从零开始学机器学习——分类器详解
原创

首先给大家介绍一个很好用的学习地址:https://cloudstudio.net/columns
今天我们将结合第一章节中清洗得到的菜品数据,利用多种分类器对这些数据进行训练,以构建有效的模型。在这个过程中,我会详细讲解每一种分类器的原理及其重要性。
尽管这些知识点对于实践来说并不是必须掌握的,因为第三方依赖包已经为我们完成了大量的封装,使得调用这些功能仅需一行代码,但理解其背后的原理仍然至关重要。这将有助于我们在实际应用中更好地把握模型的表现和改进的方向。
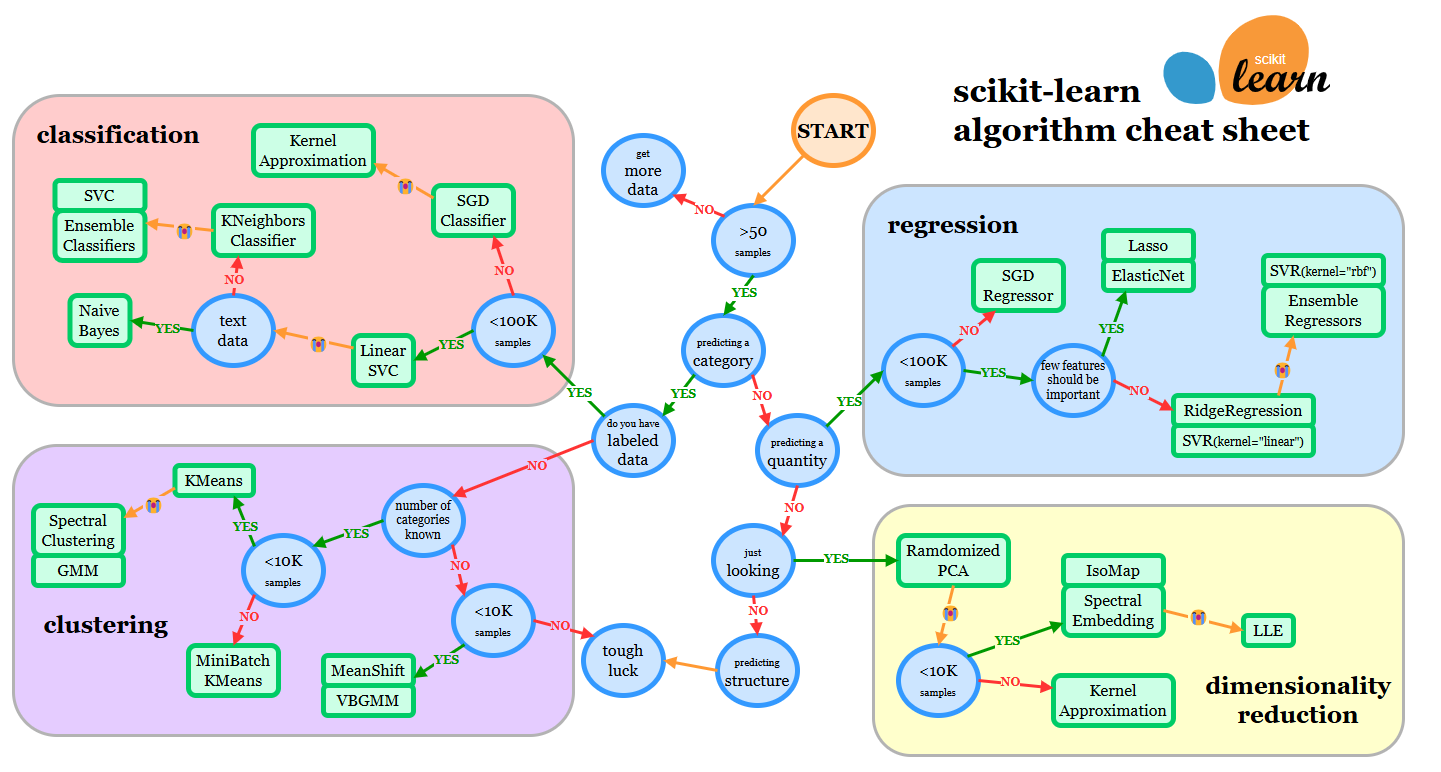
分类路线图
在上一章节中,我们已经查看了微软的小抄表,并对其进行了中文翻译,希望这些内容对你有所帮助。今天,我们将继续探索Scikit-learn提供的一个类似的速查表,但它的细粒度和信息量更加丰富。这份速查表不仅能帮助您快速查找相关信息,还能为您在调整估计器(分类器的另一个术语)时提供实用的指导。
速查表原文地址:https://scikit-learn.org/stable/machine_learning_map.html
image
表情😭符号应理解为“如果此估计器没有达到预期结果,则按照箭头尝试下一个”
然后,我们根据此路线图选择我们的分类器:
- 我们有超过 50 个样本
- 我们想要预测一个类别
- 我们有标记过的数据
- 我们的样本数少于 100000
- ✨ 我们可以选择线性 SVC
- 如果那不起作用,既然我们有数值数据,没有文本数据
- 我们可以尝试 ✨ K-近邻分类器
- 如果那不起作用,试试 ✨ SVC 和 ✨ 集成分类器
- 我们可以尝试 ✨ K-近邻分类器
模型构建
接下来第一步则是将数据分为训练集、测试集。
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve
import numpy as np
cuisines_df = pd.read_csv("../data/cleaned_cuisines.csv")
cuisines_label_df = cuisines_df['cuisine']
cuisines_feature_df = cuisines_df.drop(['Unnamed: 0', 'cuisine'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)线性 SVC 分类器
根据我们的学习路线图,第一步我们需要尝试线性SVC分类器。在深入讲解SVC之前,我们有必要先了解一下支持向量机(SVM)。这是因为在你搜索SVC时,通常会找到大量关于SVM的资料,所以理解这两者之间的区别是十分重要的。
接下来,我们将探讨这两者的不同之处,以及它们各自的特点和应用场景,以便为后续的学习奠定更扎实的基础。
支持向量机(SVM)
支持向量机是一种强大的监督学习算法,用于分类和回归问题。SVM是一个广泛的概念,涵盖了分类和回归问题;而SVC是SVM的特定应用,专门用于分类任务。在机器学习库中,SVC通常是实现SVM的分类器的名称,比如在Scikit-learn库中。
支持向量机(SVM)有几个子类,主要包括:支持向量分类(SVC)、支持向量回归(SVR)、一类支持向量机(One-Class SVM)、 多类支持向量机(Multi-Class SVM)、概率支持向量机(Probabilistic SVM)。这些子类允许支持向量机在不同类型的任务中表现出色。每个子类都有其独特的实现和优化方式,以适应特定的应用场景。
举个例子
如果理解线性 SVC 有些困难,我们来举一个例子:
想象你在一个学校,有两个班级:数学班和艺术班。每个学生都有不同的特点,比如他们的数学成绩和艺术成绩。你想根据这两个成绩把学生分到这两个班级。
- 数据点:
- 每个学生可以用一个点在图上表示:X1轴代表数学成绩,X2轴代表艺术成绩。
- 数学班的学生通常数学成绩高,艺术成绩相对低。
- 艺术班的学生通常艺术成绩高,数学成绩相对低。
- 分类目标: 你希望找到一条线(就像一个“分界线”)来把两个班级的学生分开。
- 最大间隔: SVC会寻找一条最好的分界线,使得这条线和最近的学生(支持向量)之间的距离最大。这样,即使有一些新的学生在数学和艺术成绩上介于两者之间,这条线依然能够较好地分类他们。
- 处理复杂情况: 假设有一个学生的数学和艺术成绩都很中等。用一条线可能很难将这个学生明确地分到一个班级。SVC可以通过“增加维度”,想象一下你有一个第三个维度,比如“运动成绩”。在这个三维空间中,SVC可以找到一个更复杂的分界面,来更好地分开这两个班级的学生。
通过这个比喻,SVC的核心就是:
- 它找出一种最佳的方法来区分不同的群体(如班级)。
- 通过最大化与最近的学生(支持向量)之间的距离,确保分类更加稳健。
- 在面对复杂情况时,可以使用其他特征(如运动成绩)来帮助更准确地分类。
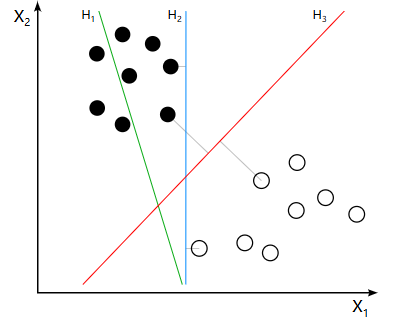
为此我找了一张图片说明一下,更容易让你理解。H3则是最佳分界线。
image
让我们直接来看一下代码。尽管实现了如此复杂的功能,代码的结构却相对简单明了。
C = 10
# 创建不同的分类器
classifiers = {
'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0)
}
n_classifiers = len(classifiers)
for index, (name, classifier) in enumerate(classifiers.items()):
classifier.fit(X_train, np.ravel(y_train))
y_pred = classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100))
print(classification_report(y_test,y_pred))运行结果如下,从表面上看,性能表现相当不错,准确率至少接近80%。
Accuracy (train) for Linear SVC: 78.7%
precision recall f1-score support
chinese 0.69 0.80 0.74 242
indian 0.89 0.84 0.87 239
japanese 0.73 0.71 0.72 223
korean 0.90 0.75 0.82 250
thai 0.76 0.83 0.79 245
accuracy 0.79 1199
macro avg 0.79 0.79 0.79 1199
weighted avg 0.80 0.79 0.79 1199K-近邻分类器
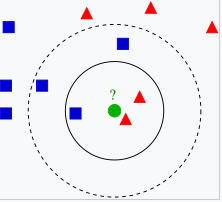
K-近邻分类器(K-Nearest Neighbors, KNN)是一种简单且直观的监督学习算法,主要用于分类和回归任务。它的基本思想是通过计算数据点之间的距离,将待分类的数据点归类到其最近的 K 个邻居的类别中。
举个例子
在社交网络中,我们常常能看到某些用户与特定兴趣群体的联系。比如,假设我们想要判断一个新用户的兴趣所在,我们可以观察他周围的朋友。
当我们分析这个新用户的社交网络时,可以查看与他最亲近的 K 个朋友。这些朋友的共同兴趣和活动可以为我们提供线索。如果这 K 个朋友大多数都喜欢摄影,那么我们可以推测,这位新用户很可能也对摄影感兴趣。
通过这种方式,我们利用社交网络中朋友的影响,判断一个用户的兴趣和爱好,从而更好地为他推荐内容和连接。
也就是说,根据近邻样本推测当前数据点属于哪一类。
image
classifiers = {
'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0),
'KNN classifier': KNeighborsClassifier(C),
}其他代码无需修改,我们只需在分类对象中添加一个 KNN 分类器即可。接下来,我们将继续观察运行结果。值得注意的是,这一调整并未产生显著的效果,KNN 分类器的引入似乎对模型的整体性能没有带来太大的提升。
Accuracy (train) for KNN classifier: 74.1%
precision recall f1-score support
chinese 0.70 0.76 0.73 242
indian 0.88 0.78 0.83 239
japanese 0.64 0.82 0.72 223
korean 0.94 0.54 0.68 250
thai 0.68 0.82 0.74 245
accuracy 0.74 1199
macro avg 0.77 0.74 0.74 1199
weighted avg 0.77 0.74 0.74 1199Support Vector 分类器(SVC)
支持向量分类(SVC)和线性支持向量分类(Linear SVC)都是支持向量机(SVM)的一种实现,但它们在一些关键方面存在区别:
- 核函数
- SVC:可以使用多种核函数(如线性核、多项式核、径向基函数核等),适用于线性可分和非线性可分的数据集。
- Linear SVC:只使用线性核,专注于处理线性可分的数据。它在优化过程中不进行核变换。
- 适用性
- SVC:适合处理更复杂的数据集,能够捕捉到非线性决策边界。
- Linear SVC:适合高维特征空间的数据,尤其是特征维数大于样本数时(例如文本分类任务)。
如果你知道数据是线性可分的或者特征维数非常高,使用 Linear SVC 可能更高效。如果数据存在非线性关系,选择 SVC 并使用适当的核函数更合适。
classifiers = {
'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0),
'KNN classifier': KNeighborsClassifier(C),
'SVC': SVC(),
}我们将继续观察SVC的运行结果,似乎表现得更为理想。
Accuracy (train) for SVC: 81.7%
precision recall f1-score support
chinese 0.73 0.82 0.77 242
indian 0.89 0.90 0.89 239
japanese 0.81 0.73 0.76 223
korean 0.90 0.77 0.83 250
thai 0.79 0.86 0.82 245
accuracy 0.82 1199
macro avg 0.82 0.82 0.82 1199
weighted avg 0.82 0.82 0.82 1199集成分类器
尽管之前的测试结果已经相当令人满意,但为了确保我们能够全面评估模型的性能,我们决定沿着既定路线走到最后。因此,我们将尝试一些集成分类器,特别是随机森林和AdaBoost。
随机森林
随机森林就是用很多棵决策树来做判断,通过随机选择样本和特征来确保多样性,最后结合这些树的结果来提高整体的准确性和稳定性。这样的方法让模型更可靠,也更能适应复杂的数据。
想象一下,你想要决定今天的午餐吃什么,但你有很多朋友,每个朋友都有不同的口味。你可以做以下几件事:
- 请教多个朋友:你询问每个朋友的建议,而不是只听一个人的意见。这样,你能得到多种不同的选择。
- 随机选择朋友:你不是每次都问所有朋友,而是随机挑选几个朋友来听听他们的意见。这样可以避免受到个别朋友强烈偏好的影响。
- 记住他们的意见:你把每个朋友的建议记下来,比如有几个朋友推荐了意大利面,有几个推荐了寿司。
- 最终决定:最后,你根据朋友们的推荐,选择那个被最多人推荐的餐点。
关键知识点
- 多样性:随机森林就是这样一个想法,它通过“请教”很多个决策树(这些树就像你不同的朋友),每棵树都是在不同的数据和特征上训练出来的。
- 减少错误:通过多个“朋友”的建议,最终的选择(预测)往往更准确,不容易受到单个决策的错误影响。
- 投票机制:所有的决策树给出的预测结果汇总后,就像你的朋友们投票一样,最终选择那个“得票最多”的结果。
AdaBoost
AdaBoost 的核心思想是通过不断学习和调整,结合多个弱分类器的力量,来提高整体的预测能力。每次迭代都关注之前的错误,从而使模型逐步改进。
想象一下,你在学校里参加一个辩论比赛,但你是个初学者,可能不太擅长辩论。你决定请教一些同学,他们的辩论水平不同,有的很厉害,有的刚刚开始。
- 请教不同同学:你找来了几位同学来帮你,他们各自有不同的观点和方法。每个同学都有可能在某个方面比你更擅长。
- 学习和调整:第一次练习时,可能有一些论点你说得不够好,这些同学会给你反馈,告诉你哪些地方可以改进。你会记住这些错误,并在下次练习时更加注意。
- 重视反馈:对于那些你之前说错的论点,给这些错误的部分“加重”。这意味着在接下来的练习中,你会特别关注这些问题,确保你能做到更好。
- 综合意见:每次练习结束后,你会把所有同学的建议结合起来。虽然每个同学的能力不同,但通过不断调整和综合意见,最终你会变得更强。
关键知识点
- 逐步改进:AdaBoost 就是这样一个过程。它通过多个“弱分类器”(就像你不同的同学),每个分类器可能都不是特别强,但通过不断的调整和学习,它们一起能够构成一个更强的“强分类器”。
- 重视错误:AdaBoost 特别关注那些之前预测错误的样本,通过增加它们的权重,来让后续的分类器更加关注这些难分类的样本。
- 加权组合:最后,所有的分类器的结果会结合在一起,就像你综合了所有同学的意见一样,通过投票或加权来决定最终的预测结果。
区别与联系
随机森林:每棵树都是相对独立的,组合后形成的模型通常更稳健,尤其在数据集比较复杂时,随机森林的每棵树之间的相关性较低,有助于减少方差,通常在特征数量很大或数据集复杂时表现良好,适用于分类和回归任务。
AdaBoost:分类器是串行的,每个新分类器都依赖于前一个分类器的结果,建立在前一个模型的基础上,AdaBoost 更容易受到噪声数据的影响,因为它会对错误分类的样本给予更高的关注。更适合处理一些简单的、需要更高准确性的任务,尤其在面对数据噪声较少的情况下。
随机森林更注重多样性和独立性,而 AdaBoost 则通过聚焦于难点来提升整体性能。
接下来,对于我们实现的代码来说就是两行代码:
# 创建不同的分类器
classifiers = {
'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0),
'KNN classifier': KNeighborsClassifier(C),
'SVC': SVC(),
'RFST': RandomForestClassifier(n_estimators=100),
'ADA': AdaBoostClassifier(n_estimators=100)
}n_estimators在随机森林中表示将生成 100 棵决策树。每棵树都是通过随机选择样本和特征来训练的。通过增加树的数量,模型的表现通常会更稳定,且更不容易过拟合。
n_estimators在AdaBoost 这表示将创建 100 个弱分类器(通常是简单的决策树)。每个分类器都会基于前一个分类器的表现进行训练,关注那些之前分类错误的样本。增加分类器的数量通常能提高模型的表现,但也可能增加过拟合的风险。
运行结果如下:
Accuracy (train) for RFST: 83.4%
precision recall f1-score support
chinese 0.78 0.80 0.79 242
indian 0.89 0.91 0.90 239
japanese 0.81 0.78 0.80 223
korean 0.89 0.81 0.85 250
thai 0.80 0.87 0.83 245
accuracy 0.83 1199
macro avg 0.83 0.83 0.83 1199
weighted avg 0.84 0.83 0.83 1199
Accuracy (train) for ADA: 69.5%
precision recall f1-score support
chinese 0.66 0.48 0.56 242
indian 0.88 0.79 0.84 239
japanese 0.66 0.64 0.65 223
korean 0.67 0.73 0.70 250
thai 0.64 0.82 0.72 245
accuracy 0.69 1199
macro avg 0.70 0.69 0.69 1199
weighted avg 0.70 0.69 0.69 1199到此为止,我们已经对整个路线图中能够应用的所有分类器进行了全面的研究。虽然在代码实现上,这可能仅仅涉及一行代码或几个参数的调整,但在背后,我们仍需对这些模型的基本逻辑和原理有一个大致的理解。
总结
在这个学习旅程中,我们不仅深入探讨了各类分类器的原理和应用,还通过实践加深了对模型构建过程的理解。通过使用不同的算法,如线性SVC、K-近邻分类器、支持向量分类器及集成方法如随机森林和AdaBoost,我们看到了数据处理和模型训练的多样性。在每一步的探索中,我们不仅关注了准确率,还思考了每种算法的适用场景及其优势。虽然使用机器学习库简化了实现的复杂性,但背后每个模型的逻辑与机制依然是值得我们深入了解的重要内容。
此外,我们学习到,模型的性能不仅依赖于选择的算法,还与数据的特性、预处理的质量和参数的调优紧密相关。面对不同的数据集,灵活地选择适合的分类器和调整其参数,是提升模型效果的关键。通过使用Scikit-learn的速查表,我们能够快速定位到合适的算法,为实际应用提供了有效的指导。
当然,最后我也想鼓励大家去看看这个学习平台,它非常适合新手,提供了丰富的资源和易于理解的教程。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号