Apache Doris 3.0 里程碑版本|存算分离架构升级、湖仓一体再进化
原创
Apache Doris 3.0 里程碑版本|存算分离架构升级、湖仓一体再进化
原创
SelectDB技术团队
修改于 2024-10-17 18:12:45
修改于 2024-10-17 18:12:45
亲爱的社区小伙伴们,我们很高兴地向大家宣布,在近期我们迎来了 Apache Doris 3.0 版本的正式发布,欢迎大家下载使用体验!
从 3.0 系列版本开始,Apache Doris 开始支持存算分离模式,用户可以在集群部署时选择采用存算一体模式或存算分离模式。基于云原生存算分离的架构,用户可以通过多计算集群实现查询负载间的物理隔离以及读写负载隔离,并借助对象存储或 HDFS 等低成本的共享存储系统来大幅降低存储成本。
3.0 版本是 Apache Doris 在湖仓一体演化路线上的重要里程碑版本。在 3.0 版本中 Apache Doris 增加了数据湖写回功能,用户可以在 Apache Doris 中完成多个数据源之间的数据分析、共享、处理、存储操作。结合异步物化视图等能力,Apache Doris 可以作为企业统一的湖仓数据处理引擎,帮助用户更好的管理湖、仓、数据库中的数据。与此同时,3.0 版本引入了 Trino Connector 类型,用户可以快速使用 Trino Connector 来连接或适配更多数据源、并可以利用 Apache Doris 的高性能计算引擎提供比 Trino 更快的数据查询能力。
3.0 版本同样对 ETL 批处理场景进行了增强,对insert into select、delete 和 update 操作提供了显式事务支持;对查询执行过程中的可观测性进行了增强。
在性能方面,3.0 版本的查询优化器在框架能力、基础设施以及规则扩充等方面做了重要增强,针对更复杂更多样的业务场景提供更极致的优化能力,盲测性能更高。实现了自适应的 Runtime Filter 计算方式,能够在运行时根据数据大小准确估算 Runtime Filter,在大数据量和高压力场景下有更好的性能表现。对异步物化视图的构建能力、透明改写能力以及性能均进行了增强,使得物化视图在查询加速、数据建模等场景具有更好的稳定性和易用性。
在 3.0 版本的研发过程中,有超过 170 名贡献者为 Apache Doris 提交了近 5000 个优化与修复。 来自飞轮科技、百度、美团、字节跳动、腾讯、阿里、快手、华为、天翼云等企业的贡献者与社区深度共建,贡献了大量来自真实业务场景下测试 Case 来帮助我们持续打磨、共同改进,在此向所有参与版本研发、测试和需求反馈的贡献者们表示最衷心的感谢。
1. 存算分离全新架构
从 Apache Doris 3.0 版本开始,Apache Doris 开始支持存算分离模式,用户可以在集群部署时选择采用存算一体模式或存算分离模式。
全新存算分离模式对计算与存储进行了解耦,计算节点不再存储主数据,而是引入共享存储层(HDFS 与对象存储)作为统一的数据主存储空间,计算资源和存储资源可以独立扩缩容,为用户带来了多方面价值:
- 负载隔离:多个计算集群共享同一份数据,用户可以使用多计算集群对不同业务或者在离线的负载进行隔离;
- 存储成本大幅降低:全量数据存储到成本更低且极其可靠的共享存储中,热数据仅在本地 Cache,相比存算一体三副本,存储成本最高下降至原先的 1/10;
- 计算资源弹性:数据不保存在计算节点,计算资源可以按照负载需求实现灵活弹性扩缩容,比如单个计算集群的扩缩容或者加减计算集群,弹性带来了资源配置的灵活性以及成本的降低;
- 系统鲁棒性的提升:数据存储到共享存储,Doris 不再有多副本一致性的逻辑,会大幅度简化分布式存储带来的复杂度,从而会提升系统的鲁棒性。
- 数据共享和克隆的灵活性:存算分离架构的灵活性不止在一个 Doris 集群内部,在跨 Doris 集群时也应该体现出灵活性,比如 Doris 集群 A 中的库表可以轻量地在 Doris 集群 B 中完成克隆,即只做元数据级别的复制,不做数据的复制。
1-1. 从存算一体到存算分离
在存算一体模式中,Apache Doris 整体由 Frontend(FE)和 Backend(BE)两类进程组成,其中 FE 节点主要负责用户请求接入、查询解析规划、元数据管理和集群管理等相关工作,BE 节点主要负责数据存储和查询计划的执行,多 BE 节点间采取 MPP 分布式计算架构,通过多副本一致性协议来帮助服务的高可用和数据的高可靠。
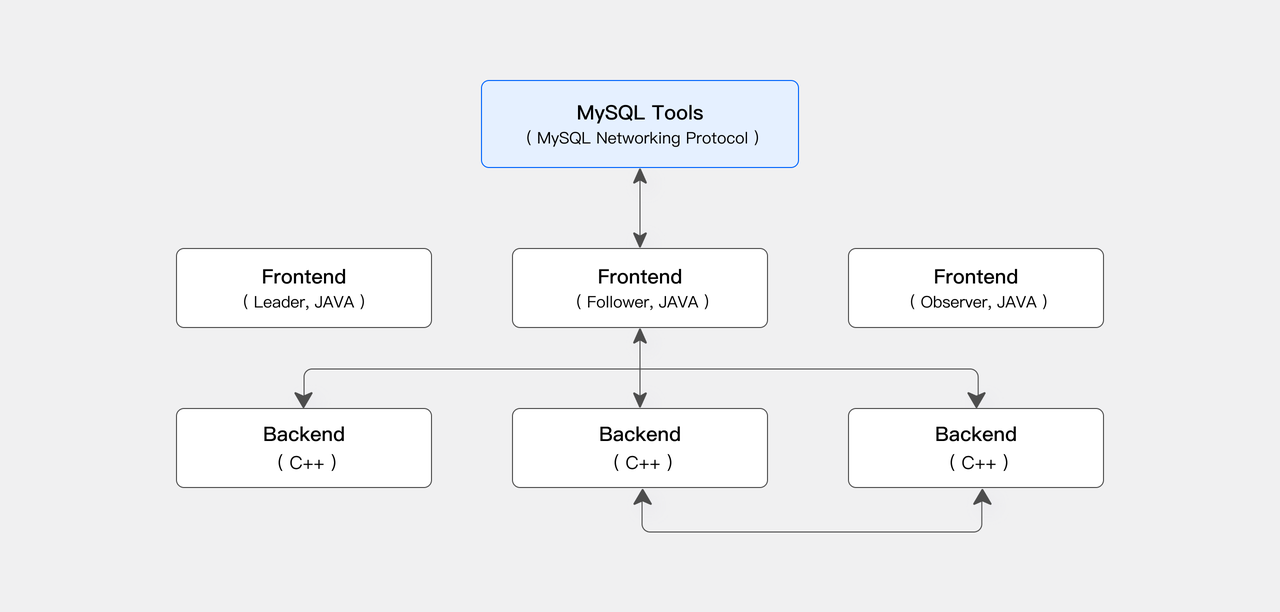
storage-compute-decoupled.PNG
新兴云计算基础设施的成熟,无论是公有云、私有云以及基于 K8s 的容器平台,云计算基础设施的革新催生了新的需求,越来越多用户期待 Apache Doris 针对云计算基础设施提供更加深度的适配,以便提供更加灵活强大的弹性能力,因此飞轮科技团队早在 2022 年基于 Apache Doris 设计并实现了云原生存算分离版本(SelectDB Cloud),在经过数百家企业近两年的大规模生产打磨后,将其贡献回 Apache Doris 社区,即当前 3.0 版本的存算分离模式。
在存算分离模式下,Apache Doris 整体架构演化成元数据层、计算层和共享存储层三层:
- 元数据层:新引入 Meta Service 模块来提供系统的元数据服务,例如库表、Schema、Rowset Meta、事务等信息,是一个可以横向扩展的无状态服务。目前 BE 的 Meta 已经全部进入了 Meta Service,FE 的部分 Meta 已进入 Meta Service,其它 Meta 在后续版本中也会全部进入 Meta Service。
- 计算层:负责执行查询规划,计算节点即无状态的 BE 节点,会缓存一部分 Tablet 元数据和数据到本地以提高查询性能。通过多个无状态的 BE 节点可以组成计算资源集合(即多计算集群),多个计算集群共享一份数据和元数据服务,计算集群支持随时弹性加减节点。
- 共享存储层:数据持久化到共享存储层,目前支持 HDFS 以及 S3、OSS、GCS、Azure Blob、COS、BOS、MinIO 等各类云上兼容 S3 协议的对象存储系统。
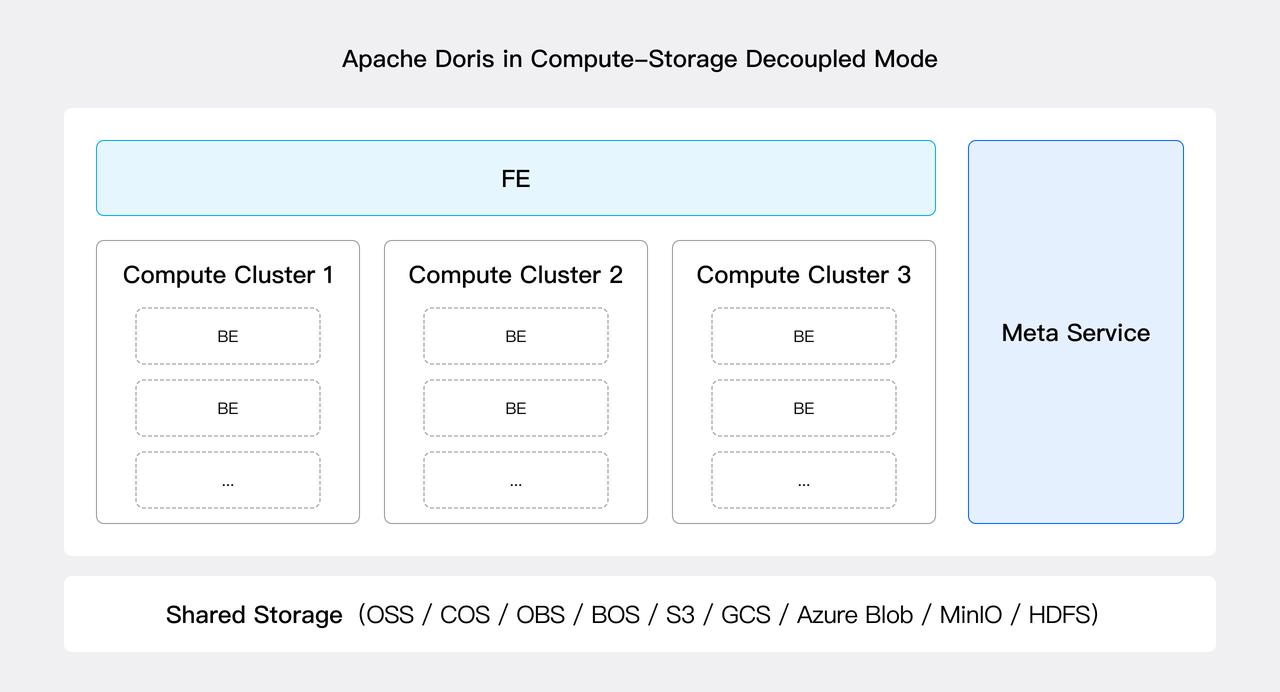
storage-compute-decoupled-2.JPEG
1-2 设计亮点
全新存算分离架构最大的设计亮点在于将 FE 全内存的元数据模式演变成共享的元数据服务,这一方案的优势在于,元数据服务提供了全局一致的状态视图,任何节点可以直接提交写入,不再需要经过 FE 做 Publish。写入时数据进入共享存储,元数据进入元数据服务,可以有效控制共享存储上的小文件数量,同时单表的实时写入性能和存算一体相差无几,整个系统的写入能力不再受限于单 FE 的处理能力。
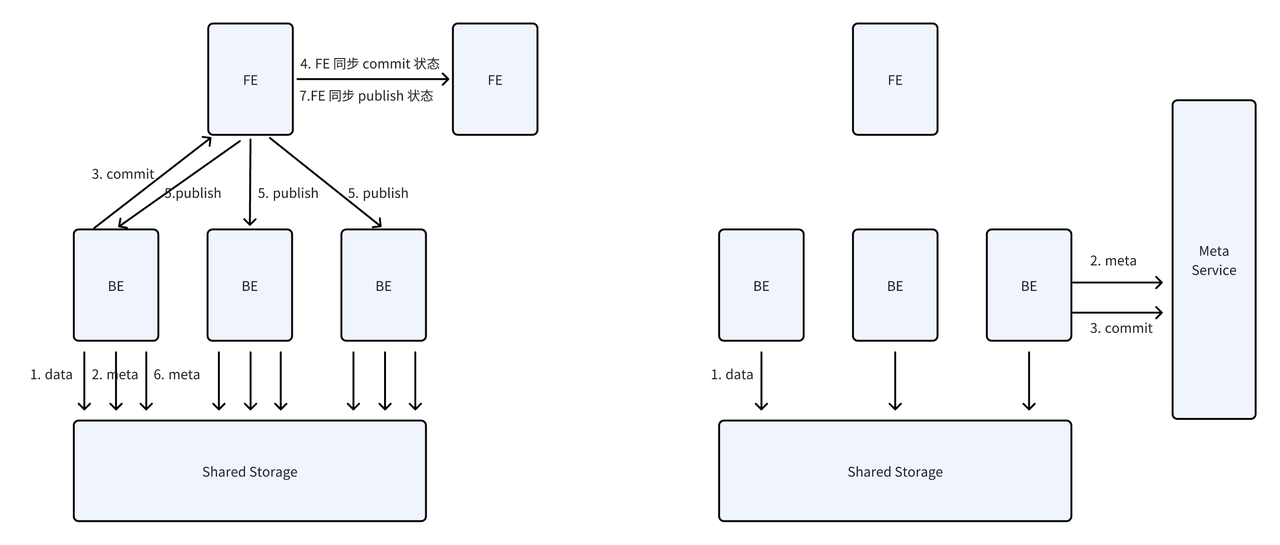
storage-compute-decoupled-highlight-3.PNG
基于全局一致的状态视图,在数据 GC 时,我们采用了设计上容易证明正确性和效率更高的正向数据删除。具体而言,将共享存储中的数据纳入到在共享元数据服务提供的全局一致视图中,数据生成时绑定一个事务,元数据删除时也绑定一个事务,以此可以实现删除和写入不能一起成功,视图中记录了哪些数据需要删除,异步删除过程只需要根据事务记录正向删除数据即可,不需要反向 GC。
未来随着 FE 中 Tablet 相关的 Meta 进入共享服务,Doris 集群规模也不再受限于单 FE 内存。基于共享的元数据服务和正向的数据删除技术,在此基础上可以便捷地扩展数据共享、轻量克隆等功能。
1-3 业界同类方案对比
业界还有另一种存算分离架构的设计方案,将数据和 BE 节点的 Meta 存放在共享对象存储或者 HDFS 中,该方案会有如下的问题:
- 无法承载实时写:在写入数据时,数据会根据分区分桶规则映射到 Tablet 中并生成 Segment 文件以及 Rowset Meta。在写入阶段会通过 FE 进行两阶段提交(即 Publish),在 BE 节点接到 Publish 请求后再将 Rowset 设置为可见,Publish 是不允许失败的。如果将 Rowset Meta 保存在共享存储中,实时写入过程中的小文件数据是数据文件的三倍,一次写入数据结束后生成 Rowset Meta、一次 Publish 时更改 Rowset Meta 状态。Publish 是由 FE 节点单点驱动的,不论单个表或整个系统的写入能力都受限于 FE 节点。
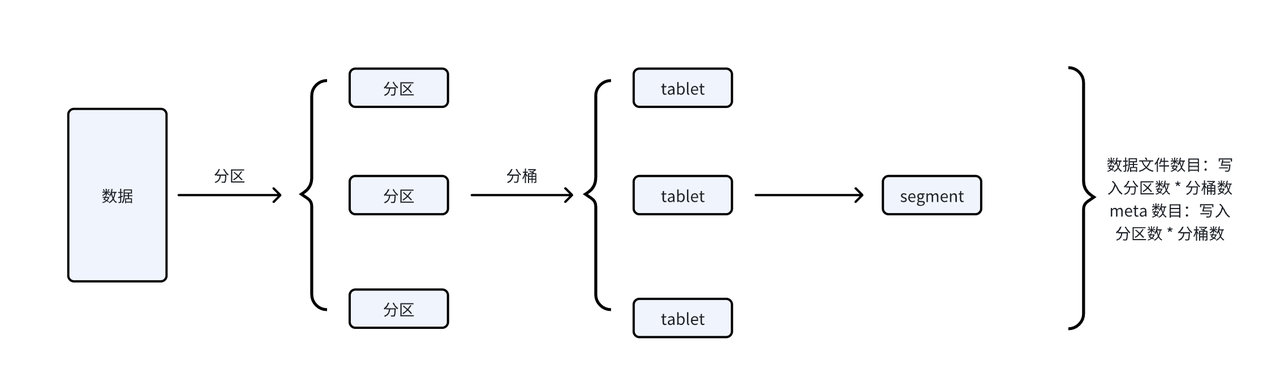
storage-compute-decoupled-comparison-4.png
在 Apache Doris 3.0 版本正式发版后,我们对该方案实时数据写入性能与 Apache Doris 进行了对比。在此我们在相同计算资源下分别模拟 500 并发任务写入 10000 个 500 行的数据文件和 50 并发任务写入 250 个 20000 行的数据文件,可以看到在 50 并发下 Apache Doris 存算分离和存算一体模式的微批写入性能基本相当,而该方案写入性能与 Apache Doris 差距达到 100 倍。在 500 并发下,Apache Doris 存算分离模式性能稍有损耗,但对比该方案仍有超过 11 倍的巨大优势。为了保证测试公平性,Apache Doris 并未开启 Group Commit 服务端攒批的能力(该方案不具备此能力),而在开启 Group Commit 后实时写入能力还将进一步增强。
storage-compute-decoupled-comparison-4.png
此外该方案在实时写入方面还存在稳定性和成本问题:
- 稳定性隐患:小文件数目多会给共享存储特别是 HDFS 带来更大的压力和不稳定隐患。
- 对象存储请求费用高:部分公有云对象存储的 Put 和 Delete 收费是 Get 的 10 倍,小文件数目多会导致对象存储请求费用大幅上升,甚至超过存储费用。
- 扩展性受限:FE 的 Meta 是全内存的,存算分离模式下往往会面对更大规模的数据存储,因此当 Tablet 数量超大时(例如超过千万级别),FE 内存的压力较大;整个系统的写入能力受到 FE 单点瓶颈的限制。
- 数据删除逻辑隐患:存算分离架构下数据只有一份,因此数据删除逻辑对于系统的可靠性至关重要。常规的跨系统数据删除做法是对比计算出差集,对于写入过程中的数据依赖超时时间,没办法从机制上 100% 避免删除和写入一起成功,删除和写入一起成功就会丢数据。另外在存储系统有异常时,用于计算差集的输入可能错误,这就可能导致误删除数据。
- 数据共享与轻量级克隆:存算分离架构未来可以借助于架构的灵活性实现数据共享和轻量级数据克隆,降低企业数据管理的负担。如若每个集群是单独的 FE,跨集群克隆数据之后,很难计算出哪些数据没有被引用可以被删除,跨多个集群计算很容易误删数据。
与之相比,Doris 3.0 版本将 FE 全内存的元数据模式演变成共享的元数据服务有效地克服了以上问题。
1-4 查询性能对比
由于存算分离模式下数据需要从远端共享存储系统中读取,因此数据传输的主要瓶颈,从存算一体模式下的磁盘 IO 转变为存算分离模式下的网络带宽,在一定程度上会造成性能损耗。
为了加速数据访问,Apache Doris 实现了基于本地磁盘的高速缓存机制,并提供 LRU 和 TTL 两种高效的缓存管理策略,并对索引相关的数据进行了优化,旨在最大程度上缓存用户常用数据、提升查询性能。新导入的数据将异步写入缓存中,以加速最新数据的首次访问。如果查询所需数据不在缓存中,系统将从远端存储中读取该数据进内存并同步写入缓存中,以便于后续查询。在涉及多计算集群的应用场景中,Apache Doris 提供缓存预热功能,当新计算集群建立时,用户可以选择对特定的数据(如表或分区)进行预热,以进一步提高查询效率。
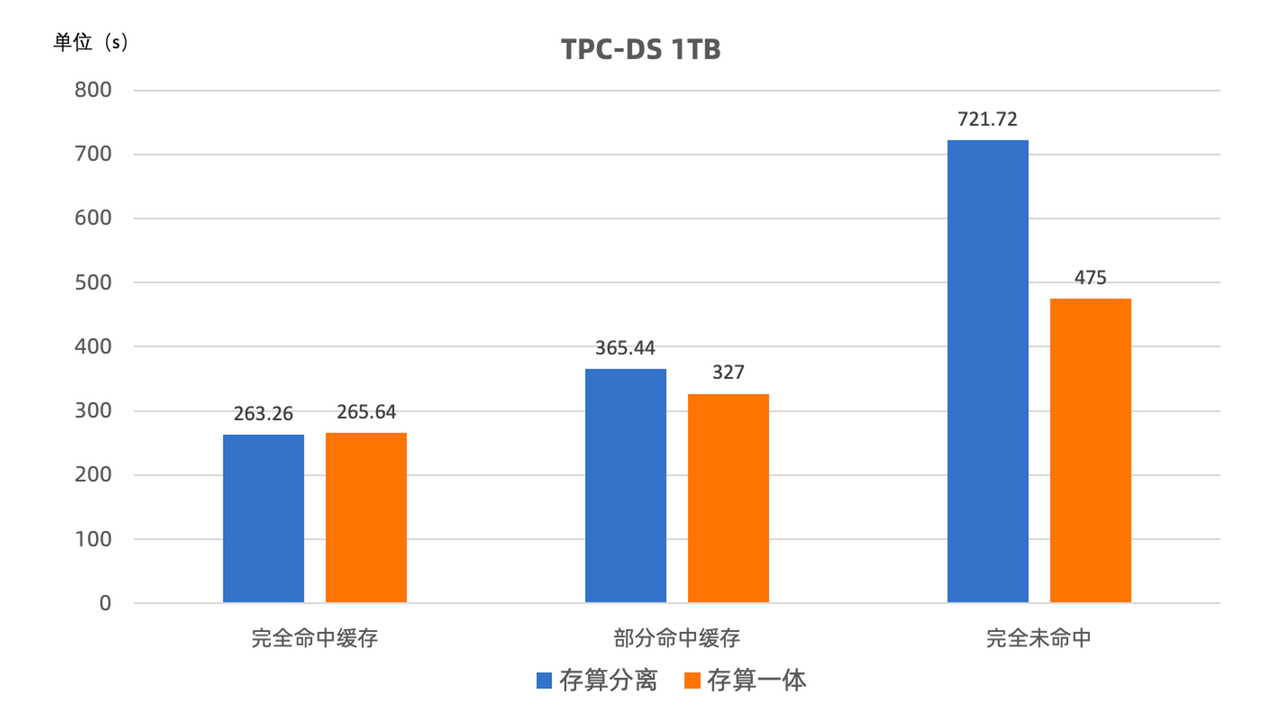
在此我们分别对存算一体模式和存算分离模式进行了不同缓存下的性能测试,以 TPC-DS 1TB 测试集为例,主要结果如下:
- 完全命中缓存时(即查询的所有数据均被加载进缓存中)存算分离模式与存算一体模式查询性能完全持平;
- 部分命中缓存时(即测试开始前清空所有缓存,初始状态下缓存中无任何数据,在测试过程中数据被逐渐加载进缓存中,性能随之持续提升)存算分离模式与存算一体模式查询性能基本相当,总体性能损耗约 10% ,这一测试场景也与用户实际应用中最为类似。
- 完全未命中任何缓存时(每次执行 SQL 前均清理所有缓存,模拟极端情况)性能损耗约 35%。即使在冷数据读取时存在一定性能损耗,但相较于业内其他同类系统,存算分离模式下的 Apache Doris 仍有着极为明显的性能优势。
storage-compute-decoupled-query-performance-6.png
1-5 写入性能对比
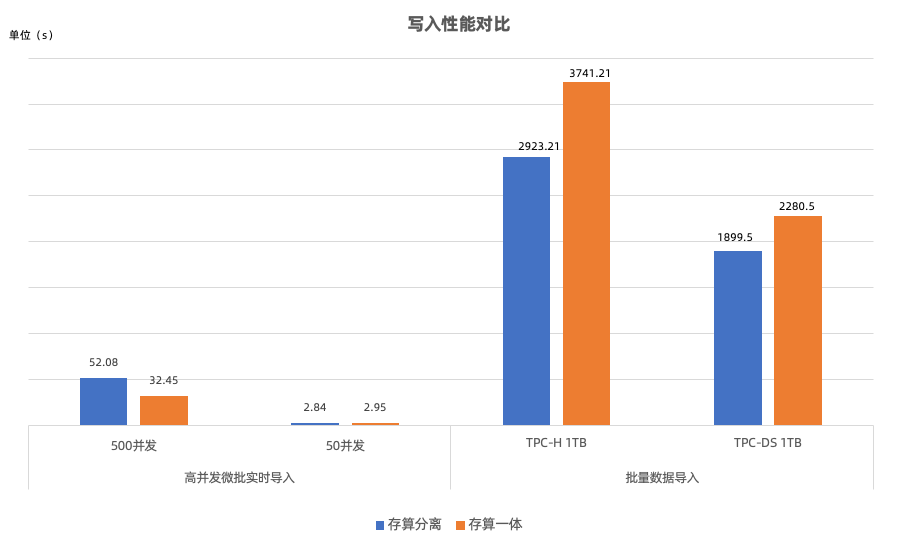
在写入性能方面,我们在相同计算资源下分别模拟了批量导入和高并发实时导入两大场景,存算一体模式和存算分离模式的写入性能对比结论如下:
- 在批量数据导入场景,导入 TPC-H 1TB 和 TPC-DS 1TB 测试数据集,在存算一体模式采用单副本的情况下,存算分离模式写入性能较存算一体模式分别提升了 20.05% 和 27.98%。批量导入时 Segment 文件大小一般会在几十 MB 到上百 MB,存算分离模式会将 Segment 文件切分成多个小文件并发上传到对象存储,因而会带来比写本地磁盘更高的吞吐。实际部署中存算一体模式一般会采用三副本,此时存算分离模式的写入性能优势会更加明显。
- 高并发实时导入场景在前文中已介绍,在此不在赘述。
storage-compute-decoupled-loading-performance-7.png
1-6 生产运行经验
- 性能:实时数据场景下可以指定 TTL 的 Cache 以及写入时数据进入 Cache,使查询性能达到与存算一体。Compaction 和 Schema Change 后台任务生成的数据根据热度进入 Cache 可以避免查询抖动。
- 负载隔离:多计算集群提供了物理层资源隔离,比如不同业务单元适合使用多计算集群隔离。单个计算集群内依然需要使用 Workload Group 对不同的查询做资源的限制和隔离。
1-7 注意事项
- 当前 3.0 版本存算一体模式与存算分离模式不可共存,用户在集群部署时需要指定其中一种模式进行部署。
- 存算一体模式的部署和升级可以正常按照官网文档进行,推荐采用 Doris Manager 进行快速部署和集群升级,存算分离模式暂不支持 Doris Manager 部署和升级,后续我们将会持续迭代以实现更好支持。
- 暂不支持从 2.1 版本原地升级至 3.0 存算分离模式,需要在存算分离集群部署完成后通过诸如 x2Doris 等工具进行数据迁移,后续也会支持通过 CCR 能力实现不停服迁移。
参考文档: 存算分离
2. 湖仓一体再进化
尽管 Apache Doris 定位于实时数据仓库,在以往版本中一直不拘于数据仓库的能力边界,在湖仓一体方向持续发力。而 3.0 版本是 Apache Doris 在湖仓一体路线上的重要里程碑版本,从 3.0 版本开始,Apache Doris 在湖仓一体场景的能力臻于完善。对于湖仓一体,我们认为其最核心的理念即数据无界、湖仓融合:
数据无界:将 Apache Doris 作为统一查询处理引擎,打破数据在不同系统间的屏障,在数据仓库、数据湖乃至数据流、本地数据文件等所有数据源端都能提供一致且极速的分析处理体验。
- 湖仓查询加速:无需将数据迁移至 Apache Doris,用户便可直接利用 Doris 高效的查询引擎,直接查询 Iceberg、Hudi、Paimon 等数据湖和 Hive 等离线数仓中的数据,实现查询分析的加速。
- 联邦分析:Apache Doris 通过扩展 Catalog 和存储插件,丰富其联邦分析能力,使用户无需将数据物理集中至统一的存储空间,在保持各数据源独立性和隐私性的同时,仅借助 Apache Doris 即可实现多个异构数据源的统一分析,既可以直查外部表以及存储文件、也可以执行内表和外表以及外表相互之间的关联分析,打破数据孤岛、提供全局一致性的数据洞察与分析。
- 数据湖构建: Apache Doris 增加了 Hive、Iceberg 数据写回功能,写回功能支持用户直接通过 Doris 创建 Hive、Iceberg 表,并将数据写入到表中。基于此,用户可以将 Apache Doris 中的内表数据写回离线湖仓,或者对离线湖仓中的数据利用 Apache Doris 进行数据加工后落地回离线湖仓,从而实现更简化和高效的数据湖构建。
湖仓融合:数据湖架构日益复杂,增加了用户技术选型成本与维护成本。同时实现多个系统一致的细粒度权限管控也变得非常困难,实时性也不足。为应对这一挑战,Apache Doris 融入了湖的核心特征,将其打造成一个轻量、高效的原生实时湖仓。
- 数据实时更新: 从 1.2 版本开始 Apache Doris 增强了主键模型,引入 Merge-on-Write,支持实时更新。借助这一特性,上游数据变更可以基于主键进行高频实时数据更新。
- 数据科学与 AI 计算支撑: 从 2.1 版本开始 Apache Doris 借助高效的 Arrow Flight 协议,增强了存储的开放性和对多计算负载的高效支持,这让 Apache Doris 支持数据科学和 AI 计算成为可能。
- 半结构化与非结构化数据增强: Apache Doris 先后引入 Array / Map / Struct / JSON / Variant 等数据类型,未来还会支持向量索引。
- 存算分离资源能效提升: 从 3.0 版本中支持了存算分离模式,进一步提升了资源效率和可扩展性。
1-1 湖仓查询加速
查询加速是湖仓一体化进程中的重要一环。借助 Apache Doris 强大的分布式查询引擎,可以帮助用户对湖仓数据进行快速分析。在 TPC-H 和 TPC-DS 标准测试集上,Apache Doris 的平均查询性能是 Trino/Presto 的 3-5 倍。
在 3.0 版本中,我们重点针对用户实际生产环境中的湖仓查询加速场景进行了优化,包括:
- 更精细的任务拆分策略: 通过对一致性哈希算法的调整以及引入任务分片权重机制,确保各个节点的查询负载均衡。
- 面向多分区、多文件场景的调度优化: 在大量文件(100 万+)场景下,通过异步、分批获取文件分片的方式,显著降低查询耗时(100s -> 10s),并降低 FE 内存压力。
后续我们将进一步针对性的提升真实业务场景下的查询加速性能,提升用户实际感受,构建业界领先的湖仓查询加速引擎。
1-2 联邦分析 - 更丰富的数据源连接器
在之前的版本中,Apache Doris 已经支持了 10 余种主流湖、仓、关系型数据库的连接器。在 3.0 版本中,我们引入了 Trino Connector 兼容框架,极大扩展了 Apache Doris 可连接的数据源。借助该框架,仅需简单适配,用户即可通过 Doris 访问对应的数据源,并利用 Doris 的极速计算引擎进行数据分析。
目前 Doris 已完成 Delta Lake、Kudu、BigQuery、Kafka、TPCH、TPCDS 等多种 Connector 的适配,也欢迎所有开发者参考开发指南,为 Apache Doris 适配更多数据源。
参考文档:
1-3 数据湖构建
在 3.0 版本中,Apache Doris 增加了 Hive、Iceberg 数据写回功能。写回功能支持用户直接通过 Doris 创建 Hive、Iceberg 表,并将数据写入到表中。该功能使得 Apache Doris 在湖仓数据处理能力上形成闭环,用户可以在 Apache Doris 中完成多个数据源之间的数据分析、共享、处理、存储操作。
在后续的迭代版本中,Apache Doris 将进一步完善对数据湖表格式的支持以及存储 API 开放性。
参考文档:数据湖构建
3. 半结构化分析全面增强
在过去发布的 2.0 和 2.1 版本中,Apache Doris 陆续引入了倒排索引、N-Gram Bloom Filter、Variant 数据类型等重磅特性,支持高性能的全文检索和任意维度分析,对复杂半结构化数据的存储和处理分析更加灵活高效。
在 3.0 版本中,我们继续对这一场景能力进行了全面增强,在应对半结构化数据分析和日志检索分析场景的挑战时更加得心应手。
Variant 数据类型在经过大规模生产打磨后,已具备充分的稳定性,成为 JSON 数据存储和分析的首选。在 3.0 版本中我们对 Variant 类型进行了多项优化:
- Variant 数据类型支持创建索引加速查询,包括倒排索引、Bloom Filter 索引以及内置的 ZoneMap 索引;
- 对于包含 Variant 数据类型的 Unique 模型表,支持灵活的部分列更新;
- Variant 数据类型支持在存算分离模式上使用,并对其元数据存储进行了优化;
- 支持将 Variant 数据类型导出成 Parquet、CSV 等格式。
倒排索引自 2.0 版本开始被引入起,经历一年多的打磨,目前已具备较高的成熟度,在数百家企业的生产环境中长期运行。在 3.0 版本中,我们对倒排索引进行了多项优化:
- 通过锁并发等一系列的性能优化,在实时报表分析场景中 Apache Doris 在查询延迟和并发等关键指标已大幅超过 Elasticsearch;
- 在存算分离模式下优化了索引文件,减少远端存储的调用,大幅优化了索引查询延迟;
- 增加了对 Array 类型的支持,加速
array_contains查询; - 对短语查询系列
match_phrase_*功能进行增强,包括支持词距 slop、短语前缀匹配match_phrase_prefix等。
4. ETL 能力持续增强
4-1. 事务增强
数据加工在数据仓库中是一个常见的场景,通常需要多个数据变更作为一个事务。Doris 3.0 对insert into select、delete 和 update 操作提供了显式事务支持。具体的应用场景比如:
- 事务性要求:例如更新一个时间范围的数据,通常的做法是先删除这个时间范围的数据,然后写入。考虑到数据已经在服务,希望查询时要么看到老的数据要么看到新的数据,因此可以在一个事务中执行
delete和insert into select。 BEGIN; DELETE FROM table WHERE date >= "2024-07-01" AND date <= "2024-07-31"; INSERT INTO table SELECT * FROM stage_table; COMMIT; - 简化任务失败的处理:例如一个数据加工包含 2 个
insert into select,在一个事务中去执行,任何一步失败只需要重新开始执行即可。 BEGIN WITH LABEL label_etl_1; INTO table1 SELECT * FROM stage_table1; INSERT INTO table SELECT * FROM stage_table; COMMIT;
参考文档: 事务 目前 CCR 暂未支持显示事务同步。
4-2 可观测性增强
- Profile 实时获取:在过去,某些复杂查询可能由于 Plan 的原因或者数据的原因,导致计算量特别大,开发者只有在查询结束后才能拿到 Profile 做性能分析以发现问题,有可能对线上系统产生影响。通过 Profile 实时获取,开发者可以在查询的运行过程中实时获取查询执行的 Profile,看到每个算子的执行情况,不需要等到查询执行结束。基于实时 Profile 获取功能,开发者还可以进一步监控每一 ETL 作业的执行进度。
- 系统表 backend_active_tasks:
backend_active_tasks系统表提供了每个 Query 在每个 BE 上的实时资源消耗信息,可以通过 SQL 对系统表做分析计算,进而实时获得每个 Query 的资源使用量,有利于用户发现大查询或者不合理的工作负载。
5. 多表物化视图
在 Apache Doris 3.0 版本中,对多表物化视图的构建能力进行了增强并提高稳定性,拓展了透明改写的能力、透明改写性能提升 2 倍,重构了同步物化视图的透明改写逻辑并拓展了透明改写的能力,同时在异步物化视图的易用性上做了增强,让物化视图在查询加速,数据建模等场景更好用、更稳定。
5-1. 构建刷新功能
- 物化视图的支持分区增量更新,大大减少了物化视图的构建成本,并且支持物化视图分区上卷,满足不同粒度的分区刷新物化视图需求。
- 支持构建嵌套物化视图,在数据建模场景更好用。
- 允许异步物化视图创建索引和指定排序键,命中物化视图后查询速度会提升。
- 提高了物化视图 DDL 的易用性,支持物化视图原子替换,可以保证物化视图一直可用的情况下,修改物化视图定义 SQL。
- 允许物化视图使用非确定函数,在定时构建 T+1 物化数据的场景更易用。
- 新增了触发刷新物化的功能,在使用嵌套物化视图数据建模时,保证数据一致性。
- 拓展了可以构建分区物化视图的 SQL 模式,让更多的场景可以使用分区增量更新能力。
5-2. 构建刷新稳定性
- 支持指定物化视图构建时的 Workload Group,限制物化视图构建使用的资源,保障查询的可用资源。
5-3. 透明改写功能拓展
- 支持了更多 Join 类型的改写,并且支持了 Join 衍生改写。当查询和物化视图的 Join 的类型不一致时,如果物化可以提供查询所需的所有数据时,通过在 Join 的外部补偿谓词,也可以进行透明改写。
- 增强了聚合改写,支持了更多的聚合函数上卷,并且支持了多维聚合函数 GROUPING SETS、ROLLUP、CUBE 的改写,同时支持了查询包含聚合,物化不包含聚合的改写,可以节省 Join 连接和表达式计算。
- 支持了嵌套物化视图的透明改写,在复杂的查询加速场景下,可以借助嵌套物化视图来进行极致加速。
- 分区物化视图部分分区失效,支持物化视图 Union All 基表补全数据,增加了分区物化视图的适用范围。
5-4. 透明改写性能
- 持续优化了透明改写的性能,透明改写性能是 2.1.0 版本的两倍。
6. 性能提升
6-1. 优化器更智能
在 3.0 版本中,查询优化器在框架能力、分布式计划支持、优化器基础设施以及规则扩充等方面做了重要增强,支持更复杂更多样的业务场景、提供更极致的优化能力,对于复杂 SQL 有更高的盲测性能:
- 更完善的计划枚举能力:对计划枚举的关键结构 Memo 做了 Projection 规范化重构,不仅提升了 Cascades 框架枚举有效计划的效率和枚举出更优计划的可能性,同时也修复了历史版本 Join Reorder 过程中列裁剪不完全导致的 Join 算子不必要开销等遗留问题,有效提升相应场景下的执行性能。
- 更完善的分布式计划支持:对分布式查询计划做了增强,使得聚合,连接和窗口函数操作能更智能的识别中间运算结果的数据特征,避免无效的数据重分布操作,提升相应场景的性能。同时,3.0 版本中对多副本连续执行模式下的执行性能也进行了优化,使其对数据缓存更友好,相应性能也得到较大提升。
- 更完善的优化器基础设施:在代价模型和统计信息估行方面,3.0 版本也修复了若干重要估行问题,代价模型问题的修复也更加适配执行引擎迭代,使得执行计划相较历史版本更稳定。
- 更丰富的 Runtime Filter 计划支持:3.0 版本在传统 Join Runtime Filter 的基础上,拓展了 TopN Runtime Filter 的能力。典型场景如存在 TopN 算子时,可以生成 TopN 的 Runtime Filter 以获得更好的执行性能。
- 更丰富的优化规则库:持续的增强和迭代基础优化规则库,通过持续不断地业务反馈和内测增强,3.0 版本中加入了如 Intersect Reorder 等典型的优化规则支持,使得优化器的规则成熟度得到了进一步的提升。
6-2. 自适应 Runtime Filter
Runtime Filter 是否能够准确生成对查询性能的影响至关重要,在过去 Doris 非常依赖于用户手工设置或者优化器根据统计信息来生成,在某些情况下一旦设置不准确将会带来性能抖动。
在 3.0 版本实现了自适应的 Runtime Filter 计算方式,能够在运行时根据数据大小准确估算 Runtime Filter,在大数据量和高压力场景下有更好的性能表现。
6-3. 函数性能优化
- 3.0 版本对数十个函数的向量化实现做了改进,部分常用函数的性能提升 50% 以上。
- 对 Nullable 类型数据的聚合计算也做了大量优化,性能提升 30%。
6-4. 盲测性能进一步提升
我们对 3.0 版本与 2.1 版本分别在 TPC-DS 和 TPC-H 测试数据集上进行了盲测性能测试,查询性能分别提升了 7.3% 以及 6.2%。
storage-compute-decoupled-loading-performance-7.png
7. 新功能
7-1. Java UDTF
从 3.0 版本开始支持增加对 Java UDTF 的支持,主要操作如下:
- 编写 UDTF:UDTF 和 UDF 函数一样,需要用户自主实现一个
evaluate方法,注意 UDTF 函数的返回值必须是 Array 类型。 public class UDTFStringTest { public ArrayList<String> evaluate(String value, String separator) { if (value == null || separator == null) { return null; } else { return new ArrayList<>(Arrays.asList(value.split(separator))); } } } - 创建 UDTF:这里会默认创建两个对应的函数
java-utdf和java-utdf_outer,outer的后缀在表函数生成 0 行数据时添加一行Null数据。 CREATE TABLES FUNCTION java-utdf(string, string) RETURNS array<string> PROPERTIES ( "file"="file:///pathTo/java-udaf.jar", "symbol"="org.apache.doris.udf.demo.UDTFStringTest", "always_nullable"="true", "type"="JAVA_UDF" );
参考文档: Java UDF - UDTF
7-2 生成列
生成列是一种特殊的数据库表列,其值由其他列的值计算而来,而不是直接由用户插入或更新。该功能支持预先计算表达式的结果,并存储在数据库中,适用于需要频繁查询或进行复杂计算的场景。
生成列可以在数据导入或更新时自动根据预定义的表达式计算结果,并将这些结果持久化存储。在后续的查询过程中,可以直接访问这些已经计算好的结果,而无需在查询时再进行复杂的计算,从而显著减少查询时的计算负担,提升查询性能。
从 3.0 版本开始 Apache Doris 支持生成列功能,创建表时可以指定列为 Generated 列。Generated 列可在写入时,根据定义的表达式,自动获取计算结果。相比于 Default value,可以定义更为复杂的表达式,但不可以显式写入指定的值。
8. 功能改进
8-1. 同步物化视图
重构同步物化视图选择逻辑,将选择逻辑从 RBO 迁移至 CBO,使其与异步物化视图保持一致。
此功能默认开启。如遇到问题,可使用开关 set global enable_sync_mv_cost_based_rewrite = false 回退到 RBO 模式。
8-2. Routine Load 导入
在之前的版本中,Routine Load 存在部分体验性问题:任务在 BE 节点之间调度不均、调度不及时,配置繁琐、需要同时改 FE 和 BE 的多个配置进行调优,稳定性不够高、重启或升级等都可能导致 Routine Load Job 暂停,需要人工介入才能恢复。我们针对这些问题对 Routine Load 做了大量的优化,使得 Routine Load 更高效、稳定且易用,为用户提供更好的体验。
- 资源调度方面,改善了任务在 BE 节点之间的调度均衡性,确保任务能够更加均匀地分配到各个节点。对于发生无法恢复错误的 Job 及时暂停,避免无效调度导致的资源浪费,并改进了调度的及时性,提升了 Routine Load 的导入性能。
- 参数配置方面,简化了配置过程,用户在大部分环境下无需修改 FE 和 BE 的配置进行调优。同时引入超时参数自动调整机制,避免集群压力增大时,任务持续超时重试。
- 稳定性方面,增强了其在各种异常场景下的稳定性,如 FE 切主、BE 滚动升级、Kafka 集群异常等都能持续稳定的工作。优化了 Auto Resume 机制,使得在故障恢复后 Routine Load 能够自动恢复运行,减少了用户的人工介入。
9 行为变更
cpu_resource_limit将不再支持,所有的资源隔离方式都依赖 Workload Group 实现。- 从 3.0 版本开始请使用 JDK 17,推荐版本
jdk-17.0.10_linux-x64_bin.tar.gz。
立刻开启 3.0
在 3.0 版本正式发布之前,存算分离架构在 SelectDB 数百家企业的生产环境已经得到近两年的大规模打磨,同时来自百度、美团、字节跳动、腾讯、阿里、快手、华为、天翼云等企业多名贡献者与社区深度共建,贡献了大量来自真实业务场景下测试 Case,使得 3.0 版本在功能易用性和系统稳定性得到了有力验证,推荐有存算分离需求的用户下载 3.0 版本进行尝鲜。
后续我们也将加快发版迭代节奏,力求给所有用户带来更稳定的版本体验。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号