设计分享|基于51单片机的交通灯指示模拟

设计分享|基于51单片机的交通灯指示模拟

电子工程师成长日记
发布于 2025-03-17 19:12:57
发布于 2025-03-17 19:12:57
具体实现功能:
利用51单片机模拟交通指示灯的切换过程。
设计介绍

51单片机简介
51单片是一种低功耗、高性能CMOS-8位微控制器,具有8K可编程Flash存储器,使得其为众多嵌入式控制应用系统提供高灵活、超有效的解决方案。
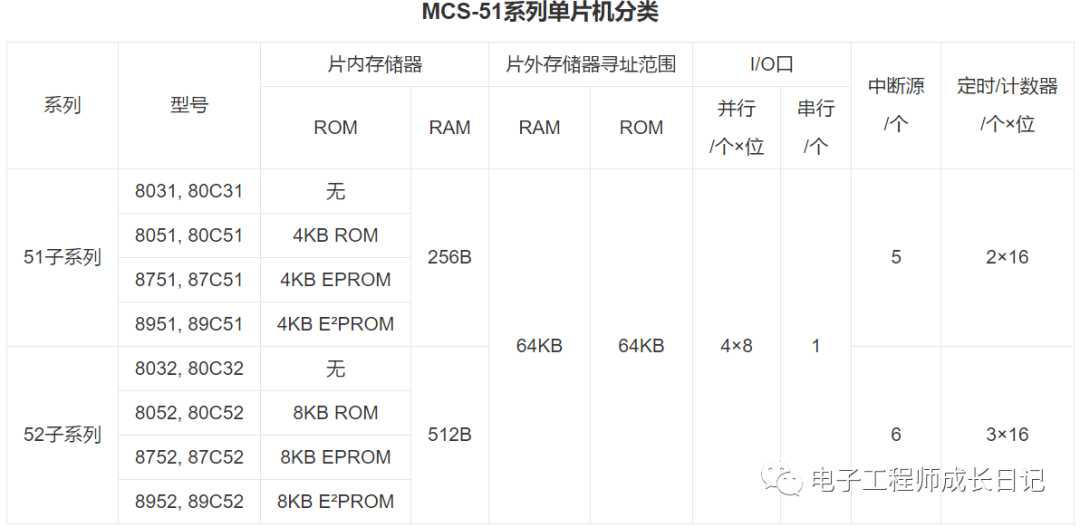
51系列单片机具有以下标准功能:
8k字节Flash,512字节RAM,
32位I/O口线,看门狗定时器,
内置4KB EEPROM,
MAX810复位电路,
三个16位定时器/计数器,
一个6向量2级中断结构,
全双工串行口。
另外, 51系列在空闲模式下,CPU停止工作,允许RAM、定时器/计数器、串口、中断继续工作。掉电保护方式下,RAM内容被保存,振荡器被冻结,单片机停止工作,直到下一个中断或硬件复位为止。本设计所使用的芯片可兼容以下所有的51系列单片机(包括AT系列和STC系列)。
设计思路
文献研究法:搜集整理相关研究资料,阅读文献,为研究做准备;
调查研究法:通过调查、分析、具体实验等方法,发现相关存在问题和解决办法;
比较分析法:比较不同设计的具体原理,以及同一类传感器性能的区别,分析系统的研究现状与发展前景;
软硬件设计法:通过软硬件设计实现硬件,最后测试各项功能是否满足要求。
单片机类设计论文参考模板:
毕设无忧|单片机类毕设论文模板
设计内容
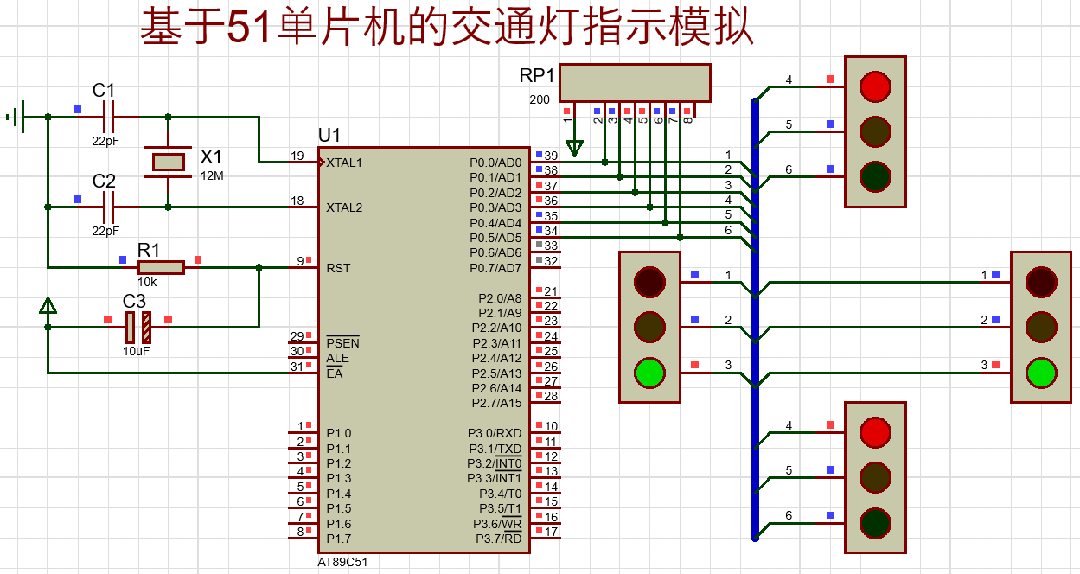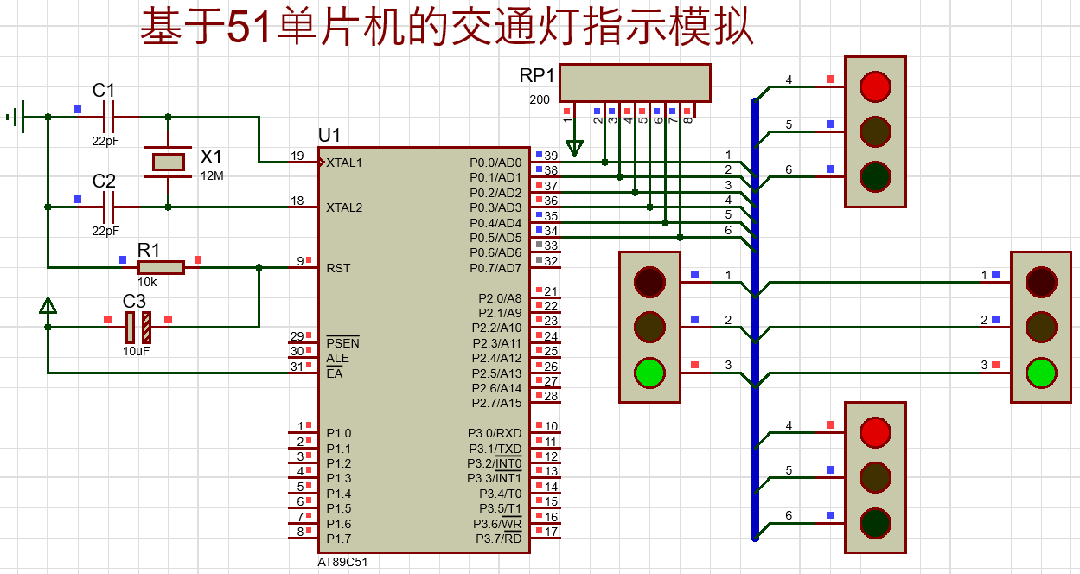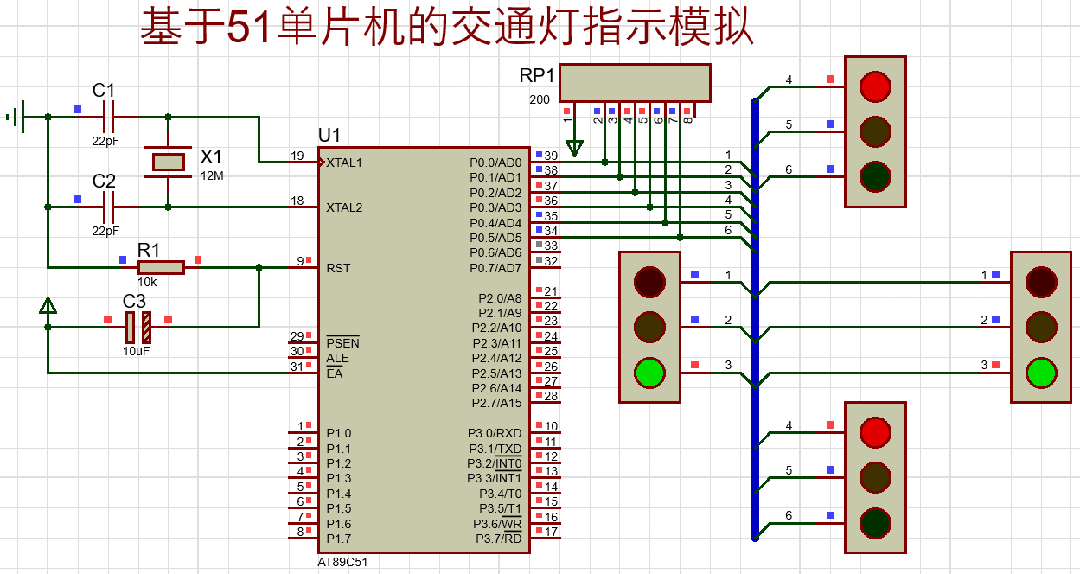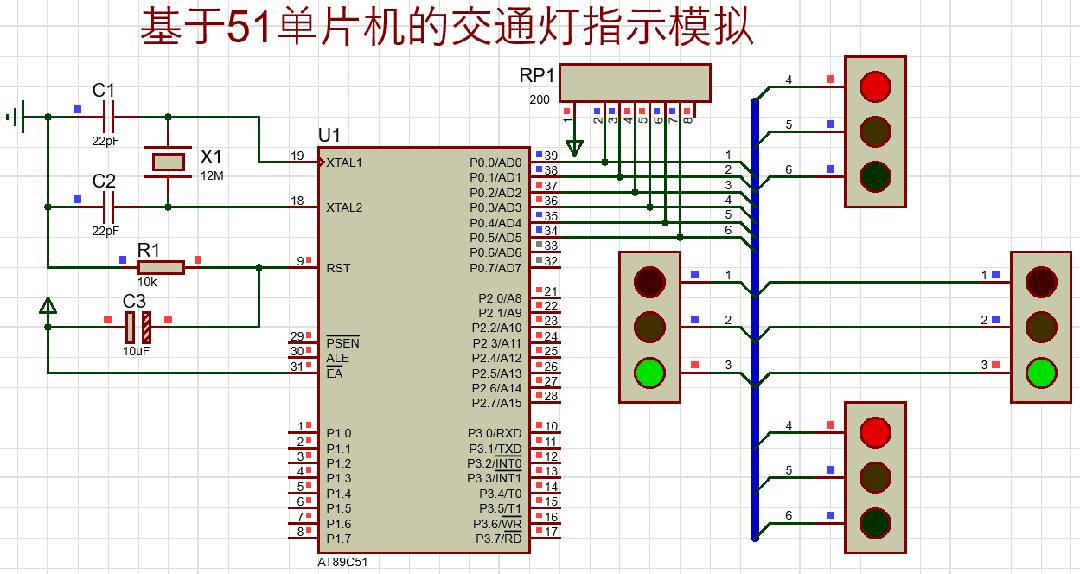
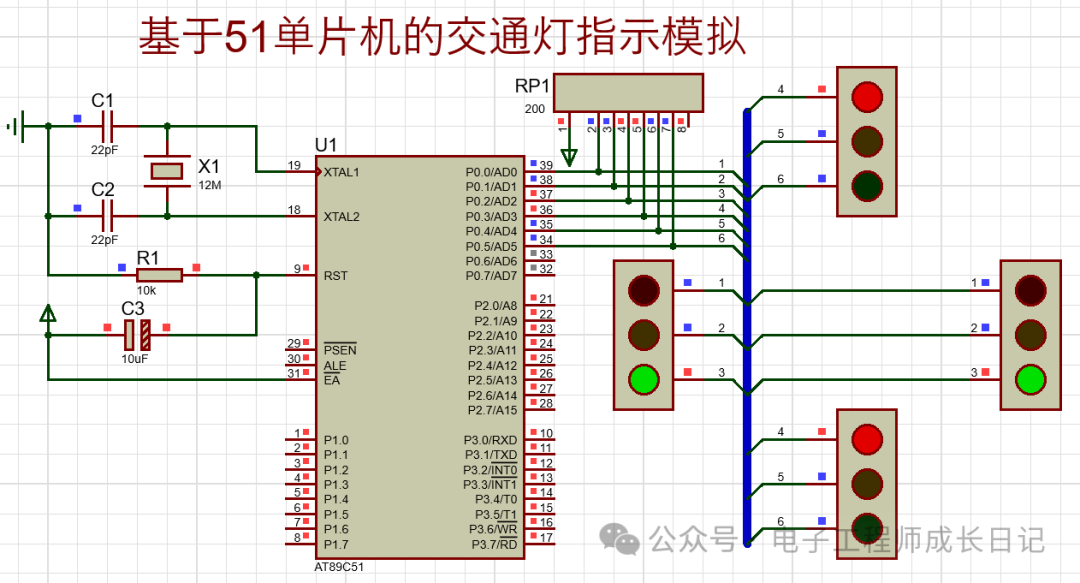
仿真图(protues8.7)
本设计利用protues8.7软件实现仿真设计,具体如图。
注:免费分享,请按照下图自行绘制仿真!!
protues8.7软件资料及仿真解决办法:
proteus8.7安装及破解教程(内附安装包)
protues仿真常见问题解决方案
Protues8.7简易教程
程序(Keil5)
本设计利用KEIL5软件实现程序设计。
注:全部代码免费分享,请自行建立工程!!
本设计由C语言编写,全部代码如下:
#include <reg52.h>
#define uint unsigned int
#define uchar unsigned char
sbit RED_A = P0^0;
sbit YELLOW_A = P0^1;
sbit GREEN_A = P0^2;
sbit RED_B = P0^3;
sbit YELLOW_B = P0^4;
sbit GREEN_B = P0^5;
uchar Time_Count = 0,Flash_Count = 0,Operation_Type = 1;
void T0_INT() interrupt 1
{
TH0 = -50000/256;
TL0 = -50000%256;
switch(Operation_Type)
{
case 1:
RED_A=0;YELLOW_A=0;GREEN_A=1;
RED_B=1;YELLOW_B=0;GREEN_B=0;
if(++Time_Count != 100) return;
Time_Count=0;
Operation_Type = 2;
break;
case 2:
if(++Time_Count != 8) return;
Time_Count=0;
YELLOW_A=!YELLOW_A;
GREEN_A=0;
if(++Flash_Count != 10) return;
Flash_Count=0;
Operation_Type = 3;
break;
case 3:
RED_A=1;YELLOW_A=0;GREEN_A=0;
RED_B=0;YELLOW_B=0;GREEN_B=1;
if(++Time_Count != 100) return;
Time_Count=0;
Operation_Type = 4;
break;
case 4:
if(++Time_Count != 8) return;
Time_Count=0;
YELLOW_B=!YELLOW_B;
GREEN_B=0;
if(++Flash_Count !=10)
return;
Flash_Count=0;
Operation_Type = 1;
break;
}
}
void main()
{
TMOD = 0x01;
IE = 0x82;
TR0 = 1;
while(1);
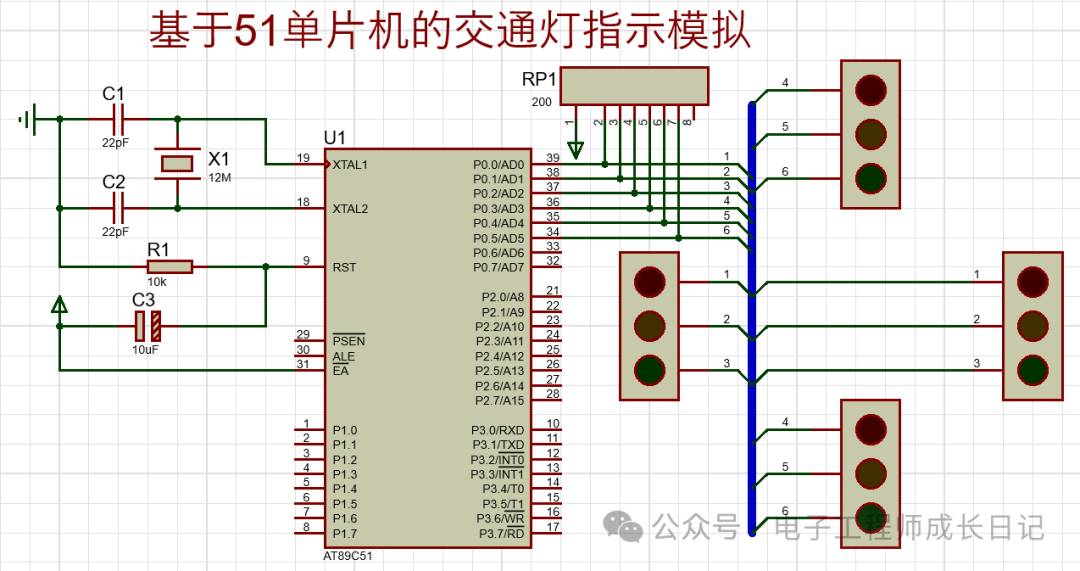
}运行结果如图:
Keil C51软件资料及使用教程:
Keil C51安装及破解教程(内附安装包)
KEIL5使用技巧
Keil5简易教程
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号