探索 RocketMQ:企业级消息中间件的选择与应用
原创

探索 RocketMQ:企业级消息中间件的选择与应用
一、关于RocketMQ
RocketMQ 是一个高性能、高可靠、可扩展的分布式消息中间件,它是由阿里巴巴开发并贡献给 Apache 软件基金会的一个开源项目。RocketMQ 主要用于处理大规模、高吞吐量、低延迟的消息传递,它是一个轻量级的、功能强大的消息队列系统,广泛应用于金融、电商、日志系统、数据分析等领域。

c41a6a12-fb7d-47b5-b0a0-a6e1a437a07d
RocketMQ作为一款纯java、分布式、队列模型的开源消息中间件,支持事务消息、顺序消息、批量消息、定时消息、消息回溯等,总之就是葛大爷的一句话。

8d2af478-f112-4738-9d28-6a20ed02c5fa

v2-d30f95c328de7c976e6fddeac6e1e8aa_b
二、发展
消息队列属于最经典的中间件之一,已经有 30 多年的历史,其发展历程可以总结为几个阶段:
- 第一阶段,2000 年之前。这个阶段的消息队列供应商是几家商业软件巨头,比如 IBM、Oracle、Microsoft 都有自己的商业化 MQ,其中最具代表性的是 IBM MQ,价格昂贵,面向高端企业,主要是大型金融、电信等企业;这类商业 MQ 一般采用高端硬件,软硬件一体机交付,MQ 本身的软件架构是单机架构。
- 第二阶段,2000~2007 年。进入 00 年代后,初代开源消息队列崛起,诞生了 JMS、AMQP 两大标准,与之对应的两个实现分别为 ActiveMQ、RabbitMQ,他们引领了初期的开源消息队列技术。开源极大的促进了消息队列的流行、降低了使用门槛,技术普惠化,逐渐成为了企业级架构的标配。
- 第三阶段,2007~2017 年。PC 互联网、移动互联网爆发式发展。由于传统的消息队列无法承受亿级用户的访问流量和海量数据传输,诞生了互联网消息中间件,核心能力是全面采用分布式架构、具备很强的横向扩展能力,开源典型代表有 Kafka、RocketMQ,闭源的还有淘宝 Notify。
RocketMQ 发展的主要历程:
2007年:淘宝实施了“五彩石”项目,“五彩石”用于将交易系统从单机变成分布式,也是在这个过程中产生了阿里巴巴第一代消息引擎——Notify。
2010年:阿里巴巴B2B部门基于ActiveMQ的5.1版本也开发了自己的一款消息引擎,称为Napoli,这款消息引擎在B2B里面广泛地被使用,不仅仅是在交易领域,在很多的后台异步解耦等方面也得到了广泛的应用。
2011年:业界出现了现在被很多大数据领域所推崇的Kafka消息引擎,阿里巴巴在研究了Kafka的整体机制和架构设计之后,基于Kafka的设计使用Java进行了完全重写并推出了MetaQ 1.0版本,主要是用于解决顺序消息和海量堆积的问题。
2012年:阿里巴巴开源其自研的第三代分布式消息中间件——RocketMQ。
经过几年的技术打磨,阿里称基于RocketMQ技术,目前双十一当天消息容量可达到万亿级。
2016年11月:阿里将RocketMQ捐献给Apache软件基金会,正式成为孵化项目。
阿里称会将其打造成顶级项目。这是阿里迈出的一大步,因为加入到开源软件基金会需要经过评审方的考核与观察。
坦率而言,业界还对国人的代码开源参与度仍保持着刻板印象;而Apache基金会中的342个项目中,暂时还只有Kylin、CarbonData、Eagle 、Dubbo和 RocketMQ 共计五个中国技术人主导的项目。
2017 年,RocketMQ 成功通过了 Apache Incubator 的评审,正式成为 Apache 顶级项目(Top-Level Project, TLP) 。这个标志性事件不仅提升了 RocketMQ 在全球开源社区的影响力,也使其获得了更多来自外部社区的支持和贡献。
2017年2月20日:RocketMQ正式发布4.0版本,专家称新版本适用于电商领域,金融领域,大数据领域,兼有物联网领域的编程模型。
2023 年,RocketMQ 发布了 5.x 版本,继续强化其在云原生、容器化环境中的应用,并且在微服务架构中发挥了重要作用。此版本在性能、可扩展性和稳定性方面进行了进一步优化,增强了在异构环境下的跨平台兼容性,并扩展了更多高级特性,如 精准消息投递、更加细粒度的消息过滤 等。
以上就是RocketMQ的整体发展历史,其实在阿里巴巴内部围绕着RocketMQ内核打造了三款产品,分别是MetaQ、Notify和Aliware MQ。
这三者分别采用了不同的模型,MetaQ主要使用了拉模型,解决了顺序消息和海量堆积问题;Notify主要使用了推模型,解决了事务消息;而云产品Aliware MQ则是提供了商业化的版本。
三、功能特点
- 高可靠性: RocketMQ 提供了强大的消息可靠性保证机制。它支持 消息持久化,即使在系统崩溃后,消息仍然可以恢复。此外,RocketMQ 提供了消息重试机制,确保消息不会丢失。
- 高吞吐量: RocketMQ 的设计目标之一就是高吞吐量。它通过高效的网络通信和存储方式,能够处理大量的并发请求,适用于大规模分布式场景。
- 分布式架构: RocketMQ 使用 分布式架构,其主要组件包括 NameServer(负责服务发现),Broker(消息存储与转发),Producer(消息生产者),Consumer(消息消费者)。RocketMQ 具有水平扩展性,能够支持多台机器集群化部署,保证了系统的高可用性和弹性扩展。
- 顺序消息支持: RocketMQ 提供了强大的 顺序消息支持。对于需要保证消息顺序的应用,RocketMQ 可以通过同一队列中存储顺序消息,确保消费顺序的一致性。
- 多种消息模型: RocketMQ 支持多种消息模型,如:
- 点对点模式(P2P) :消费者独占某个队列的消息,保证一个消息只被一个消费者消费。
- 发布/订阅模式(Pub/Sub) :多个消费者可以订阅同一个主题(Topic),消息广播到所有消费者。
- 高可扩展性: RocketMQ 通过分区(Topic 分区)和分布式的消息存储,可以横向扩展,支持大规模消息的存储和处理。可以灵活地根据业务需求进行扩展。
- 多语言客户端支持: RocketMQ 提供了多种客户端 SDK,支持 Java、C++、Python、Go 等多种语言,方便开发者进行跨语言集成。
- 事务消息: RocketMQ 提供了 事务消息功能,可以支持分布式事务场景中的消息可靠性保证。通过事务消息,开发者可以保证消息与本地事务的一致性。
- 消息回溯与重试机制: 支持消息的 回溯功能,允许消费者查看过去的消息,还支持消息的 重试机制,确保消息处理失败时不会丢失。
- 灵活的消息过滤: RocketMQ 支持消息的 标签过滤(Tag-based filtering),允许消费者根据消息的标签过滤需要的消息。
四、对比其它中间件
特性 | RocketMQ | Kafka | RabbitMQ | ActiveMQ | NATS |
|---|---|---|---|---|---|
开发背景 | 阿里巴巴开发,2010 年开源,现为 Apache 顶级项目 | LinkedIn 开发,2011 年开源,现为 Apache 顶级项目 | Pivotal(现 VMware)开发,开源项目 | Apache 软件基金会开发,支持多协议的消息队列 | 开源项目,初衷为轻量级实时消息传递 |
消息协议 | 自定义协议,兼容 MQTT、OpenMessaging 等 | 自定义协议(Kafka 协议) | 支持 AMQP、STOMP、MQTT 等多种协议 | 支持 AMQP、OpenWire、MQTT 等多种协议 | NATS 协议,专注于简单的 Pub/Sub 模型 |
性能与吞吐量 | 高吞吐量,低延迟,适用于高并发场景 | 主要侧重吞吐量,适用于大数据流处理 | 吞吐量较低,适用于中小型企业 | 吞吐量较低,适合中小型企业应用 | 极低的延迟和极高的吞吐量,专注于实时性 |
消息模型 | 支持点对点(P2P)和发布/订阅(Pub/Sub)模式 | 主要是发布/订阅(Pub/Sub)模型 | 支持点对点(P2P)和发布/订阅(Pub/Sub)模型 | 支持点对点(P2P)和发布/订阅(Pub/Sub)模型 | 支持 Pub/Sub 模型 |
消息存储 | 顺序写入,支持高效的消息持久化 | 顺序写入,按日志存储,支持高效的消息持久化 | 使用内存/磁盘存储,支持消息持久化 | 使用内存/磁盘存储,支持消息持久化 | 存储较为简单,不强调持久化 |
扩展性 | 支持分布式部署,高可用,支持水平扩展 | 高扩展性,支持分布式部署和多副本机制 | 集群模式,但扩展性不如 RocketMQ 和 Kafka | 支持集群模式,扩展性相对较差 | 高扩展性,适用于大规模水平扩展 |
高可用性 | 支持主从复制,集群模式,容错性高 | 多副本机制,较强的容错性 | 支持镜像队列和集群模式,容错性较好 | 支持主从复制和集群模式,容错性一般 | 支持集群模式和多节点部署,容错性较好 |
事务消息 | 原生支持事务消息和分布式事务 | 不支持原生事务消息,需自行实现 | 支持事务消息,但性能不如 RocketMQ | 支持事务消息,但一致性和性能较差 | 不支持事务消息 |
顺序消息 | 支持严格顺序消费,适合高并发场景 | 支持分区内的顺序消费,但需要手动控制分区的数量和分布 | 支持顺序消费,但通常不如 RocketMQ 强大 | 支持顺序消费,但不如 RocketMQ 强大 | 不强调顺序消息处理 |
延迟 | 在高并发场景下延迟较低,适用于实时消息传递 | 吞吐量优先,延迟相对较高 | 在高负载时延迟较高 | 延迟较高,尤其在负载较重时 | 延迟极低,适用于实时性要求较高的场景 |
适用场景 | 高吞吐量、大规模分布式系统、事务消息、顺序消息等场景 | 日志聚合、流数据处理、大数据平台 | 企业消息传递、支持 AMQP 协议的系统 | 中小规模企业消息传递、企业级应用 | 实时数据流、IoT、微服务架构等高性能、低延迟场景 |
社区与生态 | Apache 社区支持,活跃且发展迅速 | Apache 社区支持,社区活跃 | 社区活跃,广泛应用于企业级应用 | Apache 社区支持,但活跃度和扩展性相对较弱 | 开源社区活跃,适用于微服务和高并发场景 |
总结:
- RocketMQ 在高吞吐量、低延迟和事务消息支持方面表现出色,适用于金融、电商等高并发、高可靠的场景。
- Kafka 强调吞吐量,适用于大数据流处理、日志聚合等大规模数据平台,且具有较好的扩展性。
- RabbitMQ 适用于中小规模企业,特别是需要支持多协议(如 AMQP)的消息传递应用。
- ActiveMQ 相对较为传统,适合于小到中规模的企业应用,支持多协议但性能和扩展性较差。
- NATS 轻量级、高性能,适用于实时性要求较高的场景,如物联网、微服务架构等。
五、应用场景
以下是一些典型的 RocketMQ 应用场景:
- 金融行业
- 交易消息系统:金融交易系统对消息的可靠性、事务性和高吞吐量有严格要求。RocketMQ 支持事务消息(Transaction Message),能够确保分布式事务的准确性,适合在银行、电商金融、支付系统中进行实时交易消息处理。
- 风控系统:在金融风控系统中,常常需要高并发、高吞吐量的消息系统来处理海量数据。RocketMQ 的高吞吐量和低延迟特性使其适用于此类实时风控决策系统。
- 资金调度:资金调度的核心需求是可靠性与高吞吐量,RocketMQ 能够在大规模并发请求下保证数据一致性,适合资金结算、账户调度等高并发场景。
- 电商平台
- 订单处理系统:电商平台中的订单生成、支付、库存管理、物流等环节常常需要保证高并发、高吞吐量的消息传递。RocketMQ 能够保证系统的高效性,特别是在“双十一”等促销活动期间,能够平稳处理海量订单消息。
- 异步消息处理:电商系统中,很多操作是异步的,例如支付回调、库存扣减、物流派送等。使用 RocketMQ 可以通过消息队列解耦这些操作,提高系统响应速度。
- 促销活动推送:对于电商平台的秒杀、优惠券发放等高频业务,RocketMQ 能够提供高并发支持,保证消息的顺序和稳定性。
- 大数据与流处理
- 日志收集与分析:RocketMQ 可以高效地处理海量的日志数据,支持从各类应用程序、服务器、设备等收集日志并进行实时处理。与 Flume、Logstash 等流式处理框架配合使用,能够快速地收集、传输和分析日志数据。
- 数据流处理:在实时数据流的场景中,如实时大数据处理、数据分析、机器学习等,RocketMQ 能够以极低的延迟和高吞吐量确保数据的稳定传输,适用于大数据平台和流计算架构。
- 微服务架构
- 微服务通信:在微服务架构中,服务之间通常通过异步消息传递进行解耦。RocketMQ 提供可靠的消息投递机制,可以保证服务间的数据一致性,避免系统耦合过紧。通过 RocketMQ,服务间的通信能够更加灵活、可靠。
- 异步处理与事件驱动:RocketMQ 作为事件驱动架构(EDA)中的核心组件,能够很好地支持微服务中的异步处理和事件发布与订阅模式。事件驱动模型适用于需要处理高并发、低延迟业务的微服务系统。
- 物联网(IoT)
- 设备数据收集与处理:在物联网应用中,设备的数量庞大,产生的数据量巨大,且对实时性要求较高。RocketMQ 的高吞吐量、低延迟和高可靠性非常适合用于 IoT 系统中,能够实时收集来自各类设备的数据并进行分发处理。
- 状态监控和告警系统:RocketMQ 能够支持设备的状态数据流转,以及实时告警通知。通过将设备数据发送到消息队列中,再进行实时分析和处理,能够在出现异常时及时触发告警。
- 实时消息推送
- 社交平台消息推送:在社交平台中,实时消息推送是一项核心功能,如聊天消息、通知、点赞、评论等,RocketMQ 具备高吞吐量和低延迟的特点,能够保证大规模用户的实时消息推送。
- 内容分发网络(CDN) :RocketMQ 可以帮助构建高效的内容分发和通知系统,推送实时更新、推荐内容等,确保数据在多个节点之间快速传递,特别适用于需要快速内容更新的场景。
- 日志与事件追踪
- 异步日志记录:许多应用系统会在后台记录用户操作、系统运行状态等信息。RocketMQ 可以异步记录日志,避免同步阻塞,同时保证高效的日志传输和存储,尤其适合大规模分布式系统的日志收集。
- 事件追踪与分析:在微服务架构中,事件追踪(如调用链追踪)对于监控和故障排查至关重要。RocketMQ 可以确保事件流的高效传递和顺序处理,帮助构建全面的事件追踪系统。
- 消息驱动的异步任务
- 后台任务处理:很多系统的任务是异步的,如生成报表、邮件发送、数据处理等。使用 RocketMQ 进行任务调度和消息驱动处理,可以有效解耦主业务流程和耗时的任务处理,提高系统的响应能力。
- 定时任务与延时消息:RocketMQ 支持延时消息功能,可以用来处理定时任务、超时重试等操作。比如在电商场景中,发货时间的计算、延时支付的重试等都可以通过 RocketMQ 延时消息机制来实现。
- 日志与审计系统
- 审计日志收集:在许多业务中,审计日志的收集与处理具有重要意义,特别是在合规性要求较高的行业(如金融、医疗等)。RocketMQ 可以作为日志收集的中间件,确保日志的可靠传输与持久化。
- 分布式系统与高可用架构
- 系统解耦与弹性扩展:在复杂的分布式系统中,RocketMQ 可以通过消息队列解耦各个服务模块,保证系统的可靠性和高可用性。尤其是在微服务架构中,消息中间件可以减少服务间的直接依赖,提高系统的扩展性和容错能力。
场景示例1—异步解耦
随着微服务架构的流行,服务之间的关系梳理非常重要。异步解耦可以降低服务之间的耦合程度,同时也能提高服务的吞吐量。
使用异步解耦的业务场景非常多,因为每个行业的业务都会不太一样,以一些比较通用的业务来说明相信大家都能理解。
比如电商行业的下单业务场景,以最简单的下单流程来说,下单流程如下:
- 锁库存
- 创建订单
- 用户支付
- 扣减库存
- 给用户发送购买短信通知
- 给用户增加积分
- 通知商家发货
我们以下单成功后,用户进行支付,支付完成会有个逻辑叫支付回调,在回调里面需要去做一些业务逻辑。首先来看下同步处理需要花费的时间,如下图:
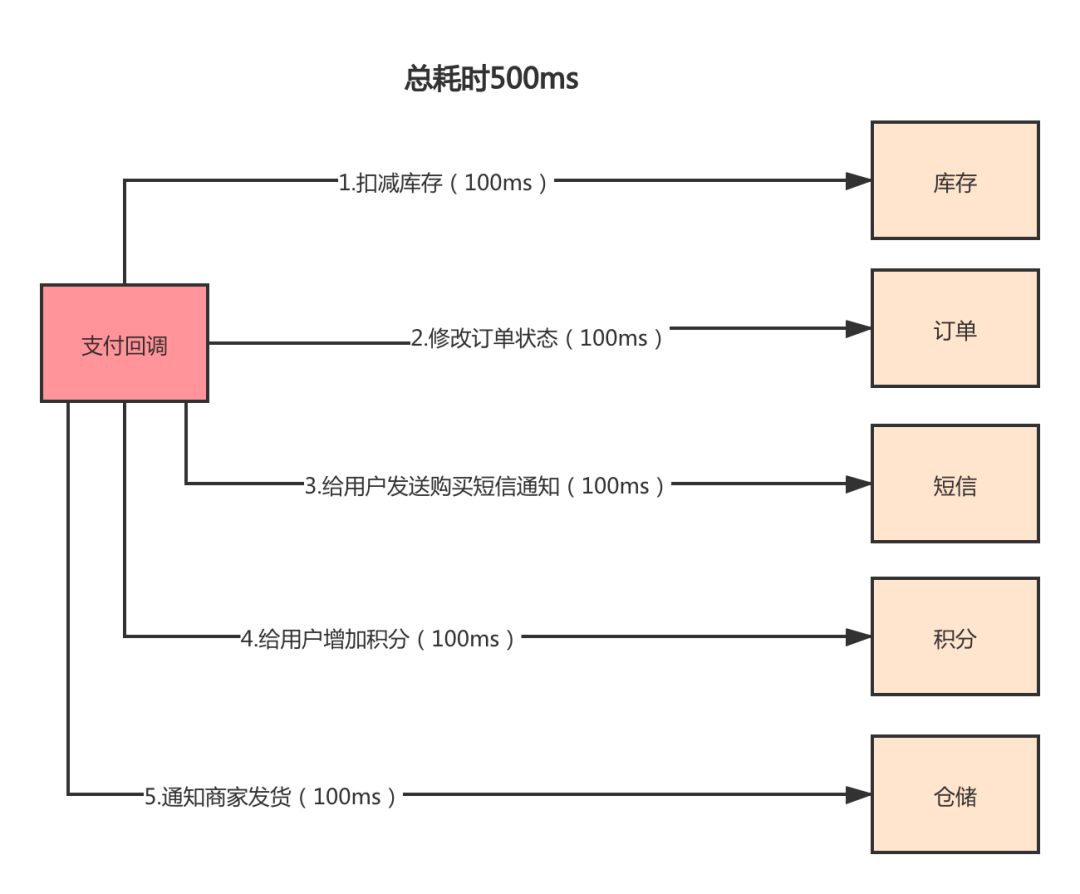
同步流程
上面的下单流程从 3 到 5 都是可以采用异步流程进行处理,对于用户来说,支付完成后他就不需要关注后面的流程了。后台慢慢处理就行了,这样就能简化三个步骤,提高回调的处理时间。
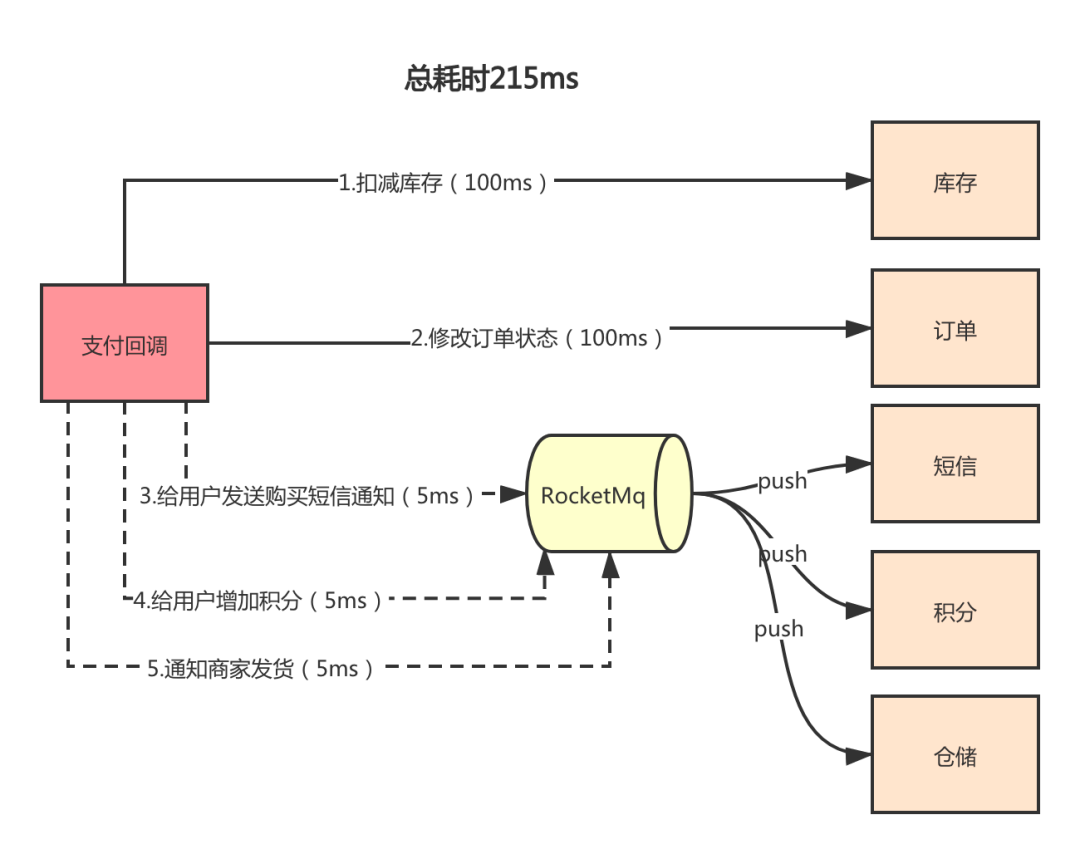
异步流程
场景示例2—削峰填谷
削峰填谷指的是在大流量的冲击下,利用 RocketMQ 可以抗住瞬时的大流量,保护系统的稳定性,提升用户体验。
在电商行业,最常见的流量冲击就是秒杀活动了,利用 RocketMQ 来实现一个完整的秒杀业务还是与很多需要做的工作,不在本文的范围内,后面有机会可以单独跟大家聊聊。想告诉大家的是像诸如此类的场景可以利用 RocketMQ 来扛住高并发,前提是业务场景支持异步处理。
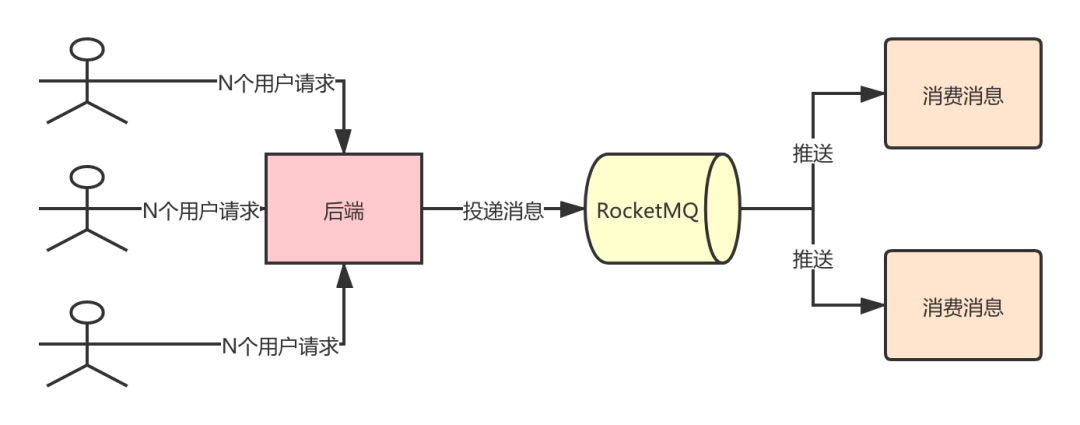
削峰填谷
场景示例3—分布式事务最终一致性
众所周知,分布式事务有 2PC,TCC,最终一致性等方案。其中使用消息队列来做最终一致性方案是比较常用的。
在电商的业务场景中,交易相关的核心业务一定要确保数据的一致性。通过引入消息队列 RocketMQ 版的分布式事务,既可以实现系统之间的解耦,又可以保证最终的数据一致性。
场景示例4—数据分发
数据分发指的是可以将原始数据分发到多个需要使用这份数据的系统中,实现数据异构的需求。最常见的有将数据分发到 ES, Redis 中为业务提供搜索,缓存等服务。
除了手动通过消息机制进行数据分发,还可以订阅 Mysql 的 binlog 来分发,在分发这个场景,需要使用 RocketMQ 的顺序消息来保证数据的一致性。
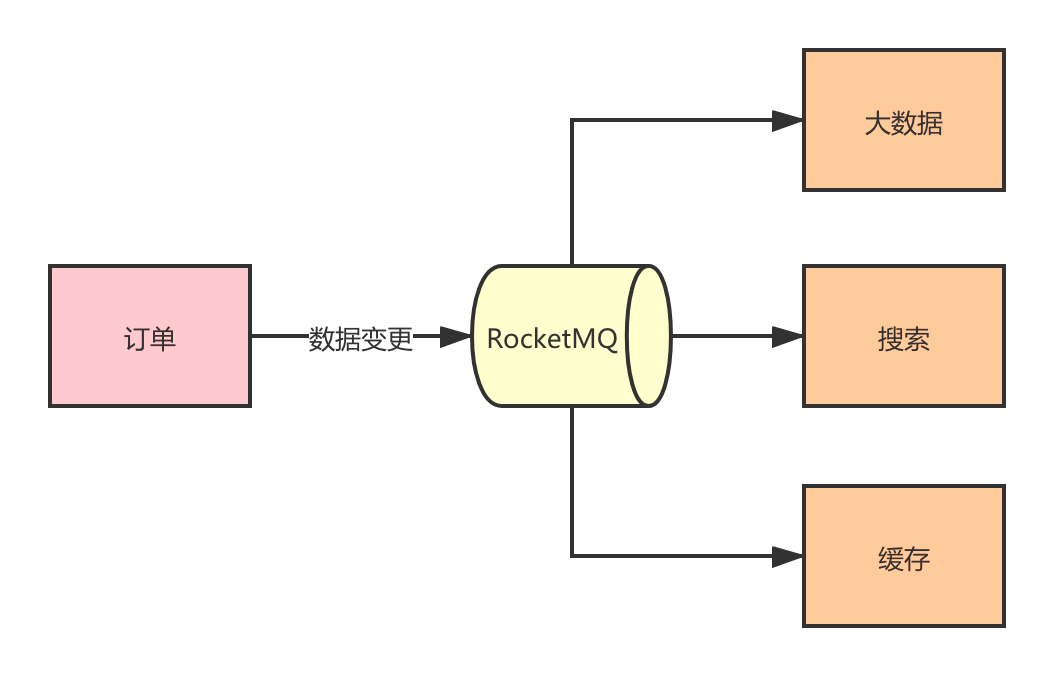
数据分发
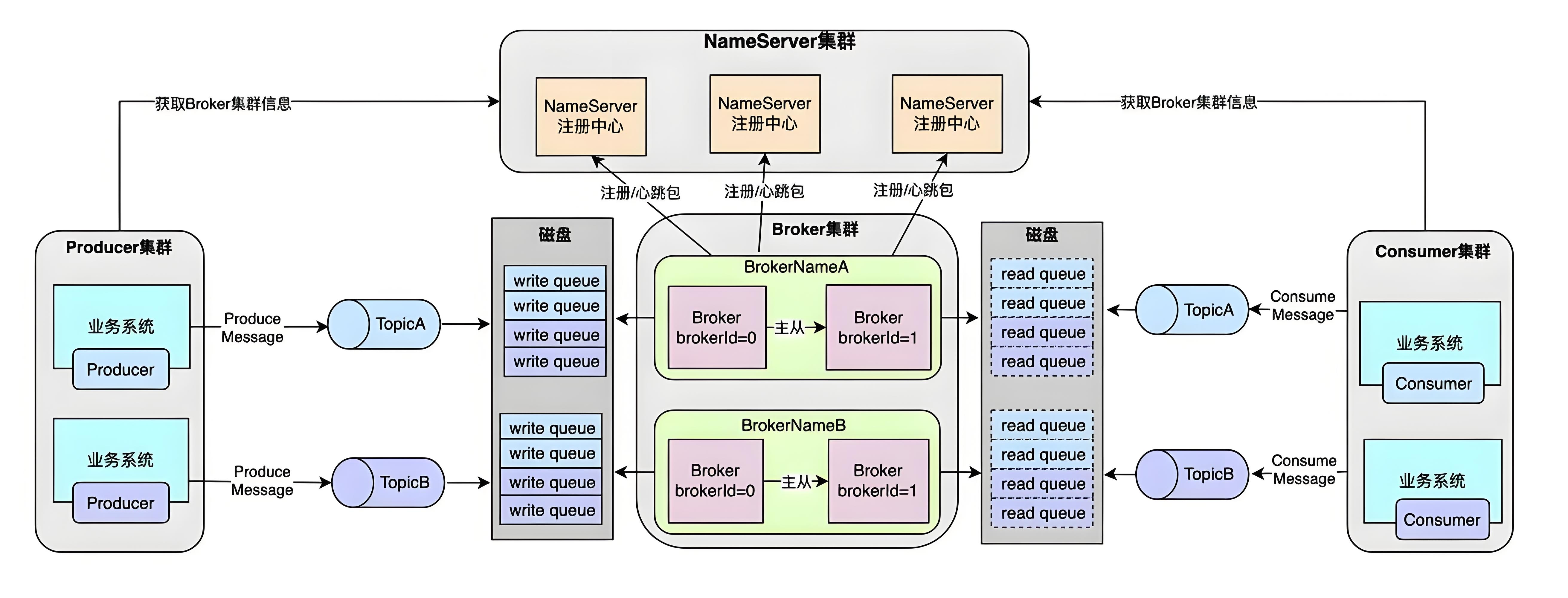
六、RocketMQ 组件
RocketMQ 的架构主要包括以下几个核心组件:
- NameServer: NameServer 是一个轻量级的服务发现模块,负责管理 Broker 节点的元数据,帮助 Producer 和 Consumer 查找 Broker,类似于一个服务注册与发现中心。
- Broker: Broker 是消息的存储和转发节点,消息生产者将消息发送到 Broker,消费者从 Broker 中拉取消息。Broker 负责消息的持久化存储、顺序消费和消息的投递。
- Producer: Producer 是消息生产者,负责将消息发送到指定的 Topic。每个 Producer 可以连接多个 Broker,发送消息到不同的队列。
- Consumer: Consumer 是消息消费者,负责从 Broker 拉取消息进行消费。Consumer 可以是 推模式(Push)或 拉模式(Pull),支持异步或同步消费。
- Admin Console: RocketMQ 提供了管理控制台,用于监控和管理集群的状态、Topic、Consumer 以及消息的流量等信息。
七、消息传递流程
- Producer 发送消息: Producer 将消息发送到 RocketMQ 的 Broker,并通过 NameServer 找到目标 Broker。消息被分配到一个队列(Queue),可以是顺序队列或并发队列。
- 消息存储: Broker 接收到消息后会将其持久化到磁盘中,并且根据需要将消息复制到其他副本节点,保证高可用性。
- Consumer 拉取消息: 消费者(Consumer)从 Broker 拉取消息进行消费。RocketMQ 支持按 消息队列(Queue) 或 消息主题(Topic) 进行消费,可以配置多种消费策略和消费并发度。
- 消息确认和重试: 消费者确认消息消费成功后,RocketMQ 会将消息从队列中删除;如果消费失败,消息会进入重试队列,按配置重试消费。
ba37ca06-a3f1-4b7f-a03f-d240a586502e
通过本文的介绍,我们可以看到 RocketMQ 作为一款高效的分布式消息中间件,无论你是正在考虑在项目中引入 RocketMQ,还是已经在使用它的开发者,掌握 RocketMQ 的核心特性和最佳实践对于提升系统的可靠性和性能至关重要。后续将分享RocketMQ的部署,及开发使用流程。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号