VINGS-Mono:大规模场景中的视觉-惯性高斯溅射单目SLAM

VINGS-Mono:大规模场景中的视觉-惯性高斯溅射单目SLAM

点云PCL博主
发布于 2025-02-19 22:00:47
发布于 2025-02-19 22:00:47
文章:VINGS-Mono: Visual-Inertial Gaussian Splatting Monocular SLAM in Large Scenes
作者:Ke Wu, Zicheng Zhang, Muer Tie, Ziqing Ai, Zhongxue Gan, Wenchao Ding
编辑:点云PCL
主页: https://vings-mono.github.io(代码即将开源)
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
从技术角度观察行业发展,努力跟上时代的步伐。公众号致力于点云处理,SLAM,三维视觉,具身智能,自动驾驶等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系dianyunpcl@163.com。文章未申请原创,未经过本人允许请勿转载
摘要
VINGS-Mono 是一种面向大规模场景的单目(惯性)高斯溅射(GS)SLAM框架,包含四个主要模块:VIO前端、2D高斯地图、NVS闭环检测和动态滤波器。在VIO前端中,RGB帧通过密集束调整和不确定性估计提取场景几何与位姿;基于此,建图模块逐步构建并维护2D高斯地图。2D高斯地图的核心组件包括基于采样的光栅化器、分数管理器和位姿优化模块,共同提升建图速度与定位精度,使SLAM系统能够处理包含多达5000万高斯椭球的大规模城市场景。为确保大尺度场景的全局一致性,我们设计了闭环模块,创新性地利用高斯溅射的新视角合成(NVS)能力进行闭环检测与高斯地图修正。此外,针对现实室外场景中动态物体的干扰,文章提出动态滤波器。通过在室内外环境的广泛评估,本方法在定位性能上与视觉-惯性里程计(VIO)相当,并超越近期基于GS/NeRF的SLAM方法,同时在建图与渲染质量上显著优于现有方法。我们还开发了移动端应用,验证了仅通过智能手机摄像头与低频IMU传感器即可实时生成高质量高斯地图。据我们所知,VINGS-Mono是首个支持户外场景与千米级大规模环境的单目高斯SLAM方法。

图1:VINGS-Mono 在三种不同场景下的轨迹估计和重建的高斯地图。该方法能够在大规模驾驶场景、无人机航拍视角和室内环境中有效估计位姿并重建高质量的高斯地图。特别是左侧的驾驶场景,其轨迹跨度达3.7公里,高斯地图包含3250万个高斯椭球。在训练过程中,我们跟踪高斯点的数量,并对特定区域进行放大,以提高可视化清晰度。
主要贡献
本文介绍了 VINGS-Mono,一种支持 大规模城市场景 的 单目(惯性)高斯点绘制(GS)SLAM 框架。该框架由四个主要模块组成:VIO 前端、2D 高斯地图、NVS 回环检测和动态物体清除器。关键技术创新:
- 高斯地图存储与优化效率:我们开发了一种 评分管理器(Score Manager),通过整合局部和全局地图表示来管理 2D 高斯地图,提升存储和优化效率。
- 加速 GS 反向传播计算:我们设计了一种 采样光栅化器(Sample Rasterizer),优化高斯点绘制的反向传播算法,显著提升计算效率。
- 提高位姿精度,降低大场景漂移:我们提出了一种 单帧到多帧位姿优化(Single-to-Multi Pose Refinement) 模块,该模块通过单帧渲染误差的反向传播来优化整个视锥体范围内的所有帧位姿,提高全局位姿一致性。
- 回环检测与大规模地图修正:我们利用 高斯点绘制的新视图合成(NVS) 进行 回环检测,并设计了一种高效的 回环修正方法,能够在检测到回环后 同时调整数千万个高斯属性,有效消除累积误差,确保地图的全局一致性。
- 动态物体处理:我们设计了一种基于 重渲染损失 的启发式 语义分割掩码 生成方法,以有效识别并去除动态物体,提高建图的鲁棒性。
主要贡献:
- ✅ 首个支持户外大规模城市场景 的 单目(惯性)GS-SLAM 系统,能够在公里级场景 运行。
- ✅ 提出 2D 高斯地图模块,包含采样光栅化器、评分管理器和单帧到多帧位姿优化,实现高精度定位 和 实时高质量高斯地图构建。
- ✅ 创新性 GS 回环检测方法,并提出一种 可一次性修正数千万高斯属性的高效回环修正策略,有效消除累积误差,确保地图的 全局一致性。
- ✅ 在 多种场景(室内、无人机航拍、驾驶场景) 进行了 全面实验,结果表明 VINGS-Mono 在渲染质量和定位精度上均优于现有方法。此外开发了一款移动应用 并在 真实环境 中验证了该方法的实用性与可靠性。
主要内容
系统架构概述
框架流程如图 2 所示。给定 RGB 图像序列和 IMU 读数,我们首先利用 视觉-惯性前端选择关键帧,并通过稠密束调整 计算关键帧的初始深度和位姿信息。此外基于深度估计过程中的协方差计算 深度图的不确定性,从而过滤掉 几何不准确区域和天空区域。2D高斯地图模块利用视觉前端的输出 逐步添加并维护高斯椭球。我们设计了一种 基于贡献评分和误差评分 的管理机制,以有效裁剪冗余高斯点。此外提出了一种 基于单帧渲染误差的多帧位姿优化方法,提高全局位姿一致性。为了 适应大规模城市场景,我们 实现了 CPU-GPU 内存传输机制,提高计算效率。在 NVS 回环检测模块中,我们利用 高斯点绘制的新视图合成(NVS) 设计了一种创新性的 回环检测方法,并通过 高斯-位姿对匹配 来修正高斯地图。此外集成了 动态物体清除模块,该模块能够 屏蔽短暂出现的动态物体(如车辆和行人),确保在 静态场景假设下 进行一致且精准的建图。
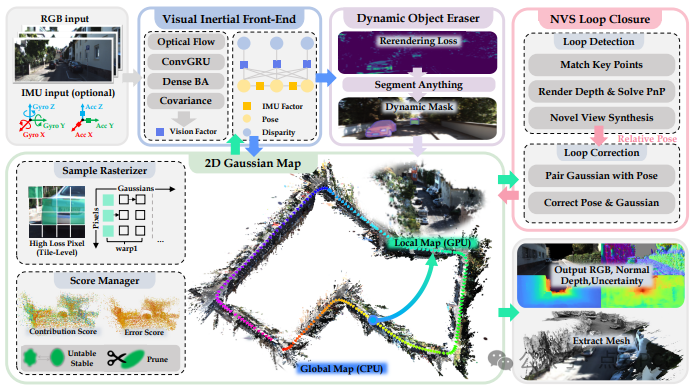
图 2:VINGS-Mono 流程概述。RGB 图像和 IMU 读数由 视觉-惯性前端 处理,以计算位姿和逆深度。基于此,2D 高斯点绘制(GS)地图 逐步更新,并包含 评分管理器、采样光栅化和位姿优化。NVS 回环检测 利用 新视图合成(NVS) 进行高效的回环检测与修正,实现无缝闭环优化。此外动态物体清除模块 可有效减少动态物体对整个框架的影响。
视觉-惯性前端
1
稠密束调整与视觉约束
视觉信息的处理基于 稠密束调整(Dense Bundle Adjustment, DBA),其优化变量包括逆深度和相机位姿。具体而言,该模块从相邻的 RGB 帧中提取特征,并使用 RAFT(Recurrent All-Pairs Field Transforms)算法构建相关体积,从而计算光流场并估计场景的深度信息。
为了实现高效的深度估计,系统采用了一种 GRU(门控循环单元)网络结构。GRU 以当前图像的编码特征、相关体积中的光流特征以及自身的隐藏状态作为输入,并输出光流残差和优化权重。这些输出随后被用于光流场的修正以及深度估计的上采样处理。
为了提高计算效率,该模块会将原始图像的分辨率缩小 8 倍,因此逆深度的计算是在低分辨率空间中进行的。在每次迭代优化过程中,系统会基于 GRU 输出的修正光流场来调整逆深度和相机位姿,并通过高斯-牛顿(Gauss-Newton)方法求解最优解。
在优化过程中,系统会构建包含多个帧之间约束关系的Hessian 矩阵,其中包含了各个帧之间的视觉观测关系。这些矩阵块通过特定的数值优化方法进行求解,并且利用 GPU 进行并行加速计算,以提高优化效率。
最终,通过消元计算(Schur Complement),系统可以消除深度变量,仅保留帧间的位姿约束信息。这一过程等效于一个线性化的视觉束调整(BA),从而可以更高效地优化位姿和深度信息。
2
视觉-惯性因子图
为了融合视觉和惯性数据,系统采用 因子图(Factor Graph)优化 方法。该因子图的节点表示系统状态变量,包括:
- IMU 在世界坐标系下的位姿;
- IMU 在世界坐标系下的速度;
- IMU 加速度计和陀螺仪的偏差。
在因子图优化中,视觉因子由视觉束调整(DBA) 计算得到,并通过Schur 消元 进一步优化,最终形成帧间位姿约束。与此同时,IMU 预积分因子则提供额外的运动信息约束。因子图的整体优化基于 GTSAM(Georgia Tech Smoothing And Mapping)库进行实现,能够有效地融合视觉与惯性数据,提高位姿估计的精度。
此外,在因子图构建过程中,所有的位姿变量均以 IMU 坐标系为基准,而视觉约束则是基于相机-IMU 外参 进行转换。这意味着,最终计算出的位姿是 IMU 坐标系下的位姿,而非直接从相机坐标系中获取。
IMU 预积分的计算方式参考了一种已有的方法,该方法能够在不同帧之间累积 IMU 测量值,并形成一个运动约束。具体来说,IMU 预积分约束包括:
- 位置约束:描述相邻帧之间的相对平移;
- 速度约束:描述相邻帧之间的速度变化;
- 旋转约束:描述相邻帧之间的旋转变换;
- 传感器偏差约束:对 IMU 的加速度计和陀螺仪偏置进行建模。
通过因子图优化,系统能够将视觉信息和惯性信息进行紧密融合,最终获得更为准确和鲁棒的位姿估计。
3
深度不确定性估计
在视觉-惯性 SLAM(同时定位与建图)任务中,由于视觉测量的不确定性,深度估计往往存在噪声和伪影。为了缓解这一问题,该系统基于信息矩阵(Information Matrix) 对深度不确定性进行建模,并通过稠密束调整(DBA) 提取每个像素逆深度的边缘协方差。
该方法的核心思想是:使用 Hessian 矩阵的稀疏形式来计算每个像素的逆深度不确定性。具体而言,系统通过 Cholesky 分解等方法求解边缘协方差,并最终获得每个像素的逆深度不确定性。该不确定性信息可用于:
- 抑制噪声影响,提高深度估计精度;
- 减少“漂浮点”(浮动点云)的生成,避免场景结构扭曲;
- 提高 SLAM 过程中的鲁棒性。
最终,结合视觉-惯性前端的所有信息,包括:
- 相机位姿序列;
- 深度图;
- 深度不确定性;
- RGB 图像数据。
系统可以逐步构建并维护一个二维高斯概率地图(2D Gaussian Map),用于后续的 SLAM 任务,如优化回环检测、全局地图对齐等。
2D 高斯溅射地图
1
在线建图过程
2D 高斯地图的初始化是在 VIO(视觉惯性里程计)前端处理完首批关键帧后进行的。首先,对于每一帧图像,系统会筛除深度过大或不确定性高的像素点,确保输入数据的可靠性。随后,从剩余的像素中随机采样 50,000 个点,并将它们投影到世界坐标系中,生成点云。接着,这些点的高斯属性会按照 2DGS 方法进行初始化,包括均值、尺度、透明度和颜色等信息。
在渲染过程中,系统会按照 2DGS 方法生成 颜色、深度、法向量和累积值,并使用深度信息和法向量的方向来优化高斯椭球的渲染结果。渲染过程中,每个高斯点的深度值决定其在相机坐标系中的位置,而法向量的方向与相机视线对齐,以保证正确的可视化效果。
建图模块与 VIO 前端并行运行,并持续进行增量式地图更新。在原始 3DGS 方法中,密集化(densification)采用的是克隆-分裂策略,但该方法在 GS-SLAM(高斯 SLAM)中表现不佳,特别是在需要重置透明度时效果欠佳。因此,本文采用了先添加大量高斯点,再进行筛选的方法,以提高建图质量。
当前端添加新的关键帧时,新的高斯椭球会被加入地图,并在训练前进行优化。首先,系统会渲染该关键帧的颜色和深度信息,然后执行两个关键操作:
1. 删除冲突高斯点:
- 在当前关键帧的视锥体(view frustum)内,如果某个高斯点的深度误差或颜色误差过大,则会被删除。
- 如果某个高斯点的投影半径过大(意味着其覆盖范围过广,可能影响建图质量),也会被移除。
2. 添加新的高斯点:
- 在低累积值区域(即当前高斯点较少的地方),会根据深度信息添加新的高斯点。
- 添加新高斯点的数量取决于低累积像素区域相对于总像素区域的比例。
- 先添加冗余的高斯点,再进行选择性筛选,确保最终的建图结果具有更好的质量。
这种先增加、再筛选的策略在前向视角场景(如自动驾驶)中尤其有效,能够避免密集化过程中出现的透明度问题,并提高地图的完整性。
在新增高斯点后,系统会从最新的关键帧列表中随机抽取帧进行训练。训练过程中,系统会计算一个损失函数,包括颜色损失、深度损失、法向量损失和累积损失。其中,累积损失用于确保被遮挡的区域不会出现不合理的黑色高斯点。在每次训练迭代时,系统会记录并更新每个高斯点的局部贡献分数和误差分数,这些变量用于管理高斯点。
2
评分管理器
为了有效管理每个高斯椭球,本文提出了一种评分机制,主要涉及状态控制、存储控制和 GPU-CPU 传输。其核心思路是通过计算贡献分数和误差分数,确保每个高斯点既能提供最大贡献,又不会引入过多误差。
1. 贡献分数:
- 计算某个高斯点在所有关键帧中的累计贡献值。
- 贡献值的计算方法是:统计该高斯点覆盖的所有像素,并累加其权重,得到该帧的贡献值。
- 最终,将该高斯点在所有关键帧中的贡献值求和,得到其总贡献分数。
2. 误差分数:
- 计算某个高斯点在所有关键帧中的误差值。
- 误差值由高斯点覆盖的像素的颜色损失累加得到,但在所有关键帧中,取最高的误差值作为最终误差分数。
此外,每个高斯点还会被赋予一个 ID 标识,表示在哪个关键帧中贡献最大。这些评分机制用于指导高斯点的存储和状态管理:
1. 状态控制:
- GPU 上的高斯点分为稳定和不稳定两种状态。
- 在一定训练迭代(400 次)后,贡献分数较低的不稳定高斯点会被移除,以减少存储和计算开销。
- 误差分数过高的稳定高斯点会被标记为不稳定,允许它们被重新优化,以适应新环境。
2.存储控制:
- 每 200 次迭代后,系统会清理贡献分数过低且处于不稳定状态的高斯点,以减少冗余存储。
- 在多房间环境或复杂道路结构中,历史高斯点可能重新进入视野。系统不会简单地根据投影半径或距离删除高斯点,而是通过稳定状态来决定是否保留,以避免误删重要信息。
3.GPU-CPU 传输:
- 由于 GPU 内存有限,系统需要在 GPU 和 CPU 之间动态管理高斯点。
- 每 8 个关键帧后,系统会根据位姿计算哪些高斯点需要驻留在 GPU,哪些可以转移到 CPU 存储,以优化计算和渲染效率。

3
采样光栅化器
在原始的高斯溅射方法(Gaussian Splatting)中,前向传播和反向传播是完全对称的,每个 GPU 线程处理一个像素,并将其损失回传到所有覆盖该像素的高斯点。这导致了一个性能瓶颈:计算时间由覆盖最多高斯点的像素决定。本文参考了 Taming 3DGS 和 NeRF 方法,优化了反向传播机制:
1. 存储中间变量:
- 在前向传播阶段,每个线程会存储中间计算结果,每 32 个高斯点存储一次,以减少计算冗余。
2. 优化计算分工:
- 反向传播阶段,GPU 被划分为多个 warp(每个 warp 由 32 个线程组成),并让每个 warp 处理固定数量的高斯点,降低单个线程的计算负担。
3. 重点采样:
- 在每个 16×16 的像素块中,仅选择损失较高的 50% 像素进行反向传播。
- 这一策略显著减少了计算量,使反向传播速度提升 273%。
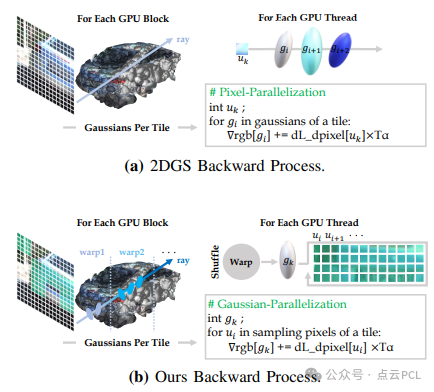
图 3:采样光栅化器。在我们的反向传播过程中,每个线程负责一个高斯点,迭代次数取决于采样的像素数量。
4
单帧到多帧位姿优化
现有的基于高斯的方法通过优化高斯点的位置,间接优化相机位姿,但这一过程效率较低。本文改进了这一方法:
1. 高斯点与关键帧关联:
- 计算每个高斯点与其关联的关键帧,并建立位姿变换矩阵作为优化变量。
2. 多帧位姿优化:
- 在反向传播过程中,同时优化多个关键帧的位姿,而不是仅优化当前帧。
- 通过渲染 RGB 图像并最小化损失,调整所有关键帧的位姿,提高整体优化效果。
NVS 回环闭合
在没有尺度信息的单目设置中,回环闭合对于消除由于连续移动而积累的误差尤其重要,尤其是在大规模环境中。为了解决这一问题,我们提出了一种基于高斯渲染的回环检测与修正方法。不同于传统的基于词袋模型(BoW)来进行回环检测的方法,我们采用了高斯渲染的新视角合成能力,从新视角合成的图像来判断是否存在回环闭合。接下来,我们利用图优化方法来修正历史帧的位姿,并通过高斯点的帧索引 ID(g) 来修正 2D 高斯地图。
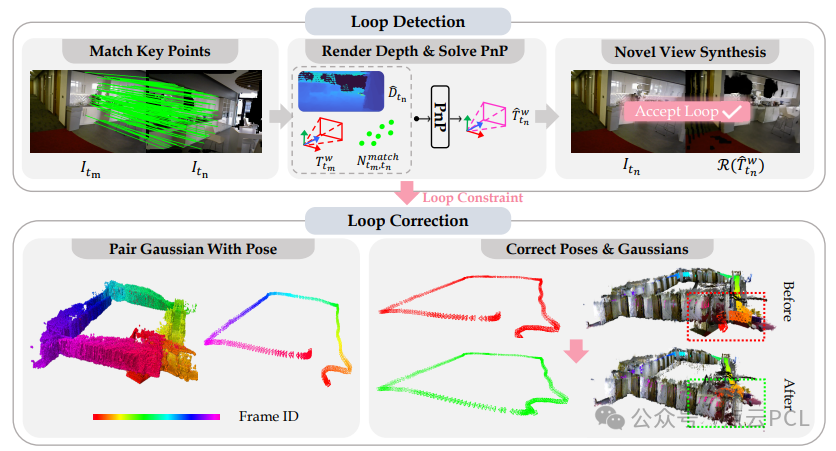
图 4:NVS 回环闭合的流程。我们对符合距离阈值要求的关键帧进行特征匹配、筛选和新视图合成,从而实现回环检测。一旦检测到回环,我们通过将高斯与姿态配对对齐和图优化来实现姿态和高斯地图的回环修正。
1
回环检测
回环检测的过程可以分为三个主要步骤:首先,通过与历史帧匹配特征点来找到潜在的回环;接着,通过匹配到的特征点和深度图计算两个帧之间的相对位姿;最后,通过新位姿合成新的视角图像来判断是否存在回环闭合。
- 匹配关键点:首先,我们从当前帧的位姿出发,提取并与历史帧中的特征点进行匹配。历史帧是指那些与当前帧的位姿距离在一定范围内,并且帧 ID 与当前帧的差异超过十个的帧。我们记录每一对历史帧与当前帧之间成功匹配的特征点数量。若某帧的匹配点数超过了预设的阈值(比如50个),那么这些历史帧将根据匹配点数进行降序排列。
- 估计相对位姿:对于降序排列后的历史帧,我们根据匹配的特征点计算这些帧之间的相对位姿。通过 Perspective-n-Point(PnP)方法来估算两个帧之间的相对位置和姿态。随后,通过全局位姿转换得到当前帧的全局位姿。
- 新视角合成:核心问题是判断两张图像是否捕捉到相同的场景。借助高斯渲染技术,我们能够生成一个新的视角,并通过与原始图像进行对比来判断是否存在回环闭合。如果合成的新图像与原始图像之间的颜色差异低于某个特定阈值,或者小于所有历史帧的中位数颜色差异的十分之一,那么就认为检测到回环闭合。
2
回环修正
在成功检测到回环闭合后,接下来需要修正历史帧的位姿和高斯地图。由于大规模环境中的回环闭合误差较大,直接根据回环闭合约束来优化高斯地图是不可行的。直接对高斯地图进行训练可能无法有效收敛,因此我们采取了更为稳妥的方法:首先将每个高斯点与历史关键帧的位姿进行关联,确保高斯地图与历史位姿保持一致,然后对其进行微调。
- 将高斯与位姿配对:对于每一个历史关键帧,我们依次计算每个高斯点在该帧中的贡献,并记录每个高斯点与其对应的位姿。然后,选择贡献最大的位置作为高斯点的匹配位姿。由于渲染速度非常快,这个过程在大约两秒钟内就能完成一千帧的计算。
- 修正位姿与高斯:接下来,我们为所有历史帧构建一个位姿图,并将回环闭合约束添加到位姿图中。通过图优化方法,更新所有历史关键帧的全局位姿。在计算过程中,我们还需要考虑历史帧的尺度信息,通过比较变换前后的平移向量,来计算并修正历史关键帧的尺度。最终,我们计算每个高斯点的新的位置和旋转,同时保持其他属性不变。然后,我们对所有历史关键帧进行多次训练,以进一步优化模型。最后,基于一定的标准,我们对高斯点进行修剪,从而减少存储开销。
通过这一系列步骤,回环闭合不仅可以消除由位姿误差引起的偏差,还能优化整个系统的精度和稳定性,特别是在大规模环境下,能够有效减少长期累积的误差。
动态物体滤波器
高斯溅射技术的基本假设是场景中的物体是静态的。然而,在实际应用中,尤其是在大规模环境中,动态物体(如车辆和行人)是常见的,并且会干扰高斯建图的准确性。传统的动态高斯溅射方法一般是在离线训练环境下进行的。这些方法会建模4D空间,并通过离线方式训练数据集中高斯属性与时间之间的关系。但这些方法并不适用于SLAM(同步定位与地图构建),因为SLAM需要增量式地加载数据并实时更新。考虑到SLAM是一个在线过程,并且高斯溅射能够进行新视图合成,我们设计了一种基于启发式引导的动态物体分割方法,以便有效区分并去除动态物体对高斯建图的影响。
该方法首先使用一个加速的开放集语义分割模型,在整个图像上生成一组语义掩膜,表示图像中不同物体的类别。当一个新的关键帧到达时,我们首先通过渲染当前帧的颜色来准备数据,并计算与新关键帧的图像之间的SSIM损失和L1损失。SSIM损失对图像中的纹理变化特别敏感,而L1损失则主要反映颜色值的差异。通过将这两个损失相乘,我们计算出一个综合的重新渲染损失。为了精确评估动态物体的影响,我们对每个像素的损失进行计算,并取90%分位数作为评估标准。
对于一些动态物体,如移动的车辆或行人,往往具有较为平滑的纹理,这使得它们的重新渲染损失主要集中在边缘区域。因此,我们对损失的计算进行了优化,加入了深度不确定性因素,使得我们能够更有效地识别和处理这些动态物体。在计算中,动态物体的掩膜会根据损失值进行过滤,确保这些动态物体不会影响新的高斯生成或后续的渲染过程。
最终,通过结合SSIM和L1损失以及深度不确定性信息,我们能够识别出动态物体的区域,并在高斯建图的构建过程中将其去除。这一方法能够有效减少动态干扰物对高斯溅射生成地图的影响,从而提高SLAM系统的鲁棒性和准确性。
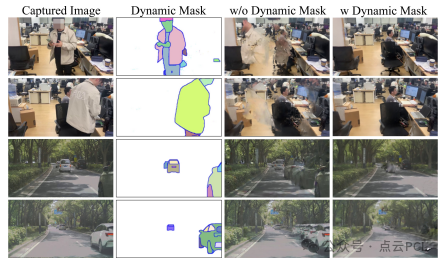
图 5:动态物体去除器的效果。我们的动态去除器能够过滤掉室内的行人和室外的快速移动车辆,防止高斯地图受到动态浮动物体的影响。
实验
我们进行了全面的比较实验,评估了我们的框架在跟踪性能和高斯溅射(Gaussian Splatting)建图性能方面的表现。此外,我们还进行了动态物体滤波的比较实验,并对系统的各个组件进行了消融研究。最后,我们分析了系统的运行时间,并介绍了我们开发的移动应用程序以及现实世界的实验。
实验设置
数据集与指标:为了验证我们算法的有效性和鲁棒性,我们仅使用真实世界的数据集,而非模拟数据。我们的实验包括两个大规模室内场景、一个经典的动态室内SLAM数据集以及五个不同的户外场景,这些场景具有不同的光照条件、运动速度和采集设备。此外,我们还使用消费级智能手机的传感器收集了真实世界的数据。
参数和实现细节:所有实验结果都使用一台单独的RTX 4090 GPU和Intel Xeon 6133 CPU(2.50GHz)记录。预设参数分为三个部分:前端、高斯地图和回环闭合检测。

图6: 小城市场景中VO的性能。由于被大型浮动物体遮挡,MonoGS在跟踪时失败,而由于缺乏复杂纹理和快速运动,PhotoSLAM无法匹配特征点并重新定位到起始点。相比之下,我们的方法稳定且强健地实现了定位,并构建了高质量的高斯地图。
定位性能
在本节中,我们比较了VINGS-Mono的位姿估计性能与传统SLAM方法和基于高斯溅射的方法。
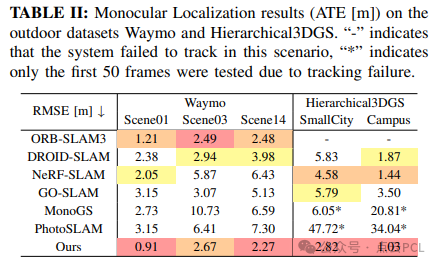
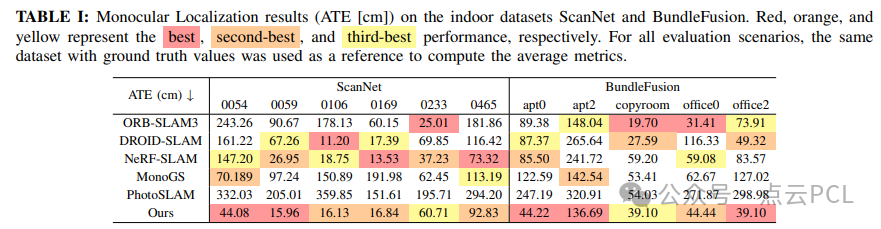
VO比较:我们在两个大规模室内场景数据集以及两个户外场景数据集上进行了实验。为了评估,我们选择了代表性的传统SLAM方法ORB-SLAM3 和 DROID-SLAM。为了确保DROID-SLAM的公平比较,我们省略了全程运行后的全局BA后处理步骤。值得注意的是,这些方法无法构建高斯地图。此外,我们还包括了一种基于NeRF的SLAM方法,以及两种最先进的基于单目高斯的SLAM方法MonoGS 和 Photo-SLAM。
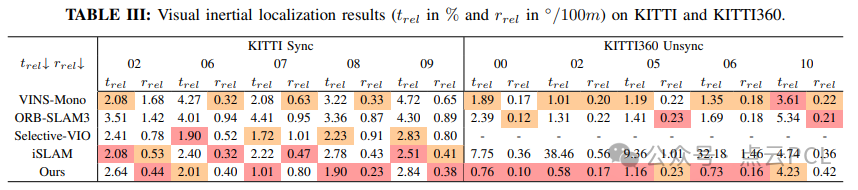
VIO比较:我们比较了在竞争性KITTI 和 KITTI-360数据集上的纯里程计精度。由于公里级别城市场景的显著存储和计算需求,现有的NeRF/3DGS-based SLAM方法无法在这两个数据集上运行。因此,我们选择了两种基于特征的方法VINS-Mono和ORB-SLAM3,以及两种先进的基于学习的方法iSLAM和 Selective-VIO 进行比较。
渲染性能
本节比较了VINGS-Mono与基于NeRF的方法和基于3DGS的方法的渲染性能。
1) 室内渲染结果:
在ScanNet和BundleFusion数据集上评估了VINGS-Mono与GO-SLAM(NeRF方法)、MonoGS和PhotoSLAM(基于3DGS的方法)的渲染质量。我们的方法在大多数场景中优于PhotoSLAM,稳定性更强,避免了后期追踪过程中漂浮物覆盖整个帧的问题。表V显示,我们的方法在ScanNet和BundleFusion数据集上均取得了最佳的定量表现。
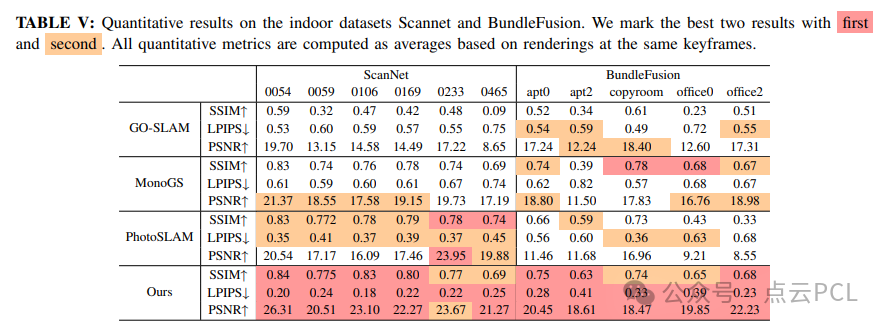

图7: 质量渲染结果。我们将我们的方法与两种室内和五种室外场景进行了比较,测试了三种先进的单目SLAM算法,包括基于NeRF的GO-SLAM和两种基于GS的方法,MonoGS和PhotoSLAM。VINGS-Mono在渲染质量上显著优于现有方法。
室外渲染结果:
室外场景的挑战较大,涉及较长的轨迹(从数百到数千米)和较快的移动速度,影响了基线方法的渲染质量和地图存储要求。在五个数据集上进行实验:KITTI、KITTI-360、Waymo、Hierarchical和MegaNeRF。该方法在长距离、高速的自动驾驶数据集(如KITTI、KITTI-360和Waymo)上,能够渲染高质量的细节;在手持设备数据集(如Hierarchical)上,我们的方法能精确建模建筑物边缘和表面细节;在具有显著深度变化和复杂分层场景的无人机数据集上,我们的方法展示了优越的重建质量,特别是在稀疏区域。我们的方法在所有场景中均展示了SOTA(最先进)性能,尤其在PSNR、SSIM和LPIPS指标上。高斯地图的可视化(图8),展示了我们的方法在KITTI-360中的表现,支持通过RTX 4090 GPU处理超过5100万个高斯体素。
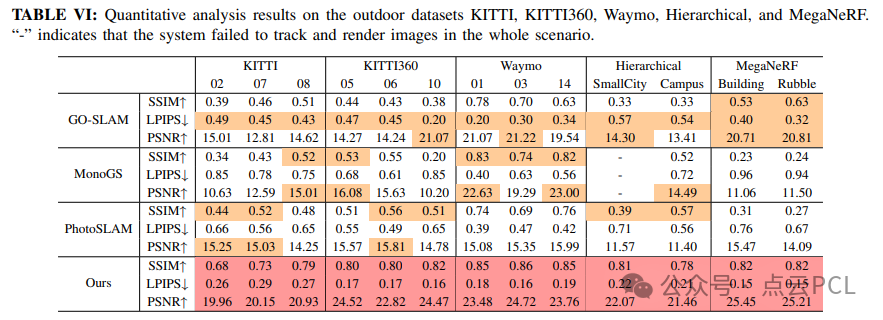
图8: KITTI360的高斯地图可视化。场景2013 05 28 drive 0006的轨迹长度为8.05公里,整个高斯地图包含5173万个椭球体。我们记录了训练过程中的高斯数量,并放大了地图的不同部分以获得更清晰的可视化。
动态去除性能
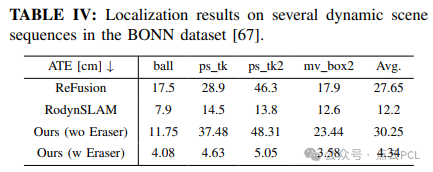
为评估Dynamic Eraser在动态环境中增强追踪性能的有效性,我们使用了BONN数据集进行对比实验。
- 我们与ReFusion和RodynSLAM(针对动态场景的SLAM方法)进行了对比,结果表明我们的方法在动态场景中的表现更好。
- 动态物体主导场景时,Dynamic Eraser显著提高了追踪精度。

图9: Waymo数据集的网格提取。我们支持基于渲染深度提取网格,并将其加载到Unity中进行仿真,以缩小仿真与现实之间的差距。
消融实验
1) 样本光栅化消融:选用KITTI数据集,评估了每次训练迭代的前向传播和反向传播中的渲染效果。相较于原始的2DGS像素并行方法和Taming3DGS中的高斯并行方法,我们的样本基础反向传播策略加速了170%(从7.21ms减少到4.23ms),尽管PSNR略有下降(0.56)。相较于2DGS方法,我们的方法加速了273%。
2) 评分管理器消融:评分管理器的主要功能是移除不必要的高斯体,并减少CPU和GPU之间的数据传输。室内场景中,评分管理器不仅减少了高斯数量,还提高了渲染质量;室外场景中,评分管理器减少了22%的高斯体,且PSNR仅下降了0.3%。
3) 位姿优化消融:我们的方法结合了不同关键帧位姿的高斯体进行渲染,同时优化所有可见关键帧的位姿。在室内和室外场景中,我们的方法优于单帧优化策略,尤其在前端追踪性能差的场景中表现出显著改善。
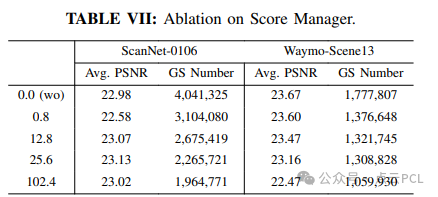
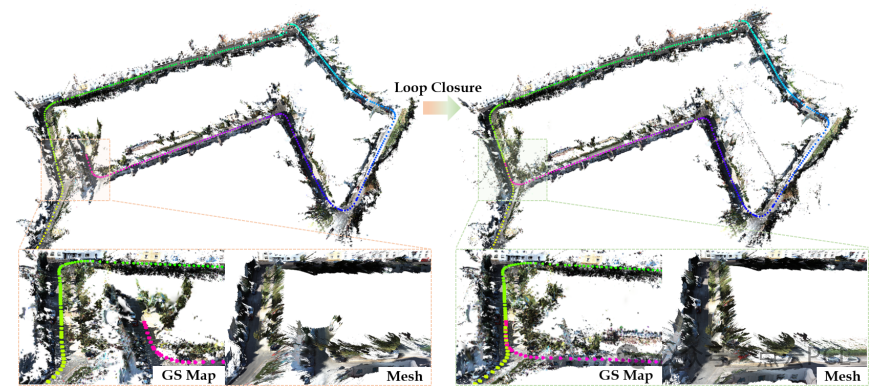
图10: 城市场景中NVS回环闭合的性能。我们的NVS回环闭合可以在不耗时重新训练的情况下校正高斯地图。我们放大了回环闭合位置的高斯地图并导出了网格,我们的方法有效地确保了高斯地图的全局一致性。
运行时间分析
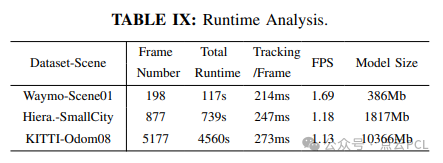
报告了在Waymo、Hierarchical和KITTI数据集上,使用RTX 4090 GPU的运行时和模型大小。我们的框架在短轨迹和长轨迹下均能在线运行。
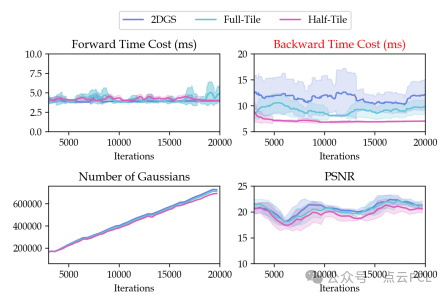
图11: 样本光栅化器的消融实验
真实世界实验
1) 大规模环境:我们在校园环境中收集了大规模室外数据集,测试了我们方法在单目设置下的大规模场景中的稳定性和鲁棒性。测试显示,我们的方法几乎没有发生规模漂移。
2) 智能手机上的移动应用:我们在智能手机上运行VINGS-Mono,开发了基于Flutter框架的移动应用,能够收集图像和IMU数据,并在服务器上处理数据,生成实时的视觉输出。该方法在室内和室外不同光照条件下表现出色,能够重建低纹理区域和高曝光区域。


Fig. 12: 大规模自采集数据的单目SLAM结果。采集的数据覆盖了我们的校园。左侧的轨迹和地图表示由VINGS-Mono估计的结果,右上方展示了数据采集期间记录的智能手机GPS数据,与Google地图对齐。
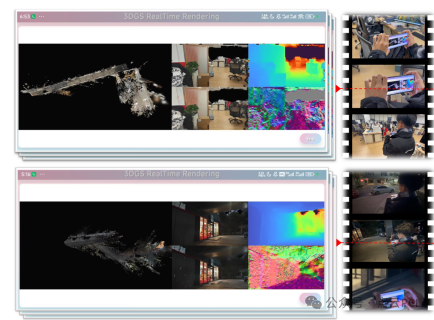
图13: VINGS-Mono的移动应用
总结
本文提出了VINGS-Mono,一种单目(惯性)高斯溅射SLAM框架,旨在解决大规模环境中的挑战。通过引入如高效高斯修剪的得分管理器、用于提高跟踪精度的单一到多位姿优化模块、利用新颖视图合成进行全局一致性的回环闭合方法,以及处理瞬态物体的动态物体遮罩机制,VINGS-Mono实现了高效、可扩展且准确的SLAM性能。
我们通过广泛的实验对系统进行了严格评估。首先,我们在两个公共室内数据集和五个室外数据集上进行了对比实验,以评估VINGS-Mono的定位精度和渲染质量。与最先进的基于NeRF/GS的方法和视觉SLAM方法进行比较,结果表明我们的系统在定位和建图性能上具有优越性。此外,我们还在大规模环境中进行了实际世界实验,以验证我们方法的鲁棒性和稳定性。接下来,我们对VINGS-Mono的各个模块进行了消融实验,以验证它们的有效性。最后,我们开发了一个移动应用,并通过现场演示验证了系统的实时能力,展示了在室内外环境中构建二维高斯地图的过程。
我们的方法通过利用高斯溅射技术,能够重建密集的几何和颜色信息,即使在激光雷达或深度相机不适用的户外场景中也能实现。这为高效的导航和探索提供了便利,能够保留场景的关键细节,并支持实例图像目标导航等高级任务。此外,具有新颖视图渲染能力的高斯地图非常适合VR/AR和数字双胞胎等实时应用,提高了大规模自主系统的可扩展性、适应性和效率。
该工作的一个主要局限性在于,在极高速度运动下无法有效重建和定位。具体来说,当帧间隔较大时,DBA在捕捉和恢复密集几何信息方面面临挑战,而GS所需的多个训练迭代限制了二维高斯地图的重建速度。
另一个局限性是,该系统尚未部署到设备上进行计算。在未来的工作中,我们将探索将VINGS-Mono直接部署到边缘计算设备上,以进一步增强我们算法的实际价值和适用性。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号