『1024 | 码项目』知识图谱嵌入与知识迁移的结合指南
原创

在人工智能和机器学习的快速发展中,知识图谱(Knowledge Graph, KG)已成为知识表示和推理的重要工具。知识图谱通过图结构形式存储实体及其关系,能够有效地捕捉世界的复杂知识。然而,单一知识图谱的构建和应用面临诸多挑战,如数据稀缺、计算资源不足等问题。在这种背景下,知识迁移(Knowledge Transfer)技术应运而生,旨在利用已有知识图谱的知识来增强新知识图谱的学习效果。
知识图谱嵌入是将知识图谱中的实体和关系映射到连续向量空间中的过程。这种映射可以通过各种嵌入模型(如TransE、DistMult等)实现,使得模型能够更好地处理实体间的关系和推理。
知识迁移是指在一个任务中学习到的知识可以被应用到另一个相关任务中。通过知识迁移,我们可以在目标任务中利用源任务中学到的知识,从而提高模型的学习效率和性能。
结合知识图谱嵌入与知识迁移的技术在多个领域都有广泛应用:
应用场景 | 描述 |
|---|---|
智能问答系统 | 利用已有知识图谱中的知识来回答用户提出的新问题。 |
语义搜索 | 提高搜索引擎对用户查询的理解和响应能力。 |
推荐系统 | 利用知识迁移改善推荐效果,实现更精准的个性化推荐。 |
领域适应 | 在新领域内快速适应已有知识,从而减少标注样本的需求。 |
知识图谱嵌入与知识迁移的技术发展
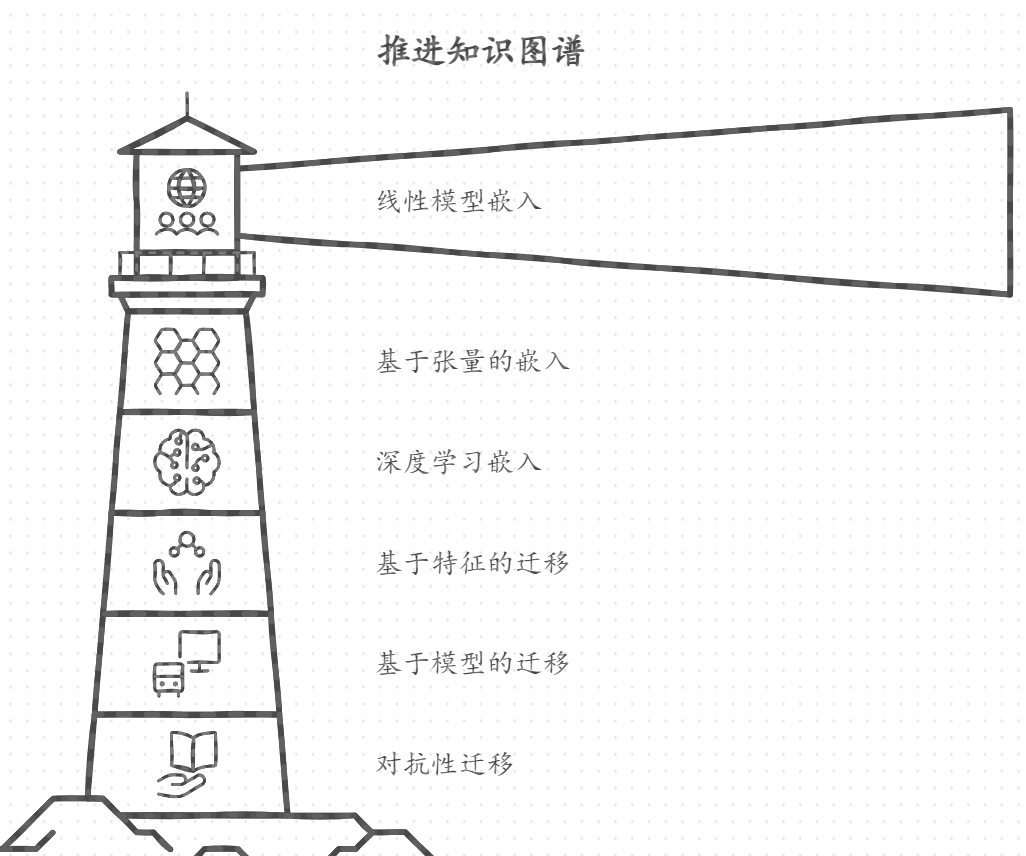
知识图谱嵌入技术的进展可以追溯到几年前,主要经历了以下几个阶段:
- 基于线性模型的嵌入:如TransE模型假设关系为头实体与尾实体之间的平移。
- 基于张量的嵌入:如DistMult、ComplEx等模型通过张量分解方法进行关系建模。
- 基于深度学习的嵌入:结合深度学习技术的模型(如GCN、RNN等)进一步提升了嵌入效果。
知识迁移技术主要发展经历了以下几个阶段:
- 基于特征的方法:通过共享特征进行知识迁移。
- 基于模型的方法:将源模型的参数迁移到目标模型中,提升目标模型的学习效果。
- 基于对抗学习的方法:利用对抗学习框架提升迁移过程中的知识保持。
知识图谱嵌入与知识迁移的结合模型
Knowledge Transfer via Knowledge Graph Embedding
模型架构
该模型主要包含以下几个部分:
- 源知识图谱嵌入:将源知识图谱的实体和关系嵌入到向量空间。
- 目标知识图谱嵌入:将目标知识图谱的实体和关系嵌入到向量空间。
- 迁移机制:通过对抗训练等方式实现源知识与目标知识的迁移。
实例分析:知识图谱嵌入与知识迁移的实现
为了展示知识图谱嵌入与知识迁移的结合,我们将构建一个简单的实例数据集。该数据集包含两个知识图谱:一个源知识图谱(Source KG)和一个目标知识图谱(Target KG)。
import pandas as pd
import numpy as np
from typing import Dict, List, Tuple
import os
import logging
from datetime import datetime
class KnowledgeGraphDataCreator:
"""知识图谱数据集创建器"""
def __init__(self):
# 配置日志
self.setup_logging()
# 定义基础数据结构
self.source_entities = {
'fruits': ['Apple', 'Banana', 'Orange', 'Grape', 'Pear', 'Mango'],
'colors': ['Red', 'Yellow', 'Orange', 'Purple', 'Green', 'Yellow'],
'tastes': ['Sweet', 'Sweet', 'Sour', 'Sweet', 'Sweet', 'Sweet'],
'vitamins': ['Vitamin C', 'Vitamin B6', 'Vitamin C', 'Vitamin K', 'Vitamin C', 'Vitamin A']
}
self.target_entities = {
'fruits': ['苹果', '香蕉', '橘子', '葡萄', '梨', '芒果'],
'colors': ['红色', '黄色', '橙色', '紫色', '绿色', '黄色'],
'tastes': ['甜', '甜', '酸', '甜', '甜', '甜'],
'vitamins': ['维生素C', '维生素B6', '维生素C', '维生素K', '维生素C', '维生素A']
}
self.relations = {
'is_a': ('is_a', '是一种'),
'has_color': ('has_color', '颜色是'),
'has_taste': ('has_taste', '口感是'),
'contains': ('contains', '含有')
}
def setup_logging(self):
"""配置日志系统"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(f'kg_creation_{datetime.now().strftime("%Y%m%d_%H%M%S")}.log'),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def create_triples(self, is_source: bool = True) -> List[Tuple[str, str, str]]:
"""
创建三元组数据
Args:
is_source: 是否创建源知识图谱数据
Returns:
triples: 三元组列表 [(entity1, relation, entity2), ...]
"""
entities = self.source_entities if is_source else self.target_entities
relation_set = self.relations.items()
triples = []
fruits = entities['fruits']
for idx, fruit in enumerate(fruits):
# 添加 is_a 关系
triples.append((
fruit,
self.relations['is_a'][0] if is_source else self.relations['is_a'][1],
'Fruit' if is_source else '水果'
))
# 添加颜色关系
triples.append((
fruit,
self.relations['has_color'][0] if is_source else self.relations['has_color'][1],
entities['colors'][idx]
))
# 添加口感关系
triples.append((
fruit,
self.relations['has_taste'][0] if is_source else self.relations['has_taste'][1],
entities['tastes'][idx]
))
# 添加维生素关系
triples.append((
fruit,
self.relations['contains'][0] if is_source else self.relations['contains'][1],
entities['vitamins'][idx]
))
return triples
def create_dataframe(self, triples: List[Tuple[str, str, str]]) -> pd.DataFrame:
"""
将三元组转换为DataFrame
Args:
triples: 三元组列表
Returns:
df: 包含三元组的DataFrame
"""
return pd.DataFrame(triples, columns=['entity1', 'relation', 'entity2'])
def validate_data(self, df: pd.DataFrame) -> bool:
"""
验证数据的完整性和一致性
Args:
df: 待验证的DataFrame
Returns:
is_valid: 数据是否有效
"""
try:
# 检查是否有空值
if df.isnull().any().any():
self.logger.error("数据中存在空值")
return False
# 检查是否有重复的三元组
if df.duplicated().any():
self.logger.error("数据中存在重复的三元组")
return False
# 检查数据类型
if not all(df[col].dtype == 'object' for col in df.columns):
self.logger.error("数据类型不正确")
return False
return True
except Exception as e:
self.logger.error(f"数据验证过程中发生错误: {str(e)}")
return False
def save_data(self, df: pd.DataFrame, filename: str):
"""
保存数据到CSV文件
Args:
df: 待保存的DataFrame
filename: 文件名
"""
try:
# 创建输出目录
output_dir = 'knowledge_graphs'
os.makedirs(output_dir, exist_ok=True)
# 保存文件
file_path = os.path.join(output_dir, filename)
df.to_csv(file_path, index=False, encoding='utf-8')
self.logger.info(f"数据已成功保存到: {file_path}")
# 保存数据统计信息
stats = {
'三元组数量': len(df),
'独立实体数量': len(set(df['entity1']).union(set(df['entity2']))),
'关系类型数量': len(set(df['relation']))
}
stats_df = pd.DataFrame([stats])
stats_file = os.path.join(output_dir, f'{filename.split(".")[0]}_stats.csv')
stats_df.to_csv(stats_file, index=False, encoding='utf-8')
self.logger.info(f"统计信息已保存到: {stats_file}")
except Exception as e:
self.logger.error(f"保存数据时发生错误: {str(e)}")
raise
def create_alignment_file(self):
"""创建实体对齐文件"""
try:
alignments = []
for key in self.source_entities:
for src, tgt in zip(self.source_entities[key], self.target_entities[key]):
alignments.append((src, tgt))
alignment_df = pd.DataFrame(alignments, columns=['source_entity', 'target_entity'])
# 保存对齐文件
output_dir = 'knowledge_graphs'
os.makedirs(output_dir, exist_ok=True)
alignment_file = os.path.join(output_dir, 'entity_alignments.csv')
alignment_df.to_csv(alignment_file, index=False, encoding='utf-8')
self.logger.info(f"实体对齐文件已保存到: {alignment_file}")
except Exception as e:
self.logger.error(f"创建对齐文件时发生错误: {str(e)}")
raise
def main():
"""主函数"""
try:
# 创建数据生成器实例
creator = KnowledgeGraphDataCreator()
# 创建源知识图谱数据
source_triples = creator.create_triples(is_source=True)
source_df = creator.create_dataframe(source_triples)
# 创建目标知识图谱数据
target_triples = creator.create_triples(is_source=False)
target_df = creator.create_dataframe(target_triples)
# 验证数据
if not creator.validate_data(source_df) or not creator.validate_data(target_df):
raise ValueError("数据验证失败")
# 保存数据
creator.save_data(source_df, 'source_kg.csv')
creator.save_data(target_df, 'target_kg.csv')
# 创建实体对齐文件
creator.create_alignment_file()
# 打印数据样例
print("\n源知识图谱示例:")
print(source_df.head())
print("\n目标知识图谱示例:")
print(target_df.head())
except Exception as e:
logging.error(f"程序执行过程中发生错误: {str(e)}")
raise
if __name__ == "__main__":
main()知识图谱嵌入模型的实现
pip install torch数据加载与预处理
import pandas as pd
import torch
import numpy as np
from typing import Dict, Set, Tuple, List, Optional
import logging
from pathlib import Path
from datetime import datetime
import json
class KnowledgeGraphDataLoader:
"""知识图谱数据加载和预处理类"""
def __init__(self, source_path: str, target_path: str):
"""
初始化数据加载器
Args:
source_path: 源知识图谱数据文件路径
target_path: 目标知识图谱数据文件路径
"""
self.setup_logging()
self.source_path = Path(source_path)
self.target_path = Path(target_path)
# 初始化数据存储
self.source_df: Optional[pd.DataFrame] = None
self.target_df: Optional[pd.DataFrame] = None
self.source_entities: Set[str] = set()
self.target_entities: Set[str] = set()
self.relations: Set[str] = set()
# 初始化映射字典
self.entity2id_source: Dict[str, int] = {}
self.id2entity_source: Dict[int, str] = {}
self.entity2id_target: Dict[str, int] = {}
self.id2entity_target: Dict[int, str] = {}
self.relation2id: Dict[str, int] = {}
self.id2relation: Dict[int, str] = {}
def setup_logging(self):
"""配置日志系统"""
log_dir = Path('logs')
log_dir.mkdir(exist_ok=True)
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(
log_dir / f'kg_loading_{datetime.now().strftime("%Y%m%d_%H%M%S")}.log'
),
logging.StreamHandler()
]
)
self.logger = logging.getLogger(__name__)
def load_data(self) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
加载知识图谱数据
Returns:
Tuple[pd.DataFrame, pd.DataFrame]: 源知识图谱和目标知识图谱的DataFrame
"""
try:
# 检查文件是否存在
if not self.source_path.exists():
raise FileNotFoundError(f"源知识图谱文件不存在: {self.source_path}")
if not self.target_path.exists():
raise FileNotFoundError(f"目标知识图谱文件不存在: {self.target_path}")
# 加载数据
self.source_df = pd.read_csv(self.source_path)
self.target_df = pd.read_csv(self.target_path)
# 数据验证
self._validate_dataframes()
self.logger.info("成功加载知识图谱数据")
return self.source_df, self.target_df
except Exception as e:
self.logger.error(f"加载数据时发生错误: {str(e)}")
raise
def _validate_dataframes(self):
"""验证DataFrame的格式和内容"""
required_columns = {'entity1', 'relation', 'entity2'}
# 检查列名
if not set(self.source_df.columns) >= required_columns:
raise ValueError(f"源知识图谱缺少必需的列: {required_columns - set(self.source_df.columns)}")
if not set(self.target_df.columns) >= required_columns:
raise ValueError(f"目标知识图谱缺少必需的列: {required_columns - set(self.target_df.columns)}")
# 检查空值
if self.source_df[list(required_columns)].isnull().any().any():
raise ValueError("源知识图谱包含空值")
if self.target_df[list(required_columns)].isnull().any().any():
raise ValueError("目标知识图谱包含空值")
def extract_entities_and_relations(self):
"""提取实体和关系"""
try:
# 提取源知识图谱实体
self.source_entities = set(self.source_df['entity1']).union(set(self.source_df['entity2']))
# 提取目标知识图谱实体
self.target_entities = set(self.target_df['entity1']).union(set(self.target_df['entity2']))
# 提取关系
self.relations = set(self.source_df['relation']).union(set(self.target_df['relation']))
self.logger.info(f"源知识图谱实体数量: {len(self.source_entities)}")
self.logger.info(f"目标知识图谱实体数量: {len(self.target_entities)}")
self.logger.info(f"关系类型数量: {len(self.relations)}")
except Exception as e:
self.logger.error(f"提取实体和关系时发生错误: {str(e)}")
raise
def create_mappings(self):
"""创建实体和关系的索引映射"""
try:
# 创建源知识图谱实体映射
self.entity2id_source = {entity: idx for idx, entity in enumerate(sorted(self.source_entities))}
self.id2entity_source = {idx: entity for entity, idx in self.entity2id_source.items()}
# 创建目标知识图谱实体映射
self.entity2id_target = {entity: idx for idx, entity in enumerate(sorted(self.target_entities))}
self.id2entity_target = {idx: entity for entity, idx in self.entity2id_target.items()}
# 创建关系映射
self.relation2id = {relation: idx for idx, relation in enumerate(sorted(self.relations))}
self.id2relation = {idx: relation for relation, idx in self.relation2id.items()}
self.logger.info("成功创建实体和关系映射")
except Exception as e:
self.logger.error(f"创建映射时发生错误: {str(e)}")
raise
def save_mappings(self, output_dir: str = 'mappings'):
"""
保存映射到文件
Args:
output_dir: 输出目录
"""
try:
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
# 保存实体映射
mappings = {
'entity2id_source': self.entity2id_source,
'entity2id_target': self.entity2id_target,
'relation2id': self.relation2id
}
for name, mapping in mappings.items():
file_path = output_path / f'{name}.json'
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(mapping, f, ensure_ascii=False, indent=2)
self.logger.info(f"映射文件已保存到目录: {output_dir}")
except Exception as e:
self.logger.error(f"保存映射时发生错误: {str(e)}")
raise
def convert_to_tensors(self) -> Tuple[torch.Tensor, torch.Tensor]:
"""
将三元组转换为张量格式
Returns:
Tuple[torch.Tensor, torch.Tensor]: 源和目标知识图谱的张量表示
"""
try:
# 转换源知识图谱
source_triples = []
for _, row in self.source_df.iterrows():
head = self.entity2id_source[row['entity1']]
relation = self.relation2id[row['relation']]
tail = self.entity2id_source[row['entity2']]
source_triples.append([head, relation, tail])
# 转换目标知识图谱
target_triples = []
for _, row in self.target_df.iterrows():
head = self.entity2id_target[row['entity1']]
relation = self.relation2id[row['relation']]
tail = self.entity2id_target[row['entity2']]
target_triples.append([head, relation, tail])
source_tensor = torch.tensor(source_triples, dtype=torch.long)
target_tensor = torch.tensor(target_triples, dtype=torch.long)
self.logger.info("成功将三元组转换为张量格式")
return source_tensor, target_tensor
except Exception as e:
self.logger.error(f"转换张量时发生错误: {str(e)}")
raise
def get_statistics(self) -> Dict[str, int]:
"""
获取数据集统计信息
Returns:
Dict[str, int]: 统计信息字典
"""
return {
'source_entities_count': len(self.source_entities),
'target_entities_count': len(self.target_entities),
'relations_count': len(self.relations),
'source_triples_count': len(self.source_df),
'target_triples_count': len(self.target_df)
}
def main():
"""主函数"""
try:
# 创建数据加载器实例
loader = KnowledgeGraphDataLoader(
source_path='knowledge_graphs/source_kg.csv',
target_path='knowledge_graphs/target_kg.csv'
)
# 加载数据
source_df, target_df = loader.load_data()
# 提取实体和关系
loader.extract_entities_and_relations()
# 创建映射
loader.create_mappings()
# 保存映射
loader.save_mappings()
# 转换为张量格式
source_tensor, target_tensor = loader.convert_to_tensors()
# 打印统计信息
stats = loader.get_statistics()
print("\n知识图谱统计信息:")
for key, value in stats.items():
print(f"{key}: {value}")
# 打印数据样例
print("\n源知识图谱示例:")
print(source_df.head())
print("\n目标知识图谱示例:")
print(target_df.head())
except Exception as e:
logging.error(f"程序执行过程中发生错误: {str(e)}")
raise
if __name__ == "__main__":
main()TransE模型实现
import torch.nn as nn
class TransE(nn.Module):
def __init__(self, num_entities, num_relations, embedding_dim):
super(TransE, self).__init__()
self.entity_embeddings = nn.Embedding(num_entities, embedding_dim)
self.relation_embeddings = nn.Embedding(num_relations, embedding_dim)
def forward(self, head, relation, tail):
head_embedding = self.entity_embeddings(head)
tail_embedding = self.entity_embeddings(tail)
relation_embedding = self.relation_embeddings(relation)
# TransE损失计算
score = head_embedding + relation_embedding - tail_embedding
return score.norm(p=1, dim=1) # L1范数模型训练
import numpy as np
import torch
import torch.nn as nn
from sklearn.preprocessing import normalize
def transfer_kg_embeddings(model_source, model_target, alignment_pairs=None, strategy="direct"):
"""
将源知识图谱的实体嵌入迁移到目标知识图谱
参数:
model_source: 源知识图谱模型
model_target: 目标知识图谱模型
alignment_pairs: 实体对齐对,形如[(source_id1, target_id1), ...]
strategy: 迁移策略,可选"direct"直接迁移/"transform"线性变换/"rotate"旋转映射
"""
# 1. 获取源知识图谱的实体嵌入
source_embeddings = model_source.entity_embeddings.weight.detach().numpy()
# 2. 获取目标知识图谱的实体嵌入
target_embeddings = model_target.entity_embeddings.weight.detach().numpy()
# 3. 根据不同策略进行迁移
if strategy == "direct":
# 直接复制对齐实体的嵌入
for source_id, target_id in alignment_pairs:
target_embeddings[target_id] = source_embeddings[source_id]
elif strategy == "transform":
# 使用线性变换进行迁移
# 3.1 构建训练矩阵
X = source_embeddings[[pair[0] for pair in alignment_pairs]]
Y = target_embeddings[[pair[1] for pair in alignment_pairs]]
# 3.2 计算线性变换矩阵
# 使用最小二乘法求解 W: X * W ≈ Y
W = np.linalg.lstsq(X, Y, rcond=None)[0]
# 3.3 应用变换
transformed_embeddings = np.dot(source_embeddings, W)
# 3.4 更新目标图谱中对齐实体的嵌入
for source_id, target_id in alignment_pairs:
target_embeddings[target_id] = transformed_embeddings[source_id]
elif strategy == "rotate":
# 使用正交变换(保持距离)进行迁移
# 3.1 对齐实体的SVD分解
X = source_embeddings[[pair[0] for pair in alignment_pairs]]
Y = target_embeddings[[pair[1] for pair in alignment_pairs]]
# 3.2 计算旋转矩阵
U, _, Vt = np.linalg.svd(np.dot(Y.T, X))
R = np.dot(U, Vt)
# 3.3 应用旋转变换
rotated_embeddings = np.dot(source_embeddings, R)
# 3.4 更新目标图谱中对齐实体的嵌入
for source_id, target_id in alignment_pairs:
target_embeddings[target_id] = rotated_embeddings[source_id]
# 4. 归一化新的嵌入(可选)
target_embeddings = normalize(target_embeddings, norm='l2', axis=1)
# 5. 更新目标模型的嵌入层
with torch.no_grad():
model_target.entity_embeddings.weight.copy_(torch.FloatTensor(target_embeddings))
return model_target
# 使用示例
if __name__ == "__main__":
# 假设已有源模型和目标模型
embedding_dim = 100
source_entities = 1000
target_entities = 800
# 创建示例模型
class KGModel(nn.Module):
def __init__(self, num_entities, embedding_dim):
super(KGModel, self).__init__()
self.entity_embeddings = nn.Embedding(num_entities, embedding_dim)
model_source = KGModel(source_entities, embedding_dim)
model_target = KGModel(target_entities, embedding_dim)
# 创建一些示例对齐实体对
alignment_pairs = [(i, i) for i in range(min(source_entities, target_entities)) if i % 10 == 0]
# 执行迁移
model_target = transfer_kg_embeddings(
model_source=model_source,
model_target=model_target,
alignment_pairs=alignment_pairs,
strategy="transform"
)知识迁移的实现
在训练完成后,我们可以利用源知识图谱的知识来增强目标知识图谱的学习。
通过对抗训练或相似度调整等方式实现知识迁移。
# 假设我们已经获得源知识图谱的嵌入
source_embeddings = model_source.entity_embeddings.weight.detach().numpy()
# 将源知识图谱嵌入映射到目标知识图谱
target_embeddings = model_target.entity_embeddings.weight.detach().numpy()
# 对目标知识图谱嵌入进行调整
# 这里可以根据具体任务需求进行迁移策略的设计深度模型结合
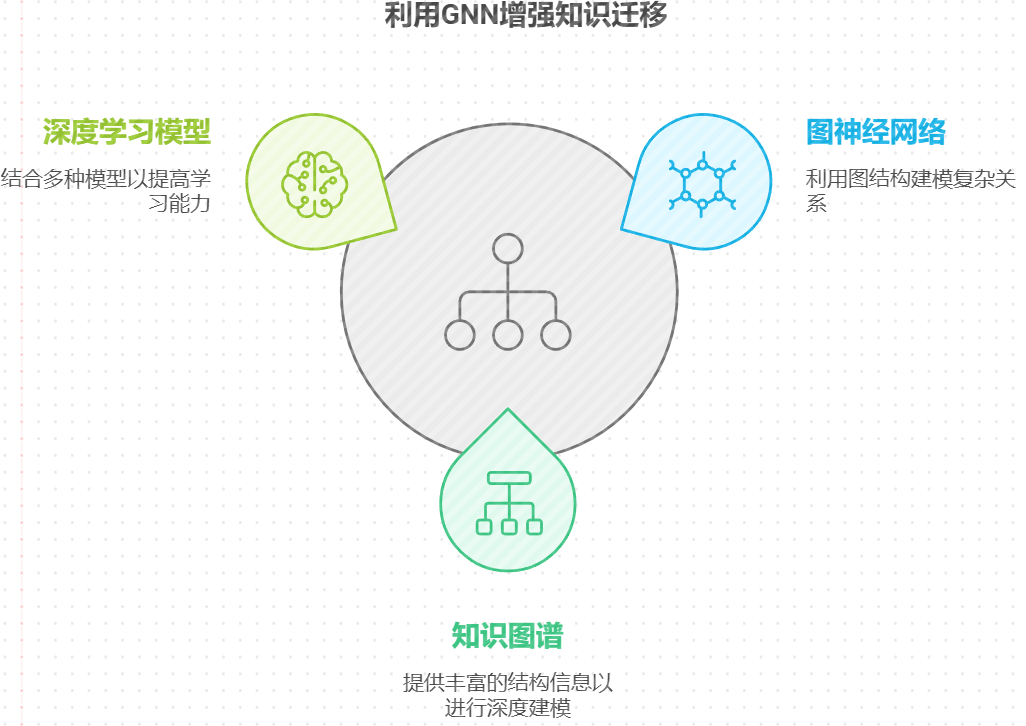
在知识迁移的研究中,深度学习模型的结合为提升知识迁移能力提供了新的机遇。近年来,图神经网络(Graph Neural Networks, GNNs)作为一种有效的处理图结构数据的方法,受到了广泛关注。通过引入GNN,我们可以充分利用知识图谱中丰富的结构信息,实现对实体及其关系的深度建模。具体而言,GNN能够在节点之间传播信息,从而捕捉到复杂的上下文关系,提升模型对新知识的学习能力。
例如,在某些应用场景中,GNN可以通过迭代消息传递机制将源知识图谱中的知识迁移到目标知识图谱中。这样的迁移不仅限于简单的实体映射,还可以通过综合考虑实体的邻居关系和路径信息,使得迁移过程更加灵活和精准。此外,GNN还可以与其他深度学习模型(如卷积神经网络、循环神经网络等)结合,形成混合模型,从而增强迁移学习的效果。这种模型结合的方式,可以在多个领域(如社交网络分析、推荐系统等)中有效提高模型的性能,尤其是在处理复杂任务时。
多模态知识迁移
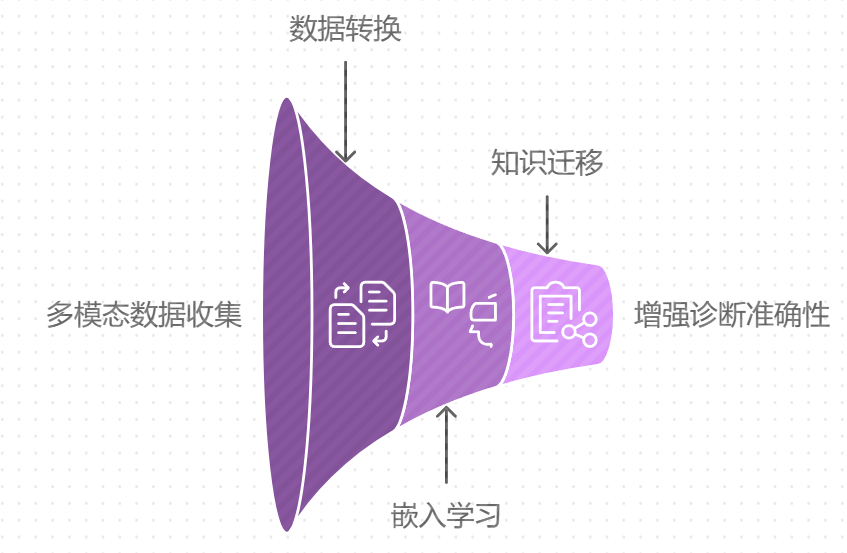
随着信息技术的快速发展,多模态知识的获取与融合已成为研究的热点。在知识迁移的背景下,将多模态信息(如图像、文本和音频等)结合到知识迁移过程中,不仅能丰富知识的表示形式,还能提升迁移效果。例如,在医疗领域,医生的诊断不仅依赖于文本描述,还需要结合患者的影像数据。通过将图像数据与知识图谱中的文本信息进行融合,可以帮助模型更全面地理解和处理问题。
具体而言,多模态知识迁移可以通过将不同模态的数据转换为统一的表示形式进行实现。这样的转换可以使用深度学习技术,如卷积神经网络处理图像数据、循环神经网络处理文本数据等。之后,通过嵌入学习的方法,将不同模态的信息整合到一个共享的向量空间中,从而实现对新任务的知识迁移。这种方法不仅增强了模型的泛化能力,还提升了对复杂任务的适应性。例如,在医疗诊断中,基于多模态知识迁移的系统可以同时考虑患者的病历、实验室结果和影像资料,从而提供更准确的诊断建议。
实时迁移机制
在快速变化的现实世界中,知识图谱需要具备实时更新与动态迁移的能力,以保持其有效性和适应性。实时迁移机制的实现是知识图谱应用的一个重要研究方向。通过构建动态知识图谱,可以实时捕捉新知识,并将其融入到现有知识中。这一机制不仅能够提升知识图谱的时效性,还能确保其在不断变化的环境中保持准确性。
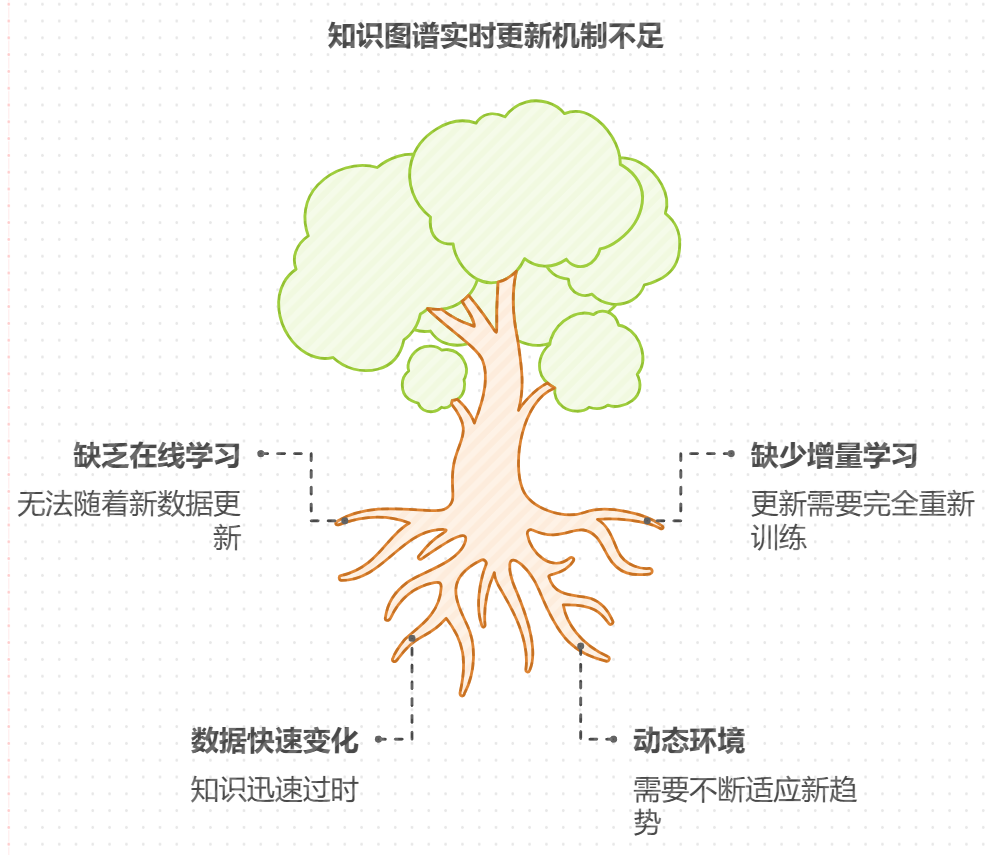
实时迁移机制可以通过引入在线学习和增量学习的方法来实现。在线学习允许模型在接收到新数据时立即更新其参数,而增量学习则能够在不完全重训模型的情况下,逐步引入新知识。这种机制尤其适用于快速发展的领域,如社交媒体、金融市场等。在这些领域,数据变化迅速,知识图谱需要及时调整以应对新的信息。例如,在社交网络分析中,实时迁移机制可以帮助系统动态识别新兴趋势、热点话题以及用户行为模式,从而提高信息推荐的准确性。
应用场景扩展
知识迁移技术的广泛应用为多个领域带来了革命性的变革,特别是在医疗、金融、智能交通等行业。通过将知识迁移技术与具体应用相结合,我们可以显著提高系统的智能化水平和决策能力。在医疗领域,知识迁移能够帮助医生快速获取相关疾病的最新研究成果,并根据患者的具体情况提供个性化的治疗方案。例如,基于知识图谱的系统可以在医生输入患者病历的同时,自动推荐相关文献、临床路径和药物信息,从而提高医疗服务的效率。
在金融领域,知识迁移可以用来分析市场趋势和风险管理。通过构建金融知识图谱,并结合历史数据与实时市场信息,金融机构能够快速识别潜在的风险和投资机会,从而优化决策流程。在智能交通系统中,知识迁移可以用于实时交通流量预测和路况分析。通过融合交通数据与城市知识图谱,系统能够更精准地识别拥堵情况并优化交通信号控制,提升城市交通的效率。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号