【多干预多响应】Uplift模型如何做因果推断结果分析?
原创
【多干预多响应】Uplift模型如何做因果推断结果分析?
原创
百川AI
发布于 2024-10-20 23:00:44
发布于 2024-10-20 23:00:44
Uplift模型有很多介绍的文章,也有一些评估方式,例如AUUC、 十分位柱状图、累计增益曲线Qini Curve等,但是如果模型结果好或者不好,我们需要怎么进一步分析,却少有文章介绍,本问以Interpretable multiple treatment revenue uplift modeling这篇论文的方法介绍模型分析以及可解释性的方法。
建模方法
首先Uplift模型从干预和响应类型分为四类,文章主要介绍的场景也是多干预场景连续结果MT-Rev,这也是现实中比较场景的场景,特别是在营销推荐场景中。
- ST-Conv:单干预和二分类响应。
- ST-Rev:单干预和多分类响应,甚至响应可能是连续值。
- MT-Conv:多干预和二分类响应。
- MT-Rev:多干预和多分类响应,甚至响应可能是连续值。
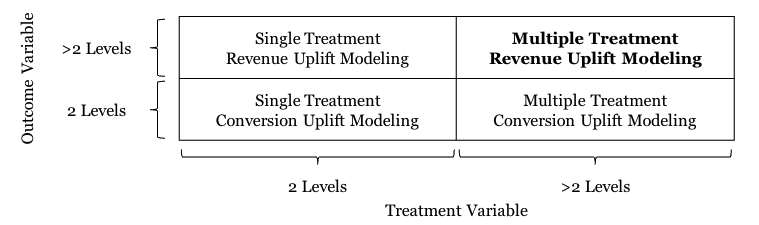
文章在MT-Rev场景一种方法是将干预作为特征和未干预做比较获得lift值(Combined Treatment Approach),另一种方法是分别将每一种干预和未干预建模比较lift值(Treatment Comparison Approach),文章使用功第二种方法,基于因果森林算法进行实际分析。整体方法上比较简单,但是文章做了一些深入的可解释性的分析。
使用有两个数据集,也做了一些预处理缺失值填充、去除脏数据等,然后随机抽取70%训练,30%做测试。
- 欧洲在线书店的优惠券数据,包含六种优惠券类型和控制组。
- 美国电子邮件营销促销数据,包含针对男性和女性的促销活动以及控制组
结果分析
ITE效果分析:
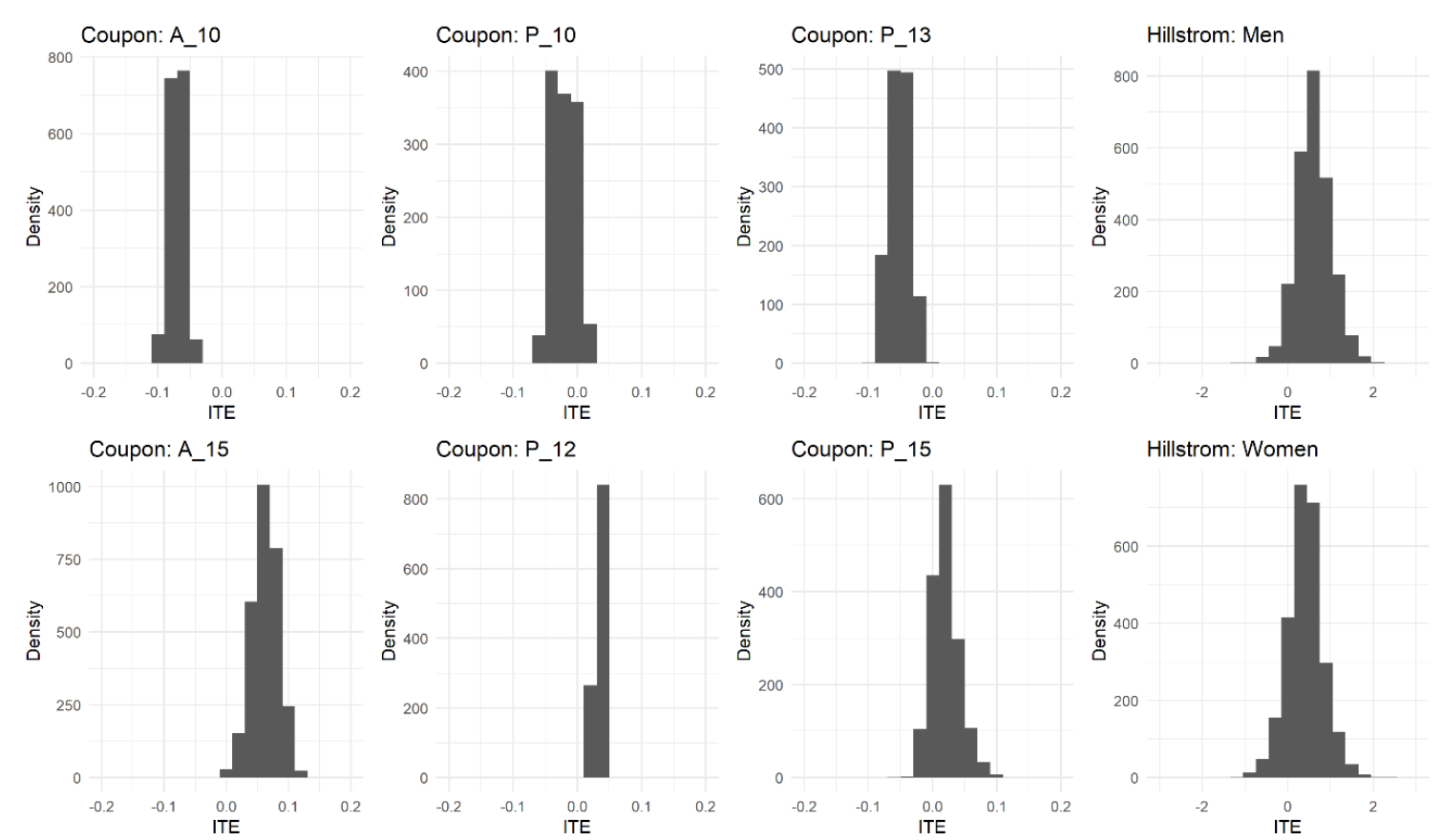
数据集的ITE差异:从不同数据集的优惠券类型和ITE分布来看,优惠券数据的个体处理效应(ITE)分布在 [-0.2, 0.2] 之间,而Hillstrom邮件的数据的 ITE 分布在 [-3, 3] 范围内,邮件的干预效果优于优惠券,有可能是因为不同场景本身增益空间天花板就不一样,因为这里模型方法一样。
干预特征和人群的ITE差异:
- 优惠券数据:10€、10% 和 13% 的优惠券主要有负的估计 ITE,而价值为 15€、12% 和 15% 的优惠券主要有正的 ITE。其中15€的优惠券ITE最高
- 邮件数据:男女人群的干预效果分布没有明显差异,但是女性的峰值ITE高于男性。
特征重要度分析:
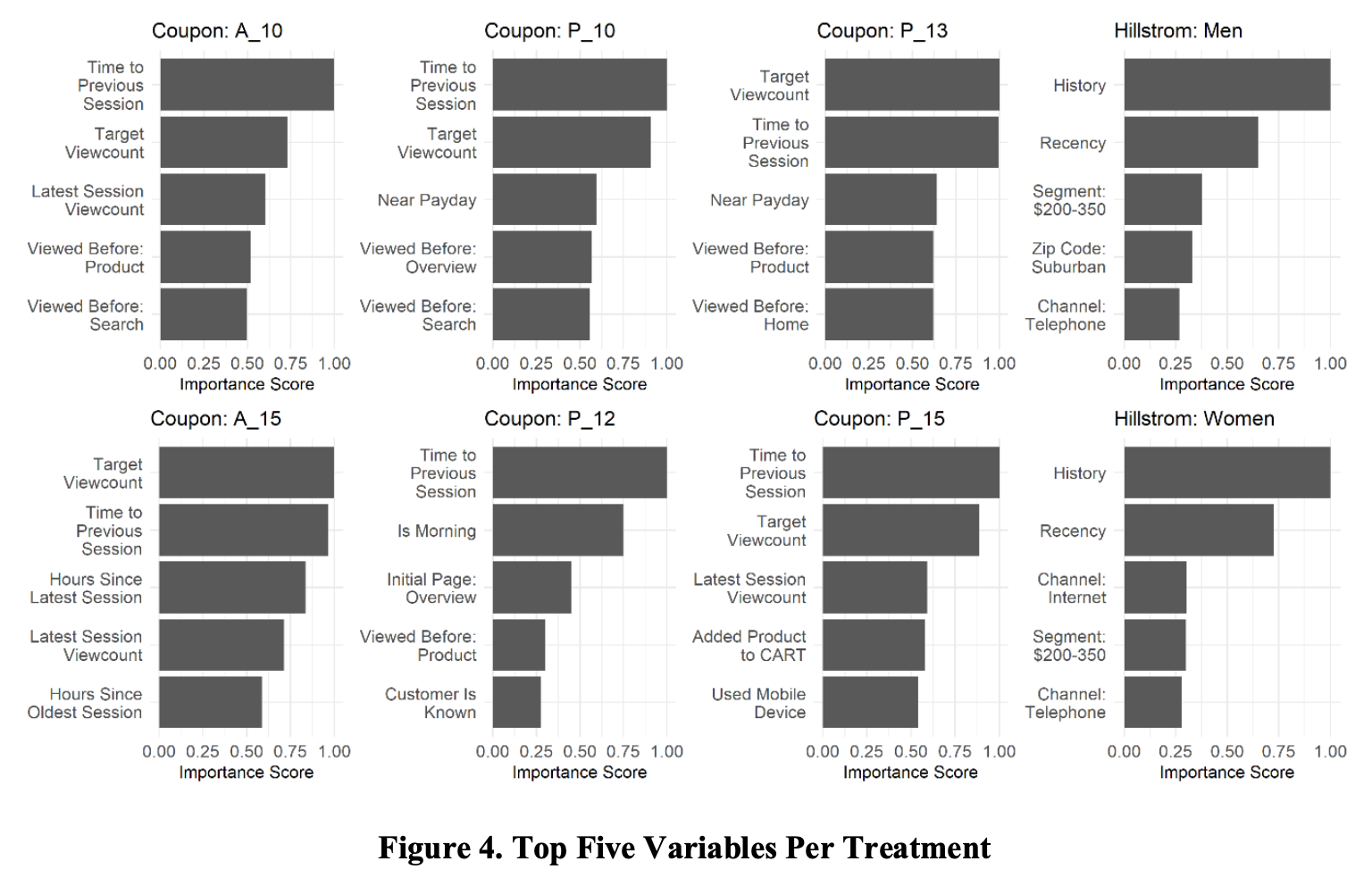
一般像树模型会输出特征重要度,但是如果是响应模型,特征重要度往往反应的是特征对于结果Y的预测重要度,而非实际对于lift值的重要度,因果树会输出基于lift的特征重要度,文章通过'最小-最大缩放法',在上图中展示了每个干预特征的最重要特征。
对于优惠券数据:
- 普遍都重要的特征:当前会话和最近一次会话之间的时间间隔(“到上一会话的时间”)以及当前会话的目标印象频率(“目标浏览量”)在对个干预模型中重要度都很高。
- 个别重要的特征:顾客在店铺不同页面类型(产品、搜索、概述、主页)上的先前浏览量和最近会话中出现次数等也频繁出现;个别变量在某些干预模型中很重要,在12% 优惠券模型中,是否早上访问重要度很高、最新和最老回话间隔在15券很关键,个人感觉有点怪怪的。
对于邮件数据:
- 普遍重要特征:去年的消费金额(“历史”)和自上次购买产品以来的月数(“近期”)。即付费额和付费间隔。
- 个别重要特征:男性像所属郊区、公司电话通信的偏好等影响较大,女性则是是否通过互联网交互。
营销收入结果评估:
通过预测ITE排名,分别将实验组和对照组以十分位法分桶,然后每个十分位内对比对照组和干预组的收入差异。这里注意由于每个十分内对照组和干预组的的记录数不一样,需要进行等比例缩放进行对比。
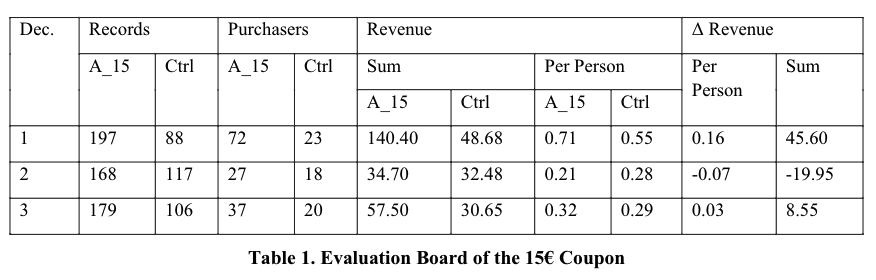
上图是前三个十分位上的收入分析,可以看到1/3分位收入均正向。第2个分位收入是负向的,所以即使模型预测ITE正向,对应的玩家收入仍然负向,低于未干预用户。
由于上面某些分位正向有些负向,看不出累计效果,所以又进行了累计收益的分析,
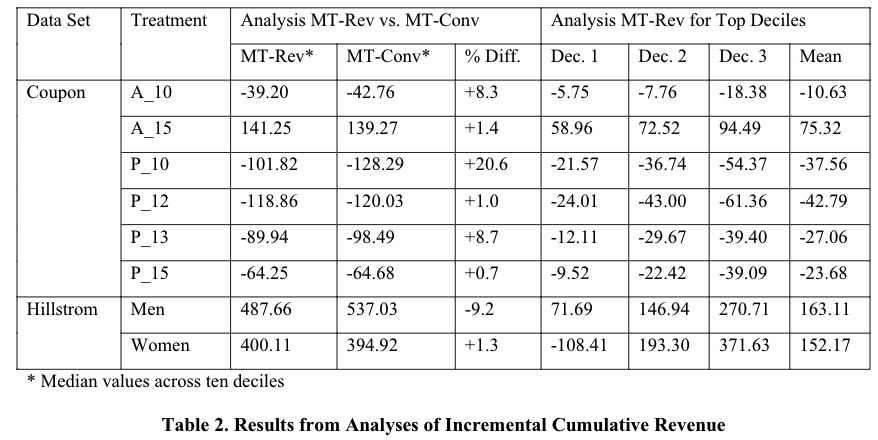
结果可以看到:
- 优惠券数据中,只有15€是正向的收入,看起来该场景式决策是否所有人都发x券,然后分析发了x券与不发券的收益差异,实际场景并不会这样一刀切,可能会针对不同人群下发不同的券值,以期望收益最大化,参考爱彼迎的动态定价的文章。
- 邮件数据中,基本收入都正向,只有女性第一个分位数负向(尬住),在其他分位数上都优于男性。
价格影响折扣感知:从优惠券场景可以看出,低价产品,顾客可能更倾向于绝对折扣(因为低价的绝对折扣对应的优惠比例更高)进而导致不同类型优惠券在收入上存在差异,这也是为什么15€的优惠券收益最好。。这里也可以引申出消费力不同人群在不同折扣上也会存在收入差异。
写到最后,文章通过因果森林的预测结果,分析两个公开数据集上的ITE效果,这里个人感觉ITE的准确性有待考量,实际线上应该可以通过某些方式来获取CATE来比较不同干预措施的效果,比如psm对齐,或者通过寻找镜像人群。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号