清华 & 北大提出 EgoPLan ,以自我为中心的视觉语言规划 !

清华 & 北大提出 EgoPLan ,以自我为中心的视觉语言规划 !

AIGC 先锋科技
发布于 2024-08-27 20:10:15
发布于 2024-08-27 20:10:15

本文探讨如何利用大型多模态模型(LMMs)和文本到图像模型构建一个更通用的身体代理。LMMs在规划涉及符号抽象的长期目标方面表现出色,但往往在物理世界的实现上存在困难,无法准确识别图像中的目标位置。需要建立一座桥梁将LMMs与物理世界相连接。 本文提出了一种新颖的方法,即以自我为中心的视觉语言规划(EgoPlan),从不同的家庭场景以自我为中心地处理长期目标任务。该模型利用扩散模型模拟状态和动作之间的基本动力学,并结合样式转移和光流等技术来增强在不同环境动力学之间的泛化。 LMM作为规划器,将指令分解为子目标,并根据它们与这些子目标的匹配情况选择行动,从而实现更通用和有效的决策。 实验表明,与家庭场景中的 Baseline 相比,EgoPlan从以自我为中心的观点改善了长期任务成功率。
1 Introduction
大型语言模型(LLMs)和大型的多模态模型(LMMs)的出现,彻底改变了人工智能领域的格局。它们强大的推理能力和强大的泛化能力使得它们可以直接应用在各种场景中。在实现人工通用智能(AGI)的路上,研究行人正考虑让大型模型(LMs),特别是LMMs,突破文本和图像所表达的世界,与物理世界互动。他们的目标是构建一个能够智能地与物理世界互动的通用可嵌入代理。
LMMs在物理世界中的符号抽象长程规划任务上表现出令人惊讶的能力[42]。然而,仍有一部分问题尚未解决。它们在将文本世界与物理世界联系起来时遇到了困难。例如,GPT-4V在图像中往往不能准确地识别物体的位置。LMMs似乎知道“接下来要做什么”,但他们不了解“世界是如何运作的”。因此,需要一个世界模型(动力学模型)来连接LMMs和物理世界。有两大可能解决方案。一是将环境动力学隐式地集成到LMMs中,即根据海量的状态-动作序列对LMMs进行微调,如PaLM-E[7]和RT-2[11]。然而,直接训练大型模型需要大量的数据和计算资源。另一种是明确引入一个预先训练的世界模型,例如文本到图像模型[32; 34],供LMMs作为辅助工具使用。作者的工作探索了第二条道路。作者试图回答这样一个问题:“如何利用LMMs和文本到图像模型构建更通用的嵌入式代理?”
已经有一些工作将文本到图像(或视频)模型作为决策的世界模型进行训练。然而,它们仍存在一些局限性。首先,它们的任务场景通常涉及物体操作,这是一个完全可观察的环境。这在实际场景中并不常见,他们的方法似乎很难适应其他实际场景。例如,SuSIE[2]和VLP[9]需要生成几步后的图像,但对于大多数部分 observed 场景(例如自动驾驶),由长期预测引入的错误相当大。相比之下,作者关注更具挑战性的部分可观察场景。嵌入式代理,例如人类,通常需要从以自我为中心的角度完成更复杂的任务,例如家庭任务。
其次,它们的方法具有有限的可扩展性,主要体现在两个方面:
(i)低级策略针对特定任务设计,不同的动力学可能导致策略失败;
(ii)相同的文本描述的动作的动力学可能因场景(例如左转)的不同而变化。这是因为不同环境下的个人(例如模拟器或物理世界)表现出差异。
文本到图像(或文本到视频)模型缺乏个体运动模式信息,并且无法准确地泛化到训练数据集中不包括的其他环境动力学。作者希望代理能够扩展到相同类型的场景中的不同动力学,例如家庭场景。
在这项工作中,作者提出了一种以自我为中心的视觉语言规划(EgoPlan),一种具有通用性和实体性的代理,可从自我中心视角在不同家庭环境中完成长时间视野任务。在以自我为中心的视角下,预测较少的观察值是不可靠的。因此,采用文本到图像模型(扩散模型),即在部分可观察条件下实现基本动力学模型。在此模型中,观察和行动分别用图像和文本表示。此外,两种不同环境的主要差异来自两个方面:环境风格的差异以及相同类型动作的幅度(速度)的不同。为了准确地将文本到图像模型泛化到其他环境,可以基于LoRA [26]进行风格迁移,并引入光学流引导运动模式。
在决策时,需要一种通用的策略,因此作者选择LMM(线性多臂赌博机)作为规划器。具体而言,当收到指令时,LMM首先将其分解为许多子目标。对于子目标的表示,作者研究了基于文本和图像的方法,并分析了每种形式。根据动力学模型根据每个动作的结果,LMM可以判断哪个结果更接近当前子目标,从而选择合适的行为。直观地,如果规划和动力学模型具有一定程度的泛化能力,代理也会继承这种能力。
作者对具有实体性的代理的每个模块进行了全面评估和分析。实验表明,世界模型生成的图像质量高,光学流预测精度高。随后,作者验证了世界模型在更复杂任务中的决策辅助有效性。最后,作者确认了该方法在不同环境下的泛化能力。作者的主要贡献如下:
作者收集了关于Virtualhome的数据集,该数据集将智能体的动作视为轨迹,并提供以自我为中心的观察,在轨迹的每个时间步显示光学流、深度图和语义分割图,这将为实体环境中的导航和操作任务提供数据支持。
作者提出EgoPlan,这是一个将LMM与预测下一个动作执行后场景的以自我为中心的世界模型相结合的复杂任务规划框架。为了能够规划更复杂任务(复合任务包括导航和生产任务)与更多多样且不同的视角(从视角看,复合任务包括导航和生产任务),作者将世界模型的预测步长限制在一个较小的值,以避免预测算法出现复杂性爆炸,并引入光学流信息到世界模型中,以使世界模型对动作位置变化的敏感性更高,在导航过程中适应场景变化。作者在全面的任务上通过使用LMMworld模型规划进行演示。
考虑不同环境和不同动作的以自我为中心的观察,包括智能体运动自身以及环境精细背景信息。光学流信息表示运动信息本身,对不同场景和风格具有计算不变性,而环境精细背景信息可以从环境代理的角度通过从少量样本图像中进行微调进行细调。作者借用了计算机视觉中的风格迁移思想,并采用Lora模型微调作者的扩散世界模型,以实现作者的框架在不同实体环境下的少量样本泛化能力。在habitat上的实验表明,作者的框架仍可以协助不同环境下的多模态大型模型进行任务规划。
2 Related Work
Diffusion Model
扩散模型在图像生成的领域以及图像编辑的领域中得到了广泛研究。扩散模型可以在图像生成过程中实现高度的控制。具体而言,InstructPix2Pix (InstructP2P)[3] 训练一个条件扩散模型,该模型可以根据输入图像以及有关如何编辑的文本指令,生成编辑后的图像。
ControlNet [49] 广泛应用于通过使用各种先验信息来控制生成图像的风格,如边缘信息和对齐。通过在网络中添加 LoRA 或 Adapter [25]模块,经过训练在一种数据分布上的模型可以通过几个图像示例,转移到其他数据分布(不同的视觉风格)上。
由当前扩散模型生成的图像具有非常高的质量,高度的实感和易控制性。这促使各种领域考虑使用这些生成的图像来辅助完成其他任务。本文采用扩散模型生成任务子目标并预测下一个状态的图像用于决策。
World Model for Decision-making
世界模型用于模拟环境动力学,对构建自主代理和实现各种场景中的智能交互至关重要。然而,开发一个精确的世界模型仍然是一个重大的挑战,尤其是在基于模型的决策中。
Dreamer系列[17; 18; 19]模型通过将环境动力学映射到潜在空间来预测游戏环境中的未来状态。它使得游戏代理可以通过想象来学习任务,从而减少了有效的学习交互。然而,由于世界模型是在潜在空间而非像素空间中学习的,因此这些模型往往缺乏对未见任务和环境的泛化能力。在像素空间构建的世界模型可能具有更好的泛化能力。通过精心编排不同轴的丰富数据,UniSim[45]可以以视觉形式模拟人类、机器人和其他交互式代理的动作响应,从而呈现出真实的视觉体验。总之,作者可以发现世界模型的应用领域不仅限于游戏和机器人技术。
基于扩散的世界模型的进步正在改变作者如何在现实世界的环境中模拟物理运动定律,特别是在机器人领域。UniPi[8]将机器人决策问题框架为文本到视频任务。生成的视频被 feed 到反动力学模型(IDM)中,从中提取底层低级控制动作,并通过模拟或真实机器人代理执行这些动作。视频语言规划(VLP)[9]引入了一种新颖的方法,将视频生成与搜索算法集成,以实现任务规划。这种方法使得机器人可以通过可视化未来的动作和结果来规划更长的时间范围。与先前的作品不同,SuSIE[2]利用预训练图像编辑模型来预测可能的未来帧。在此类假设的未来帧上的低级目标达到策略是在机器人数据上进行训练的。因为一个目标帧预测不需要模型精确理解机器人的低级动力学,因此它应该有助于从其他数据源(例如,人类视频)的迁移。RoboDreamer[50]通过利用视频扩散来构建结合动作和目标的组合计划,从而在尚未探索的机器人环境中解决新颖的任务。
作者发现将文本到视频模型应用于部分观察场景是不现实的。此外,预测几步后的目标帧仍然具有挑战性,因为视角的改变可能很大。因此,作者采用文本到图像模型准确预测一步规划的短期成果。
3 VH-1.5M Dataset
大多数与具身代理相关的数据集,例如RT-X [12] 和RH20T [14],采用第三人称视角以避免视觉遮挡问题,因此缺少以主观视角(第一人称视角)获取的数据。确实有些数据集采用第一人称视角,然而,它们通过假设动作瞬间完成来简化状态转换,这并未模仿现实世界环境中的动力学变化。作者基于虚拟家居(VirtualHome)环境 [30; 31] 提出了VH-1.5M数据集,以解决这些问题。
作者将在虚拟家居环境中构建数据集VH-1.5M,该环境包括50个独特的房屋。每个房屋中包含大约300个可交互物体,具身代理可以执行超过10种动作。请注意,虚拟家居环境是一个专为具身代理设计的模拟器,可以详细模拟居住场景。它支持一系列家庭任务,如导航和目标操作。
VH-1.5M数据集以结构化的方式组织,囊括动作、房屋、具身代理和轨迹之间的关系。每个任务序列条目遵循分层结构,例如"/open/house_0/Female4/2_fridge"(女性4在house0打开冰箱2)。
数据集详情: VH-1.5M数据集包括:
- 13种动作:具身代理在房屋内的各种物理动作和交互。
- 50座房屋:独特设计的房屋,拥有多样布局和物体放置。
- 4个具身代理:四个具有不同能力的具身代理,都具备执行全部动作的能力。
- 1.5M样本:数据集包含许多详细序列,每个执行一个动作。序列中的每个步骤的信息存储为一个样本。图1中的示例就是其中一个。作者使用house49作为验证集。
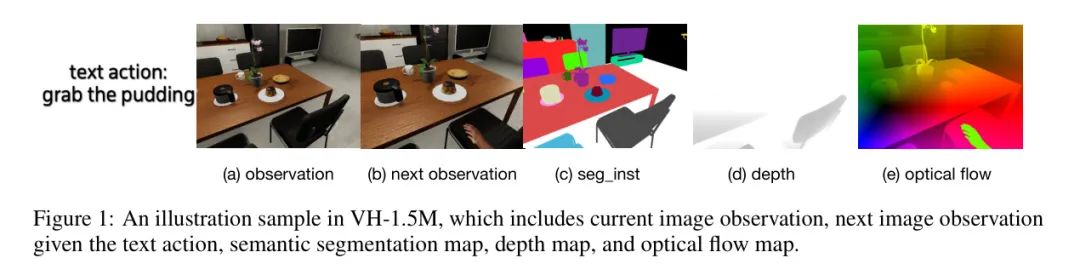
数据集的更多详情可在附录中找到,作者会开源该数据集。
4 Method
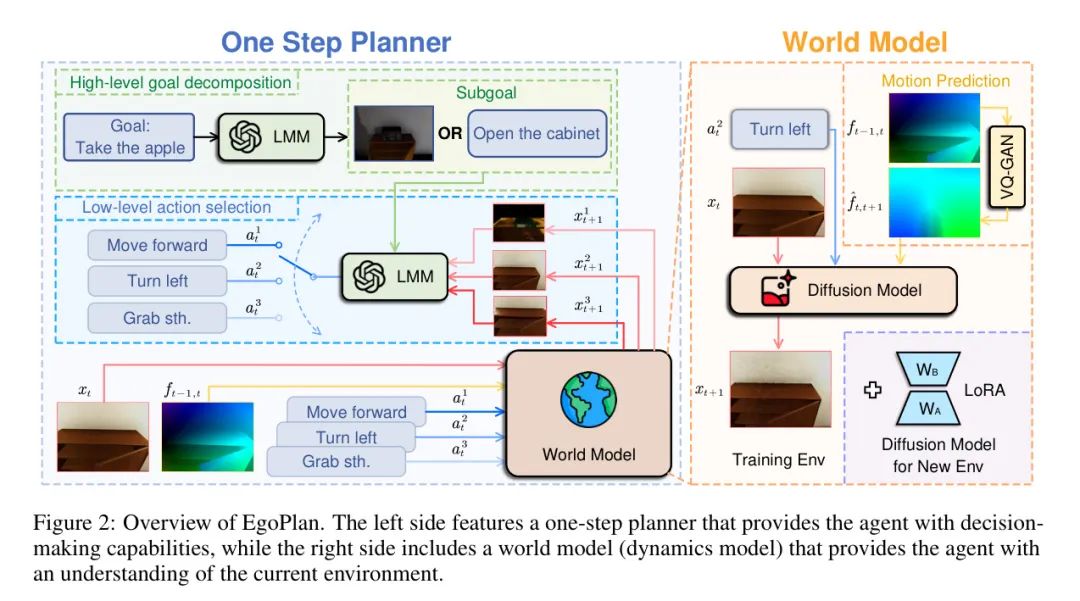
作者的具有身体感知的智能代理EgoPlan,在当前时间步长t处输入一个场景的视觉观测和自然语言目标,并输出用于与环境互动的动作。请注意,只能部分表示当前环境的 states。此外,智能代理使用封装的技能(如向前移动、转向和抓取物体)作为动作。
EgoPlan 由两个部分组成,如图2所示。一个是动态模型,它为智能代理提供当前环境的概念;另一个是规划器,赋予智能代理决策能力。从直观上讲,作者人类首先在脑海中想象每个行动的结果,然后,通过比较结果,作者做出最佳决策。
Diffusion-Based Dynamics Model
4.1.1 Learning Dynamics

4.1.2 Generalization
作者希望从不同的角度提高模型的泛化能力。换句话说,作者不仅通过大数据和大型模型来增强泛化,而且要明确在方法层面上解决上述环境中存在的差异。
运动正则化。首先,作者必须将运动信息集成到扩散模型中,以区分不同的运动模式。光流因此引起了作者的关注。光流是指在连续的两帧图像之间,由物体或摄像机运动所造成的目标图像的明显运动模式。在光流图中,颜色表示运动的方向,颜色深度或强度表示运动幅度,这是不同环境中的一般特征。
然而,实际上在没有下一观测的情况下,作者不能获得当前的光流 。受到其他运动估计工作 [4, 47] 的启发,作者假设在短期内(即突然变化不会发生)运动一致性成立。因此,连续的光流图高度相关,允许作者使用前一图来预测当前的光流图。前一图是根据前一帧计算得到的,反映了当前环境中的实际运动模式。

Planning with Dynamics Model
为了避免在新型环境中进行额外的训练,作者使用 LMM( Large Mind Model,即 GPT-4V)作为规划器。LMM 需要同时负责高层次的目标分解和低层次的动作选择。同时,预训练的动力学模型可以帮助 LMM 更好地理解世界。
4.2.1 Goal Decomposition
对于长期复杂的任务,分解目标是必不可少的步骤。子目标可以以文本和图像形式表示。对于基于文本的子目标 ,作者提示 LMM 生成一个合理的子目标。此外,作者训练另一个扩散模型 ,仅基于文本子目标和当前观察生成图像子目标 。请注意,预测子目标的图像可能比预测下一个观测更具挑战性,这意味着结果精度不是很高。作者计划研究不同类型的子目标对任务的影响。见第 5.2 节。
4.2.2 One-Step Planner
由于作者只能确保对于下一个状态的预测相对准确,所以作者采用了一步规划方法。具体来说,作者利用预训练的动力学模型来预测下一个状态中所有动作的视觉结果。一旦获取了基于文本/图像的目标子任务,作者将子任务和所有视觉结果发送到LMM。然后,作者促使LMM与所有潜在结果相比,确定哪个动作可以使代理更接近目标。
5 Experiment
在本节中,作者对嵌入式代理的每个模块进行全面评估和分析。首先,作者使用世界模型评估图像生成的质量,并使用光学流预测评估质量。其次,作者评估作者的世界模型是否能帮助任务规划完成更复杂的任务。最后,作者评估作者的方法的一般化能力。
Visual Quality
作者采用两个指标,FID [21]和用户评分,来评价生成的世界模型的图像质量。对于模型,InstructP2P (预训练) 是InstructP2P的默认模型。
InstructP2P (微调)是作者基于自身数据集进行微调的模型。Ours (前馈)是作者基于前向运动图的世界模型,而Ours是基于预测的运动图的世界模型。请注意,VH-1.5M的验证集约有5000个样本。
FID得分。 FID是一个标准指标,通过使用认知模型来测量两个图像分布之间的距离。FID越小,两个图像越相似。表1显示了作者的模型和 Baseline 的FID分数。作者可以看到,使用现有的扩散模型作为世界模型是无效的,因为它们的训练数据通常缺少与状态转换相关数据。同时,引入光学流图,它作为运动模式信息,显著增强了生成结果。此外,基于上一帧预测的光学流的世界模型。
用户研究。 作者还对世界模型在图像生成方面的准确性进行了用户研究。对于标准,用户判断执行的动作的方向和幅度是否正确。每个用户需调查1000个样本,总共8名用户参与了这项调查。如表2所示,作者的用户研究再次证实了作者预测的光学流可以帮助生成更高质量的图像。

分析。 如图3所示,InstructP2P (精调)生成了错误方向的场景。然而,通过结合光学流信息,这一缺陷可以大大改善。此外,如果考虑运动模式预测,还可以更准确地预测关闭电冰箱的动态。

VirtualHome Tasks
结果。为了证明作者的世界模型能很好地帮助LMM进行任务规划,作者在VirtualHome环境中对12个不同的任务进行评估,每个任务都是一个说明,这些任务组合了多个连续的子任务。对于 Baseline ,作者使用GPT4与React [46]作为任务规划和策略,表示为GPT4+React,并作为输入以JSON格式文本环境描述。作者还直接使用GPT-4V进行决策,表示为GPT4V,并将GPT4V与React [46]和Reflexion [36]结合作为任务规划和策略,分别表示为GPT4V+React和GPT4V+Reflexion。对于消融 Baseline ,作者使用微调后的InstructP2P作为世界模型,表示为GPT4V+P2P。以过去的光流图作为条件的世界模型,表示为GPT4V+PrevOF。
如图4所示,世界模型显著提高了GPT-4V在各种长期对齐任务上的能力。此外,将光流信息纳入图像生成,进一步提高任务规划性能。结果也证明了预测光流图的有效性。
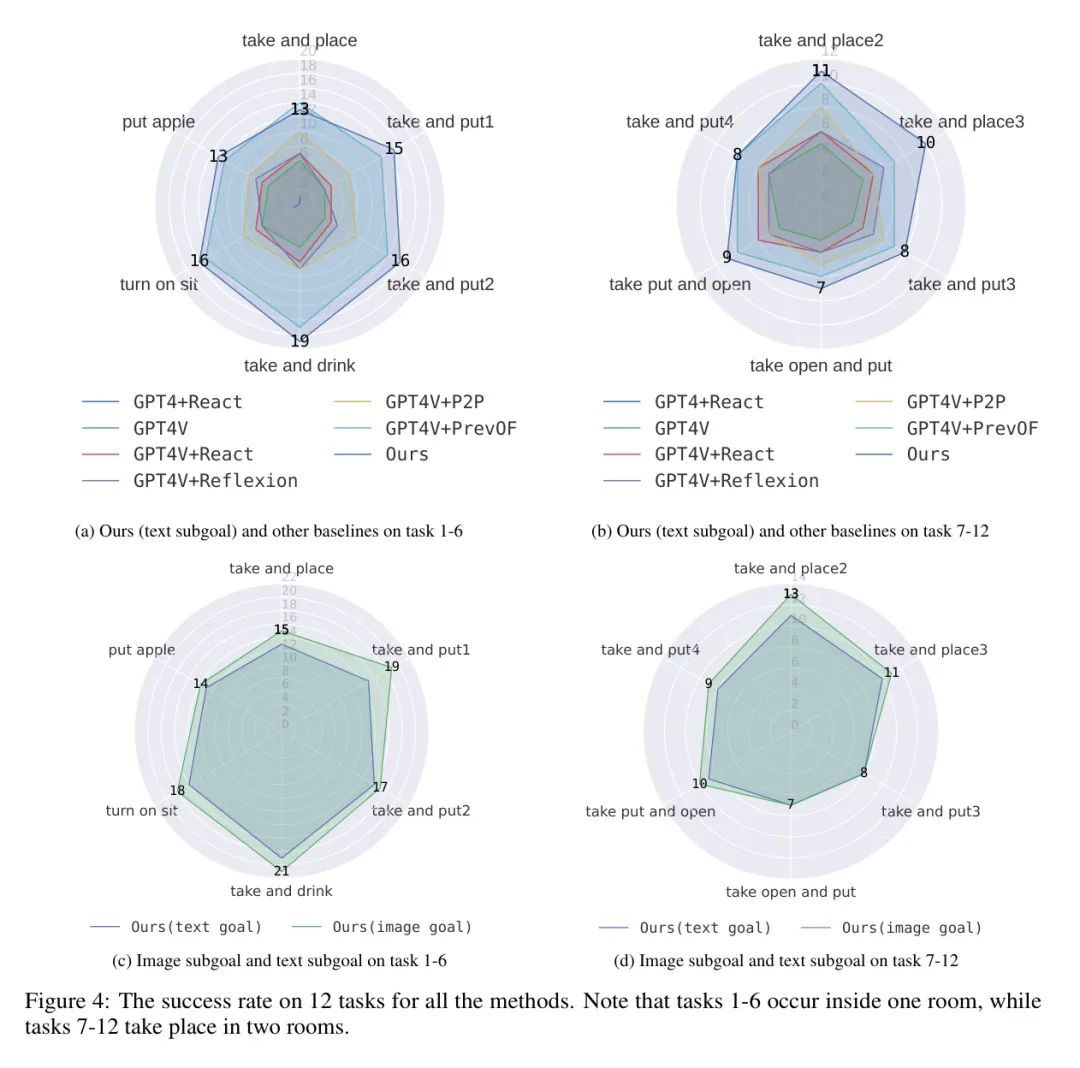
图像子目标_vs._文本子目标。在这一部分,作者分析不同类型的子目标对任务的影响。在子目标分解过程中,由LLM任务规划器直接输出的文本子目标代表了一个高层次、粗糙的描述。如果作者作者的方法在子目标完成时间的场景,可以得到一个更详细、更精细的描述,这可能增强了依赖于子目标质量的动作选择能力。
具体来说,作者对VH-1.5M进行了训练,在子目标完成时生成图像,生成结果如图5所示。决策结果如图4所示,细粒度的子目标描述比粗糙的描述更好,即使生成的图像不准确也是如此。

Motion Pattern
正如之前提到的,作者无法从当前时间步长获取光学流到下一个时间步长的光学流。因此,作者采用VQ-GAN模型预测当前的光学流图。如图5(a)和5(c)所示,对细节的预测质量是有前景的。此外,如图5(d)和5(e)所示,在VH-1.5M数据集上训练的VQ- GAN可以轻松泛化到其他环境。这是因为光学流图是一种通用的特征,不需要预测复杂的纹理。
平均端点误差(AEE)特定地测量了两个像素级运动向量之间的平均距离。如图3所示,预测的光学流图与真实值之间的差距小于前一个流图与真实值之间的差距(当前光学流图与真实值之间的差距)。此外,在VirtualHome上训练的模型仍然可以预测Habitat2.0和AI2-THOR中的光学流图[27]。这证实了VQ-GAN模型的有效性和泛化能力。
泛化
为了评估作者的方法的一般化能力,作者在一个新家庭环境中评估其性能。更详细地说,作者选择Habitat2.0,因为它与其他模拟器如AI2-THOR的高保真场景相比更高。然而,Habitat2.0并没有提供关于操作技能的帧间信息,这是不现实的。因此,作者只进行导航任务。
为了提高可用性,作者使用预训练的光学流模型RAFT[40]计算前一步的光流,因为光学流不能直接获取。RAFT结果如最后两列所示。由于VQ-GAN在5.3节中证明了在Habitat2.0中对于某种程度的泛化能力,作者可以预测新环境中的运动模式。剩下的任务是将视觉风格转移到新环境,作者采用LoRA进行世界模型微调。如图7所示,作者成功进行风格转移(只需几十个样本),并且 LoRA得到的结果比没有LoRA视觉的更接近真实场景图像。

图8显示了所有方法在Habitat2.0中导航任务的成功率。作者可以与VirtualHome环境中的相同结论:将预测光流纳入世界模型可以增强代理的决策能力。此外,作者的方法取得了很高的成功率,进一步证明了其强大的泛化能力。

6 Conclusion and Limitations
本文介绍了EgoPlan,一个使用LMM作为一次规划器和文本到图像模型作为长期任务的世界模型的具身体验代理。
作者展示了其高质量图像生成、精确的光流预测以及有前途的决策能力。
更重要的是,作者在不同环境中证实了其 generalization 能力。也要承认EgoPlan的局限性。
目前,该代理使用封装技能作为动作。它不能执行低级控制,例如关节位置。如何直接控制低级动作将留待未来研究。
参考
[1].Egocentric Vision Language Planning.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-08-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号