多语言BERT与图像编码器:EfficientNet0和微型Swin Transformer在视觉检索中的应用 !

多语言BERT与图像编码器:EfficientNet0和微型Swin Transformer在视觉检索中的应用 !

AIGC 先锋科技
发布于 2024-09-10 20:58:07
发布于 2024-09-10 20:58:07

本研究探索了在低资源语言中为图像检索开发多模视觉语言模型,特别是阿塞拜疆。现有的视觉语言模型主要支持高资源语言,并在计算上是耗时的。 为解决低资源语言视觉检索的挑战,作者将CLIP模型架构集成并采用了一些技术,以便在计算效率和性能之间实现平衡。这些技术包括通过机器翻译、图像增强和特定领域数据进一步训练变形器基础模型的注意机制。 作者将多语言BERT作为像ResNet50、EfficientNet0、图像 Transformer (ViT)和微型 Swin Transformer 那样的图像编码器。作者的研究表明,像EfficientNet0和微型Swin Transformer在它们训练的数据集(如COCO、Flickr30k和Flickr8k)上表现最好。 增强技术将EfficientNet0在Flickr30k上的MAP提高到了0.87,将ResNet50在MSCOCO上的MAP提高到了0.80,从而在视觉语言检索方面创造了新的最先进水平(SOTA)。 作者将作者的配置和结果分享给进一步的研究。 代码和预训练模型可在https://github.com/aliasgerovs/azclip。
1 Introduction
数字世界充斥着大量信息。文本、图像和视频以空前的速度被生产出来,针对文本 Query 的传统搜索系统跟不上节拍。基于关键词的搜索通常产生大量的结果,无法捕捉用户的意图或多媒体数据的丰富性,为获取所需信息设置了障碍。理想情况下,信息检索系统应该允许用户不受本族语言或首选交互方式的限制找到所需内容。这就是多模态检索变得至关重要的地方,因为它允许使用不仅仅是文本,还有图片、口头语言或不同输入模态的组合进行搜索。这种方法显著提高了搜索能力,使信息对人们来说更加触手可及,无论他们说的是哪种语言,无论他们喜欢如何搜索。例如,在图像到图像的搜索中,可以将相机对准一座建筑物来搜索其建筑风格,或者使用一幅画来在网上找到衣服。这些例子说明了多模态数据检索如何帮助人们更高效地搜索。
然而,存在一个重大的挑战,即大多数多模态数据检索系统依赖于在大量复杂数据集上训练的大型、复杂的模型。这些模型资源消耗大,需要在特定语言上获取大量的训练数据,为语言资源有限的挑战。这项研究旨在填补这一差距,使这些模型的利益对所有人开放。通过提高这些系统在内存和计算上的效率,并利用所有语言的大量可用图像数据,作者可以解锁多模态检索对所有语言的潜力。大多数最新多模态系统在低资源语言设置中存在可伸缩性问题,在数据量大、维度过高的情况下效率较低。
数据类型可用性的不平衡复杂化了低资源语言中进行多模态系统研究或训练的过程。此外,高级模型的计算需求非常高,而且无法根据有限的计算资源进行调整。因此,基于CLIP或类似模型的数万亿参数的系统在低资源语言中并不广泛适用。本研究的 primary objective 是为阿塞拜疆语言开发一个适应多模态视觉语言检索系统,在低资源设置中平衡计算效率和可伸缩性。这项研究的一个重要组成部分是分析在不同领域训练模型的方法,重点关注数据受到限制的情况。
目标是创建一个在阿塞拜疆语言中表现良好,并代表其他类似低资源语言(如哈萨克或乌兹别克)可伸缩骨架的模型。这种方法旨在将强大的AI技术扩展到各种语言多样且低资源丰富的设置,使计算困难的任务对更广泛的受众变得容易。
作者的主要贡献是:
- 为阿塞拜疆语言开发和广泛验证了一个多模态视觉语言检索模型,创建了一个特殊的图像检索模型,可以在低资源语言环境中有效地执行。
- 为模型设计领域的计算效率做出了贡献。该模型可以轻松复制为其他低资源语言,其高计算效率降低了操作需求,并允许操作部署。
- 比较了视觉编码器和解码器和域内和域外数据的性能,以估计泛化和扩充过程,这一过程通过评估它们如何适应新、未见过的环境进行了评估。
2 Literature Review
Introduction to Multimodal Retrieval
多模态检索系统已成为人工智能研究领域的一个重要课题,因为它关注于在多种模态(例如视觉和文本/语音等)下分析数据。Frome等人提出的深度视觉语义嵌入模型 是这个领域的基石贡献之一。由于该模型将视觉和文本数据合并到一个表示空间中,因此启发了该领域许多即将推出之作。接着,Radford开发了CLIP(Radford等,2021年)- 对比语言图像预训练,该方法使用自然语言中的描述来识别视觉概念。随后,开发了新的架构,使得文本和视觉数据的交互更好。Visual-BERT 和 ViLBERT 均使用转型设计作为其架构的一部分,以接收视觉和文本视角的输入。LXMERT是最近的另一个实例,该模型适用于更通用的多模态任务,例如更好地理解图像和文本,例如视觉问答。总的来说,所提及的系统遵循了从早期的模型(例如DeViSE(Frome等人,2013年)和CLIP(Radford等,2021年)开始整合视觉文本数据的趋势,该趋势已经扩展到包括越来越多的任务,从物体识别到翻译。
History of Image Retrieval Techniques
近年来,图像检索的先进发展深受深度学习技术整合的影响,特别是从基于关键词的方法向更先进的上下文分析的转变。早期的方法如Swain和Ballard的色索引,标志着从外部关键词依赖转向利用图像内在特性。卷积神经网络(CNNs)使得可以提取复杂的图像特征,通过识别图像中更高级的内容来改进检索过程。Srivastava和Salakhutdinov 探索的多模态学习,使用文本和图像数据来学习深度表示,进一步发展了该领域。像AlexNet这样的模型以及更近的基于 Transformer 的架构,已经精进了图像特征与视觉词汇的提取和匹配,显着提高了任务效率并使处理实现实时化,如Joulin等人所示以及Radford等人所示(Radford等人,2021年)。
Dataset Development and Challenges
大规模数据集如COCO,Flickr 8k/30k和ROCO的创建对于训练和评估多模态模型至关重要,尽管存在关于代表性和文化偏见的一些批评(Sharma等人,2018年)。COCO因其庞大的图像集和物体类别而在这类任务中发挥了关键作用(Lin等人,2014年),而专门的数据集如ROCO已经解决了医学影像的具体需求(Pino等人,2019年)。然而,仍存在挑战,尤其是在低资源语言环境中,数据稀少和计算限制降低了多模态模型的有效性(Agic和Vulic,2020年;Lewis和Denoyer,2020年)。图像和文本表示方法的最近发展,包括ResNet(He等人,2016年),视觉 Transformer (Dosovitskiy等人,2021年)和BERT(Devlin等人,2019年),进步了特征提取和理解。然而,这些进步也强调了在资源有限的环境中需要高效的、可适应的模型。人工数据生成,如Varol等人(2017年)(Varol等人,2017年)所演示的,提供了一种有价值的方法来解决这个问题,即在真实数据稀缺或敏感的地方提供高质量训练数据。
3 Research Methodology
Method
本系统的核心是基于两个主要组件:图像编码器和服务器,一起处理和比较视觉和文本数据。图像编码器使用一个预训练网络(例如,ResNet50),该网络被调整以忽略最后的分类层,而是专注于提取图像的特征表示。文本编码器则采用了一个预训练的BERT模型,该模型能够理解多种语言,因此在处理各种语言的文本(BertModel来自Hugging Face)方面非常适合。
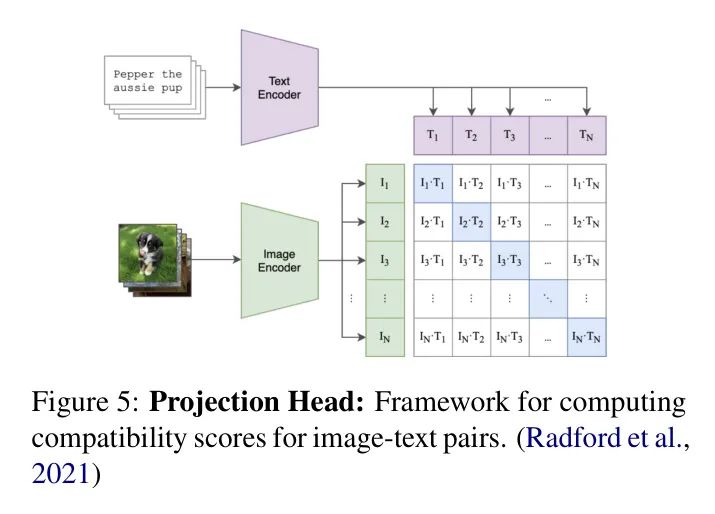
为了建立图像和文本表示之间的联系,作者在两个编码器的输出上使用了一个投影头。因此,组件的目的是将输出的维度降低到相似的大小。同时,能够实际比较图像和文本特征的技术对比损失,同时也帮助模型理解哪些图像和文本它已经被学习到相关。
算法1 训练一个CLIP模型

Dataset and Preprocessing
这项研究基于多个现有和最近的数据集,这些数据集已经进行了阿塞拜疆语翻译,以促进在机器学习中的少研究的语言的有效训练。一个关键的数据集是MS COCO数据集,用于详细理解和识别图像。它包含大量的视觉信息,包括详细的描述和详细的分割,对于训练模型在自然环境中理解复杂场景具有价值(Lin等人,2014)(Lin等人,2014)。另一个是Flickr30k数据集,它包含来自Flickr的31,000张图片,每个图片都由五个不同的描述组成,详细描绘了所显示的场景、物体和活动,从而增强了模型解释和生成关于图像的细微文本的能力(Young等人,2014)(Young等人,2014)。ROCO(Visual Context for Medical Objects)数据集包括医学影像数据,例如与描述文本配对的影像扫描,扩展了模型处理和理解医学影像的能力(Pelka等人,2018)(Pelka等人,2018)。
3.2.1 Generated Dataset for Azerbaijan Language
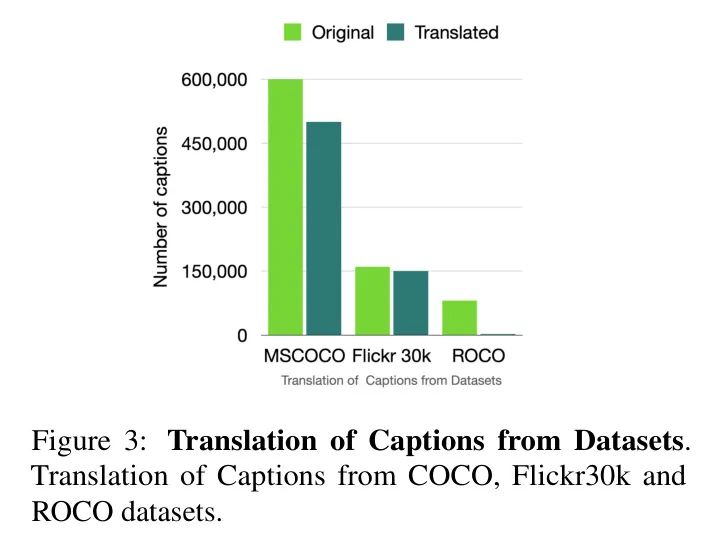
本研究为了支持阿塞拜疆语,因为它是低资源语言,所以在研究中使用了阿塞拜疆语的图像-文本对。作者所做的是,作者将COCO数据集中的超过50万个描述从英语翻译成阿塞拜疆语,同时也包括Flickr30k的90%描述(见图3)。
这些数据集经历了几个预处理步骤,以确保模型训练的高质量数据:
数据清洗: 在准备数据集的主要步骤中,包括排除和删除数据集中的损坏或不相关的描述。有些图像没有5个描述可用,作者必须删除这些样本,因为这将导致数据集的偏差。作者还使用了其他类型的数据清洗技术,以确保作者的数据集中不含有特殊字符和噪音。
文本翻译: 与Microsoft COCO数据集中的图像相关的文本,拥有超过50万个描述,以及来自Flickr的超过4万个描述,作者还从ROCO数据集中超过了2500个描述,这些文本都被翻译成阿塞拜疆语,以构建一个支持这种语言的数据集,从而扩大了模型的可用性。
Image Encoders
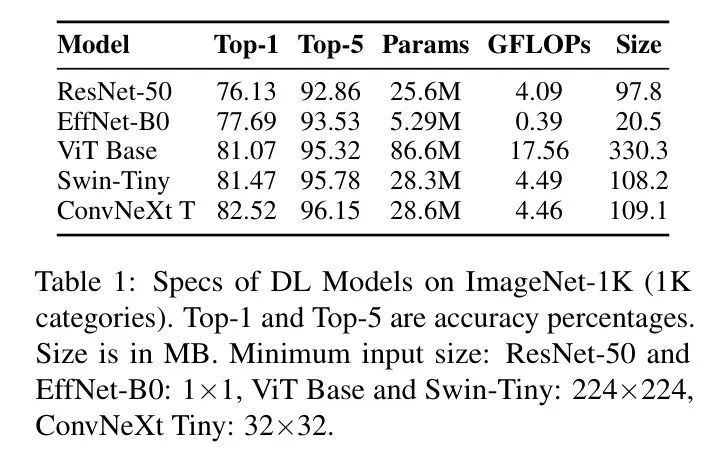
图5所示的架构能够有效地处理视觉和文本数据,同时增强涉及视觉和语言的任务的性能,尤其是在低资源设置下(由于数据和计算需求降低)能有效处理。通过将图像编码和文本嵌入相结合,并使用较小的模型,可以在不进行 extensive 微调的同时通过图像增强和特定领域的文本数据增强编码能力,从而提高多语言BERT模型中的注意力机制。图像编码器使用了预训练的CNN模型,最后一层修改为身份映射以获得丰富的图像表示。各类CNN架构,如ResNet-50、EfficientNet-B0、视觉Transformer(ViT)、Swin Transformer、ConvNeXt,在多模态检索任务中被测试其特征提取能力。每个模型都在ImageNet-1K上的top-1和top-5准确率、参数数量、GFLOPS和模型文件大小等指标上进行评估,以便根据具体应用需求选择合适的架构。
Text Encoder
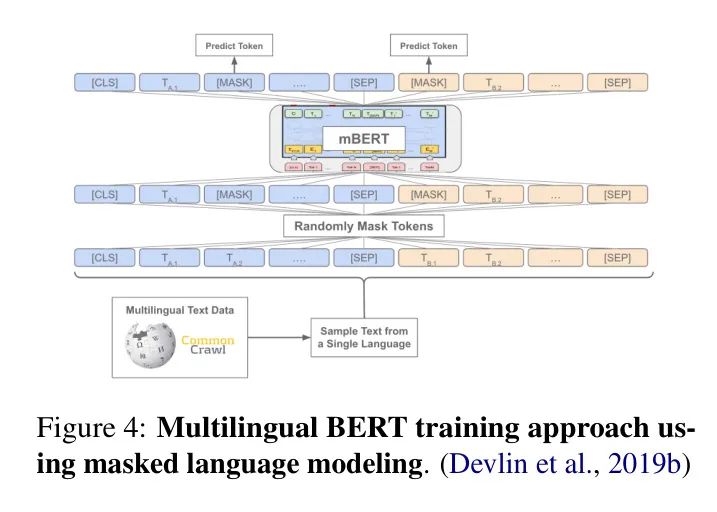
作者使用了针对低资源语言的多语言BERT(Devlin等人,2019),具有超过104种语言的标记支持,非常适合需要多样化语言支持的应用(见图4)。
3.4.1 Projection Head
图2:COCO数据集。来自微软COCO Caption数据集(Lin等人,2014年的文章)的示例图像和标题。

图像和文本编码器具有一个投影头,可以将高维特征映射到共享的嵌入空间,从而增强对比学习效率(参见图5)。
3.4.2 Contrastive Learning Loss
该模型采用对比学习损失,旨在最大程度地提高正确图像-文本对之间的相似度,同时最小化错误图像-文本对之间的相似度,通过引入边缘基罚用来提高区分能力。
(公式1至公式4如下)
3.4.3 Enhancing Feature Extraction
适应性特征学习和多分辨率特征提取技术被引入,以优化图像特征提取,根据图像内容调整网络响应,并按不同分辨率处理图像。用领域特定数据(来自维基百科)重训练多语言BERT,并采用分层注意网络,以提高模型在文本特征提取方面的能力,使其更高效地处理复杂的 Multi-modal 输入。通过将这些技术集成到图像和文本特征提取两方面,该系统实现了更强大、更适应的特征提取过程,从而增强了它在多模态任务中的整体性能。
3.4.4 Training Procedure
训练过程使用了AdamW优化器和动态学习率调度策略来提高模型性能。为了防止过拟合,作者采用了dropout和数据增强等正则化技术(见图6)。
Image Retrieval Process
表1:图像Net-1K(1K个类别)上的DL模型特性。Top-1和Top-5分别为准确率百分比。大小以MB为单位。输入最小尺寸:ResNet-50 和 EffNet-B0: 11,ViT Base 和 Swin-Tiny: 224224,ConvNeXt Tiny: 3232。
检索过程首先加载预计算的图像特征表示,这些是来自MSCOCO数据集的视觉内容的张量表示。作者已经预先计算了图像特征表示并保存在本地仓库中,这是一次任务,有助于提高速度并避免在每次 Query 中浪费计算资源。接着将训练好的模型设置为评估模式,即禁用训练特定操作如dropout以保持推理一致性。然后将给定的输入文本, Query 进行分词、填充和截断以确保统一长度,并使用预训练的文本编码器将其转换为文本嵌入。接下来,任务是将此嵌入通过线性层投影以与图像嵌入的维度对齐,并进行归一化以促进尺度不变的比较。
计算文本和图像嵌入之间的相似度使用余弦相似度度量,该度量在数学上表示为:
其中:
- 和是长度为n的两个向量。
- 和分别是向量和的相应分量。
作者正在识别具有最高相似度分数的前k个图像的索引。这些索引用于从数据集中检索相应的图像ID,它们代表与给定文本描述最相似的图像。检索过程的结束是输出最佳匹配文本 Query 的图像ID。
Evaluation Metrics
对于图像检索任务的评估,选择能有效捕获检索图像的准确性和相关性的指标非常重要。以下指标被用来量化图像检索系统的性能:
精确度:精确度(P)衡量了检索到的图像中有多少是相关的。它按照公式计算:
检索到的相关图像数量检索到的图像总数
召回率:召回率(R)衡量了成功检索到的相关图像的比例。它由公式给出:
检索到的相关图像数量全部相关图像数量
3.6.1 Mean Average Precision (MAP)
平均平均精确度(MAP)是一个收集每检索到相关图像后所有 Query 图像平均精确度分数的度量标准。这提供了一个关于多个检索效果的综合衡量。MAP的公式为:
其中,代表 Query 的次数,代表针对第次 Query 的相关图像数量,而表示在截断值处针对每个相关图像计算的精确度。
3.6.2 Mean Average Recall (MAR)
平均平均恢复率(MAR)是一种全面的指标,它将每个相关图像的恢复率平均值相加,这些相关图像是针对所有 Query 进行检索的。它提供了多个 Query 图像的性能的综合衡量。MAR的公式为:
图7:AzClip基础模型(Epochs)
其中,表示 Query 的数量,表示 Query 的相关图像数量,是在截取值处计算的恢复率,该值对应于每个相关图像在检索位置。
MAR可以有效地整合每个 Query 的性能,并提供了一种客观、简洁地衡量不同 Query 图像之间的差异的方法。
3.6.3 Mean Average F1 Score (MAF1)
平均平均F1得分(MAF1)是一种全面度量,它将在每个相关图像被检索后,对所有 Query 求平均F1分数。在相关图像分布不均匀的场景中,特别是平衡精度和召回率方面,它特别有用。MAF1的公式为:
其中Q表示 Query 数量,而表示 Query q的F1-分数,计算方式如下:
Precision和Recall是在每个相关检索点上计算的,以确保该度量反映了所有 Query 之间的检索效果平衡。
3.6.4 Mean Average Accuracy (Top-k Accuracy)
均值平均准确率(Mean Average Accuracy)用于顶部K(其中k是1、5或10)是一个关键的度量标准,用于衡量模型在识别所有 Query 的顶K个预测中的正确答案的准确性。特别是在多个潜在正确答案都可行,但它们的准确排序不那么关键的场景中,这个度量标准尤为重要。均值平均顶部K(Top-k)准确率的公式如下:
其中,Q表示 Query 数量,Accuracy表示对于 Query q,其正确答案是否出现在前k个结果中,定义为:
这个度量标准强调了模型在输出列表的顶部呈现高度相关的结果的有效性,这在搜索和推荐系统中尤为有用,即立即的相关性至关重要。
4 Implementation
第四节 实现部分的开端。
Experiment Design
作者的实验利用了多种模型,并与Base Multilingual BERT结合,用于处理阿塞拜疆语文本:
架构: ResNet50, EfficientNet0, Vision Transformer (ViT), Tiny Swin Transformer。
数据集: MSCOCO, Flickr8k, Flickr30k。还使用机器翻译和增强技术生成了模拟低资源条件的合成数据集。
指标: 平均平均 precision (MAP),平均平均召回率 (MAR),平均平均 F1-Score (MAF1), Top-K 准确率指标(Top1, Top5, Top10)
- ResNet50 + Multilingual BERT: 在 MSCOCO 上进行评估,通用到 Flickr8k 和 Flickr30k。
- 图像增强数据 ResNet50 + Multilingual BERT: 在 Flickr30k 上评估图像增强的影响,并将其通用到 MSCOCO 和 Flickr8k。
- EfficientNet0 + Multilingual BERT: 在 Flickr30k 上评估基础性能,并将其扩展到 MSCOCO 和 Flickr8k。
- 增强数据 EfficientNet0 + 增强 Multilingual BERT: 探索图像增强和增强的 BERT 技术对 Flickr30k 的影响,并将其通用到 MSCOCO 和 Flickr8k。
- ViT + Multilingual BERT: 在 Flickr8k 上测试,通用到 Flickr30k 和 MSCOCO。
Controlled Variables and Their Impact on Model Performance
在本文节中,作者以系统化的方式描述了每个实验中的不同变量,并探讨了这些变量如何随着目的和意图的变化而变化,旨在研究这些变量对性能的影响。的所有这些变量都为优化和扩展模型在不同的设置(特别是在低资源下和不同领域)提供了洞察。
模型配置:实验中尝试了不同的文本和图像编码模型配置,如不同的层数,激活函数和微调深度,以找到最能平衡性能和计算效率的特征组合。这包括将标准BERT架构与多语言版本进行比较,以及为图像编码器尝试不同的后端架构,包括ResNet-50相对于其他选项。这旨在检查不同设置提供在准确性和计算负载之间的权衡。
数据集大小和质量:通过在不同大小和条件的数据集(如MSCOCO和Flickr30k,Flickr8k等)上训练和测试模型,评估了对数据质量和数据集大小的敏感性。测试了数据增强技术对提高数据质量和使用模型性能的影响,以获取模型在意外的真实世界环境数据集上可能表现如何的看法。
计算约束:实验中的性能测量针对实时部署,尤其是在低资源设置。在这方面,模型在不同的计算约束下的性能非常重要,因此作者选择了入门级GPU,如Nvidia T4。为获得最佳性能与计算需求之间的权衡效率,在实践中由于计算约束更为关键。
当这些在不同实验中变化的参数可以理解时,这有助于构建不仅适合理想条件下性能最优的模型,还确保在多样化和具有挑战性的环境中具有实用性。例如,如果需要将模型部署到另一个领域,该领域没有或者只有很少的描述可用来进一步训练模型,那么模型本身应该能够适应其他领域。
- MSCOCO等数据集中丰富的标注和多样化图像内容导致模型性能更好。
- 数据源的增强一致地提高了模型精度。
- 域间性能差距突出显示了模型应更好地泛化跨不同数据集的需求。
- 在计算效率和精度之间保持谨慎的平衡,尤其是在资源受限的环境中,尤为重要。
这些发现强调了数据集质量的重要性,增益数据的好处以及模型和数据异构性的挑战。解决这些挑战是推进视觉语言模型最先进技术的关键。
Analysis of Results
作者对各种模型架构在COCO、Flickr30k和Flickr8k等数据集上的性能进行了研究,揭示了在不同数据环境下模型泛化的复杂性。作者对ResNet50、EfficientNet0、视觉 Transformer 、Tiny Swin Transformer 和Base多语言BERT等模型进行了评估,发现在原数据集上的模型性能优于异领域数据集。主要评估指标如MAP、MAR和MAF1用于评估模型在多模态图像检索任务中的性能。例如,在基础损失条件下,ResNet50在MSCOCO数据集上的MAP从0.70增加到0.80。增益技术进一步提高了性能,Flickr30k数据集上的MAP达到0.82。EfficientNet0在Flickr30k数据集上实现了0.84的MAP,在数据增益之后提高了到0.87。视觉 Transformer 和Tiny Swin Transformer 在Flickr8k数据集上也展示了强大的性能,分别实现了0.80和0.84的MAP。这些发现强调了架构变化和数据增益在跨域模型泛化的显著影响,显示了仔细的数据增强和损失函数优化可以平衡性能和计算效率。
5 Limitations
作者对低资源语言的视觉语言检索系统进行了多模态研究,发现了关键局限性:
合成数据质量:性能严重依赖于合成数据的准确性,例如从英语翻译成阿塞拜疆语的合成字幕。确保高质量的数据(可能通过人工验证)至关重要,以避免错误和偏见。
可扩展性和泛化性:从一个语言过渡到另一个语言可以相对容易,但在同一语言内部从一个领域过渡到另一个领域仍然是一个重大的挑战。在特定领域训练的模型通常在没有进行广泛调整的情况下很难泛化到其他领域。
6 Conclusion and Future Work
本研究发现了一种多模态视觉语言模型在低资源语言图像检索中的应用,特别关注阿塞拜疆。通过使用合成数据集——通过机器翻译和数据增强将英文翻译为阿塞拜疆语,研究发现传统模型的检索准确性得到了提高。未来的关键方向包括:
- 扩展到其他低资源语言并进行增强的数据增强:将该方法扩展到其他低资源语言,并整合高级数据增强,并让人类审核以提高合成数据集的质量,可能可以增强模型性能。
- 跨领域的架构评估:在翻译的ROCO数据集上测试各种架构,尤其是在医疗影像等多样化领域,可能提供宝贵的洞察。
- 图像描述和节能优化:探索图像描述的逆任务,并优化模型在资源受限环境下的效率,可能使模型能够在移动设备上部署。
- 交互式用户反馈系统:开发能够结合用户反馈来调整模型输出的系统,可能可以提高检索准确性和用户满意度。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-09-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号