数据合并与数据关联:数据处理中的核心操作
原创
数据合并与数据关联:数据处理中的核心操作
原创
KPaaS集成扩展
发布于 2025-01-16 17:38:55
发布于 2025-01-16 17:38:55
在数据分析和处理过程中,数据合并(Data Merging)和数据关联(Data Association)是两个非常重要的操作。它们分别用于整合不同数据集中的信息以及发现数据之间的潜在关系。
数据合并(Data Merging)
数据合并是指将多个数据集整合为一个数据集的过程。通常,数据合并基于某些共同的列或键(Key)进行,这些列或键在两个或多个数据集中都存在。数据合并的主要目的是将分散的数据整合到一个统一的结构中,以便后续的分析和处理。
数据合并的常见方法
数据合并可以分为两种主要方式:纵向合并和横向合并。
纵向合并(Concatenation)
纵向合并是指将多个数据集按行或列拼接在一起。这种合并方式通常用于数据结构相同但数据内容不同的情况。例如,将多个月份的数据表按行拼接成一个年度数据表。
在Python的Pandas库中,可以使用pd.concat()函数实现纵向合并:
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [3, 4], 'B': [5, 6]})
# 按行拼接
result = pd.concat([df1, df2], ignore_index=True)
print(result)横向合并(Joining/Merging)
横向合并是指基于某些共同的列或键将两个数据集合并在一起。这种合并方式通常用于将不同来源的数据整合到一个表中。例如,将用户基本信息表和用户订单表通过用户ID进行合并。
在Pandas中,可以使用pd.merge()函数实现横向合并:
df1 = pd.DataFrame({'ID': [1, 2], 'Name': ['Alice', 'Bob']})
df2 = pd.DataFrame({'ID': [2, 3], 'Order': ['Book', 'Pen']})
# 基于ID列进行合并
result = pd.merge(df1, df2, on='ID', how='inner')
print(result)数据合并的类型
在横向合并中,根据合并方式的不同,可以分为以下几种类型:
- 内连接(Inner Join):仅保留两个数据集中连接键(即用于匹配的字段)都存在匹配的行。换言之,只显示两个表中都有对应记录的行。
- 左连接(Left Join):保留左表的所有行,即使右表中没有匹配的行。对于左表中没有对应匹配的行,右表的部分将会填充为NULL(通常用NaN表示)。
- 右连接(Right Join):与左连接相反,保留右表的所有行。对于右表中没有对应匹配的行,左表的部分将会填充为NULL。
- 全外连接(Full Outer Join):保留两个表中的所有行。对于任意一个表中没有对应匹配的行,另一个表的部分将会填充为NULL。
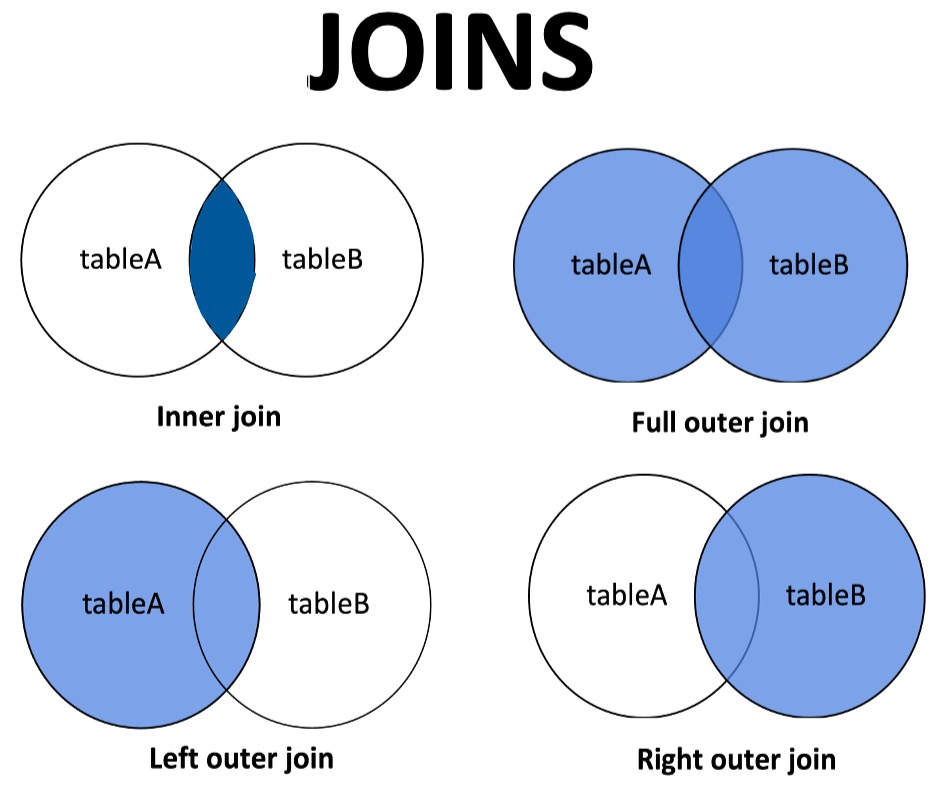
例如,以下代码展示了不同类型的合并方式:
# 内连接
result_inner = pd.merge(df1, df2, on='ID', how='inner')
# 左连接
result_left = pd.merge(df1, df2, on='ID', how='left')
# 外连接
result_outer = pd.merge(df1, df2, on='ID', how='outer')数据合并的应用场景
数据合并在实际工作中有广泛的应用场景,例如:
- 将多个部门的数据整合到一个统一的数据库中。
- 将用户的基本信息与行为数据进行关联。
- 将不同时间段的数据拼接成一个完整的时间序列数据集。
数据关联(Data Association)
数据关联是指识别不同数据集中记录之间关系的过程。与数据合并不同,数据关联的主要目的是发现数据之间的潜在关系或模式,而不是简单地将数据整合在一起。数据关联在数据挖掘和机器学习中有着重要的应用,例如购物篮分析、推荐系统等。
数据关联的常见方法
数据关联可以通过多种方法实现,以下是几种常见的技术:
关联规则学习(Association Rule Learning)
关联规则学习是一种用于发现变量之间有趣关系的技术。它通常用于市场篮分析,例如发现“如果顾客购买了A商品,那么他们也可能购买B商品”的规则。
常用的关联规则学习算法包括Apriori算法和FP-Growth算法。以下是使用Apriori算法的一个示例:
from mlxtend.frequent_patterns import apriori, association_rules
# 示例数据集
dataset = [['Milk', 'Bread'], ['Milk'], ['Bread', 'Beer'], ['Milk', 'Bread', 'Beer']]
# 转换为One-Hot编码
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 生成频繁项集
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# 生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print(rules)相关性分析(Correlation Analysis)
相关性分析用于衡量两个变量之间的线性关系。常用的相关性分析方法包括Pearson相关系数和Spearman相关系数。例如:
import pandas as pd
# 示例数据
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [2, 4, 6, 8]})
# 计算Pearson相关系数
correlation = df['A'].corr(df['B'])
print(correlation)主成分分析(PCA)
主成分分析(PCA)是一种降维技术,它通过识别数据中的主要成分来发现变量之间的关系。PCA通常用于高维数据的可视化和特征提取。
数据合并与数据关联的区别
尽管数据合并和数据关联都是数据处理中的重要操作,但它们的目的和应用场景有所不同:
目的:
- 数据合并的主要目的是整合多个数据集,形成一个统一的数据结构。
- 数据关联的主要目的是发现数据之间的关系或模式。
操作对象:
- 数据合并通常针对多个数据集进行操作。
- 数据关联可以针对单个数据集或多个数据集中的变量进行操作。
输出结果:
- 数据合并的输出是一个整合后的数据集。
- 数据关联的输出是关系规则、模式或相关性指标。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号