大型系统高可用管控体系建设
原创

大型系统的高可用性(High Availability, HA)管控体系建设是一个全面的过程,旨在确保系统在面对硬件故障、软件错误或其它异常情况时仍能持续提供服务。这一体系不仅涉及技术层面的实现,还包括流程管理、人员培训和应急预案等多个方面。
管控体系主要是在遇到一些异常情况时提供保护系统的措施,包括开关系统、预案系统、限流降级系统等。
一、开关系统
开关系统主要是管理一些线上常用的操作,尤其是一些带有联动性的操作,通过统一管理可以减少出错的概率。开关系统既要支持基于内存和持久化的操作方式,也要支持单机和集群的灵活操作方式,如下图所示。
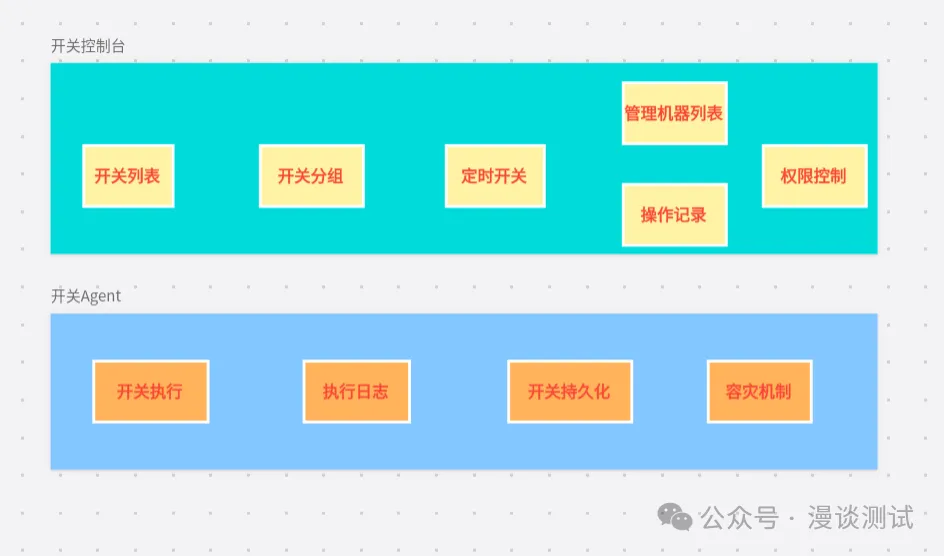
图片
二、预案系统
预案系统整合业务降级开关,保证业务降级的一致性和完整性,保证所有应急预案处理统一调度、统一决策,信息互通、消除孤岛。如下图所示。
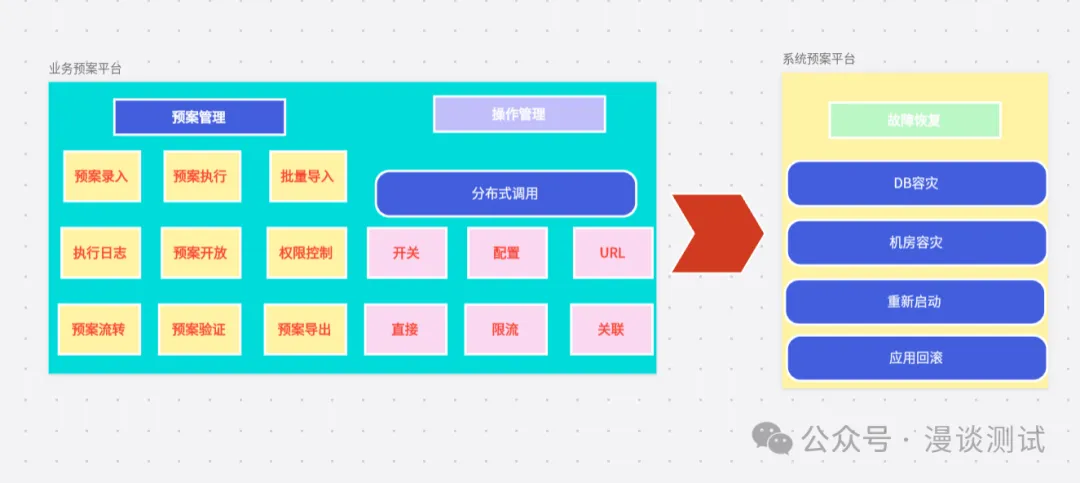
图片
三、限流降级系统
当系统的容量达到瓶颈时,需要执行限流降级来保护系统,既要可以人工执行开关,也要支持自动化的保护;既要支持 URL 以及方法级别的细粒度的限流,也要可以基于 OPS、线程、Load 设置阀值。如下图所示。
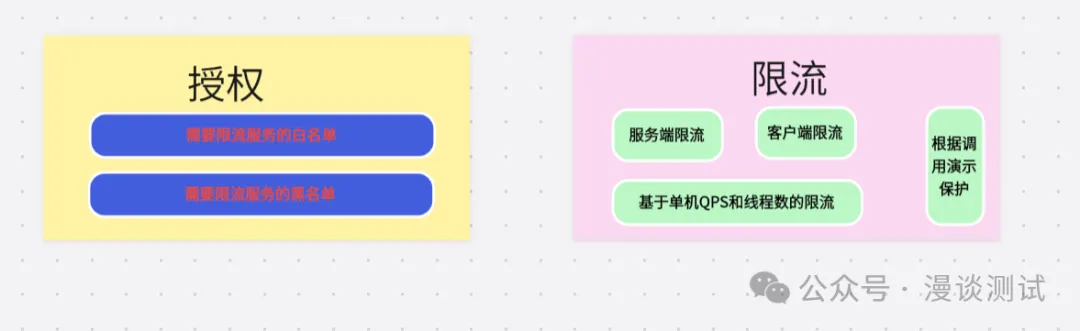
图片
四、以下是构建一个高效高可用管控体系的关键步骤
1. 高可用架构设计
冗余设计:确保关键组件(如数据库、服务器、网络设备等)具备冗余能力,避免单点故障。
分布式部署:采用分布式架构,将应用和服务分散到多个地理位置,以减少区域灾难的影响。
2. 自动化运维工具
自动化部署:使用CI/CD管道实现应用程序的自动构建、测试和部署,提高部署效率并减少人为错误。
自动化监控:部署实时监控工具,如Prometheus、Grafana、Zabbix等,及时发现和响应性能问题。
自动化恢复:配置自动化恢复机制,例如健康检查、自动重启、负载均衡等,以快速从故障中恢复。
3. 容灾备份与恢复计划
数据备份:定期对重要数据进行备份,并验证备份数据的完整性和可恢复性。
异地容灾:建立异地数据中心或云环境作为备用站点,确保在主站点发生重大故障时能够迅速切换到备用地点继续服务。
4. 测试与演练
压力测试:定期执行压力测试,评估系统在极端条件下的表现,并据此优化系统配置。
故障演练:模拟各种可能的故障场景,通过实际演练检验应急响应流程的有效性,同时锻炼团队处理突发事件的能力。
5. 持续改进
反馈循环:建立从问题发现到解决再到预防的闭环管理机制,不断总结经验教训,完善管控措施。
技术更新:紧跟行业发展和技术进步的步伐,适时引入新技术、新方法来提升系统的高可用性水平。
6. 人员培训与意识培养
技能提升:为运维团队提供持续的技术培训,确保他们掌握最新的工具和技术。
文化塑造:培养全体员工对于高可用性的重视程度,形成良好的安全文化和风险意识。
7. 文档化与标准化
文档记录:详细记录所有相关的架构设计、操作指南、故障处理手册等信息,方便团队成员查阅学习。
流程规范:制定并严格执行一系列标准化的工作流程,包括变更管理、发布管理、事件响应等。
8. 合规性与安全性
遵循标准:遵守行业内的最佳实践和相关法规要求,确保系统的安全性和合规性。
安全防护:加强网络安全建设,采取必要的安全措施防止外部攻击导致的服务中断。
大型系统的高可用管控体系建设需要综合考虑技术实现、运营管理、人员素质等多个维度,通过不断的迭代优化,确保系统能够在任何情况下都能稳定运行,满足业务需求。
阅读后若有收获,不吝关注,分享,在看等操作!!!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号