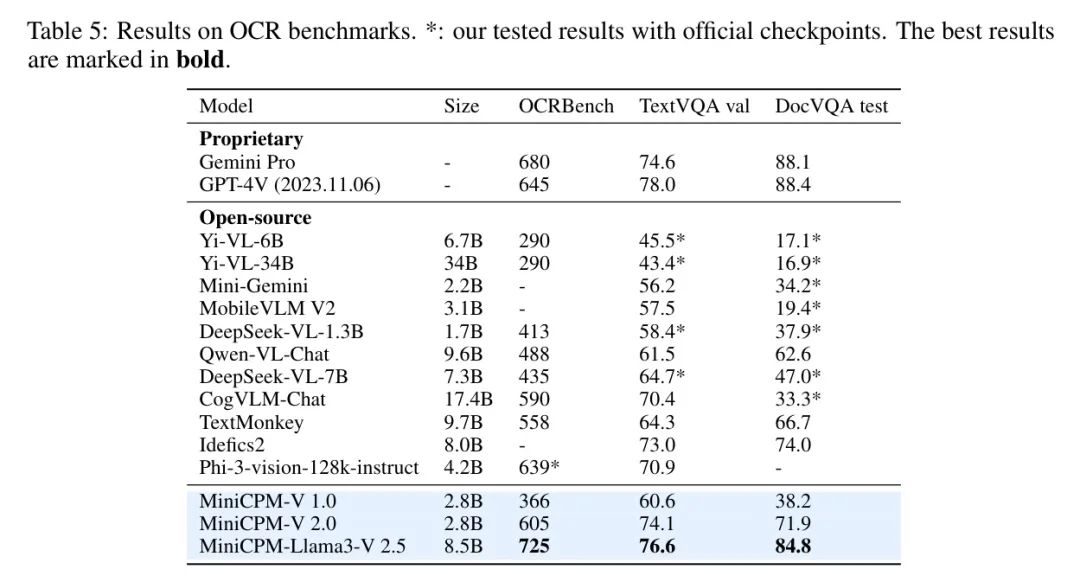
在OCR基准测试上,MiniCPM-V模型也展示了强大的OCR能力,包括场景文本、文档和截图理解。如表5所示,MiniCPM-Llama3-V 2.5在OCRBench、TextVQA和DocVQA上超过了开源的MLLM,如1.7亿至34亿参数的模型,甚至与专有模型如GPT-4V-1106和Gemini Pro相媲美。
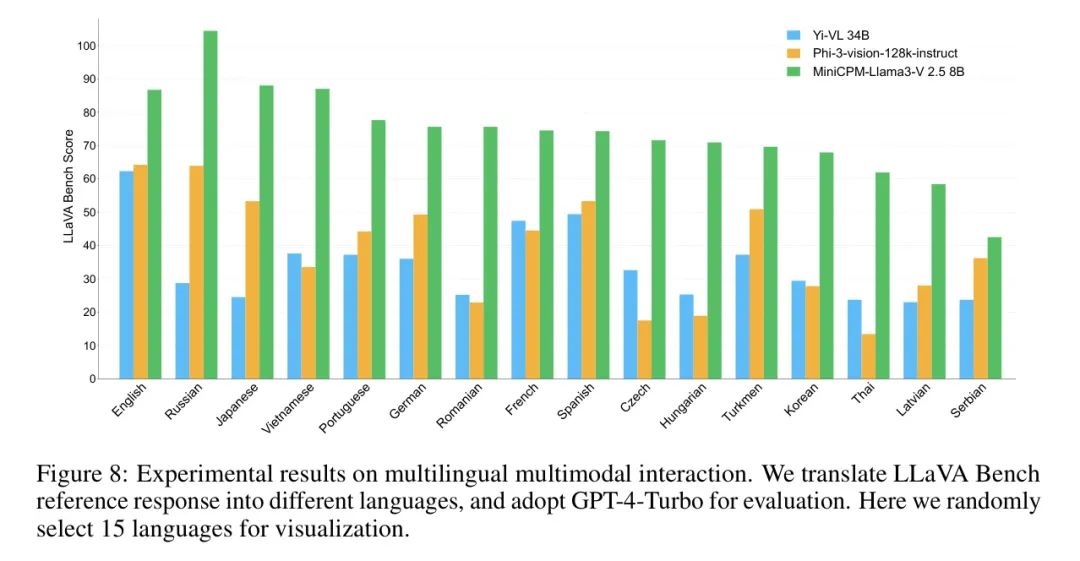
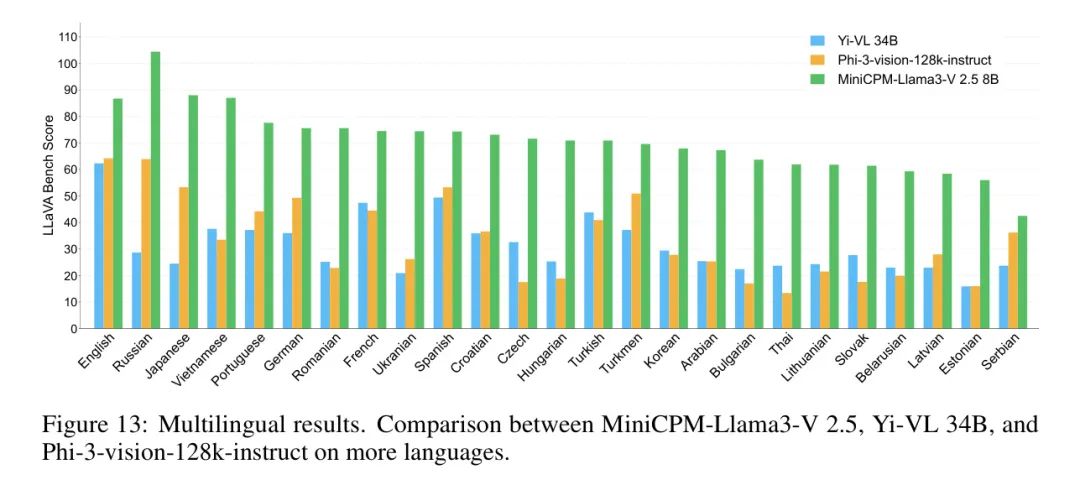
多语言多模态能力。基于自监督视觉定位框架VisCPM的跨语言跨模态泛化方法,MiniCP-Llama3-V 2.5将多模态能力扩展到30多种语言。如图8所示,MiniCPM- Llama3-V 2.5可以超过Yi-VL 34B和Phi-3-vision 128k-instruct在多语言的LaVA Bench上的表现。因此,MiniCPM-Llama3-V 2.5在为拥有多种语言的更大群体提供服务方面具有巨大潜力。
与其他基于LLaMA3的模型进行比较。从表4的实验结果中,作者可以观察到:
(1)MiniCPM-Llama3-V 2.5在所有基准测试上,相较于强大的LLaVA-NeXT-Llama-3-8B,实现了更好的结果。例如,与LLaVA-NeXT-Llama-3-8B相比,MiniCPM-Llama3-V 2.5的视觉标记数量范围也更小。
(2)此外,MiniCPM-Llama3-V 2.5的推理计算需求显著减少。例如,MiniCPM-Llama3-V 2.5的视觉标记数量范围为(96,960),而LLaVA-NeXT-Llama-3-8B为(1728,2880)。这在推理速度、第一标记延迟、内存使用和功耗方面特别重要, especially 对于实际应用中的端到端应用。
Ablation Study
作者在MiniCPM-Llama3-V 2.5的组成部分上进行了消融研究,包括RLAIF-V和多语言训练。
RLAIF-V的影响。从表6的结果来看,RLAIF-V有效降低了基础模型在响应 Level 和提及 Level 的幻觉率,使模型在行为上更有可信度。重要的是,幻觉减少并没有牺牲基础模型的通用能力。相反,RLAIF-V通过使用小于0.5%的多语言SFT数据,在平均11个基准测试上提高了OpenCompass的整体性能0.6点。

多语言泛化。作者研究了多语言泛化技术的需求和有效性。如表8所示,在小于0.5%的多语言SFT数据下,作者在所有语言上都看到了超过25点的改进。结果表明,多语言泛化方法在没有良好数据和计算效率的情况下,可以有效提高多语言能力。此外,作者注意到,不同语言上的性能提升不均衡。作者假设,性能提升的程度可能与给定语言的基础 LLM 的能力有关,作者计划在未来的工作中进行更系统的探索。
Case Study
在案例研究中,作者提供了更直观地理解MiniCPM-Llama3-V 2.5能力的说明。
OCR能力。MiniCPM-Llama3-V 2.5在实际场景中展现了强大的OCR能力。如图2所示,模型在屏幕截图中生成的英语文章中准确地转录为纯文本,将既包含英语又包含中文的表格转换为Markdown格式,理解代码逻辑,并根据图像内容提供合理的计划。

高分辨率输入的任意比率。MiniCPM-Llama3-V 2.5处理具有极端比例的高分辨率输入的能力是其显著的特征。如图9所示,模型可准确地处理具有10:1的方面比率的输入,并且准确识别文章的详细内容。有趣的是,模型也可以解释图像中的图像,正确地描述中央图像为一个“微笑并持有一个巧克力慕司”的男人。

多语言多模态能力。得益于从VisCPM [41]中采用的多语言多模态泛化方法,MiniCPM-Llama3-V 2.5在超过30种语言之间展现出多语言熟练程度,泛化能力覆盖了多种语言和模态。图11展示了德语、法语、日语、韩语和西班牙语的多模态对话,展示了对特定语言文化知识的良好理解。

图10:MiniCPM-Llama3-V 2.5和GPT-4V在hallucinations(幻觉)上的对比。

值得信任的行为。基于RLAIF-V,MiniCPM-Llama3-V 2.5确保了更值得信赖的响应,降低了hallucination(幻觉)的速率。如图10所示,模型与其功能强大的GPT-4V相比,其响应更具可行性,显示出在实际场景中的可靠性和可信度。
结论
贡献。在这项工作中,作者引入了MiniCPM-V系列模型作为对强大端侧MLLMs的主要探索。由于采用了如自适应视觉编码、多语言泛化和RLAIF-V方法等技术,MiniCPM-Llama3-V 2.5可以在远少于GPT-4V参数的情况下实现与GPT-4V水平相当的表现。通过各种端侧优化技术,该模型保证了移动设备上的可接受的用户体验。
局限性。尽管表现出色,但现有的MiniCPM-V模型仍存在几个局限性。(1) 能力深度。增强多模态理解能力和推理效率还有很大的改进空间。(2) 能力宽度。除了图像模式外,将MLLM能力扩展到其他模态(如视频和音频等)也是很有前途的,GPT-4o [78]和Google Astra [29]已经给出了很好的例子。
除了MLLM能力外,端侧部署也面临着独特的挑战。推理速率和延迟仍远非足够好,模型服务的电池容量也可能受到限制。此外,之前的芯片和部署框架的努力主要针对CNNs和LSTMs,而对于MLLMs可能不是最优的。专门针对MLLM的定制工作有很大的改进空间。
未来工作。考虑到当前的局限性和端侧MLLMs promising的未来,作者预计学术界和产业界将增加改进模型在某一方面(深度和宽度)和端侧设备的能力。作者相信,模型能力和端侧设备能力的同步提升,将促使不久后的端侧应用为用户提供令人满意的体验。
图12:MiniCPM-V 2.0的定性结果。(1)案例1为街头的场景文本理解举例。(2)案例2为具有极端比例的图像理解的示例。(3) 案例3比较了MiniCPM-V 2.0和GPT-4V在详细描述上的表现。幻觉输出用红色标出。

参考
[1].MiniCPM-V: A GPT-4V Level MLLM on Your Phone.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-08-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号