ChatGPT|字节开源的毫秒文生图模型


介绍
SDXL-Lightning是开源文本到图像生成模型,生成图秒出,图片质量也还不错,其huggingface地址:https://huggingface.co/ByteDance/SDXL-Lightning。
体验地址1:https://fastsdxl.ai/ 体验地址2:https://huggingface.co/spaces/radames/Real-Time-Text-to-Image-SDXL-Lightning 体验地址3:https://replicate.com/lucataco/sdxl-lightning-4step
输入:A cinematic shot of a baby raccoon wearing an intricate italian priest robe 输出:

本地部署
具体代码:
import time
import torch
from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, EulerDiscreteScheduler
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
base = "stabilityai/stable-diffusion-xl-base-1.0"
repo = "ByteDance/SDXL-Lightning"
ckpt = "sdxl_lightning_2step_unet.safetensors" # Use the correct ckpt for your step setting!
# 加载模型,如果是GPU可以将"cpu" -> "cuda"
unet = UNet2DConditionModel.from_config(base, subfolder="unet").to("cpu")
unet.load_state_dict(load_file(hf_hub_download(repo, ckpt), device="cpu"))
pipe = StableDiffusionXLPipeline.from_pretrained(base, unet=unet).to("cpu")
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing")
start_time = time.time()
pipe("A cinematic shot of a baby raccoon wearing an intricate italian priest robe", num_inference_steps=2, guidance_scale=0).images[0].save("output.png")
end_time = time.time()
print("执行耗时:{}秒".format(end_time - start_time))
执行耗时:1.7429804801941秒。
原理
图像生成模型是由噪音到清晰图片逐步转换的过程,在这一过程中,通过神经网络学习在这个转化流(flow)中各个位置上的梯度,具体步骤:
- 在流的起点随机采样一个噪声样本
- 神经网络计算出梯度值,根据当前位置的梯度值,对样本进行微调
- 重复以上步骤
- 每次迭代后,样本都会更加接近想要的图片分布,知道迭代结束获得清晰的图片
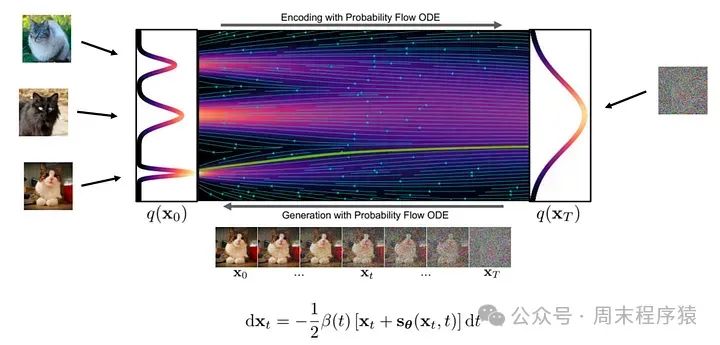
图像生成模型步骤
由于上述生成过程每次只能走一小步,减少梯度误差的累计,所以需要神经网络的大量计算,为了减少生成图像所需的步骤数量有两种方式:
- 减少误差采样的方法,试图生成流更加直线化,但是仍然不能在2个推理步骤生成图像;
- 模型蒸馏能在少量的推理步骤中生成高质量图像,不同于计算当前流位置下的梯度,模型蒸馏改变模型预测的目标,直接让其预测下一个更远的流位置,具体来说,训练一个学生网络直接预测老师网络完成了多步推理后的结果,这样的策略可以大幅减少所需的推理步骤数量,通过反复应用这个过程,可以进一步降低推理步骤的数量;
SDXL-Lightning(https://arxiv.org/abs/2402.13929)论文介绍在实际操作中,学生网络往往难以精确预测未来的流位置,误差随着每一步的累积而放大,导致在少于 8 步推理的情况下,模型产生的图像开始变得模糊不清。
为了解决这个问题,提出策略是不强求学生网络精确匹配教师网络的预测,而是让学生网络在概率分布上与教师网络保持一致。换言之,学生网络被训练来预测一个概率上可能的位置,即使这个位置并不完全准确,也不会对它进行惩罚,这个目标是通过对抗训练来实现的,引入了一个额外的判别网络来帮助实现学生网络和教师网络输出的分布匹配。

训练方式
参考
(1)Progressive Distillation for Fast Sampling of Diffusion Models,https://arxiv.org/abs/2202.00512 (2)SDXL-Lightning: Progressive Adversarial Diffusion Distillation,https://arxiv.org/abs/2402.13929 (3)https://www.infoq.cn/news/lkPiQyHETmWPiBmtCrMY
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号