A800_1.6T RDMA实例测试指导文档
原创
A800_1.6T RDMA实例测试指导文档
原创
Yellowsun
修改于 2024-10-22 21:02:58
修改于 2024-10-22 21:02:58
版本 | 改动 |
|---|---|
V7 - 2024/3/4 | 升级GPU驱动(535.129.03),容器镜像(NGC 23.11) |
V8 - 2024/3/4 | 更正OS镜像信息,更新容器镜像(基于NGC 24.01) |
V9 - 2024/7/26 | 更新容器镜像(基于NGC 24.03) |
一、 购机选择正确的共享镜像
从"共享镜像"标签中选择“A800_535_TL24_CVM_RELEASE img-haurw7f3”。
该OS镜像预装了如下软件:
- 操作系统:Tencent Linux 2.4 (与CentOS 7.9同源, 使用yum安装所需的包)
- 内核:5.4.119-19-0009.11 (优化内核)
- RDMA网卡驱动:MLNX_OFED_LINUX-5.4-3.1.0.0-LTS
- GPU驱动: 535.129.03 (包括GDR所需要的驱动:nvidia_peermem)
- docker 20.10.21 + nvidia-docker2 2.13.0-1
备注:如果不使用此OS镜像,镜像内需要增加一些补丁才能正常使用
- GPU驱动、RDMA驱动、nvidia_peermem
- Linux内核增加ARP双发特性,支持RDMA的双发(提供内核patch)
- RDMA bond网络的反向路由检查
- bond配置脚本,rdma网卡名不建议ethX格式,会和弹性网卡顺序乱。
二、 系统检查
1、 检查网卡设备
命令:
ibdev2netdev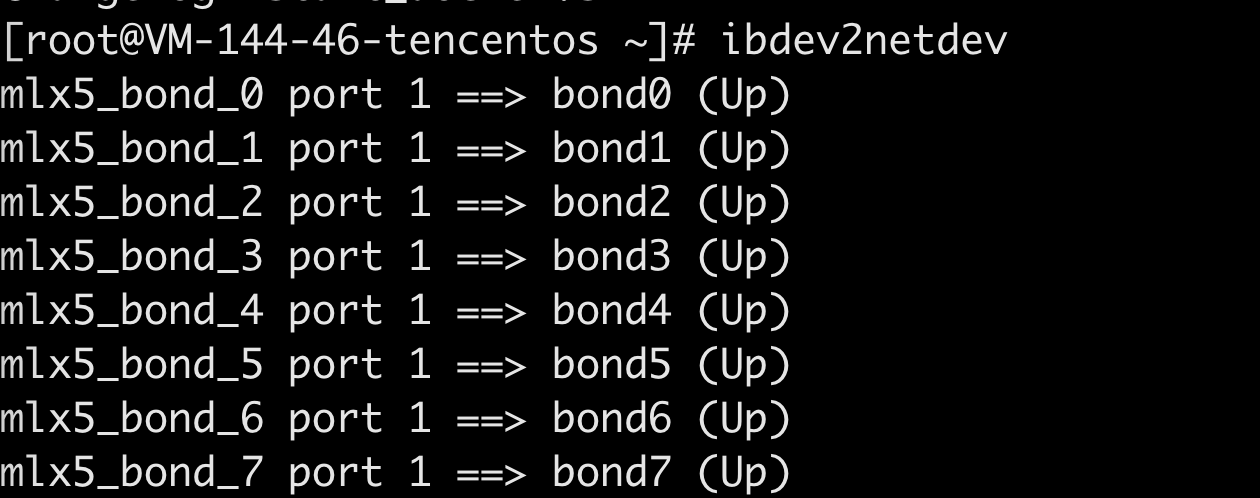
2、 检查GPU驱动和nvlink状态
命令:
nvidia-smi nvlink -s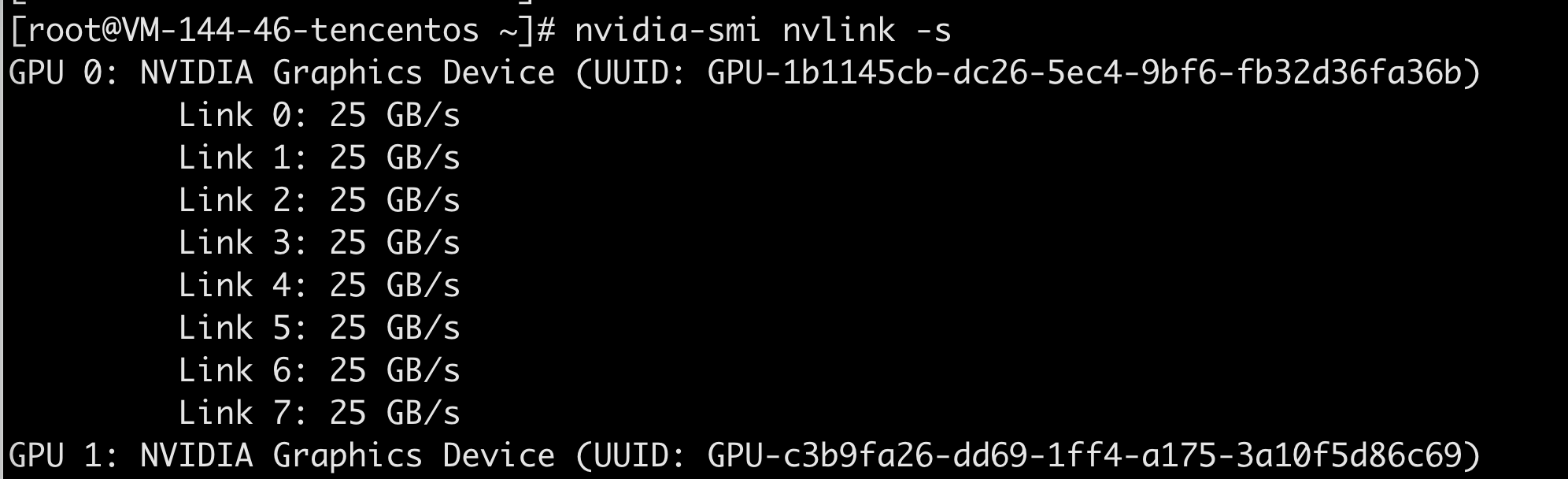
如果出现inactive,执行如下命令,重启fabric manager:
systemctl enable nvidia-fabricmanager.service && systemctl restart nvidia-fabricmanager.service3、 检查GDR驱动是否已经加载
命令:
lsmod | grep nvidia_peermem
如果没有加载,执行如下命令:
modprobe nvidia-peermem && echo "nvidia-peermem" >> /etc/modules-load.d/nvpeermem.conf4、 启动docker测试镜像
// 下载并启动测试镜像
docker run \
-itd \
--gpus all \
--privileged --cap-add=IPC_LOCK \
--ulimit memlock=-1 --ulimit stack=67108864 \
-v /root:/mnt \
--net=host \
--ipc=host \
--name=ai haihub.cn/tencent/taco-train/cuda12.4-ofed5.4-nccl2.20.5-torch2.3-2.5:latest
// 进入容器当中
docker exec -it ai bash● 注意:docker的启动参数里面必须包含:"--privileged", "--net=host"
该测试docker包含的软件版本如下:
base: nvcr.io/nvidia/pytorch:24.03-py3
OS:Ubuntu 22.04.3
CUDA:V12.4.99
python:3.10.12
torch:2.3.0a0+40ec155e58.nv24.3
deepspeed: 0.13.4
transformer-engine: 1.4.0+0fbc76a
flash-attn: 2.4.2
accelerate: 0.27.2
mmcv:2.1.0
mmengine:0.10.3
mmdet:3.3.0三、 性能测试
1. RDMA 性能测试
测试两机之间极限带宽和延时:带宽测试两机bond之间互打perftest write流量,延时测试同LA及跨LA情况下bond之间send延时。
带宽测试server:
taskset -c 20,21 ib_write_bw -d mlx5_bond_0 -x 3 -F --report_gbits -p 18500 -D 2 -q 10 --run_infinitely
taskset -c 24,25 ib_write_bw -d mlx5_bond_2 -x 3 -F --report_gbits -p 18502 -D 2 -q 10 --run_infinitely
taskset -c 80,81 ib_write_bw -d mlx5_bond_4 -x 3 -F --report_gbits -p 18504 -D 2 -q 10 --run_infinitely
taskset -c 84,85 ib_write_bw -d mlx5_bond_6 -x 3 -F --report_gbits -p 18506 -D 2 -q 10 --run_infinitely带宽测试client:
taskset -c 20,21 ib_write_bw -d mlx5_bond_0 -x 3 -F --report_gbits -p 18500 -D 2 -q 10 --run_infinitely 30.7.64.146
taskset -c 24,25 ib_write_bw -d mlx5_bond_2 -x 3 -F --report_gbits -p 18502 -D 2 -q 10 --run_infinitely 30.7.64.134
taskset -c 80,81 ib_write_bw -d mlx5_bond_4 -x 3 -F --report_gbits -p 18504 -D 2 -q 10 --run_infinitely 30.7.64.194
taskset -c 84,85 ib_write_bw -d mlx5_bond_6 -x 3 -F --report_gbits -p 18506 -D 2 -q 10 --run_infinitely 30.7.64.182● 其中client侧需要指定server端IP, taskset绑核需要与网卡numa node一致, 并且由于pcie switch限制,网卡需要错开pcie switch验证, 例如bond0/2/4/6同时测,bond1/3/5/7同时测(pcie switch分布可以通过lspci -tv命令查询)
● 由于单个QP只能使用一个端口,所以需要配置多个QP端口将bond带宽打满
延时测试server:
ib_send_lat -d mlx5_bond_0 -a -F延时测试client:
ib_send_lat -d mlx5_bond_0 -a -F 30.7.64.146● 其中client侧需要指定server端IP
2. 集合通信性能
2.1 添加训练节点IP(只在master节点修改)
修改/workspace/run_nccl_tests.sh变量<ip_list>,添加所有训练节点的IP地址(ifconfig eth0)
2.2 启动测试(只在master节点执行)
// 运行4机32卡1G数据包的AllReduce
bash run_nccl_test.sh 0 1G 32
// 运行4机32卡128M数据包的AllToAll
bash run_nccl_test.sh 1 128M 323. AI模型性能
3.1 llama2预训练
cd /workspace/Megatron-LM
// 下载数据集
bash download_dataset.sh
// 启动训练
bash start_llama2.sh3.2 baichuan2微调
cd /workspace/Baichuan2/fine-tune
// 下载数据集
bash download_model.sh
// 启动微调
bash start.sh
// 验证模型效果(需要适配checkpoints路径)
python infer.py3.3 chatGLM3微调
cd /workspace/ChatGLM3/finetune_demo
// 下载数据集和模型
bash download_dataset_model.sh
// 启动全量微调
bash start_ft.sh
// 验证模型效果(需要适配checkpoints路径)
python infer.py3.4 stablediffusion 2.1 微调
cd /workspace/diffusers
// 下载数据集和模型
bash download_model_dataset.sh
// 启动微调
bash start.sh3.5 VIT训练
cd /workspace/classification
// 启动训练
// 可以修改训练参数,跑不同的vision model和配置参数
bash start.sh四、 性能结果
1. 测试环境信息
机型 | HCCPNV4sne |
|---|---|
CPU | Intel IceLake*2 (124c 2.7GHz/3.3GHz) |
GPU | 8 * A800 NVSwitch 80G |
网卡 | CX6 100G * 2 * 8 |
存储 | NVMeSSD-6.4T*4 |
2. RDMA
带宽write:

延时同LA:
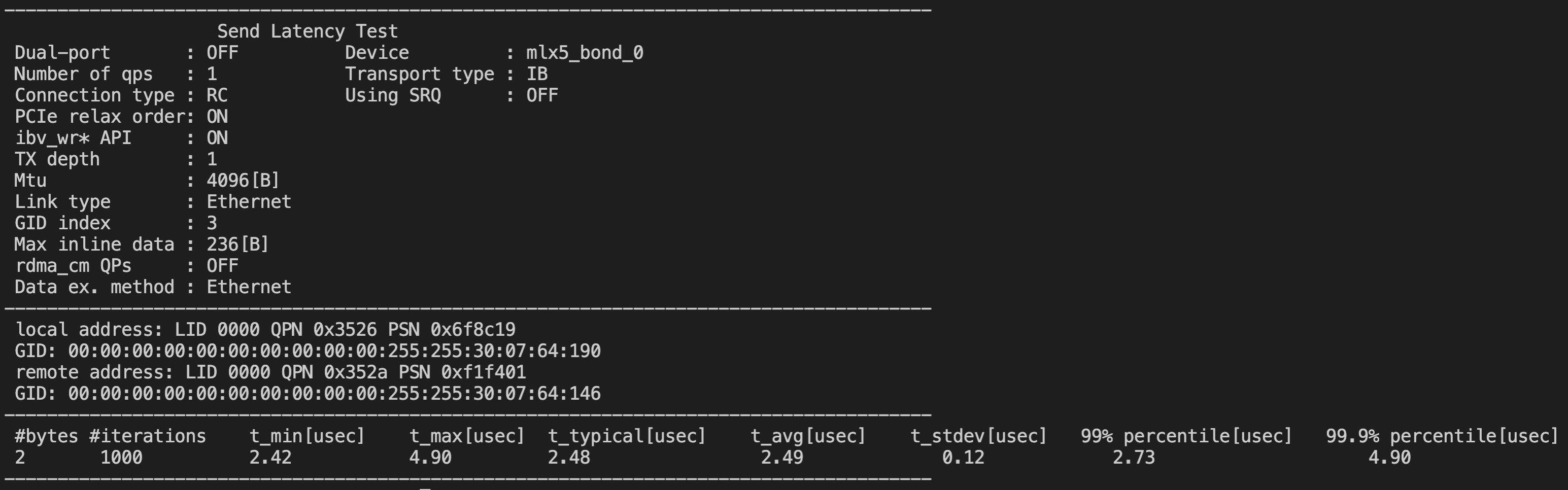
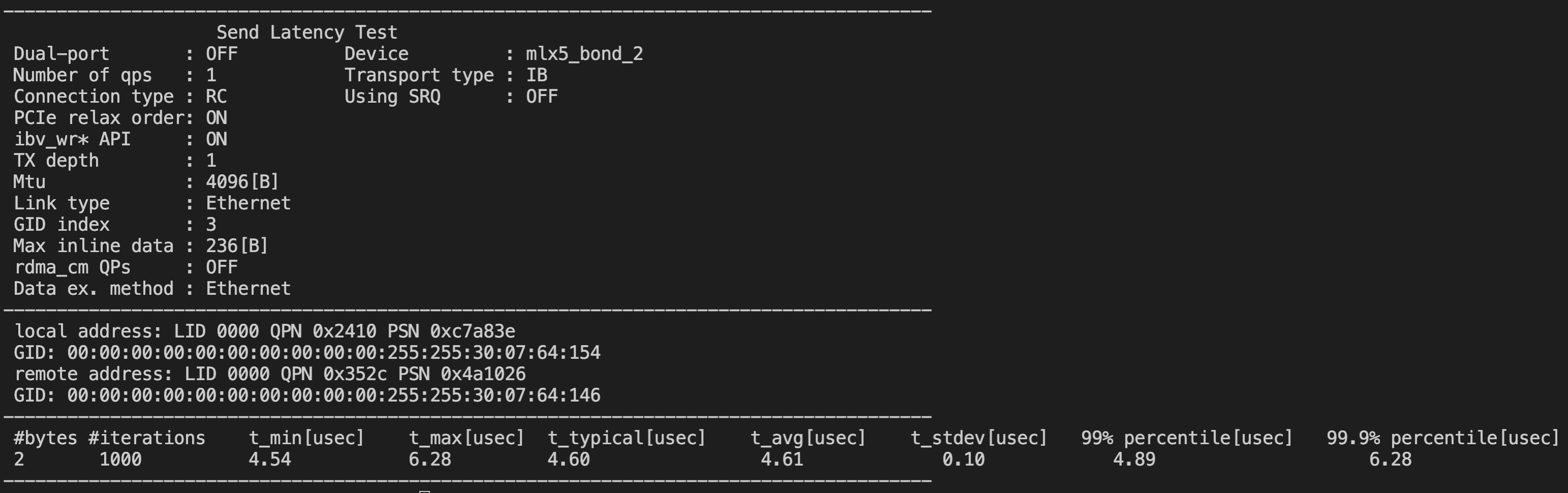
延时跨LA:
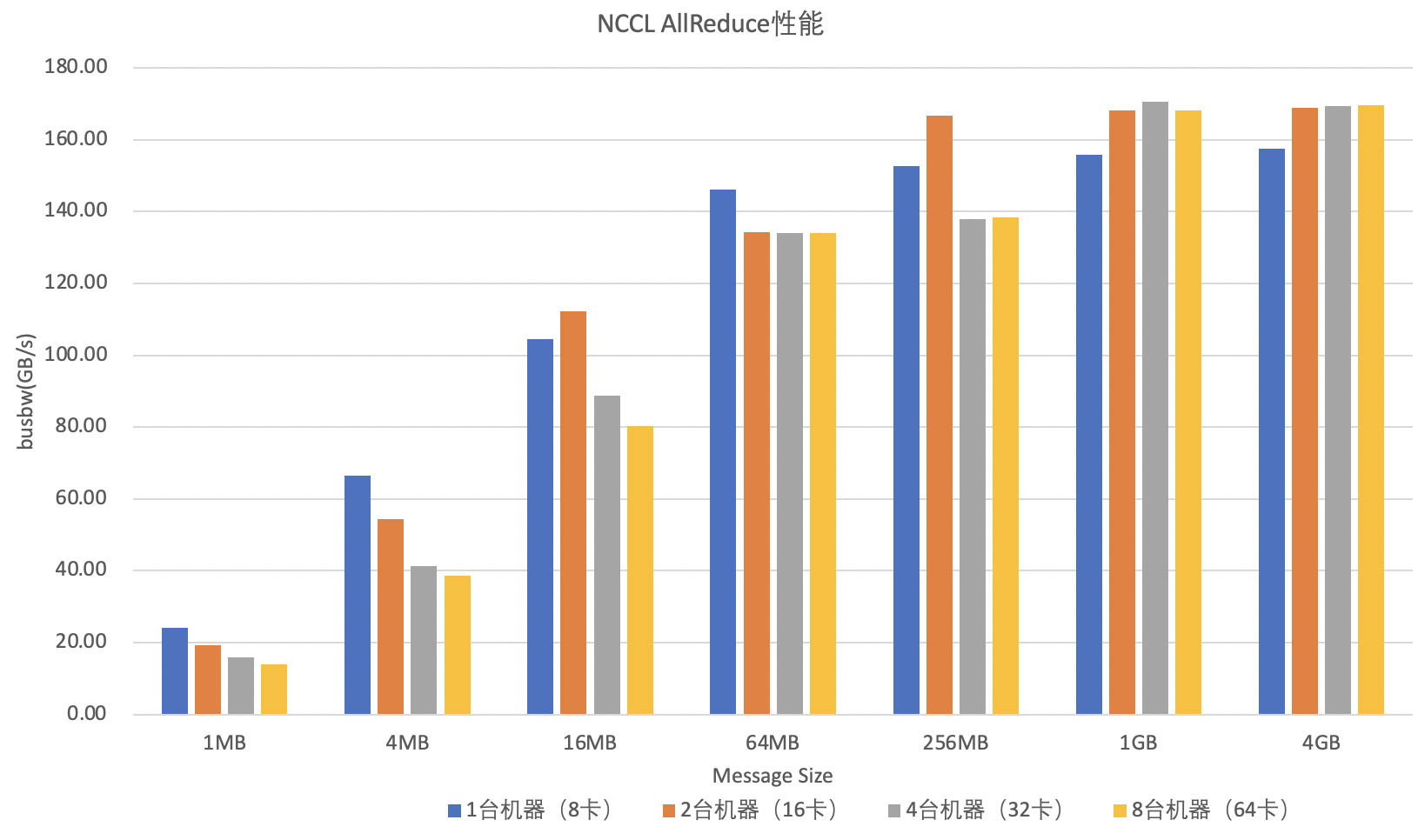
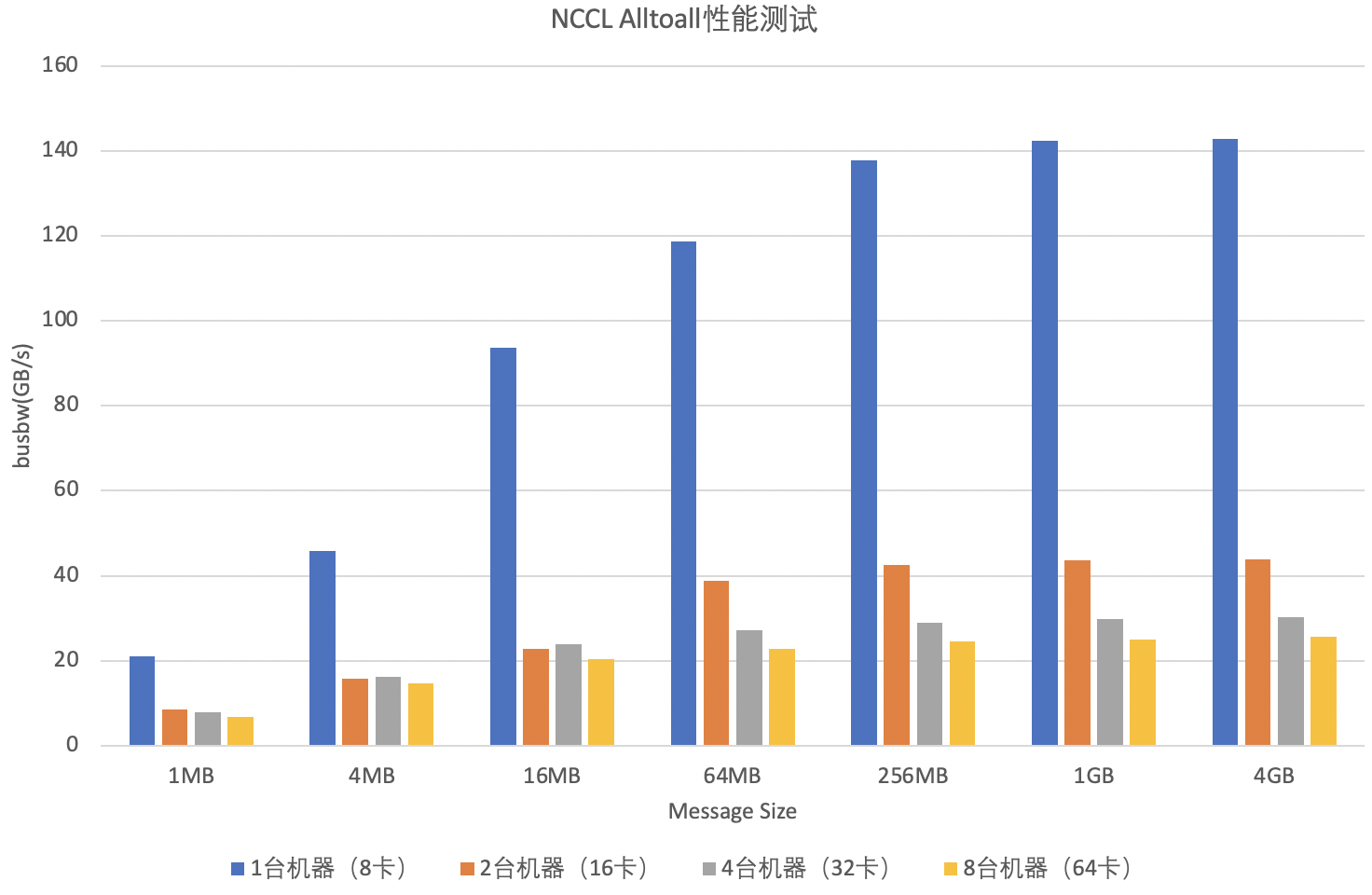
3. nccl-tests
AllReduce测试:
AlltoAll测试:
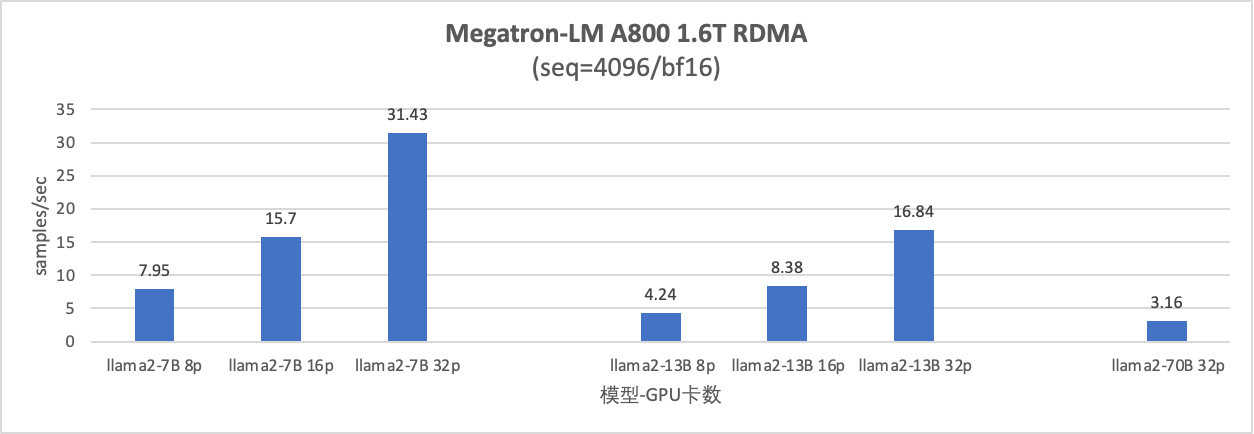
4. AI模型性能
五、 自定义容器镜像安装指引
1. 用户态RDMA驱动
如果使用自定义的业务镜像,请在镜像当中安装正确的用户态RDMA驱动:
// Ubuntu 22.04
RUN wget https://taco-1251783334.cos.ap-shanghai.myqcloud.com/ofed/MLNX_OFED_LINUX-5.4-3.6.8.1-ubuntu22.04-x86_64.tgz && \
tar xf MLNX_OFED_LINUX-5.4-3.6.8.1-ubuntu22.04-x86_64.tgz && \
cd MLNX_OFED_LINUX-5.4-3.6.8.1-ubuntu22.04-x86_64 && \
./mlnxofedinstall --user-space-only --without-fw-update --force && cd ../ && rm MLNX_OFED_LINUX* -rf2. NCCL插件安装和环境变量
2.1 安装高性能NCCL插件
// Ubuntu 22.04
RUN sed -i '/nccl_rdma_sharp_plugin/d' /etc/ld.so.conf.d/hpcx.conf
RUN wget -q --show-progress "https://taco-1251783334.cos.ap-shanghai.myqcloud.com/nccl/plugin/ubuntu22.04/nccl-rdma-sharp-plugins_1.4_amd64.deb" && \
dpkg -i nccl-rdma-sharp-plugins_1.4_amd64.deb && rm -f nccl-rdma-sharp-plugins_1.4_amd64.deb2.2 配置NCCL环境变量
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=eth0
export NCCL_IB_GID_INDEX=3
export NCCL_IB_DISABLE=0
export NCCL_NET_GDR_LEVEL=2
export NCCL_IB_QPS_PER_CONNECTION=4
export NCCL_IB_TC=160
export NCCL_IB_TIMEOUT=22
export NCCL_PXN_DISABLE=03. 集群环境一致性检查
通过执行如下脚本检查集群的软件版本配置是否一致
wget https://taco-1251783334.cos.ap-shanghai.myqcloud.com/perftest/cluster_check.py
# host.txt包含所有节点的IPs,一行一个
python cluster_check.py -f host.txt原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号