大模型引导的深度强化学习在自动驾驶决策中的应用

大模型引导的深度强化学习在自动驾驶决策中的应用

一点人工一点智能
发布于 2024-12-31 11:17:10
发布于 2024-12-31 11:17:10
编辑:陈萍萍的公主@一点人工一点智能

论文地址:https://arxiv.org/pdf/2412.18511
项目地址:https://bitmobility.github.io/LGDRL/
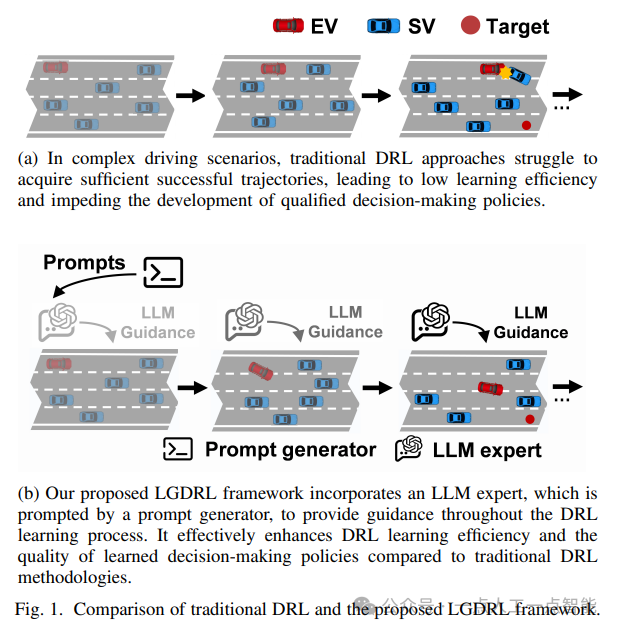
本篇论文提出了一种基于大型语言模型(LLM)引导的深度强化学习(DRL)框架,用于解决自动驾驶车辆决策问题。
该方法通过将LLM专家集成到DRL中,为DRL的学习过程提供智能指导,并利用创新的专家策略约束算法和新颖的LLM干预交互机制来提高DRL决策性能。
实验结果表明,该方法不仅在任务成功率上取得了优异的表现,而且显著提高了学习效率和专家指导利用率。此外,该方法还使DRL代理能够在没有LLM专家指导的情况下保持一致且可靠的表现。

论文方法
1.1 方法描述
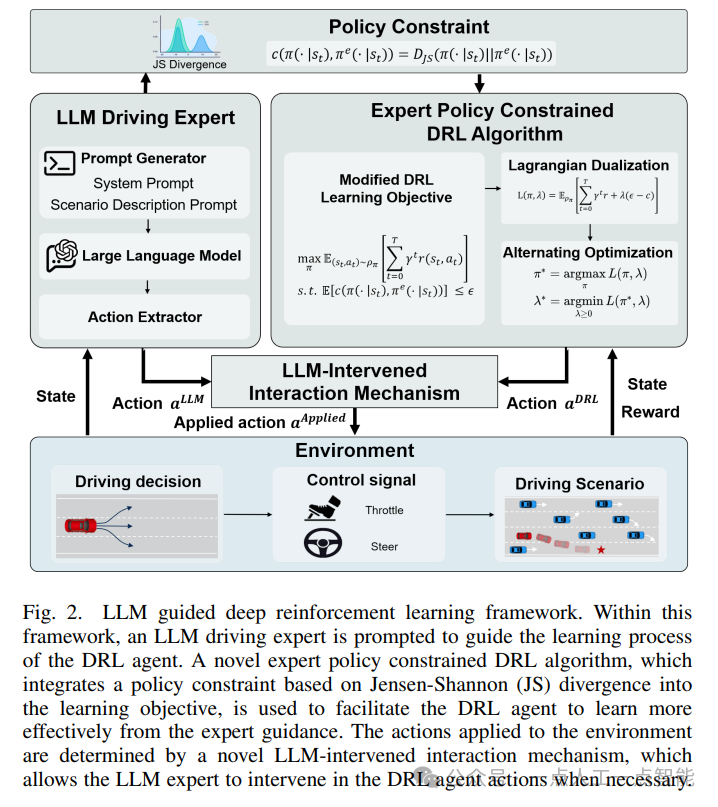
该论文提出了一种基于深度强化学习(Deep Reinforcement Learning)的自动驾驶决策制定问题解决方案。主要组件包括状态空间、动作空间和奖励函数,并通过形式化定义了行为决策制定问题。该方案将自主驾驶车辆的行为决策制定过程建模为马尔可夫决策过程(Markov Decision Process),并利用深度强化学习算法来优化自动驾驶车辆的决策制定策略。
1.2 方法改进
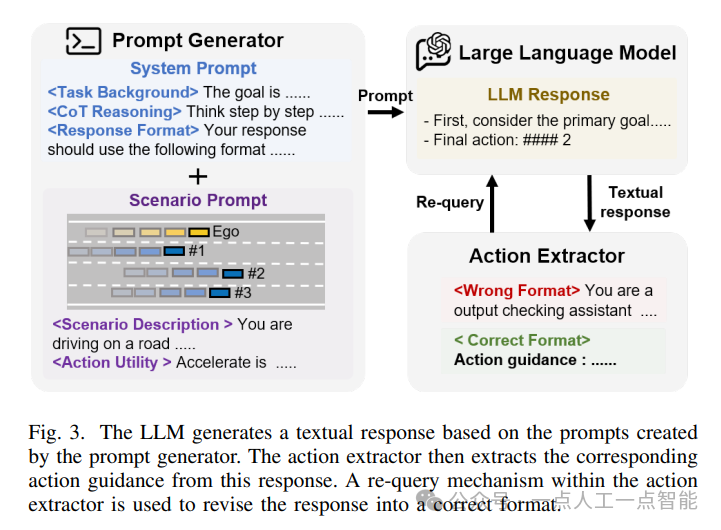
该方案采用了专家指导的深度强化学习算法,即在训练过程中引入了一个车道驾驶专家系统,以提供行动建议。同时,为了提高算法的效率和性能,该方案还提出了约束条件下的深度强化学习算法,通过限制深度强化学习策略与车道驾驶专家系统的差异,使得深度强化学习策略更加接近车道驾驶专家系统的策略。
此外,该方案还设计了一种新的交互机制,称为“专家干预”,用于替代标准的深度强化学习与环境之间的交互方式。当深度强化学习策略产生危险行为时,专家干预机制会替换深度强化学习策略的行动建议,从而避免潜在的风险。
1.3 解决的问题
该方案解决了自动驾驶中的行为决策制定问题,通过对深度强化学习算法进行改进和约束,以及引入车道驾驶专家系统和专家干预机制,提高了自动驾驶车辆的决策制定能力和安全性。这种方法可以应用于实际道路测试和自动驾驶汽车的研发中。

论文实验
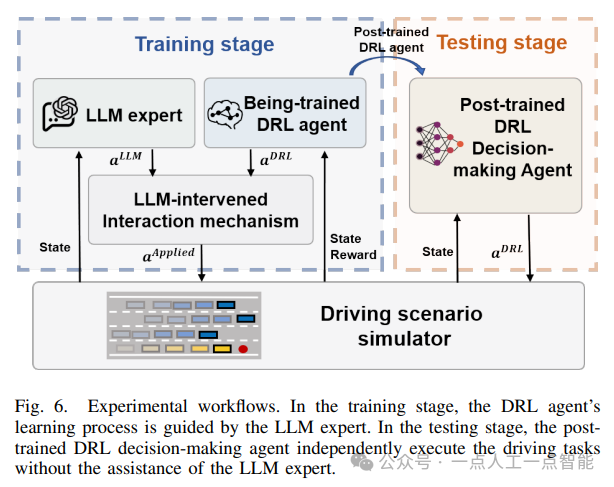
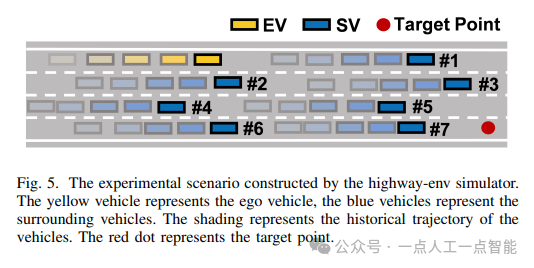
本文主要介绍了在高速公路驾驶场景下,使用深度强化学习(DRL)算法实现自动驾驶的研究。作者首先构建了一个实验场景,并引入了几个基准方法进行比较。然后,详细阐述了DRL算法的实现细节。
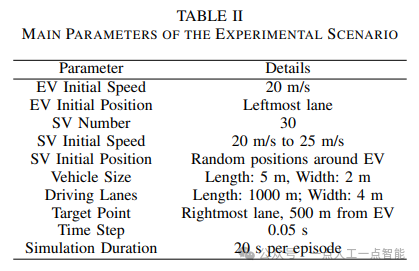
实验场景中包括四个车道,每个车道长1000米,宽4米,限速为30米/秒。车辆初始速度为20米/秒,目标点位于最右侧车道500米处。同时,周围有30辆随机位置和速度的其他车辆。实验过程中,每一步的时间间隔为0.05秒,总时间为20秒。这些参数被总结在表II中。
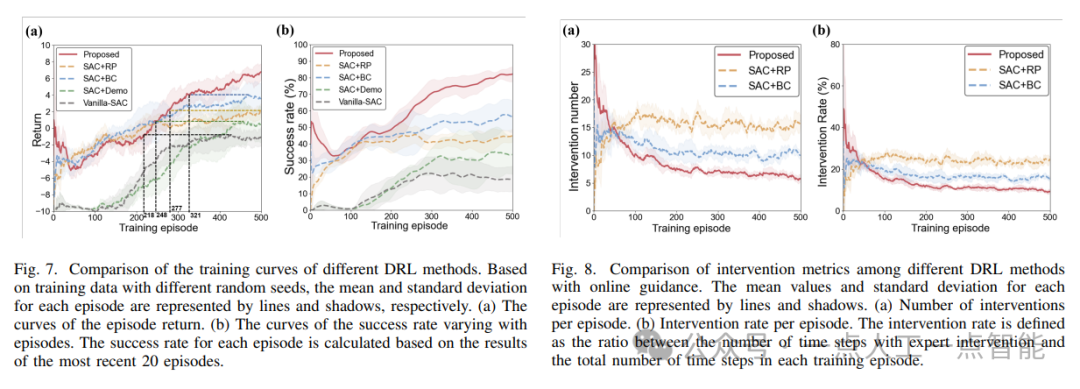
基准方法分为三类。第一类是Vanilla-SAC,没有专家指导,直接使用标准DRL算法进行训练。第二类包括SAC+RP和SAC+BC,这两种方法都使用在线专家,在学习过程中实时提供干预。第三类是SAC+Demo,使用离线专家,即预先收集的专家演示数据,不参与学习过程中的干预。所有基准方法均使用相同的神经网络架构,并在PyTorch上使用Adam优化器进行训练。实验结果如图7所示。

通过比较不同DRL方法的训练曲线,可以发现LGDRL在成功率和回报率方面表现最好。此外,LGDRL还可以在没有任何人类干预的情况下独立完成任务。因此,LGDRL是一种高效且可靠的自动驾驶解决方案。

论文总结
论文提出了一种新颖的LGDR框架,用于解决自动驾驶车辆的车道变道决策问题。在该框架中,设计了基于LGD的驾驶专家来提供指导,并引入了专家约束条件以更有效地利用专家知识。实验结果表明,所提出的LGDR方法在训练和测试性能方面均优于其他基准方法,具有较高的效率和准确性。
未来将进一步探索将该框架应用于其他复杂驾驶场景的可能性,研究如何结合其他技术(如多模态数据处理)来进一步提高自动驾驶系统的性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号