biotrainee note 7
原创

表达矩阵
一行是一个基因,一列是一个样本,里面是基因的表达量
数据从哪里来
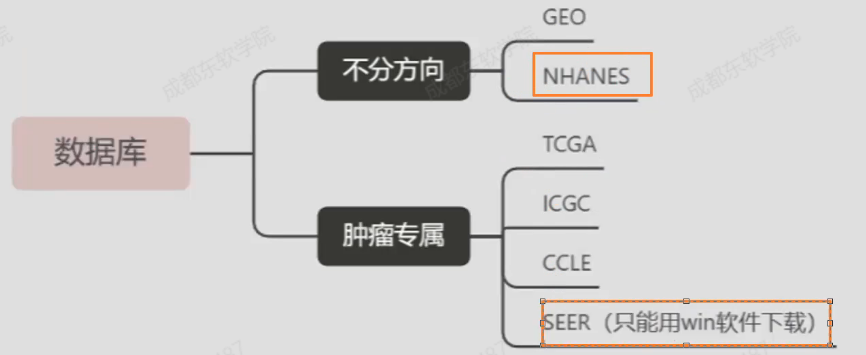
有什么类型的数据可挖掘
基因表达芯片
转录组
单细胞
突变、甲基化、拷贝数变异。。。。
怎样筛选基因
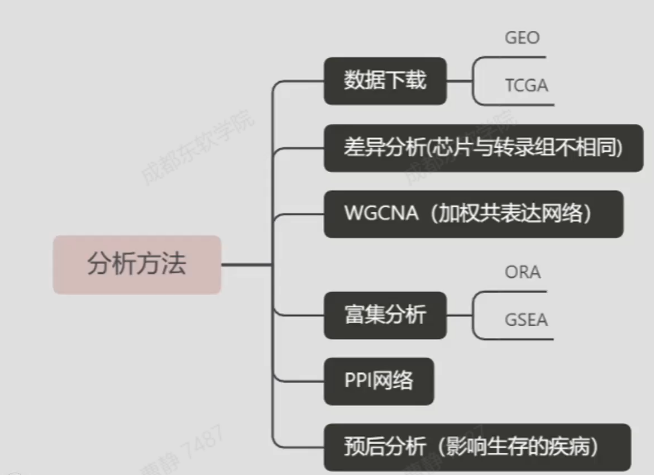
图表介绍
1.热图
输入数据是数值型矩阵/数据框
颜色的变化表示数值的大小
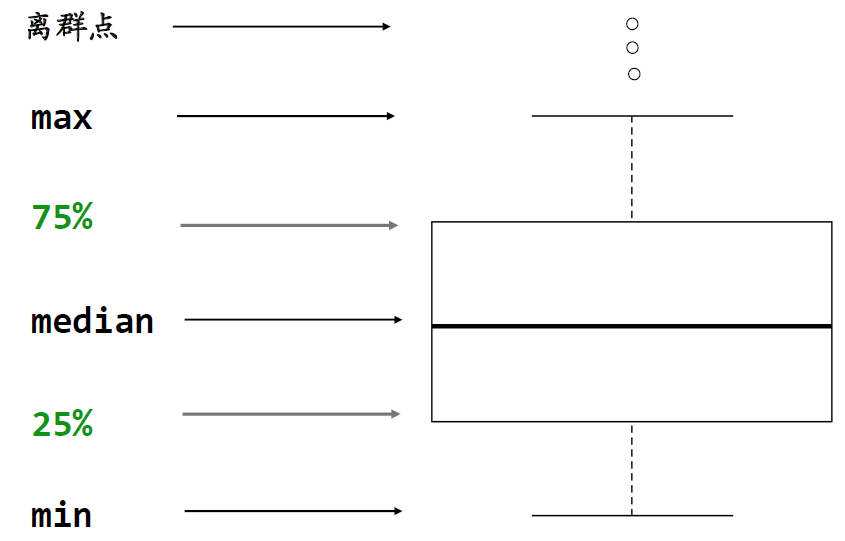
2.散点图和箱线图
输入的数据是一个连续型向量(数值型数据)和一个有重复值的离散型向量(有分类)
箱线图可以反映单个基因(或指标)在两组(或多组)之间的表达量差异
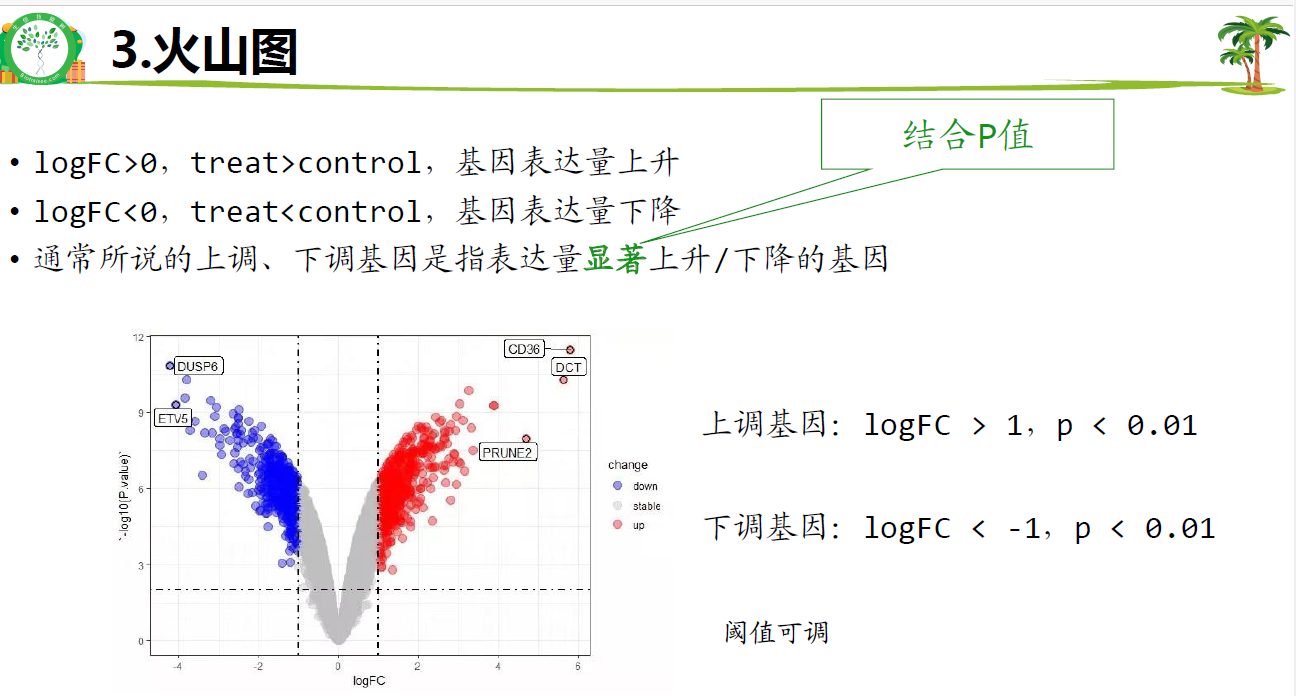
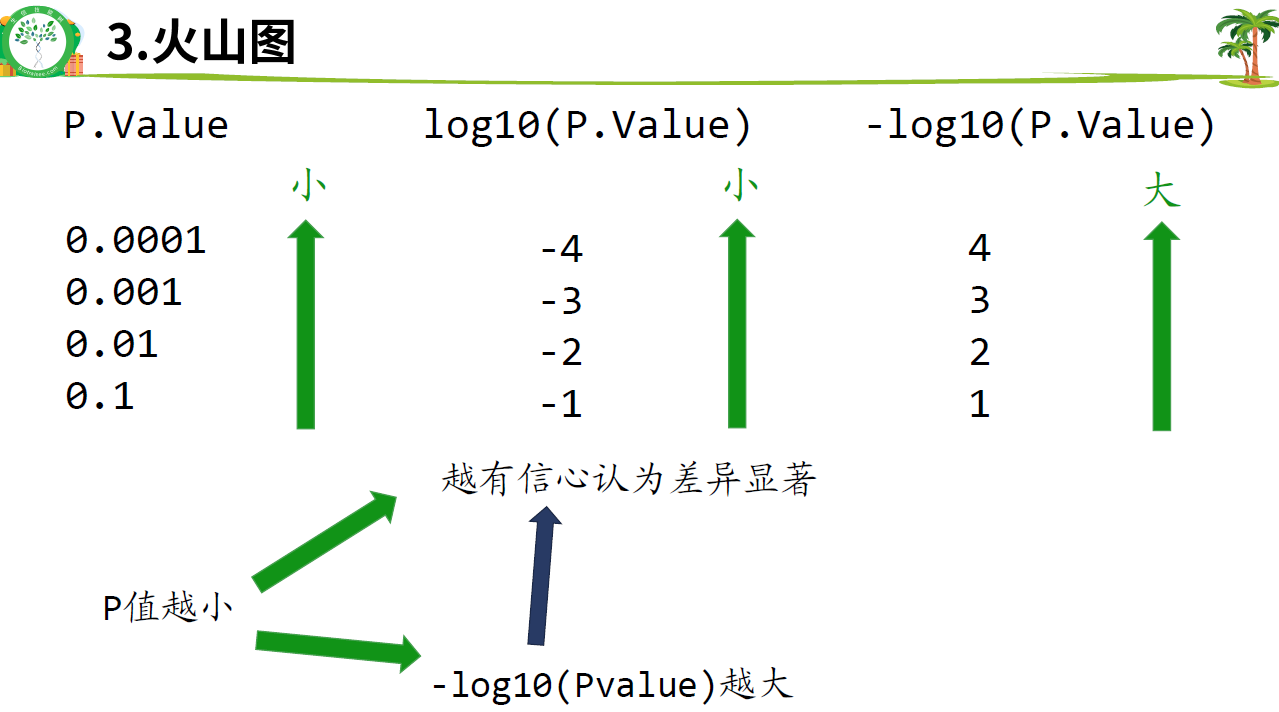
3.火山图
FoldChange(FC)=处理组平均值/对照组平均值
log2FoldChange(logFC):FoldChange取log2
差异分析的起点是一个取过log的表达矩阵(0~20),如果拿到的是未log的矩阵(0~很大),需要自行log
4.主成分分析
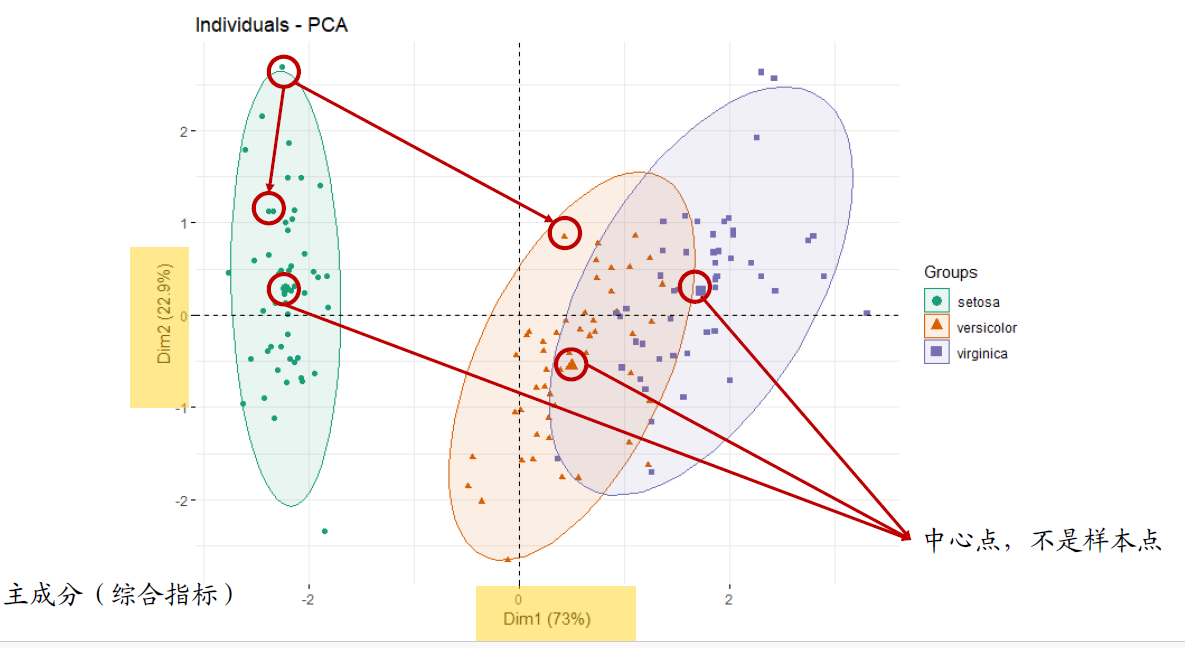
每个点代表一个样本(中心点除外),点与点之间的距离代表样本之间的相似程度
每个圈代表一个组
用于“预实验”,简单查看组间是否有差别

GEO背景知识+表达芯片分析
1.实验设计
实验目的:通过基因表达量数据的差异分析和富集分析来解释生物学现象
有差异的材料→差异基因→找功能/找关联→解释差异,缩小基因范围
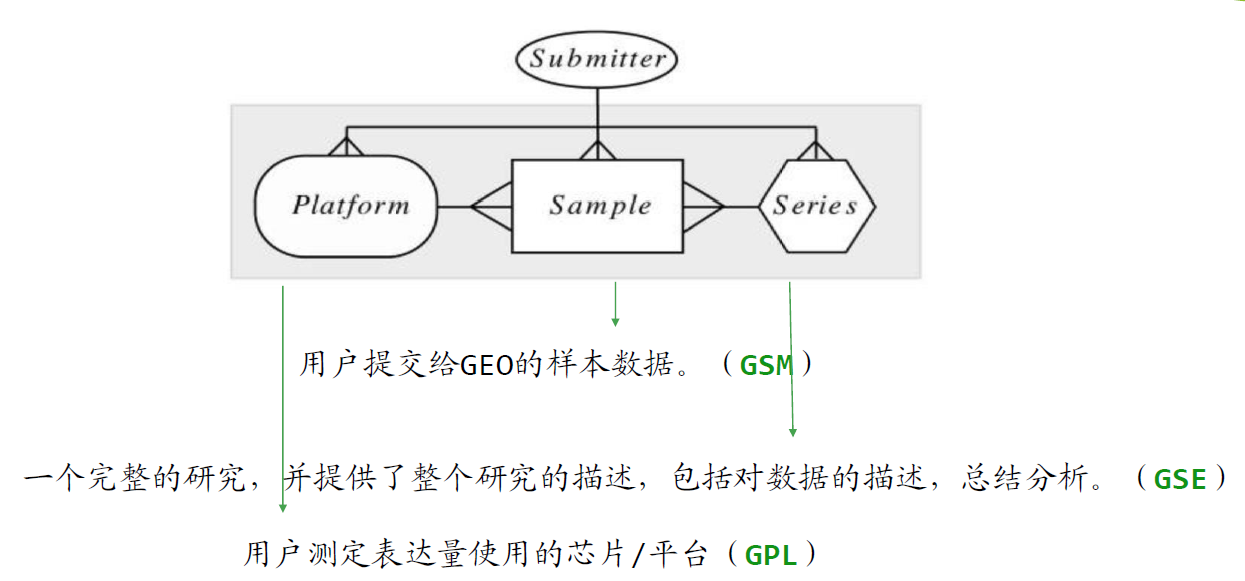
2.数据库介绍
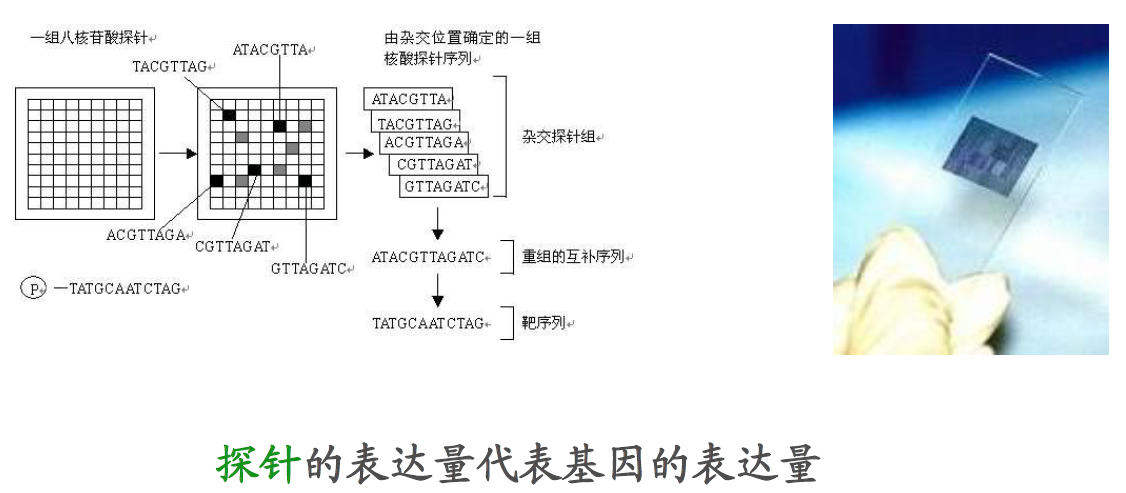
3.基因表达芯片的原理
4.分析思路
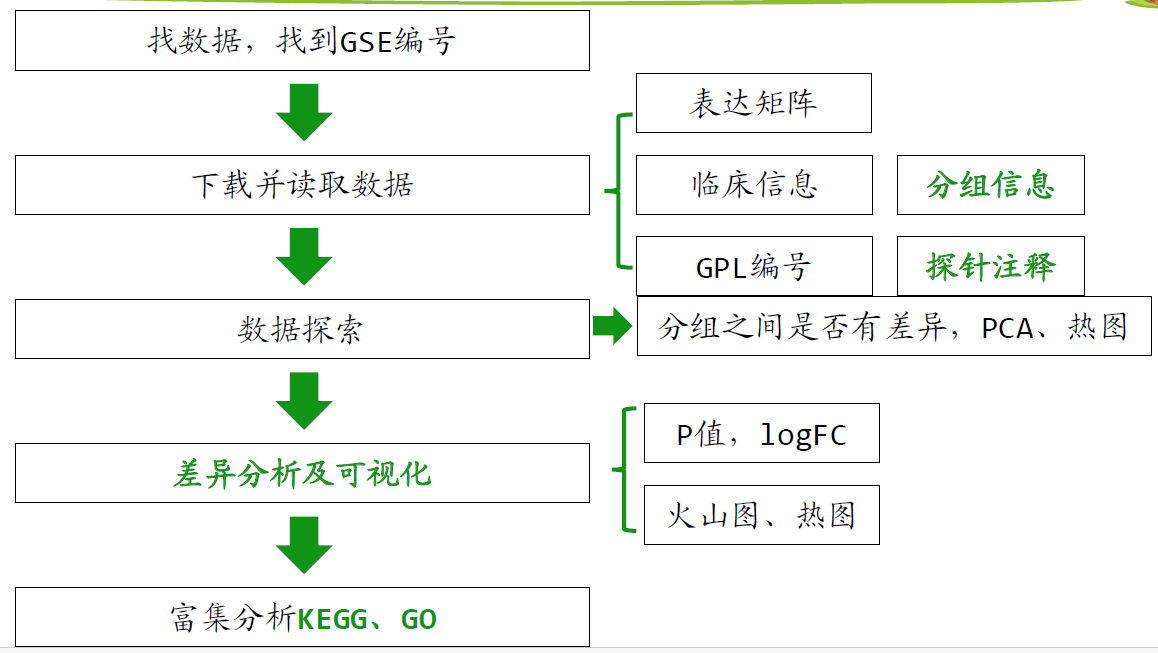
5.下载数据
在GEO网站上,找到目标数据,点击下图所示位置进入数据下载页面
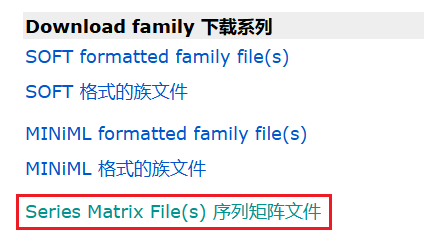

如果这里的文件大小小于500kb,说明这儿的数据只有临床信息表格,没有表达矩阵,可能是因为:1.这不是芯片数据;2.文件放到了别的地方,一般会放在补充文件那里。

#打破下载时间的限制,改前60秒,改后10w秒
options(timeout = 100000)
options(scipen = 20)#不要以科学计数法表示
#传统下载方式
library(GEOquery)
eSet = getGEO("GSE7305", destdir = '.', getGPL = F)
#网速太慢,下不下来怎么办
#1.从网页上下载/发链接让别人帮忙下,放在工作目录里
#2.试试geoChina,只能下载2019年前的表达芯片数据
#library(AnnoProbe)
#eSet = geoChina("GSE7305") #选择性代替第7行
#研究一下这个eSet
class(eSet) #是一个列表
length(eSet) #列表里只有1个元素
eSet = eSet[[1]] #提取这个唯一的元素
class(eSet) #显示这个数据的类型是一个“对象”
#(1)提取表达矩阵exp
exp <- exprs(eSet)
#⭐第一个要检查的地方👇,表达矩阵行列数,正常是几万行,列数=样本数,
#如果0行说明不是表达芯片或者是遇到特殊情况,不能用此流程分析
dim(exp)
#⭐二个要检查的地方👇
range(exp)#看数据范围决定是否需要log,是否有负值,异常值,如有负值,结合箱线图进一步判断
#⭐可能要修改的地方👇
exp = log2(exp+1) #需要log才log,不需要log要注释掉这一句
#⭐第三个要检查的地方👇
boxplot(exp,las = 2) #看是否有异常样本
#遇到异常样本,可以直接删掉异常样本,也可以用函数
#exp = limma::normalizeBetweenArrays(exp) 来将样本做一个归一化处理,即将少量的异常样本拉到正常水平6.表达矩阵的数值范围

7.关于表达矩阵里的负值

8. 关于原始数据
不同格式对应不同处理的方法
不是所有的原始数据都有办法分析,太小众的查不到资料
对R语言基础和解决问题的能力要求较高
优先找正常的、靠谱的数据,先打好基础再想着处理原始数据
引自生信技能树
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号