【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)

【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)

LDG_AGI
发布于 2024-10-23 08:31:51
发布于 2024-10-23 08:31:51

一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型
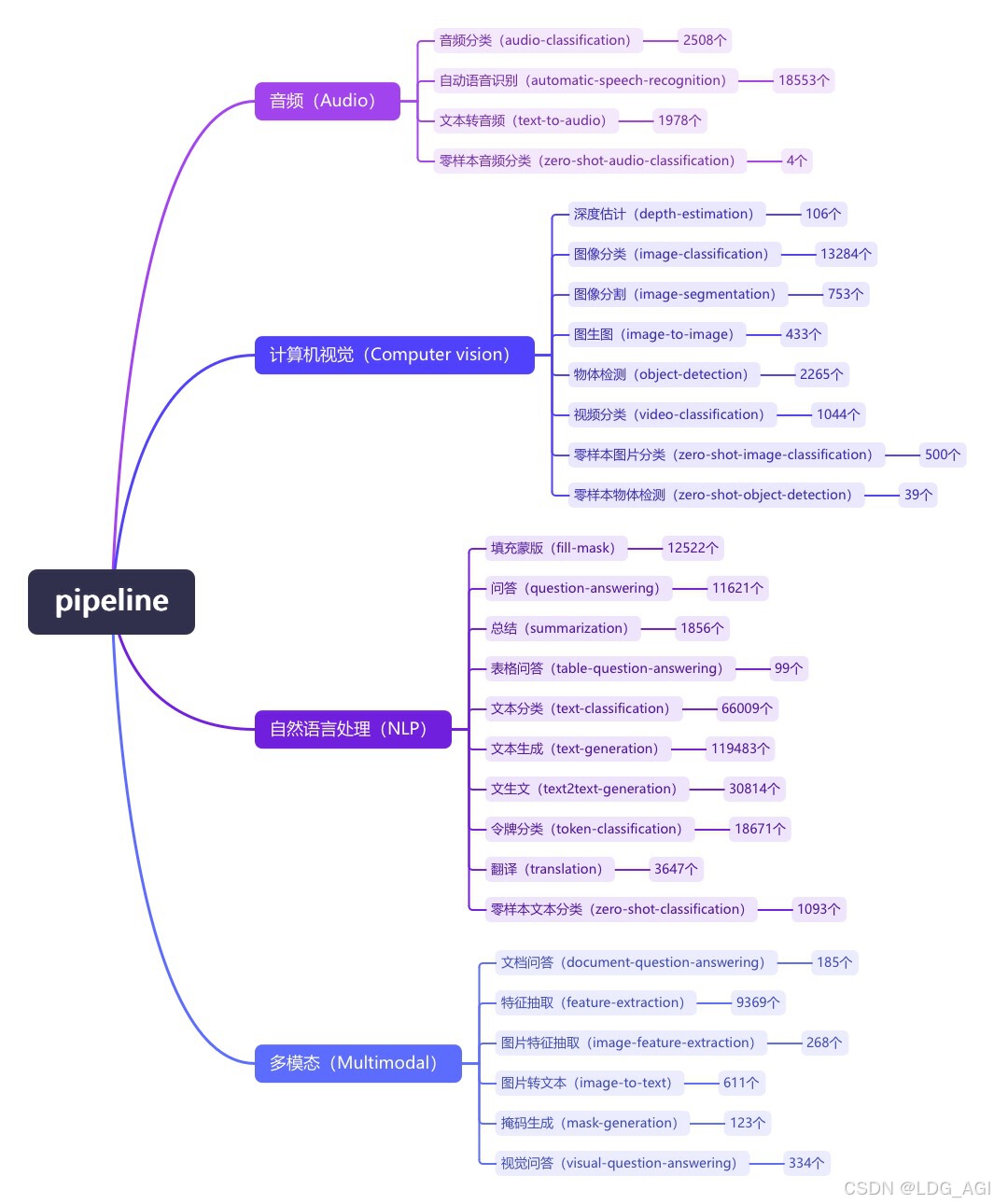
今天介绍NLP自然语言处理的第八篇:令牌分类(token-classification),在huggingface库内有2万个文本生成(text-generation)模型。
二、令牌分类(token-classification)
2.1 概述
标记分类是一种自然语言理解任务,其中为文本中的某些标记分配标签。一些流行的标记分类子任务是命名实体识别 (NER) 和词性 (PoS) 标记。可以训练 NER 模型来识别文本中的特定实体,例如日期、个人和地点;而 PoS 标记可以识别文本中的哪些词是动词、名词和标点符号。
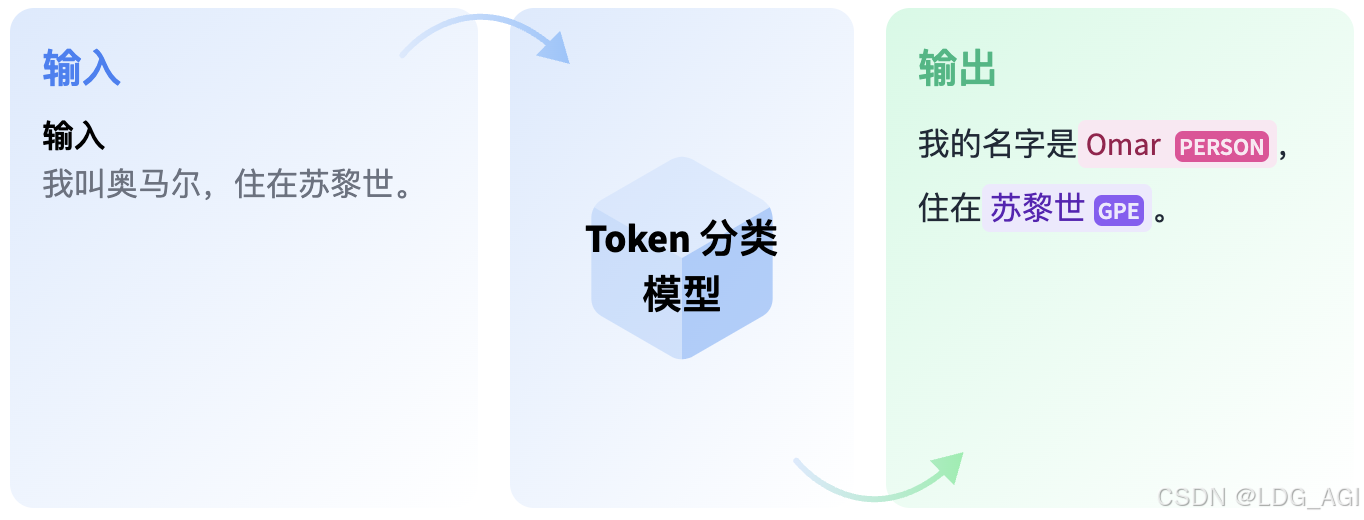
2.2 Facebook AI/XLM-RoBERTa
XLM-RoBERTa 是 RoBERTa 的多语言版本。它已在包含 100 种语言的 2.5TB 经过筛选的 CommonCrawl 数据上进行了预训练。
RoBERTa 是一个以自监督方式在大型语料库上进行预训练的 transformers 模型。这意味着它只在原始文本上进行预训练,没有任何人工标记(这就是它可以使用大量公开数据的原因),并有一个自动流程从这些文本中生成输入和标签。
更准确地说,它是使用掩码语言建模 (MLM) 目标进行预训练的。以一个句子为例,该模型随机屏蔽输入中的 15% 的单词,然后通过模型运行整个被屏蔽的句子,并必须预测被屏蔽的单词。这与通常一个接一个地看到单词的传统循环神经网络 (RNN) 或内部屏蔽未来标记的 GPT 等自回归模型不同。它允许模型学习句子的双向表示。
通过这种方式,模型可以学习 100 种语言的内部表征,然后可以使用这些表征提取对下游任务有用的特征:例如,如果您有一个带标签的句子数据集,则可以使用 XLM-RoBERTa 模型生成的特征作为输入来训练标准分类器。
2.3 pipeline参数
2.3.1 pipeline对象实例化参数
- model(PreTrainedModel或TFPreTrainedModel)— 管道将使用其进行预测的模型。 对于 PyTorch,这需要从PreTrainedModel继承;对于 TensorFlow,这需要从TFPreTrainedModel继承。
- tokenizer ( PreTrainedTokenizer ) — 管道将使用其对模型的数据进行编码的 tokenizer。此对象继承自 PreTrainedTokenizer。
- modelcard(
str或ModelCard,可选) — 属于此管道模型的模型卡。 - framework(
str,可选)— 要使用的框架,"pt"适用于 PyTorch 或"tf"TensorFlow。必须安装指定的框架。 如果未指定框架,则默认为当前安装的框架。如果未指定框架且安装了两个框架,则默认为 的框架model,如果未提供模型,则默认为 PyTorch。 - task(
str,默认为"")— 管道的任务标识符。 - num_workers(
int,可选,默认为 8)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的工作者数量。 - batch_size(
int,可选,默认为 1)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的批次的大小,对于推理来说,这并不总是有益的,请阅读使用管道进行批处理。 - args_parser(ArgumentHandler,可选) - 引用负责解析提供的管道参数的对象。
- device(
int,可选,默认为 -1)— CPU/GPU 支持的设备序号。将其设置为 -1 将利用 CPU,设置为正数将在关联的 CUDA 设备 ID 上运行模型。您可以传递本机torch.device或str太 - torch_dtype(
str或torch.dtype,可选) - 直接发送model_kwargs(只是一种更简单的快捷方式)以使用此模型的可用精度(torch.float16,,torch.bfloat16...或"auto") - binary_output(
bool,可选,默认为False)——标志指示管道的输出是否应以序列化格式(即 pickle)或原始输出数据(例如文本)进行。 - ignore_labels(
List[str],默认为["O"])— 要忽略的标签列表。 - grouped_entities (
bool,可选,默认为False) — 已弃用,请使用aggregation_strategy。是否在预测中将与同一实体相对应的标记分组在一起。 - stride(
int,可选)— 如果提供了 stride,则管道将应用于所有文本。文本被拆分为大小为 model_max_length 的块。仅适用于快速标记器,与aggregation_strategy不同NONE。此参数的值定义块之间重叠标记的数量。换句话说,模型将tokenizer.model_max_length - stride每一步向前移动标记。 - aggregation_strategy(
str,可选,默认为"none")—根据模型预测融合(或不融合)标记的策略。- “none” :不会进行任何聚合,仅返回模型的原始结果
- “simple” :将尝试按照默认模式对实体进行分组。 (A, B-TAG), (B, I-TAG), (C, I-TAG), (D, B-TAG2) (E, B-TAG2) 最终将变为 [{“word”: ABC, “entity”: “TAG”}, {“word”: “D”, “entity”: “TAG2”}, {“word”: “E”, “entity”: “TAG2”}] 请注意,两个连续的 B 标签最终将成为不同的实体。 在基于单词的语言中,我们可能会不合需要地拆分单词:想象一下 Microsoft 被标记为 [{“word”: “Micro”, “entity”: “ENTERPRISE”}, {“word”: “soft”, “entity”: “NAME”}]。 寻找 FIRST、MAX、AVERAGE 来缓解这种情况并消除单词歧义(在支持该含义的语言上,基本上是用空格分隔的标记)。这些缓解措施只对真实的词语起作用,“纽约”可能仍然被标记为两个不同的实体。
- “first” :(仅适用于基于单词的模型)将使用
SIMPLE除了单词之外的策略,不能以不同的标签结尾。当存在歧义时,单词将简单地使用单词的第一个标记的标签。 - “average” :(仅适用于基于单词的模型)将使用
SIMPLE除单词之外的策略,不能以不同的标签结束。分数将首先在标记之间取平均值,然后应用最大标签。 - “max” :(仅适用于基于单词的模型)将使用
SIMPLE除单词之外的策略,不能以不同的标签结尾。单词实体将只是具有最高分数的标记。
2.3.2 pipeline对象使用参数
- text_inputs(
str,List[str],List[Dict[str, str]],或List[List[Dict[str, str]]])— 需要完成的一个或多个提示(或一个提示列表)。如果传递了字符串或字符串列表,则此管道将继续每个提示。或者,可以传递“聊天”(以带有“role”和“content”键的字典列表的形式),或传递此类聊天的列表。传递聊天时,将使用模型的聊天模板对其进行格式化,然后再将其传递给模型。 - return_tensors (
bool,可选,默认为False) — 是否在输出中返回预测的张量(作为标记索引)。如果设置为True,则不返回解码后的文本。 - return_text(
bool,可选,默认为True)— 是否在输出中返回解码后的文本。 - return_full_text(
bool,可选,默认为True)— 如果设置为,False则仅返回添加的文本,否则返回全文。仅当 return_text设置为 True 时才有意义。 - clean_up_tokenization_spaces(
bool,可选,默认为True)—是否清理文本输出中可能出现的额外空格。 - prefix(
str,可选)— 添加到提示的前缀。 - handle_long_generation(
str,可选)— 默认情况下,此管道不处理长生成(以某种形式超出模型最大长度的生成)。 - generate_kwargs(
dict,可选)——传递给模型的生成方法的附加关键字参数(请参阅此处与您的框架相对应的生成方法)。
2.3.3 pipeline返回参数
- word (
str) — 分类的标记/单词。这是通过解码选定的标记获得的。如果您想要获得原始句子中的精确字符串,请使用start和end。 - score(
float)—— 的对应概率entity。 - entity (
str) — 为该标记/单词预测的实体(当 aggregation_strategy不是时,它被命名为entity_group)。"none" - index(
int,仅当存在时aggregation_strategy="none")——句子中对应标记的索引。 - start(
int,可选)— 句子中相应实体的起始索引。仅当标记器中的偏移量可用时才存在 - end(
int,可选)— 句子中相应实体的结尾索引。仅当标记器中的偏移量可用时才存在
2.4 pipeline实战
基于pipeline的token-classification任务,使用FacebookAI/xlm-roberta模型:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
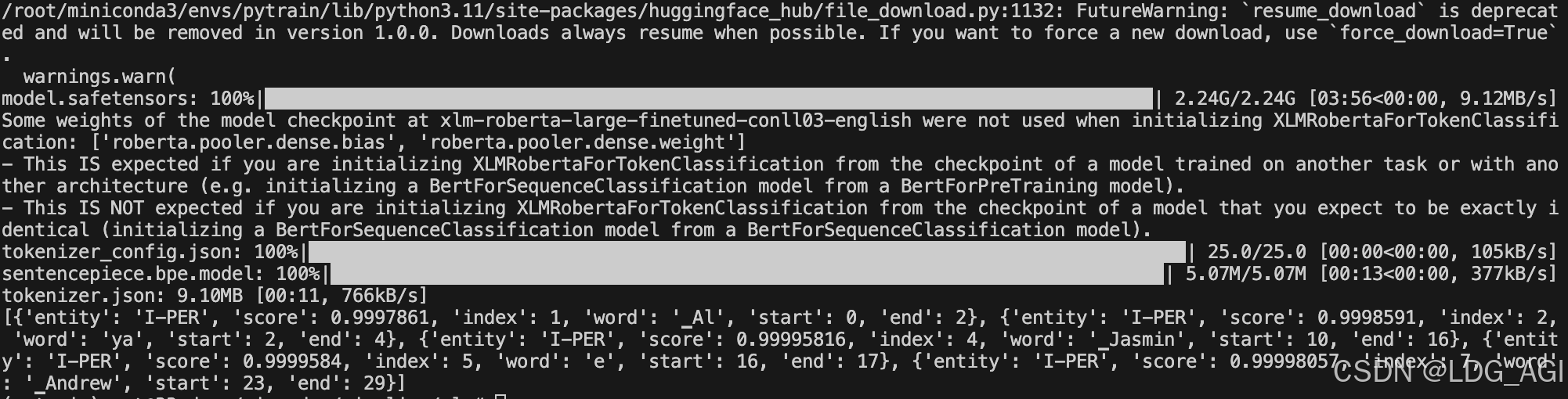
classifier = pipeline("ner", model= "xlm-roberta-large-finetuned-conll03-english" )
output=classifier("Alya told Jasmine that Andrew could pay with cash..")
print(output)执行后,自动下载模型文件并进行识别:
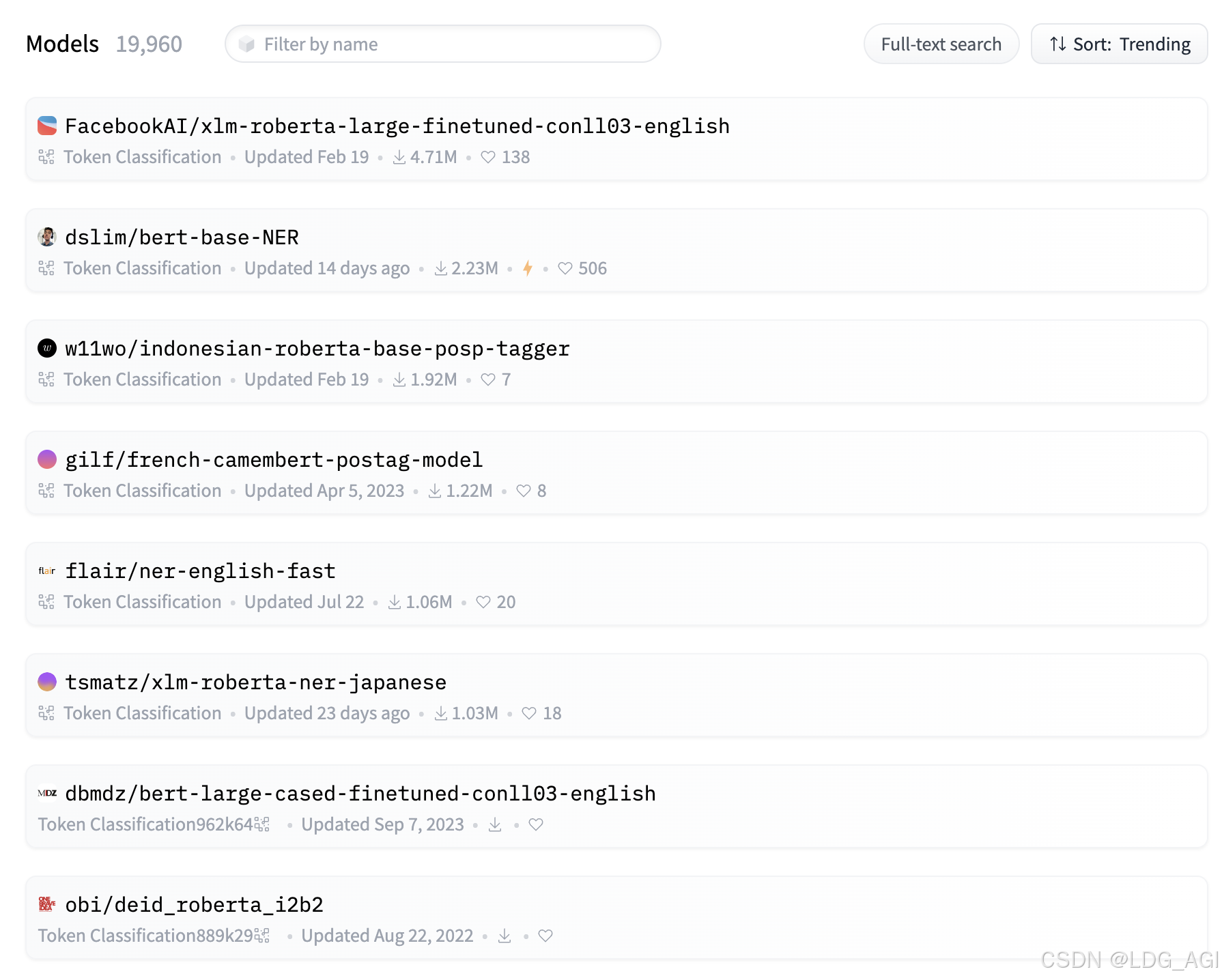
2.5 模型排名
在huggingface上,我们将令牌分类(token-classification)模型按下载量从高到低排序,总计2万个模型,文中FacebookAI的xlm-roberta排名第一。
三、总结
本文对transformers之pipeline的令牌分类(token-classification)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用NLP中的令牌分类(token-classification)模型。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-10-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号