为你的LLM应用增加记忆能力


1. 记忆系统的重要性
我们都知道,大模型本身是无状态、无记忆的。默认情况下,我们向大模型发起的每次提问,在其内部都会被视为一次全新的调用。尽管诸如 ChatGPT 等聊天应用内置了部分记忆功能,可以记录用户最近几轮的聊天信息,但它仍然存在上下文长度限制,对话历史超过一定长度后,就会强制开启新一轮对话。
为了解决这个问题,很多 AIGC 应用都需要独立开发记忆系统,特别是像 AI 聊天陪伴、RAG、智能客服等应用,记忆系统的质量决定了产品是否有能力维持长期的用户对话,这会直接影响到用户体验和产品口碑。
2. 记忆系统的主流实现方案
针对 LLM 应用的记忆系统,业界已经探索出了一些成熟的解决方案,常见的实现方式包括以下几种:
2.1 Buffer Memory——缓冲记忆
2.1.1 实现思路
这是最基础的记忆模式,将所有人类提问和 AI 生成的消息全部缓存起来,每次需要使用时将保存的所有聊天消息列表全部传递到 Prompt 中,通过往用户的输入中添加历史对话信息/记忆,可以让 LLM 能理解之前的对话内容,而且这种记忆方式在上下文窗口限制内是无损的。
2.1.2优点
- 在上下文长度限制内,可以实现无损记忆,可以记忆用户输入的全部内容;
- 实现方式简单,兼容性最好,所有大模型都支持。
2.1.3 缺点
- 一次性将全部的历史上下文都传递给 LLM,会消耗大量 token,导致响应时间变慢和成本增加;
- LLM 的上下文有最大的 token 限制,无法记忆太长的对话;
- 记忆内容不是无限的,对于上下文长度较小的模型来说,记忆内容会变得极短。
2.2 Buffer Window Memory——缓冲窗口记忆
2.2.1 实现思路
在缓冲记忆的基础上,增加上下文窗口限制,即只保留固定轮次的历史对话,“遗忘”掉过于久远的记忆。
2.2.2 优点
- 在窗口大小内可以实现无损记忆;
- 对小模型也比较友好,在不提问较为久远的内容时效果最佳;
- 实现方式简单,性能优异,所有大模型都支持。
2.2.3 缺点
- 无法保留长期的记忆,会“遗忘”之前的互动历史;
- 如果窗口内部分对话的内容较长,也容易超过 LLM 的上下文限制。
2.3. Token Buffer Memory ——Token 缓冲记忆
2.3.1 实现思路
同样是基于缓冲记忆的思想,只保留 max_tokens 长度的历史上下文,超过长度限制的历史记忆会被遗忘。
2.3.2 优点
- 可以基于特定模型的上下文长度限制,来定制化记忆长度;
- 对小模型也比较友好,如果不提问比较远的关联内容,一般效果最佳;
- 实现方式简单,性能优异,所有大模型都支持。
2.3.3 缺点
- 无法保留长期的记忆,会遗忘之前的互动。
2.4 Summary Memory——摘要总结记忆
2.4.1 实现思路
将每轮对话的输入输出,生成总结摘要,作为记忆保存起来,并在下一轮对话时传递给 LLM。
2.4.2 优点
- 可以同时支持长期记忆和短期记忆;
- 基于摘要功能,可以有效减少长对话中使用的 token 数量,能记忆更多轮的对话信息。特别是在长对话时效果更加明显。
2.4.3 缺点
- 因为记忆是基于生成的摘要,因此无论是长期记忆还是短期记忆,都是模糊记忆,会丢失对话的细节;
- 对于较短的对话,可能会增加 token 使用量(短对话时,生成的摘要可能会比原始对话更长);
- 记忆功能完全依赖于摘要 LLM 的能力,并且需要为摘要 LLM 额外分配 token,会增加使用成本。
2.5 Summary Buffer Memory——摘要+缓冲混合记忆
2.5.1 实现思路
摘要+缓冲混合记忆,结合了缓冲窗口记忆和摘要总结记忆两种模式,是目前业内采用较多的一种方案:
- 对于窗口大小内的近期对话,保留原始内容,作为短期记忆;
- 对于超过窗口大小的历史对话,生成摘要后保存,作为长期记忆;
- 将短期记忆与长期记忆合并,作为记忆保存。 例如,针对最大 token 长度为16k 的 LLM,可以设置记忆窗口 max_token = 12k,并将超过 12k 的历史对话生成摘要。
2.5.2 实现流程
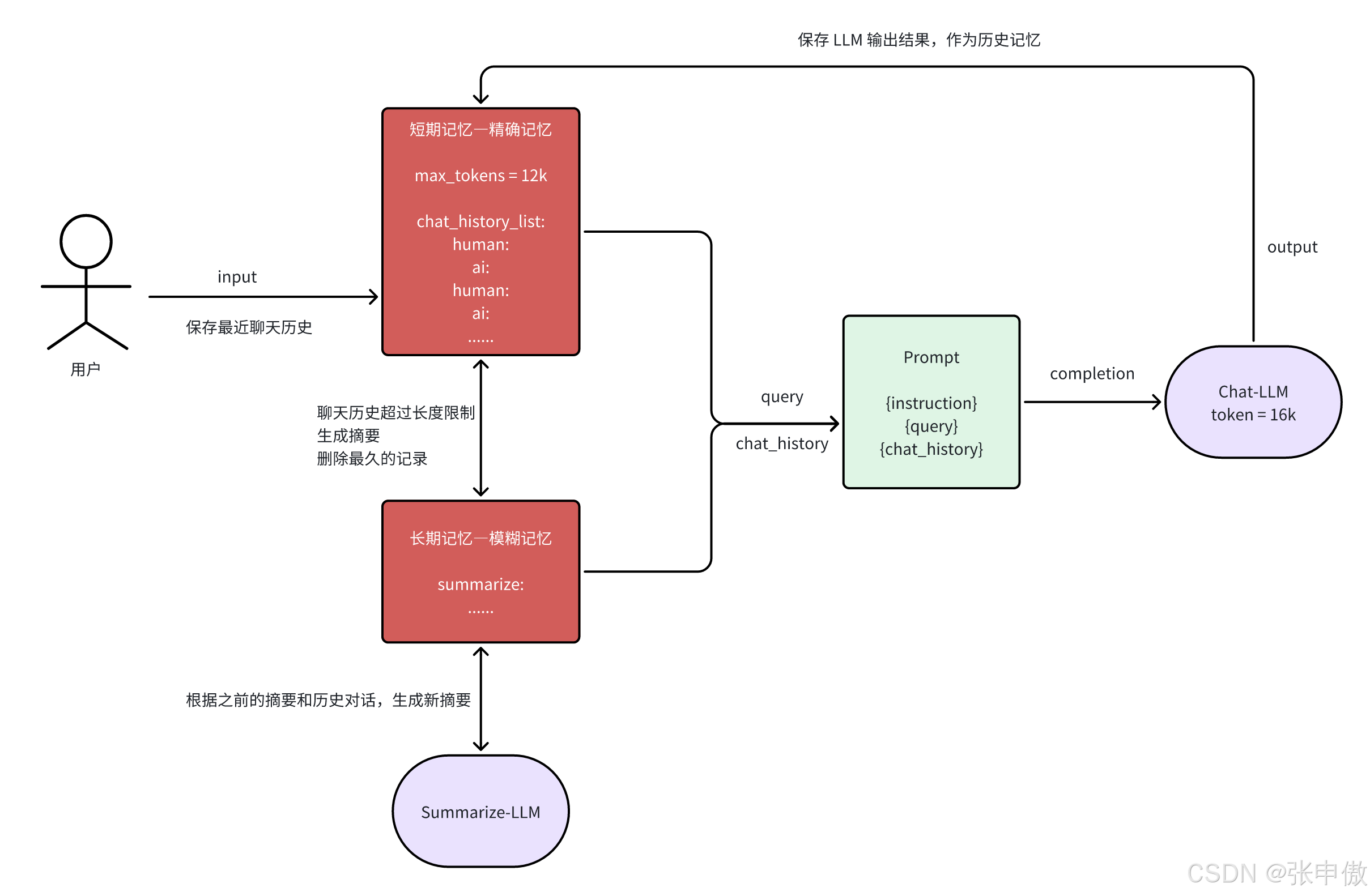
摘要缓冲混合记忆
2.5.3 优点
- 可以同时实现长期记忆和短期记忆,长期为模糊记忆,短期为精准记忆;
- 通过摘要功能,可以有效减少长对话中使用的 token 数量,能记忆更多轮的对话信息。
2.5.4 缺点
- 对于久远的历史对话为模糊记忆,会丢失部分细节。
- 长期记忆部分依赖于摘要 LLM 的能力,并且需要为摘要 LLM 额外分配 token,会增加使用成本。
2.6 Vector Store Memory——向量数据库记忆
2.6.1 实现思路
将全量记忆数据存储在向量存储中,每次搜索记忆时,基于向量检索,获取前 K 个最匹配的语料,整体的思路类似于 RAG 系统。
2.6.2 优点
- 基于向量数据库的横向扩展能力,理论上可以支持无限长度的记忆;
- 在记忆的细节上,可以比摘要总结处理地更好;
- token 的消耗相对可控。
2.6.3 缺点
- 需要向量数据库支持,增加使用成本;
- 用户的每次对话,都需要经过 Embedding 过程,性能有一定损耗;
- 记忆效果受 Embedding 检索结果的影响,效果不稳定。
3. 使用 LangChain 实战记忆系统
讲了这么多理论,下面我们动手自己实现一个简单的记忆系统。我们选择 LangChain 作为开发框架,因为 LangChain 对于 Memory 模块已经有了比较完善的封装,内置了很多开箱即用的 ChatMemory 组件,大大提升了开发效率。上面我们提到的几种记忆方案,在 LangChain 中基本都可以找到对应的实现。
LangChain_ChatMemory
下面是具体的实现代码:
# -*- coding: utf-8 -*-
"""
@Time : 2024/7/11 11:53
@Author : ZhangShenao
@File : chat_memory_chain.py
@Desc : 聊天记忆链
把聊天历史的记忆功能单独封装成一个Chain
"""
from operator import itemgetter
from typing import Dict
from langchain.memory import ConversationBufferWindowMemory
from langchain.memory.chat_memory import BaseChatMemory
from langchain_community.chat_message_histories import FileChatMessageHistory
from langchain_core.language_models import BaseChatModel
from langchain_core.output_parsers import BaseTransformOutputParser
from langchain_core.prompts import BaseChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda, RunnableConfig
from langchain_core.runnables.utils import Output
from langchain_core.tracers import Run
from typing_extensions import Any
from internal.service import VectorStoreService
CHAT_HISTORY_FILE_PATH = '../../storage/memory/chat_history.json' # 聊天历史文件路径
HISTORY_KEY = 'history' # 聊天历史Key
CONTEXT_KEY = 'context' # 上下文信息Key
INPUT_KEY = 'input' # 聊天输入Key
OUTPUT_KEY = 'output' # 聊天输出Key
MEMORY_CONFIG_KEY = 'memory' # 记忆配置Key
SAVE_CONVERSATION_ROUNDS = 5 # 保存历史对话的轮数
def invoke_chain_with_chat_memory(input: Dict[str, Any],
prompt_template: BaseChatPromptTemplate,
llm: BaseChatModel,
parser: BaseTransformOutputParser[str],
vector_store_service: VectorStoreService) -> Output:
"""
将传入的Runnable组件编排成Chain,并在此基础上封装聊天记忆功能,返回最终调用结果
:param input: 调用输入参数
:param prompt_template: 提示词模板
:param llm: LLM聊天模型
:param parser: 输出解析器
:return: Chain调用结果
"""
# 使用本地文件保存聊天历史
chat_history = FileChatMessageHistory(file_path=CHAT_HISTORY_FILE_PATH)
# 创建聊天记忆组件,使用缓冲窗口记忆方式
memory = ConversationBufferWindowMemory(
input_key=INPUT_KEY,
output_key=OUTPUT_KEY,
memory_key=HISTORY_KEY,
k=SAVE_CONVERSATION_ROUNDS, # 保留最近5轮的聊天历史,即10条消息
return_messages=True, # 结果返回聊天消息列表,而不是字符串
chat_memory=chat_history # 设置MessageHistory组件,用于持久化历史聊天记录
)
# 构建Retriever Chain,执行向量相似度检索
retriever = vector_store_service.as_retriever() | vector_store_service.join_document_page_contents
# 构造Chain执行链,用于编排组件的执行流程
chain = RunnablePassthrough.assign(
context=itemgetter(INPUT_KEY) | retriever,
history=RunnableLambda(_load_memory_variables_from_config) | itemgetter(HISTORY_KEY)
) | prompt_template | llm | parser
# 封装chain,在运行配置中传入记忆信息,并且注册on_end监听回调,在回调函数中保存聊天历史
memory_chain = (chain.with_config(configurable={MEMORY_CONFIG_KEY: memory})
.with_listeners(on_end=_save_chat_history))
# 调用memory_chain,返回结果
output = memory_chain.invoke(input)
return output
def _load_memory_variables_from_config(input: Dict[str, Any], config: RunnableConfig) -> Dict[str, Any]:
"""
从运行配置中,加载记忆变量
:param input: 运行调用输入
:param config: 运行配置
:return: 记忆变量字典
"""
# 获取运行时配置,从配置读取记忆信息
conf = config.get('configurable', {})
memory = conf.get(MEMORY_CONFIG_KEY, None)
if memory is not None and isinstance(memory, BaseChatMemory):
return memory.load_memory_variables(input)
# 空记忆信息
return {}
def _save_chat_history(run_obj: Run, config: RunnableConfig) -> None:
"""
保存聊天历史
:param run_obj: 运行时对象,包含了所有运行时的相关信息
:param config: 运行时配置信息
"""
# 获取运行时配置,从配置读取记忆信息
conf = config.get('configurable', {})
memory = conf.get(MEMORY_CONFIG_KEY, None)
if memory is not None and isinstance(memory, BaseChatMemory):
# 将当前聊天的输入输出保存到Memory中
memory.save_context(run_obj.inputs, run_obj.outputs)详细介绍一下实现思路:
- 将记忆功能单独封装成一个 chat_memory_chain。Chain 是 LangChain 中的核心组件,它可以将许多组件编排在一起,采用类似管道的方式顺序执行。
- 使用
FileChatMessageHistory组件,将聊天历史保存在本地文件系统中。MessageHistory也是 LangChain 封装的消息历史组件,下面有多种具体的实现,如RedisChatMessageHistory可以将聊天消息保存到 Redis 中、MongoDBChatMessageHistory则是保存到 MongoDB 中等等。这里我们为了方便演示,则是直接采用本地文件的方式。 - 使用
ConversationBufferWindowMemory组件,并设置 k = 5,它对应了上面的 Buffer Window Memory——缓冲窗口记忆模式,保留最近的5轮对话。 如果想选择其他记忆模式,仅需将组件替换成ConversationSummaryMemory、ConversationTokenBufferMemory等等即可。 - 利用 LangChain 的
with_listeners监听器机制,设置了on_end回调,即在每轮对话完成后,执行_save_chat_history函数,将本轮对话保存到 Memory 组件中。
通过以上的方式,即可实现一个具有缓冲窗口记忆功能的聊天应用,是不是非常简单?项目的完整代码可以参考:https://gitee.com/zhangshenao/llm-ops-backend/blob/master/internal/handler/chat_memory_chain.py
4. 实际效果演示
具备了记忆能力之后,我们就可以在本地简单测试一下聊天功能,看看大模型是否能记住之前的历史对话。 首先,我们先做个简单的自我介绍,让大模型记录相关信息:
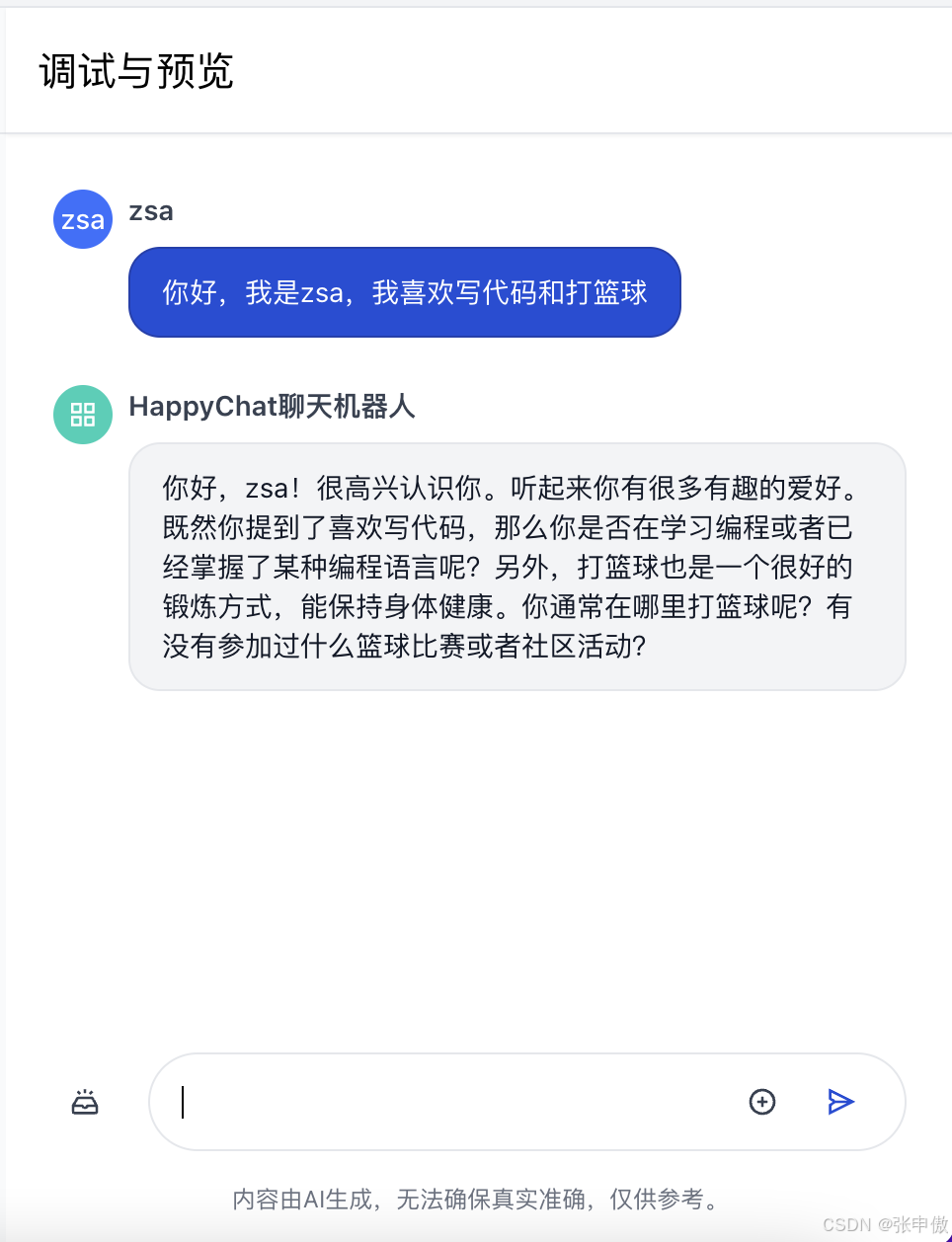
自我介绍
接下来,我们让大模型生成一些较长的内容,便于后面测试记忆能力:
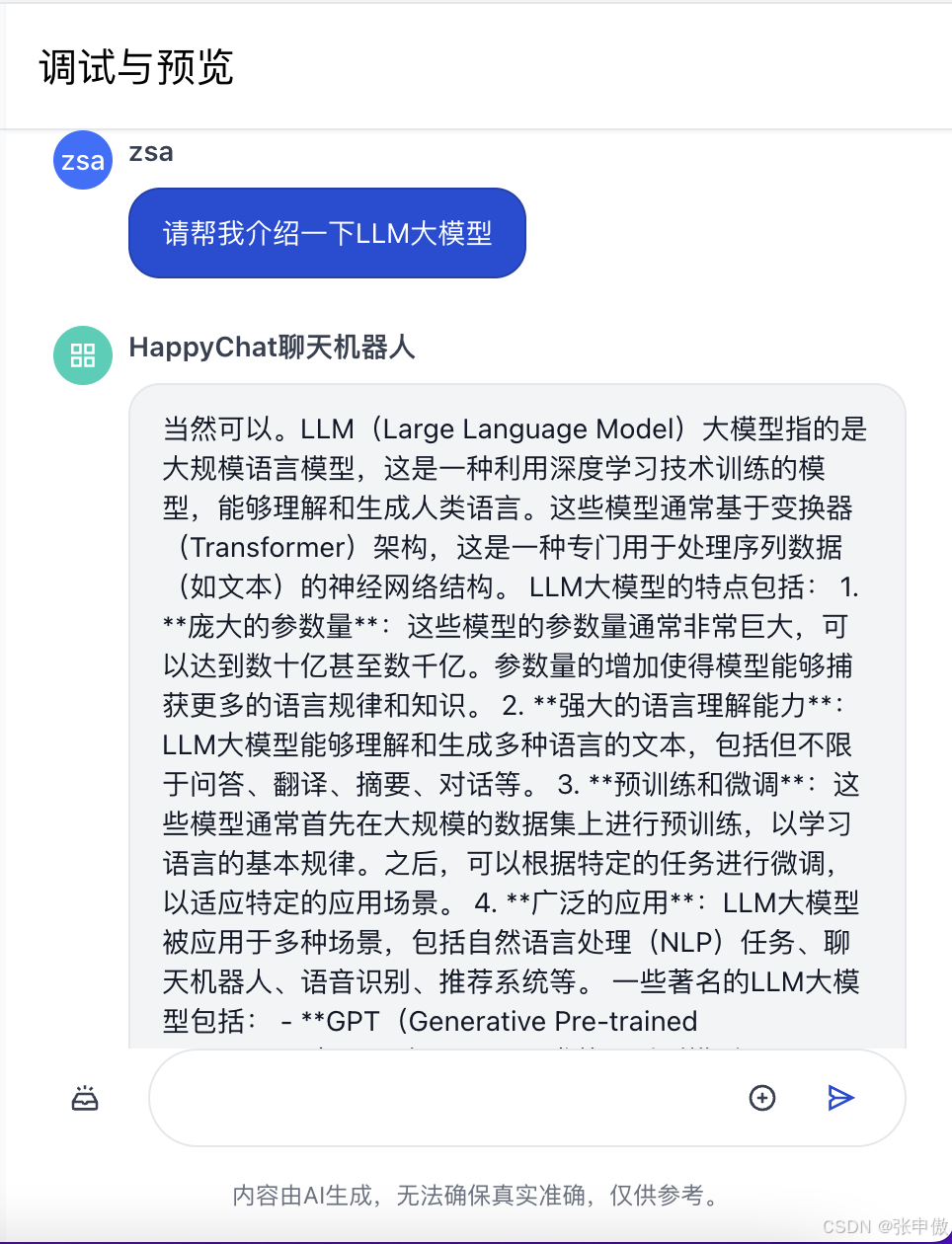
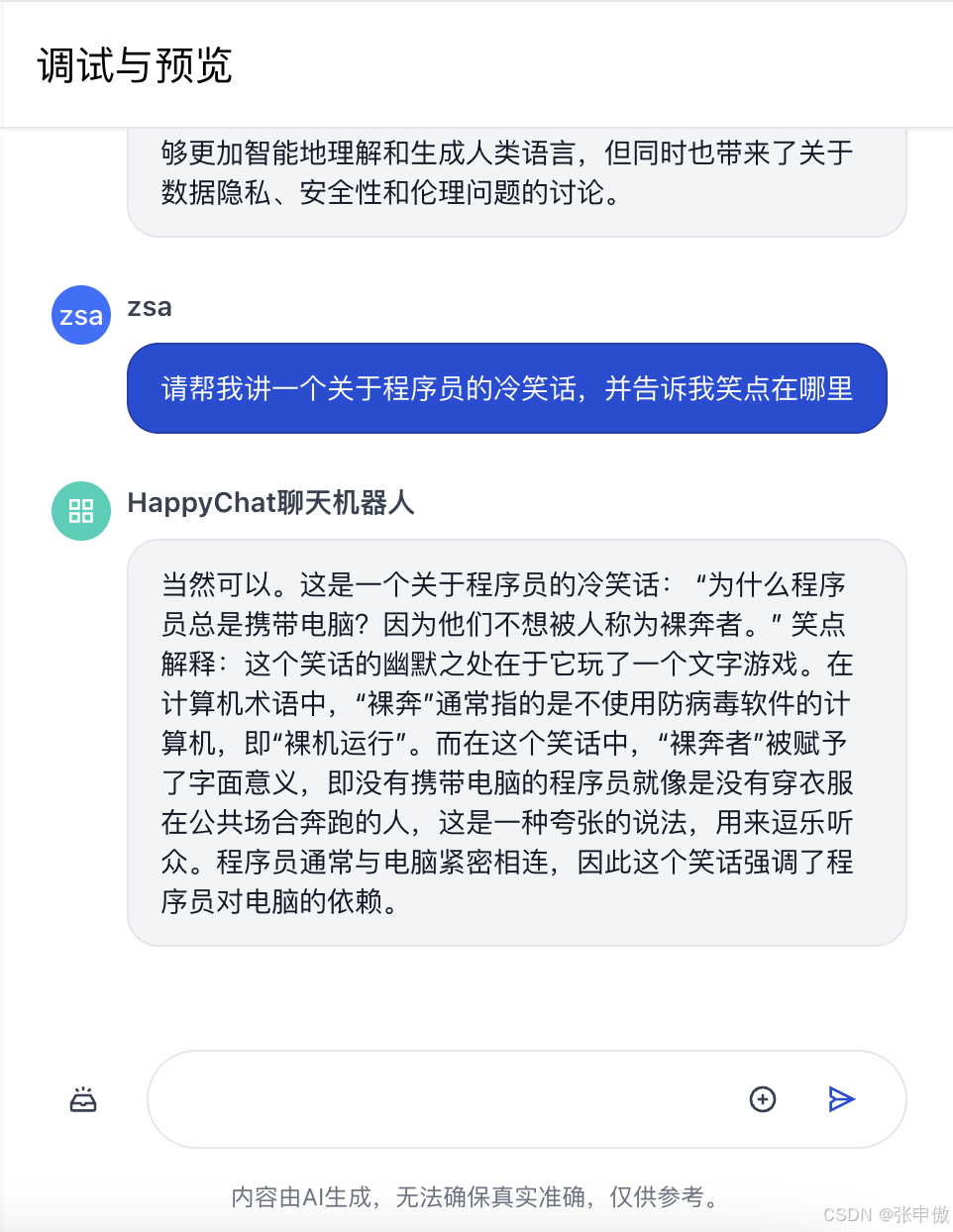
讲笑话
到这里,我们已经让大模型生成了很长的文本,肯定超过了单次上下文长度限制。 最后,我们来测试一下记忆功能,看看 LLM 是否还记得最开始的聊天信息:
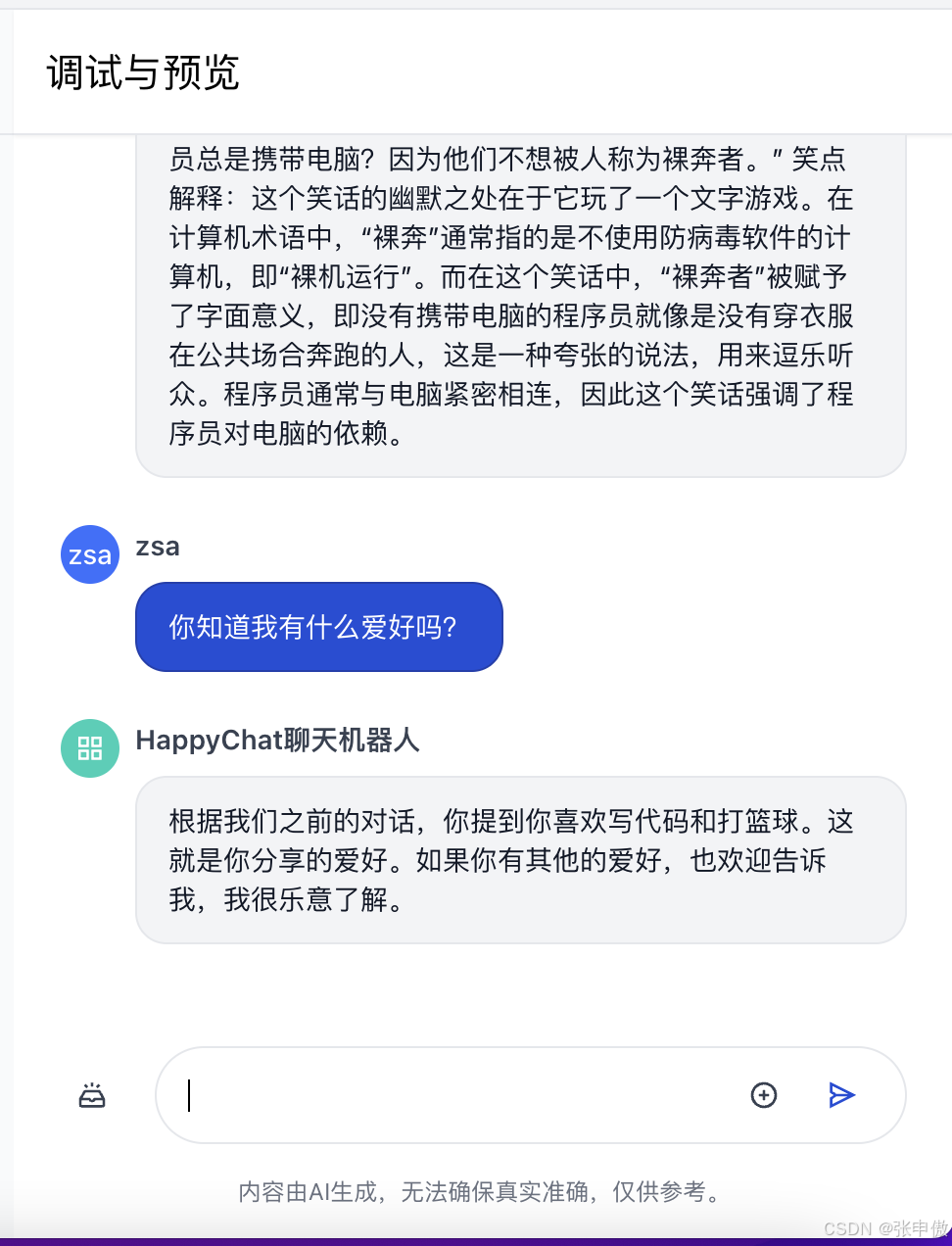
可以看到,即使中间经历了多轮对话和长文本生成,大模型仍然能够准确记忆历史的聊天信息。这说明,大模型已经具备了初步的记忆能力。
5. 总结
本篇文章首先介绍了记忆系统对于 LLM 应用的重要性,接下来介绍了业界主流的记忆系统实现方案,之后我们利用 LangChain 框架为 LLM 应用添加上记忆功能,最后简单演示了下整体效果。 如果我们把大模型比作人类的大脑,那么记忆则是大脑非常重要的一项原生能力。可惜的是,即使是目前最先进的大模型,其记忆能力还是完全无法媲美人类,已有的记忆方案更像是打补丁,并没有将记忆内化到大模型内部。 一方面,我们在通过各种工程化的方式,如 GraphRAG 来优化记忆功能;另一方面,大模型自身参数、算力和上下文长度等维度的提升,也有助于记忆能力的扩展。希望在未来的某一天,大模型可以具备堪比人类的记忆能力,那时候才有可能真正实现 AGI。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-09-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号