Spark流计算Structured Streaming实践总结

Spark流计算Structured Streaming实践总结

用户9421738
发布于 2024-08-30 16:53:50
发布于 2024-08-30 16:53:50
简介
Structured Streaming是基于Spark SQL引擎的可扩展、可容错流计算引擎。用户可以向使用批计算一样的方式使用流计算。Spark SQL持续增量计算流数据输出结果。目前支持多种开发语言Scala、Java、Python、R等等。通过checkpoint和wal机制确保端到端exactly-once语义。
默认情况下,Structured Streaming使用micro-batch处理引擎,可以实现100ms端到端延迟和exactly-once语义保证。除此之外,Structured Streaming也支持continuous处理引擎,可以实现1ms端到端延迟和at-least-once语义保证。注意:continuous处理引擎目前还不稳定,处于实验阶段。
编程模型
Structured Streaming核心思想是将实时数据流看做一个追加写的表,流计算就可以表示成为静态表上的标准批处理查询,Spark将其作为无界输入表上的增量查询运行。
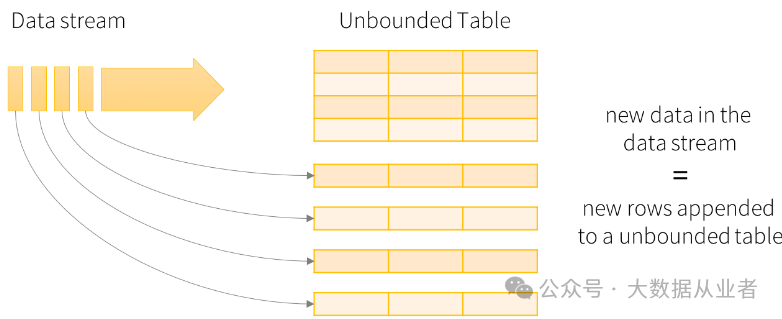
如上图所示,实时数据流映射为无界输入表,每条数据映射为输入表追加的新数据行。
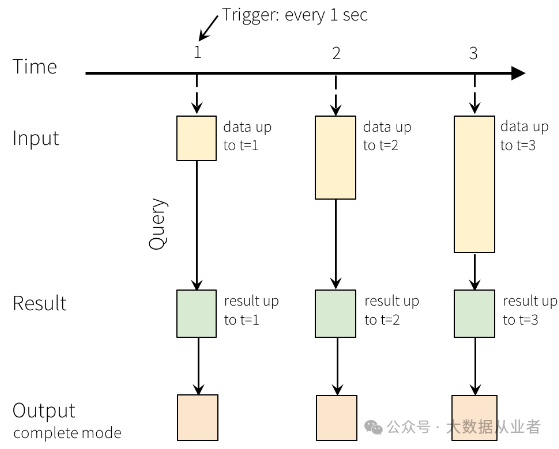
如上图所说义,输入表上的查询映射为结果表。每个触发周期,查询将输入表上新追加的数据行更新到结果表。一旦结果表更新,直接将更新后的数据写出到外部sink端。而Output定义输出写入到外部存储的具体内容模式,分为三种:
Complete Mode:每次Trigger触发输出整个结果表,适用于aggregation操作。
Append Mode(default):默认模式,输出自上次Trigger之后结果表中追加写入的行,可以确保每行数据有且仅有一次输出,适用于select、where、map、flatMap、filter、join等。
Update Mode:输出自上次Trigger之后结果表中更新的行。内置sinks
官方内置多种输出端,如下:
File sink:输出内容到文件系统目录
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()Kafka sink:输出内容到Kafka topic
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()Foreach sink:输出内容进行任意计算
writeStream
.foreach(...)
.start()
Console sink (for debugging):输出内容到标准输出,仅用于测试。
writeStream
.format("console")
.start()Memory sink (for debugging):输出内容在Driver进程内存,仅用于测试。
writeStream
.format("memory")
.queryName("tableName")
.start()每种sink所支持的输出模式和容错语义,详见下表:
输出端 | 输出模式 | 容错语义 |
|---|---|---|
File Sink | Append | Exactly-once |
Kafka Sink | Append、Update、Complete | At-least-once |
Foreach Sink | Append、Update、Complete | At-least-once |
Console Sink | Append、Update、Complete | No |
Memory Sink | Append、Complete | No |
官方示例实战
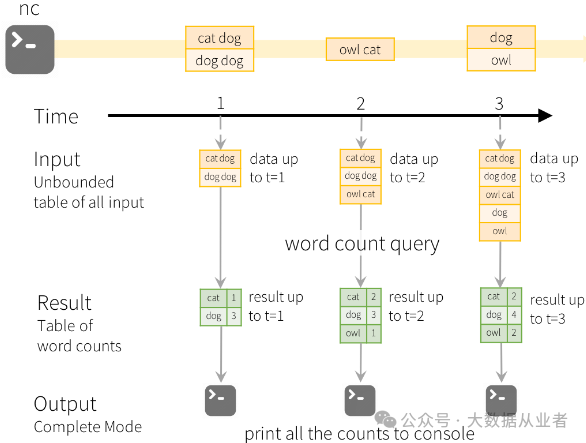
为了说明上述编程模型的实际用法,官方提供WordCount示例。输出模式使用Complete Mode,nc数据源输入内容,预期效果如下:
实测效果如下:
1.启动nc 数据源
nc –lk 99992.启动WordCount示例
./bin/run-example org.apache.spark.examples.sql.streaming.JavaStructuredNetworkWordCount localhost 99993.数据源输入数据,计算对应WorldCount如下:

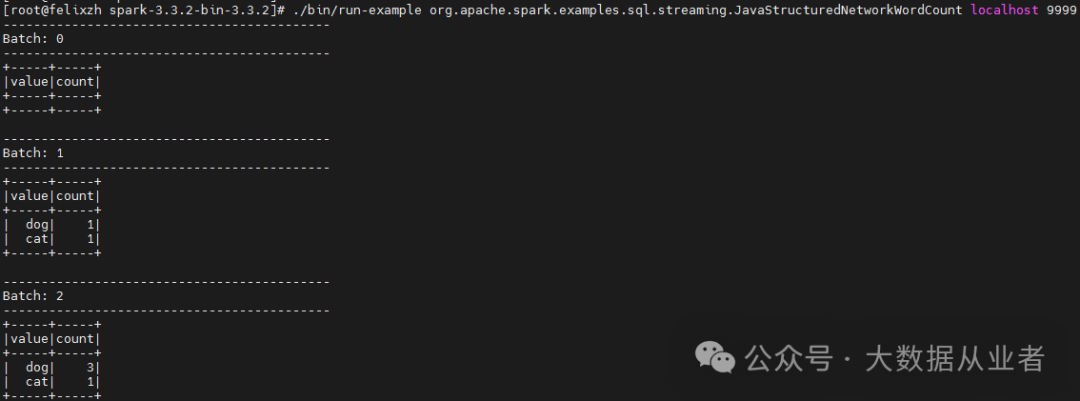
可以看出,Complete Mode时候,每次输出都是结果数据的全集。
个人实践
结合日常项目需求,本文总结记录spark streaming和structured streaming 比较常用的使用案例,如:kafka2hdfs、 kafka2kafka等等。详细完整示例见我的github:
https://github.com/felixzh2020/felixzh-java/commit/bec21e0056db0e75cca23fba5f10db03065e4e79本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-08-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号