实时离线融合计算的数据同步实践
原创
实时离线融合计算的数据同步实践
原创
大数据咖啡屋
发布于 2024-11-05 10:45:34
发布于 2024-11-05 10:45:34
实时批量融合计算时,一般需要批量将数据推送到hbase供实时使用。
本文将通过两个典型场景--累计场景与最新分区场景,讨论批量和实时衔接的设计方案,解决批量延迟可能导致的问题。
累计场景
在之前的文章中讲述了实时离线结合共同计算客户180天累积交易金额的场景。
这种情况下批量是计算178~T-2的累计值,实时算T-1,T两天的累计值。
批量将累计结果推送到hbase中,实时的计算结果关联hbase汇总批量结果后获得客户180天的累计值。
具体的开发中,假设此hbase表的rowkey为客户号_分区时间,批量实时交互细节如下图所示。
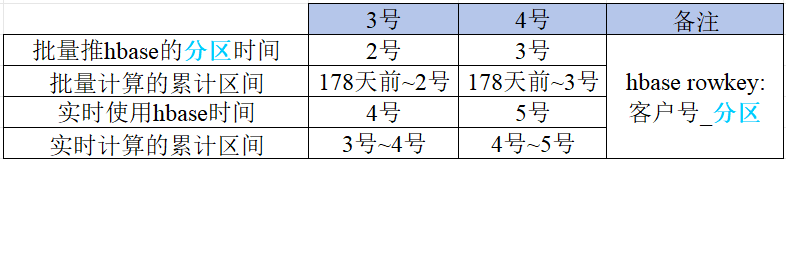
以3号为例,批量计算了178天前~2号的累计结果推送到hbase中,hbase的rowkey是客户号_2号。
实时等到4号的时候使用这份数据,并汇总实时自行计算的3号~4号数据得到180天的汇总。
如果3号这天,批量因其他因素晚批导致今日应该推送的(178天前~2号)数据未及时推送到hbase中,而实时4号就要使用数据,那就需要及时告警和人工介入处理。
此时可设计成实时计算最近3天的累计值(客户每天的累计值存下来,方便进行多天的累计)。
如果发现hbase中客户号_2号的数据还未到,则向前取一天即取客户号_1号的数据进行汇总。
这样能给批量多留出一天的处理时间,也减少了潜在的任务启停操作以保证程序运行的稳定。
最新分区场景
比如批量有一张商户表,表字段中有商户名称和商户分类两个字段。
批量需要将商户名称和分类的映射关系推到hbase供实时使用。
批量每日分区的数据可能不同,考虑批量晚批的因素,只需要推送最新分区的数据到hbase即可。
一般情况下批量实时的衔接设计如下图所示。
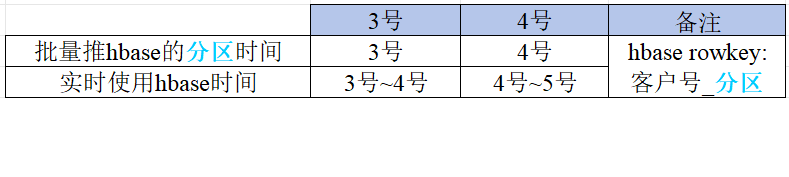
以3号为例,批量从商户表中取出最新分区的映射关系推到hbase中,rowkey是客户号_3号,实时4号的时候使用这份数据。如果3号因各种原因批量未能如期送数,此时需要进行告警和人工介入。
此时批量推送hbase表的设计应更灵活。3号批量取出数据后推送两份相同的映射关系数据到hbase中,只不过一份数据的rowkey为客户号_3号,另一份数据的rowkey为客户号__4号。
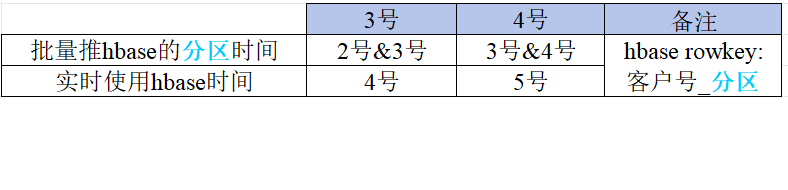
这样即使3号晚批,批量在2号推送的数据中有rowkey为客户号__3号的数据,也能实现实时使用最新分区的映射。
这样的数据冗余设计也给批量预留了一天的处理时间以及减少潜在的任务启停操作。
综上所述,通过两个典型场景--累计场景与最新分区场景的数据同步的容错设计,最小化了人工干预需求,降低了运维复杂度,确保了数据服务的连续性。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号