Python如何处理excel中的空值和异常值
原创

前言
对于普通人来说,觉得编程和自己日常的工作风马牛不相及。其实我还是建议学一下python,因为很多人的工作都是离不开与word和excel这些软件打交道。有时很多文档的处理都是重复性的规律性工作,而使用编程来完成这些工作最适合不过。
前两年与文档打交道特别多,会遇到一些例如写cosmic、excel中提取文本生成word等工作。于是我就打算开发一些小工具,在对比了Java和python的开发和使用简易性之后,我义无反顾选择了python。
python对于操作word、excle提供功能强大的库,除了开发起来比java简单,而且python更容易将程序打包成桌面应用,通过点击图标就可以使用这些工具。
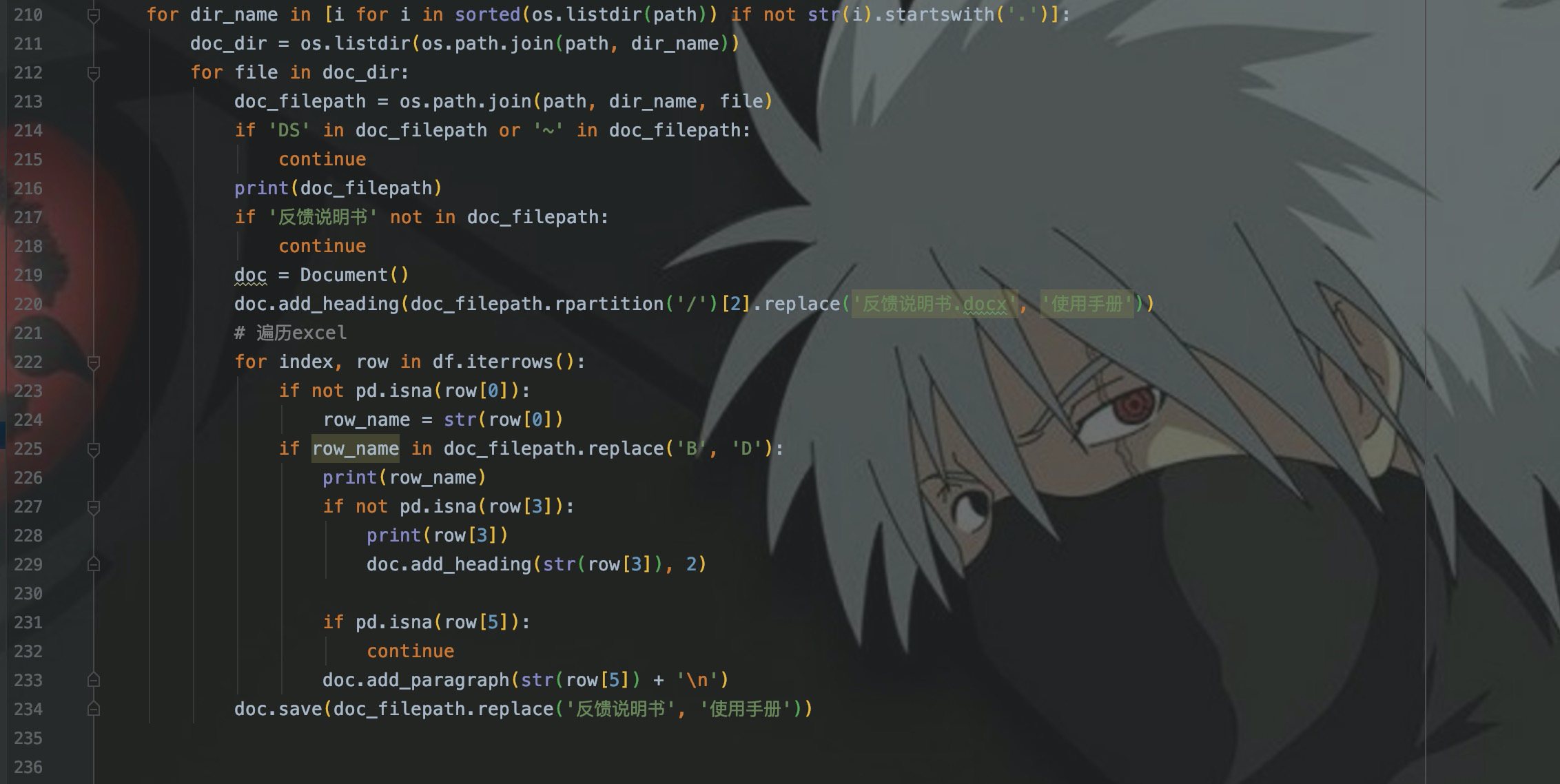
所以,今天就用python来做一个简答的excle数据处理:处理空值和异常值。
pandas
在python中,读写excle的库有很多,通常我都是使用pandas来读写excle并处理其中的数据。现在的excel通常都是xlsx格式,对于老版本的xls格式,可以使用 xlrd 和 xlwt。xlrd 来读写。
读取 Excel 数据
首先,通过 pandas 读取 Excel 文件:
import pandas as pd
# 读取 Excel 文件
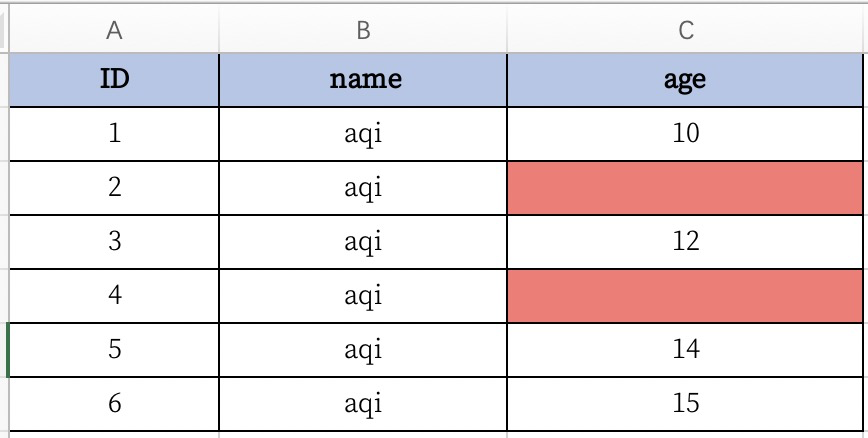
df = pd.read_excel('data.xlsx')这样,pandas读取excel中的数据,并结构化成DataFrame格式。
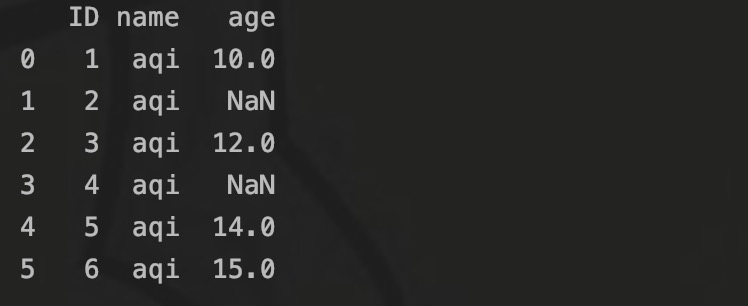
如图,第一列是数据下标,从0开始。第一行被识别为表头,所以下标是从第二行开始的。如果excel中没有表头,在read_excel()中指定header=None,则index 0就会从第一行开始。
查找空值
从读取的数据结果可以看出,excel中没有数据的部分被识别为了NaN,所以如果想要清除或者回填这些空数据的话,通过识别这些NaN即可实现。
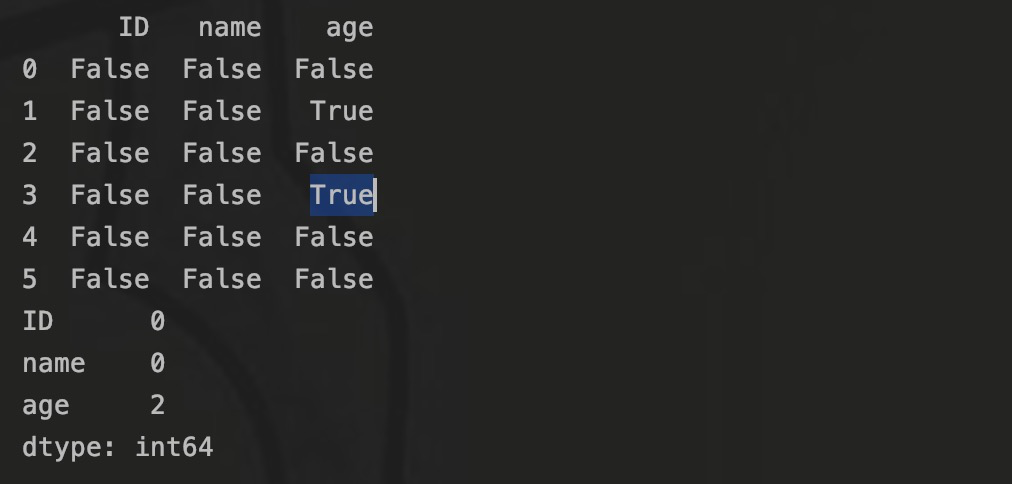
通过isnull()或者isna()即可识别excle中的空值。
print(df.isnull())
print(df.isnull().sum())如图,可以识别具体空值的位置,也可以对每列的空值进行统计:
处理空值
1. 删除空值
使用 dropna() 方法删除包含空值的行或列。
# 删除包含空值的行
df_cleaned = df.dropna()
# 删除包含空值的列
df_cleaned = df.dropna(axis=1)
# 只删除那些某些列中有空值的行
df_cleaned = df.dropna(subset=['column1', 'column2'])
# 删除空值超过一定阈值的行
df_cleaned = df.dropna(thresh=2)当然,删除可能会影响数据的完整性,通常我们会给空值填充一些默认值。
2. 填充空值
使用 fillna() 方法填充空值,常见的填充方式有:
# 用常数填充
df_filled = df.fillna(0)
# 用每列的均值填充
df_filled = df.fillna(df.mean())
# 前向填充:用前一个值填充
df_filled = df.fillna(method='ffill')
# 后向填充:用后一个值填充
df_filled = df.fillna(method='bfill')
# 针对不同列进行不同的填充
df_filled = df.fillna({'column1': 0, 'column2': df['column2'].mean()})分别使用fillna对excel中的数据进行常数、前向、后项填充,结果如下:

然后通过to_excel()将处理后的数据写到excel中。
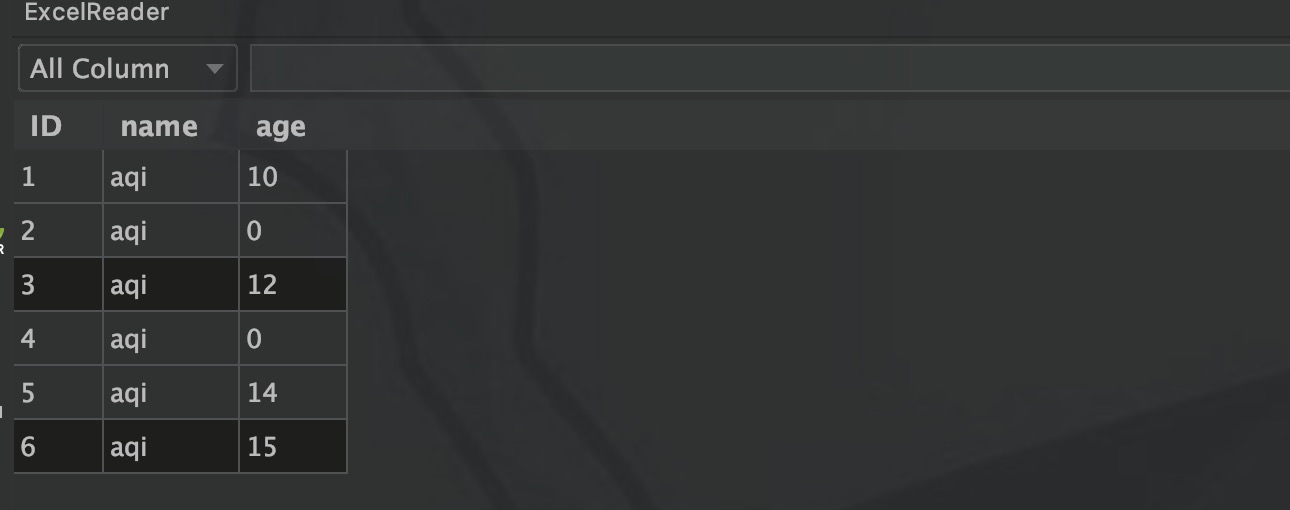
处理异常值
异常值(outliers)通常是指那些远离正常数据范围的值。可以通过多种方式来检测和处理异常值。在excel中,将某一列的age字段设置为200。
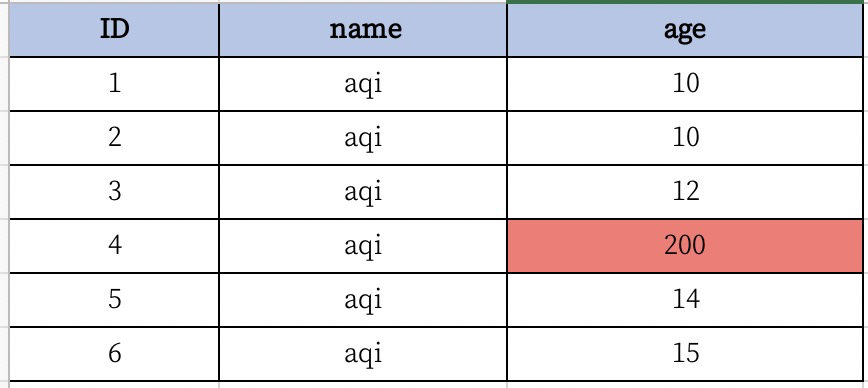
查找异常值
1. 统计信息
常见方法是使用统计指标或可视化工具来识别异常值:
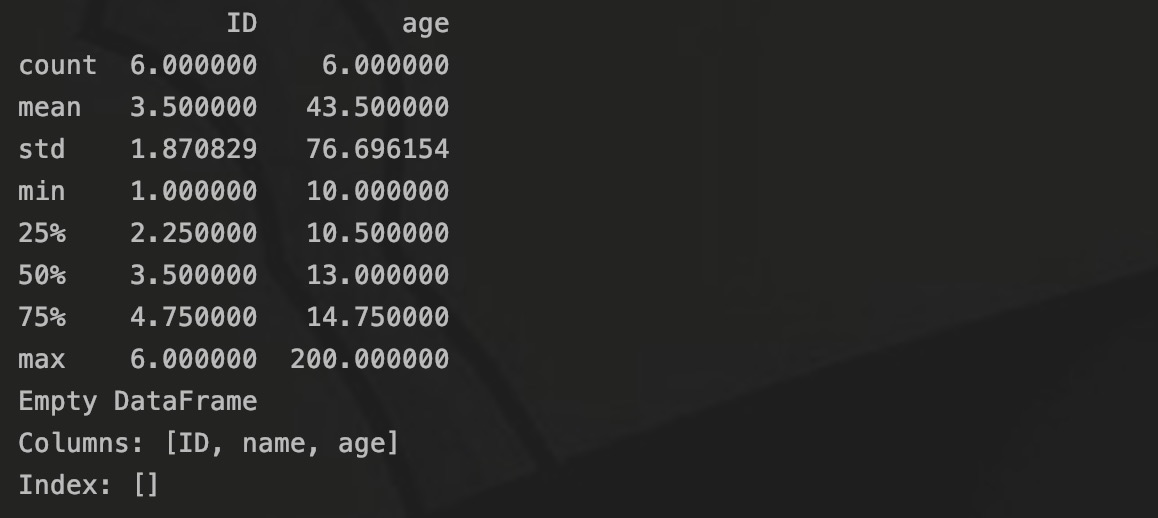
# 描述统计信息
print(df.describe())可以通过这些统计指标发现异常值,如图,在输出的信息中可以看到均值、标准差、最大最小值。
2. 箱线图
在age字段中,最小值为10,均值为43,最大值为200,所以200可能为异常值。除此之外,也可以通过箱线图来查看数据的分布:
# 使用箱线图(box plot)可视化异常值
import matplotlib.pyplot as plt
df.boxplot(column='age')
plt.show()如图,200的点与其他点分布不在同一个区域。

3. 标准差
也可以通过“三倍标准差原则”(Three Sigma Rule)寻找异常值,也称为3σ原则,主要用于检测数据中的异常值(outliers)。该原则是基于正态分布(高斯分布) 的特性而来的。
以下是其在正态分布中,数据集中围绕均值(mean)对称分布,并且:
- 68.27% 的数据点落在均值的1倍标准差(σ)范围内,即μ - σ ≤ x ≤ μ + σ
- 95.45% 的数据点落在均值的2倍标准差范围内,即μ - 2σ ≤ x ≤ μ + 2σ
- 99.73% 的数据点落在均值的3倍标准差范围内,即μ - 3σ ≤ x ≤ μ + 3σ
其中,μ 是数据集的平均值,σ 是标准差。
mean = df['age'].mean()
std = df['age'].std()
ower_bound = mean - 3 * std
upper_bound = mean + 3 * std
print(f"Lower bound: {lower_bound}, Upper bound: {upper_bound}")
# 筛选出异常值
outliers = df[(df['age'] < lower_bound) | (df['age'] > upper_bound)]
# 输出异常值
print("Outliers:")
print(outliers)结果没有输出200这个异常值:
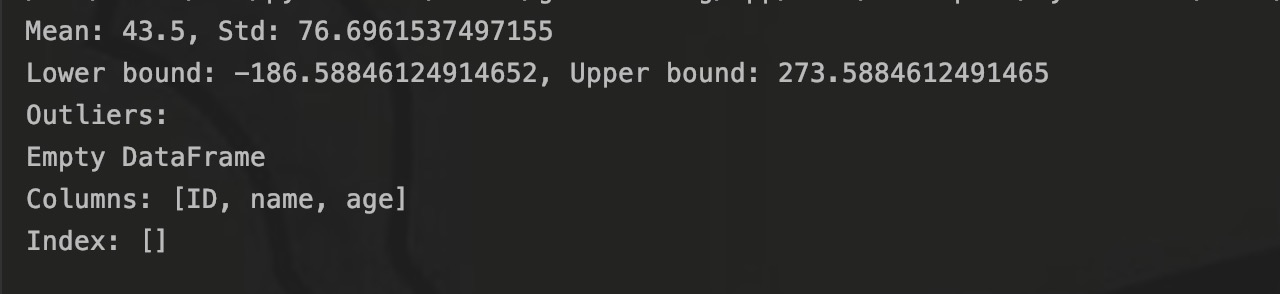
因为标准差反映了数据集的离散程度,如果标准差过大,导致 3σ 范围太宽,异常值不容易被识别,可以看到这里标准差是76,所以这里需要缩小正常数据的范围,使用 2σ 或 1.5σ 来筛选异常值,结果:

结语
在使用python开发完工具之后,可以使用pyinstaller将其打包成exe文件,然后安装在pc上。但是不支持mac,之前打包过几个生成文档的python小工具,有兴趣的可以尝试一下。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号