什么是检索增强生成 (RAG)?简单易懂,一文说清其组成和作用原理
原创
什么是检索增强生成 (RAG)?简单易懂,一文说清其组成和作用原理
原创
DenserAI_Chris
发布于 2024-09-15 21:02:32
发布于 2024-09-15 21:02:32
人工智能一直在帮助企业处理各种事务,从简单的客户查询到复杂的问题解决。然而,即使是最先进的人工智能模型有时也会有不足之处,提供的答案也不太准确。
这就是检索增强生成 (RAG) 发挥作用的地方。它通过使用实时数据改进了 AI 模型生成内容的方式。
像 RAG 这样的 AI 系统不仅依赖过时的信息,还会主动搜索最新和最相关的数据来回答客户的问题。它将 AI 模型的广泛知识库与实时数据检索的准确性相结合。这样不仅可以提供准确的响应,而且可以完美地适应上下文。
在本文中,我们将探讨 RAG 的工作原理及其改变企业使用 AI 方式的潜力。
什么是检索增强生成?
检索增强生成是人工智能中的一种先进技术,它通过将外部知识源整合到大型语言模型 (LLM) 的生成过程中来提高其能力。
与仅基于预先训练的知识生成响应的传统 LLM 不同,RAG 从外部数据库或文档中检索相关信息,并使用这些信息生成更准确、更符合上下文的响应。
这种方法可确保输出基于最新、最权威的数据,对于需要最新信息的应用程序特别有用。
RAG 系统的关键组件
为了全面理解 RAG,重要的是分解其主要组成部分:信息检索 (IR) 系统和自然语言生成 (NLG) 模型。
信息检索
IR 系统使用高级搜索算法来扫描大型数据集并快速找到相关信息。这些算法采用语义搜索技术,超越了简单的关键字匹配,能够理解查询的上下文和含义。
RAG 系统可以从多个来源检索数据,包括内部数据库、在线存储库和实时网络搜索。这些数据源的质量和范围对于系统的有效性至关重要。
自然语言生成
NLG 组件依赖于强大的语言模型,例如 GPT-3,这些模型能够生成类似人类的文本。这些模型在庞大的数据集上进行训练,使其能够创建连贯且与上下文相关的响应。
NLG 涉及多种技术,以确保生成的文本相关且准确。这包括使用特定领域的数据微调模型和使用高级文本生成算法。
为什么使用 RAG?
RAG 解决了 LLM 的几个固有局限性,例如其依赖静态训练数据,这可能导致响应过时或不准确。通过集成外部知识库,RAG 使 LLM 能够访问实时信息,从而提高其响应的相关性和准确性。
这种方法降低了错误信息出现的可能性,并增强了人们对 AI 输出的信任。此外,RAG 还允许组织控制和更新知识源,从而提供更具动态性和适应性的 AI 解决方案。
RAG 的 4 个优点和用例
如果将实时信息检索与高级 NLG 相结合,它可以帮助 RAG 系统提供更准确、更相关且更符合语境的响应。以下是使 RAG 适用于各行各业广泛应用的关键优势。
1. 经济高效的实施
与使用新数据重新训练大型语言模型相比,使用 RAG 更经济实惠。它允许您添加新信息,而无需大量重新训练带来的高昂技术和财务费用。
2. 当前信息
RAG 可让 LLM 连接实时数据、新闻网站和其他经常更新的信息源,提供最新信息。即使出现新信息,此功能也能确保响应保持相关性和准确性。
3. 提高用户信任度
提供包含权威来源的引用或参考的回复可以帮助 RAG 建立用户信任。用户可以验证信息,从而对 AI 生成的回复更有信心。
4. 更多开发人员控制
RAG 为开发人员提供了灵活性,使他们能够更有效地更改信息源并解决问题。它还允许根据授权级别限制敏感信息检索,确保响应适用于不同的上下文。
RAG 如何工作?
了解 RAG 的内部工作原理有助于我们认识到其改进 AI 生成内容的潜力。RAG 流程涉及几个关键步骤:
创建外部数据
外部数据存在于 LLM 原始训练数据之外,是从各种来源(例如 API、数据库或文档存储库)收集的。然后使用嵌入语言模型将这些数据转换为数值表示并存储在矢量数据库中,从而创建生成式 AI 模型可以访问的知识库。
检索相关信息
当收到用户查询时,它会被转换成向量表示,并与向量数据库匹配以检索相关文档。例如,在智能聊天机器人应用中,如果员工询问他们的年假,系统将检索政策文档和过去的休假记录来回答问题。
增强 LLM 提示
检索到的数据被添加到用户输入中,从而创建增强提示。此增强提示包括原始查询和相关的检索信息,然后被输入到 LLM 中,以生成既知情又符合上下文的响应。
更新外部数据
文档及其嵌入内容通过自动实时流程或定期批处理定期更新。此持续更新过程对于保持 RAG 系统检索到的信息的准确性和相关性非常重要。
提示、微调和 RAG 之间的区别
有几种方法可以充分利用语言模型。三种常见技术是提示、微调和 RAG。每种方法的工作原理不同,各有优势。
提示工程Prompt Engineering
提示工程涉及设计特定的输入或提示来指导模型的响应。这种方法方便用户且经济高效,但受到模型预训练知识的限制。它最适合一般主题和快速答案。
微调Fine-Tuning
微调使用额外数据调整模型参数,以提高知识密集型任务的性能。这种方法提供了高度的定制化,但资源密集,需要大量的计算能力和专业知识。
RAG
RAG 结合了检索和生成的优势,使用外部知识库来指导模型的响应。它平衡了提示的简易性和微调的定制性,使其适合需要动态和上下文丰富的输出的应用程序。
RAG 允许整合最新和最相关的信息,而无需进行大量的再培训。
Denser Retriever项目
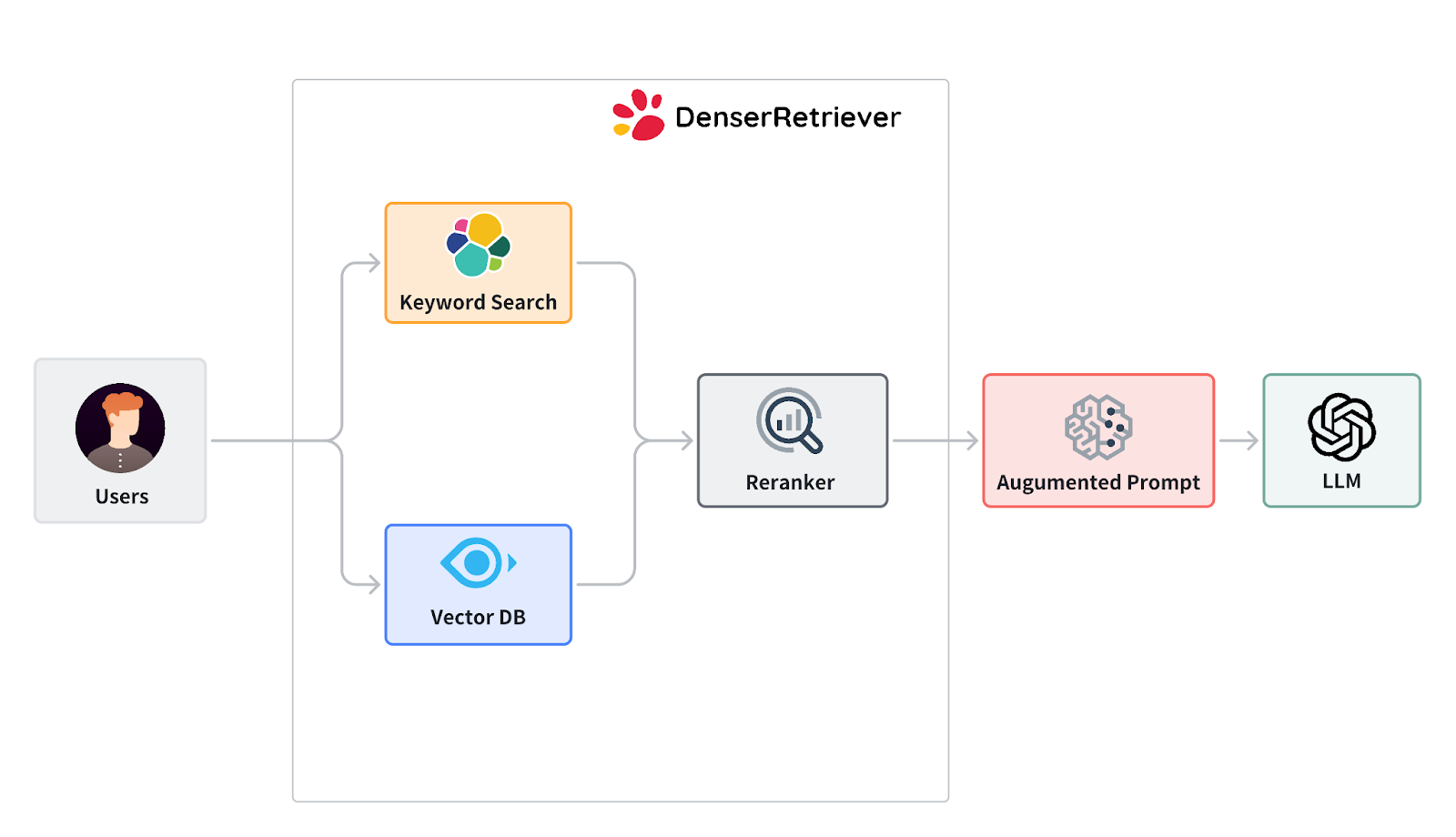
Denser Retriever 项目是 RAG 强大功能的典型示例。这项开源计划将多种搜索技术整合到一个平台中,使用梯度增强 (xgboost) 机器学习技术来集成基于关键字的搜索、矢量数据库和机器学习排名器。
其结果是一个高度精确的搜索系统,其性能明显优于传统的矢量搜索基线。
在广泛使用的 MSMARCO 基准数据集上,Denser Retriever 与最佳向量搜索基线相比,实现了 13.07% 的相对 NDCG@10 增益,证明了其卓越的性能和有效性。这一显著的改进展示了 RAG 在提高搜索和检索系统的准确性和相关性方面的潜力。
要了解更多信息并为 Denser Retriever 项目做出贡献,请浏览以下资源:
GitHub 存储库:https://github.com/denser-org/denser-retriever/tree/main
博客:https://denser.ai/blog/denser-retriever/
文档:https://retriever.denser.ai/
有采用 RAG 并支持 Denser Retriever 等得项目可以显著提升组织的能力及其 AI 系统的可靠性。这可确保它们能够为用户查询提供准确、最新且上下文丰富的响应。
关于检索增强生成 (RAG) 的常见问题解答
自然语言处理如何参与 RAG?
自然语言处理是 RAG 的核心组件。IR 和 NLG 组件均使用 NLP 技术来理解和生成类似人类的文本。在 IR 组件中,NLP 有助于执行语义搜索。同时,在 NLG 组件中,NLP 能够生成连贯且与上下文相关的响应。
语义搜索在 RAG 中扮演什么角色?
语义搜索在 RAG 中发挥着至关重要的作用,它使检索组件能够理解查询的上下文和含义。这使系统能够获取与用户意图更相关的数据,而不仅仅是匹配关键字。
RAG 和生成式 AI 有什么区别?
生成式人工智能通常是指基于预先存在的数据生成内容而无需检索其他信息的人工智能模型。
另一方面,RAG 将生成式 AI 与信息检索相结合,使其能够生成由来自外部来源的实时数据提供的信息内容,从而获得更准确、更相关的响应。
关于作者
黄志恒是加州Denser.ai的联合创始人,是科技界的杰出人物,截至 2024 年 2 月,他发表了 60 多篇顶级会议论文,并在 Google Scholar 上被引用了 13,000 多次。他最引人注目的贡献是开创性的“用于序列标记的双向 LSTM-CRF 模型”论文。
志恒曾担任 AWS 首席科学家,领导 Amazon Kendra 和 Amazon Business Q 项目,现在他将自己对深度学习和 NLP 的热情投入到 Denser,旨在通过自己丰富的专业知识推动创新和生产力。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号