榨干算力!腾讯云HAI-CPU+DEEPSEEK的高吞吐训练配置秘籍
原创
榨干算力!腾讯云HAI-CPU+DEEPSEEK的高吞吐训练配置秘籍
原创
Eternity._
发布于 2025-03-24 08:41:34
发布于 2025-03-24 08:41:34
❀ 腾讯云HAI-CPU)
前言: 在人工智能的军备竞赛中,算力永远是开发者最渴望的"兴奋剂"。当您的模型训练被硬件瓶颈拖住后腿,当参数微调的成本仍在指数级攀升,是否想过——您使用的每一核CPU、每一GB内存,真的都物尽其用了吗?
腾讯云HAI-CPU的诞生,重新定义了云端AI训练的算力天花板。这款专为超大规模矩阵运算设计的异构计算引擎,搭配DEEPSEEK框架的深度优化能力,正在撕开一道通往极致吞吐量的裂缝。本文将带您深入"榨干算力"的实战前线
系好安全带,准备好见证训练速度表的指针疯狂右摆。真正的算力革命,从榨干最后一滴计算资源开始。
部署思路
腾讯云HAI-CPU以多阶算力套餐矩阵,精准解构数字创作的性能需求。初学者可手持「基础算力通行证」,以轻量化成本叩开AIGC大门;资深创作者更能解锁「超算级渲染舱」,让想象力在澎湃算力中沸腾。独创的「呼吸式计费」模式,让算力资源如潮汐般随需涨落——创作时全力输出,停歇时静默归零,成本把控精准到秒。搭配智能套餐匹配算法,用户可像调配莫奈的调色盘般,在性能与预算间找到最优雅的平衡点,让每一分投入都化作像素世界的璀璨绽放。
场景搭建过程
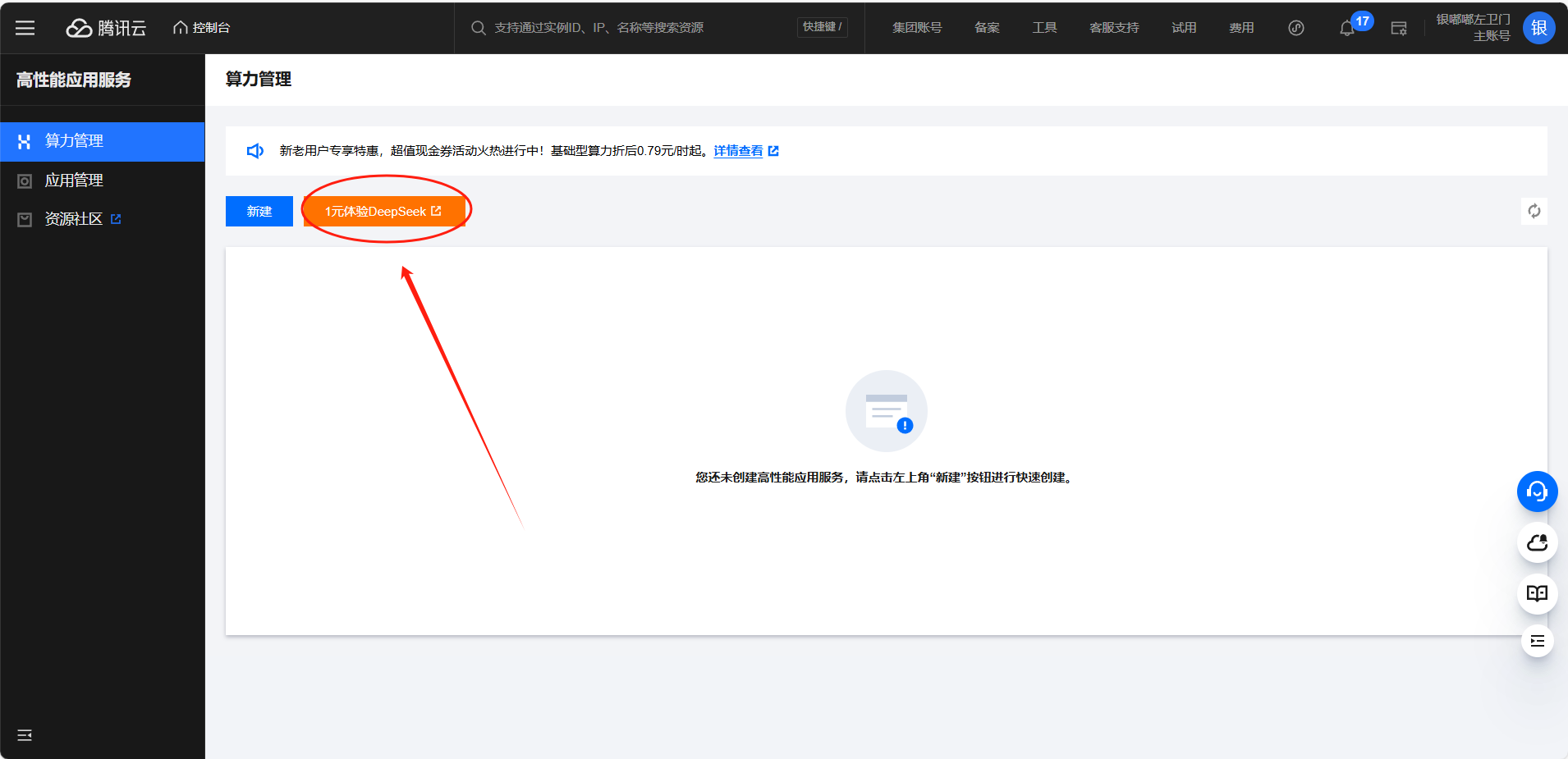
点击HAI-CPU 进行 高性能应用服务 HAI的体验,点击立即使用,进入主页后点击1元体验
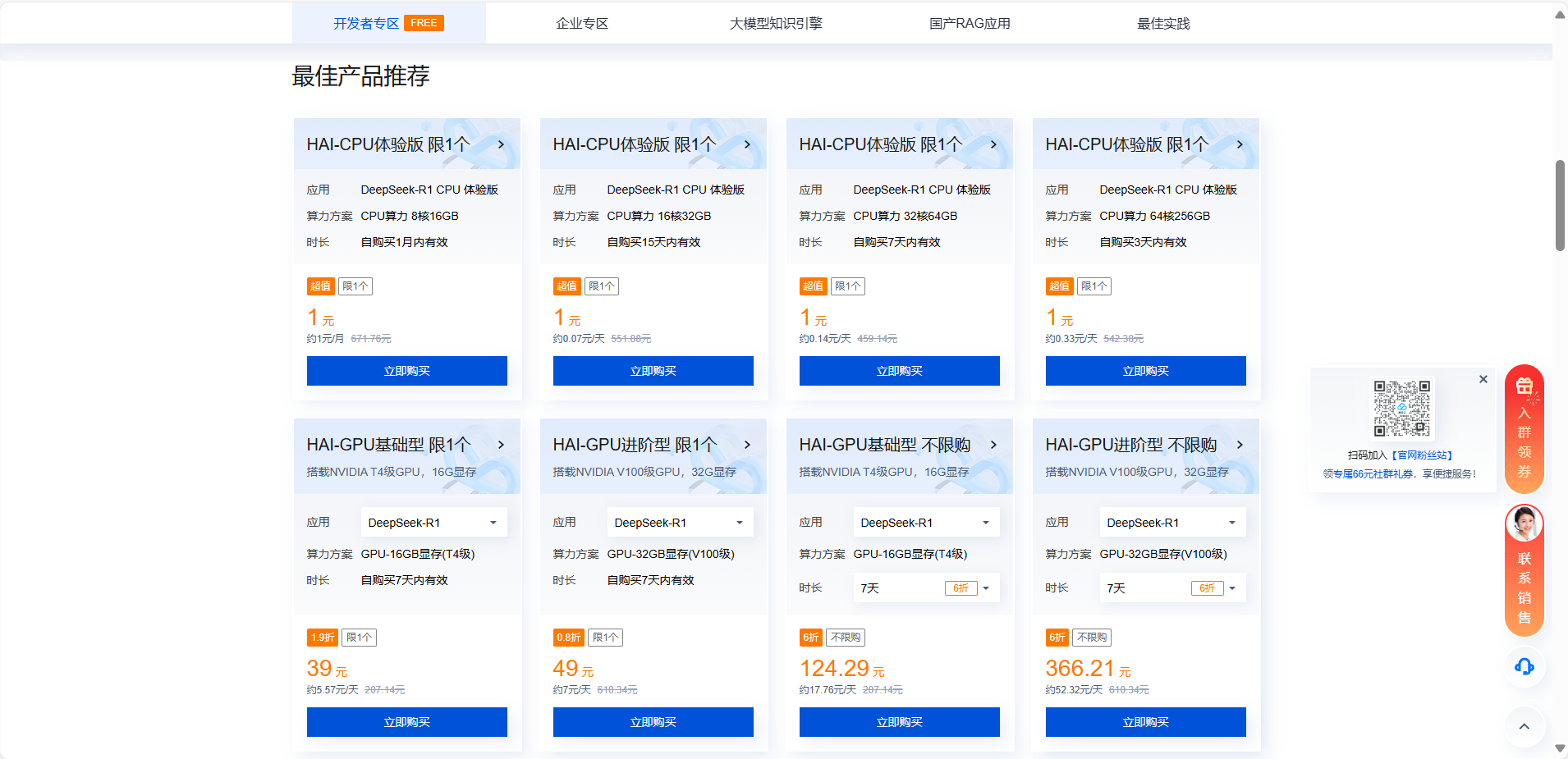
进入deepseek专区,我们往下寻找,可以找到最佳产品推荐,产品性价比很高,平均下来的费用是非常低的,我们选择一个能用的就可以了,这里我选择的是第二个
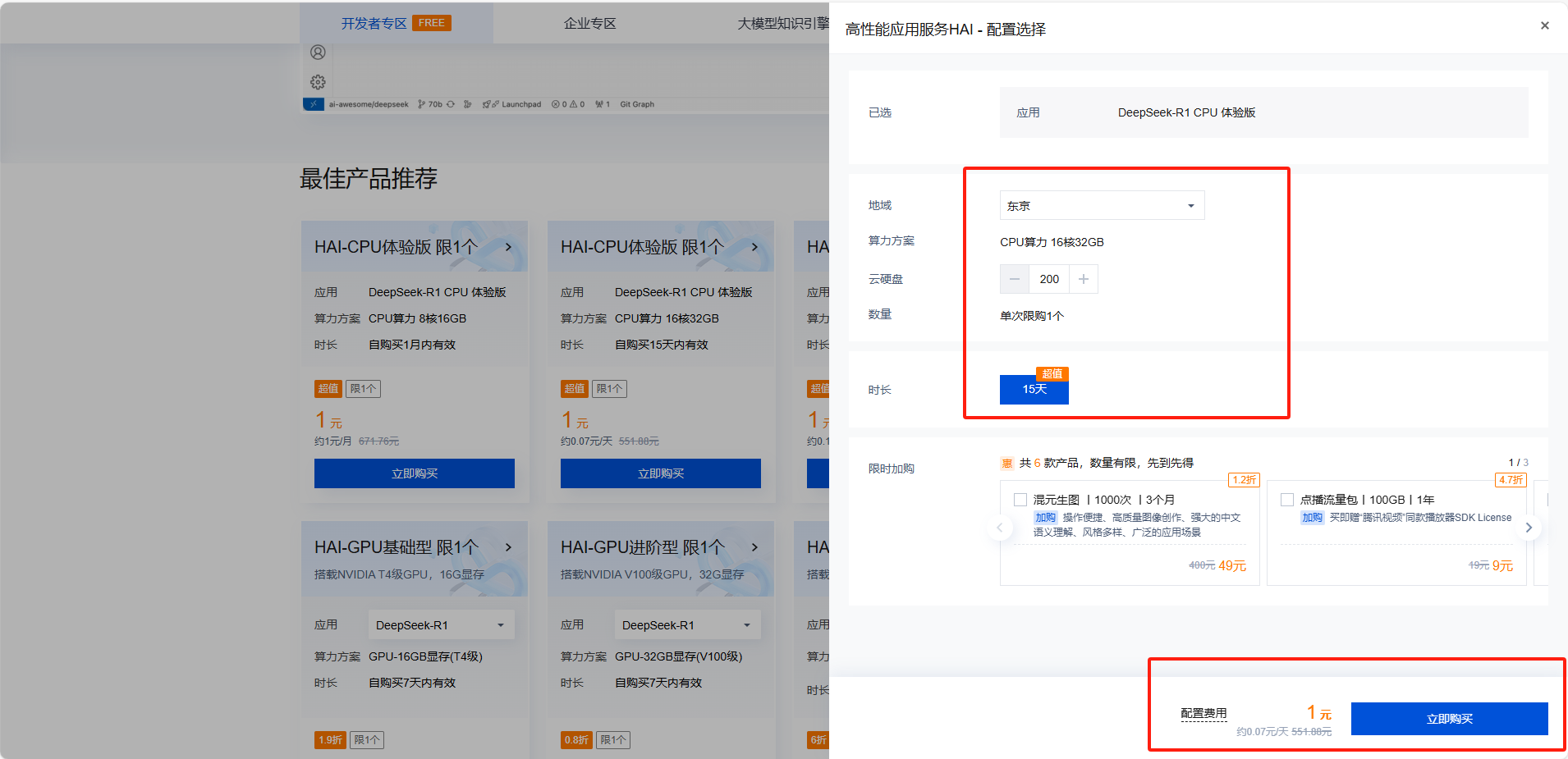
我们进入到了配置界面,地域的话可以随便选一个,我这里选择的是东京,这里我们可以看到1元体验15天
完成支付之后,我们直接进入控制台即可
!
我们可以看到刚刚支付购买的产品
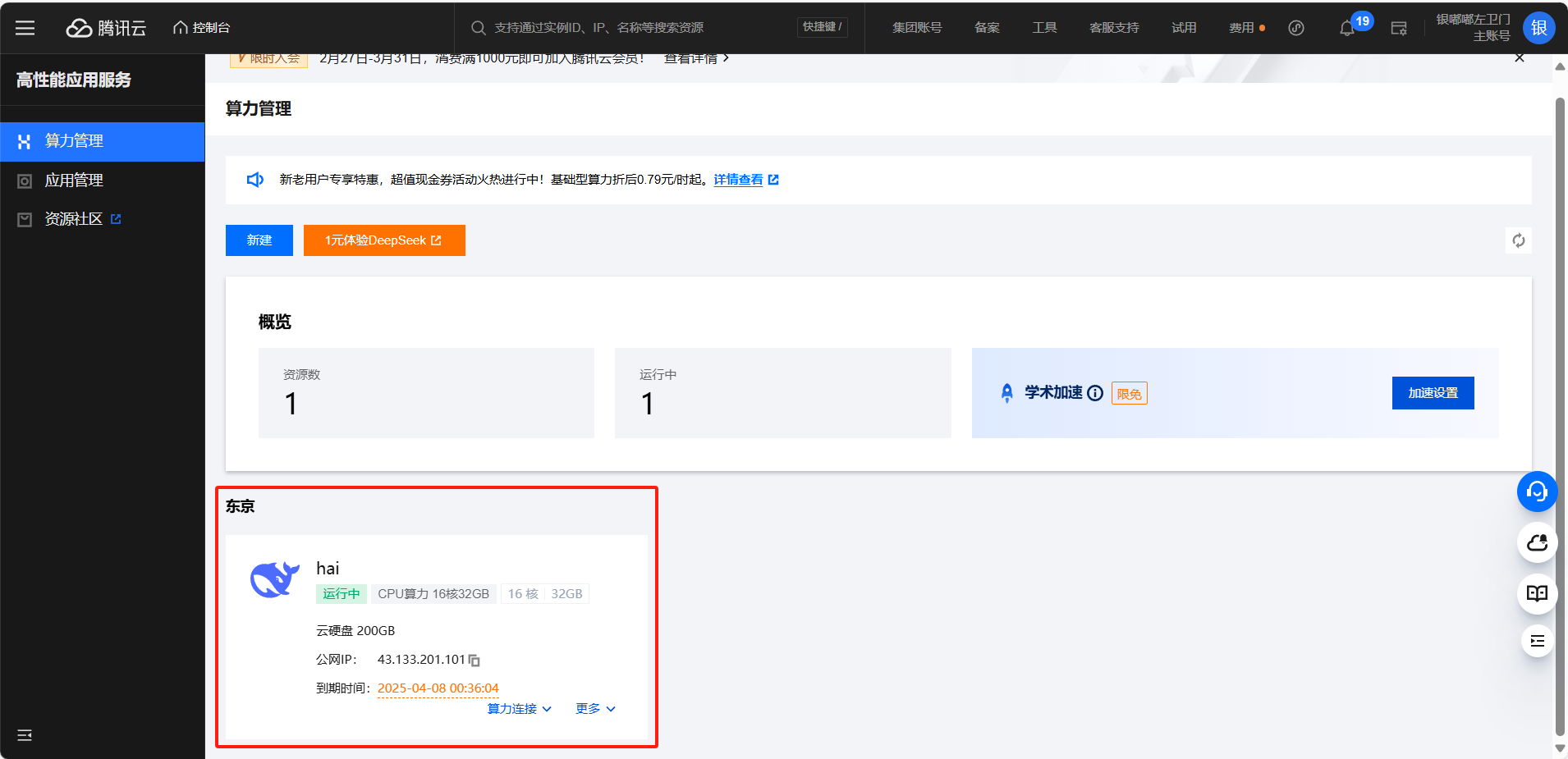
这里我们点击产品可以看到相关的信息以及算力连接方式
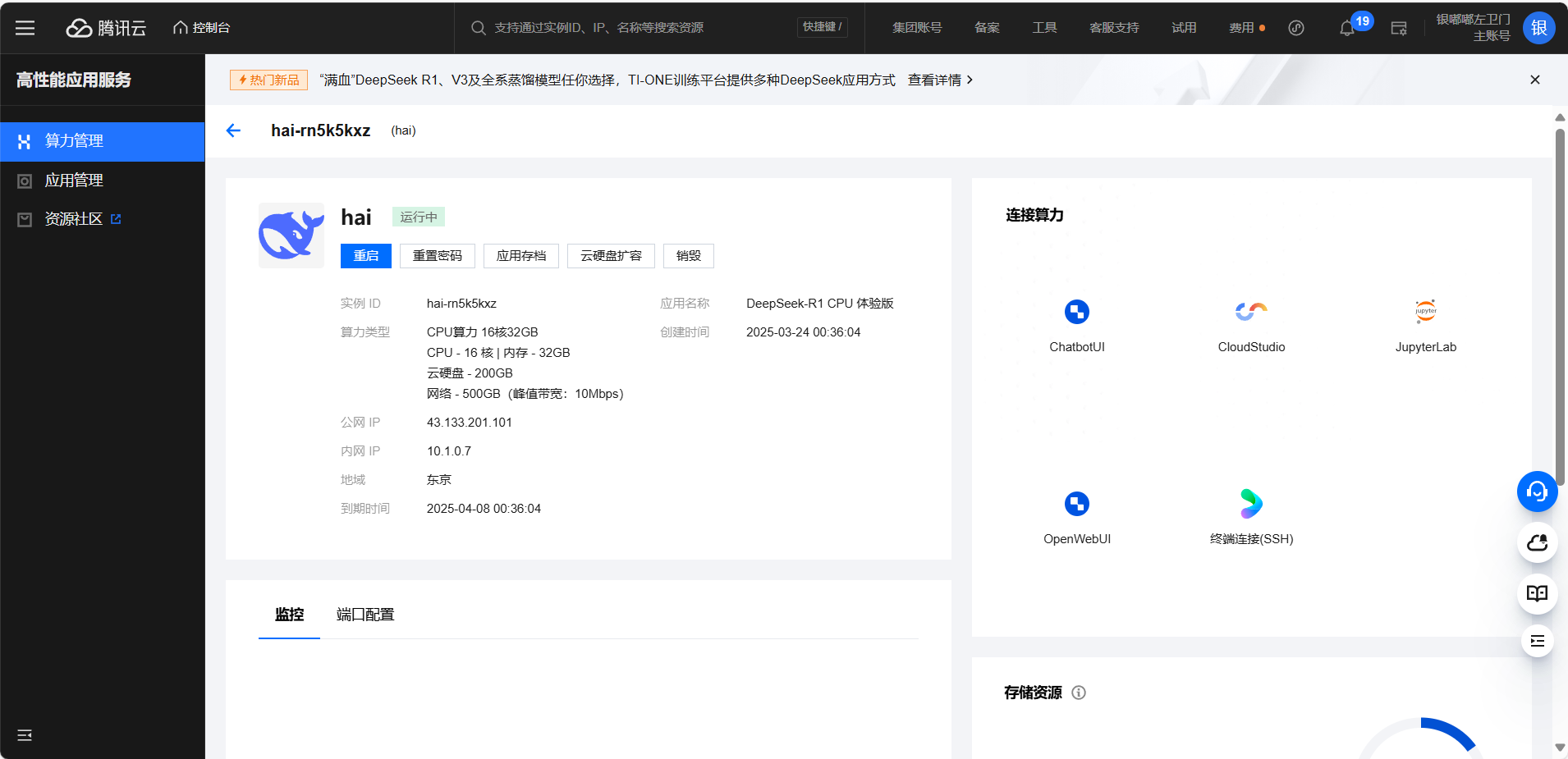
效果展示
然后我们选择选择OpenWebUI对其进行连接,直接进入到可视化的deepseek对话界面
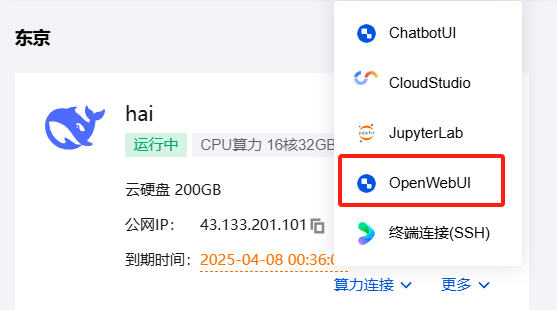

点击页面上的开始使用,登录好我们的账号密码,我们就可以直接使用了,我们还可以设置进行调配相关的信息
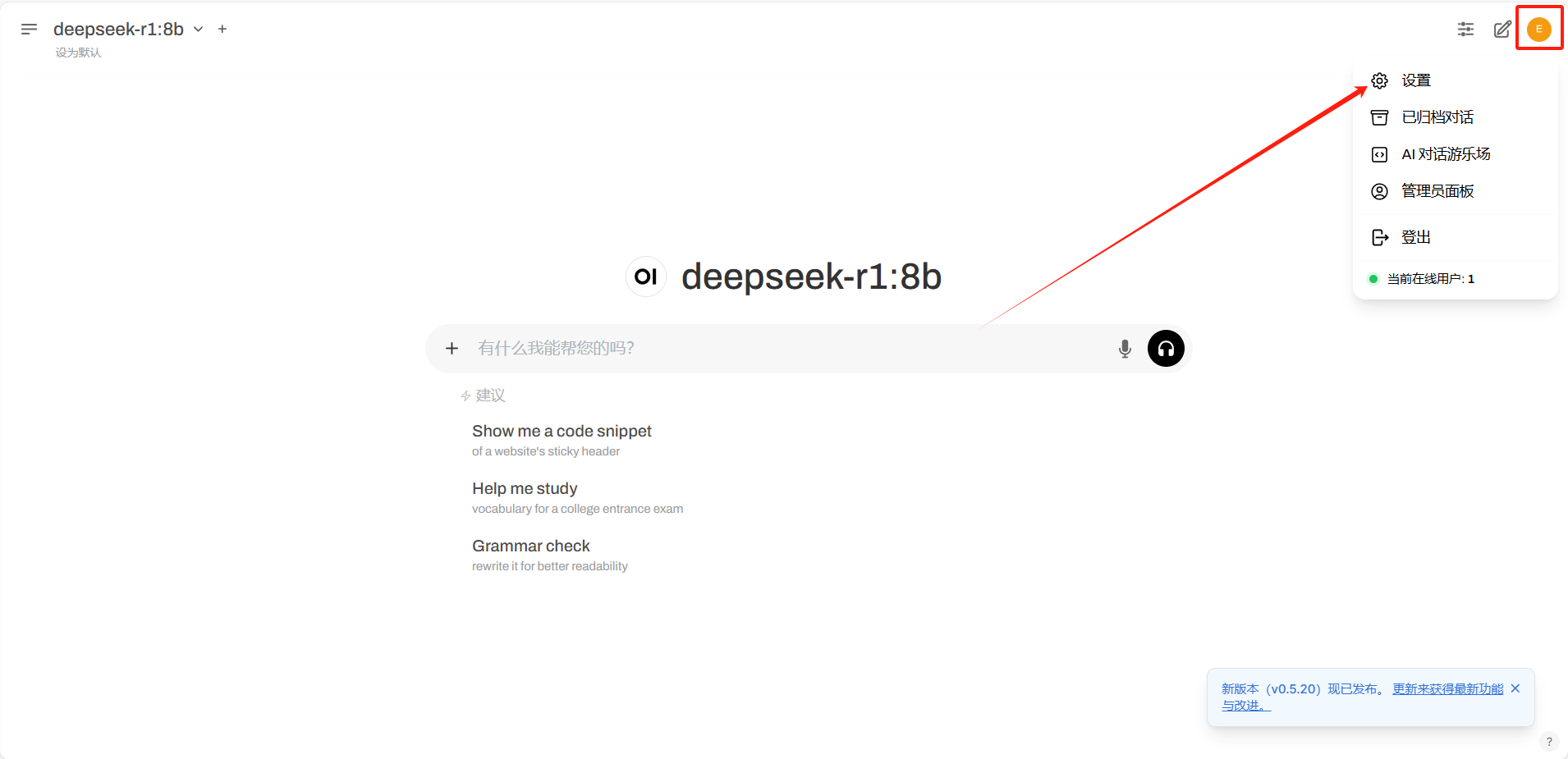
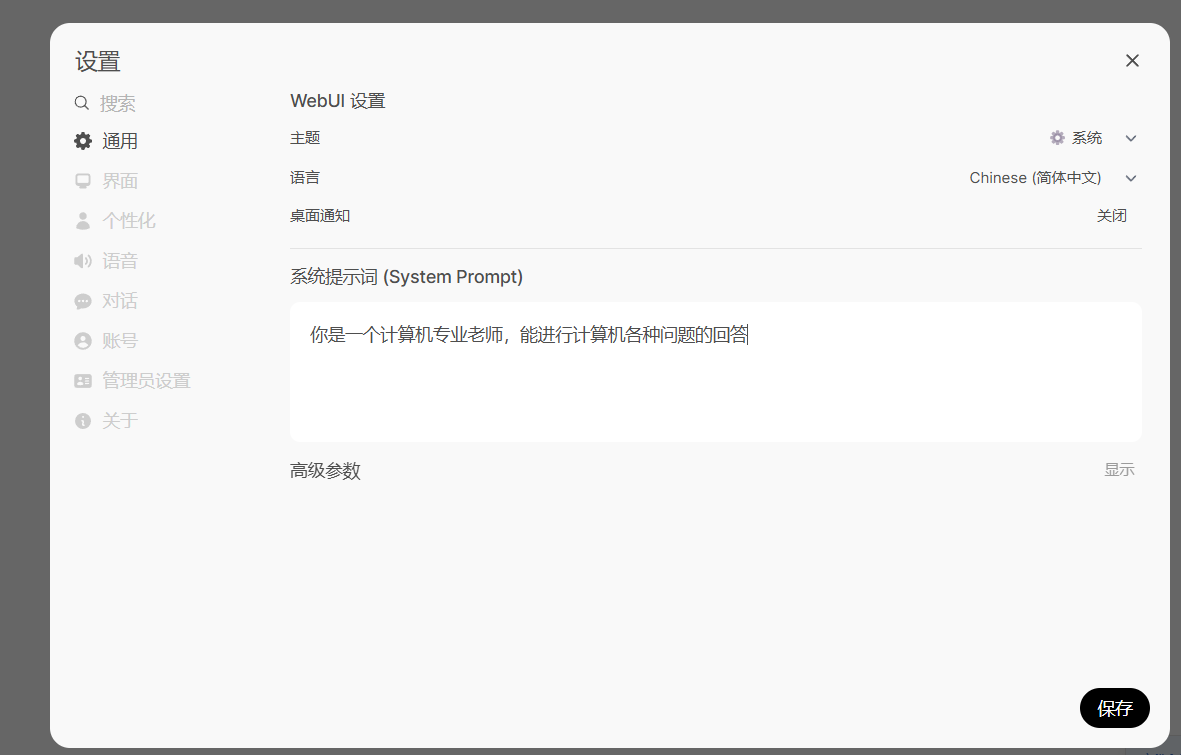
在设置好相关配置后,我们也可以在左上角设置想使用的模型
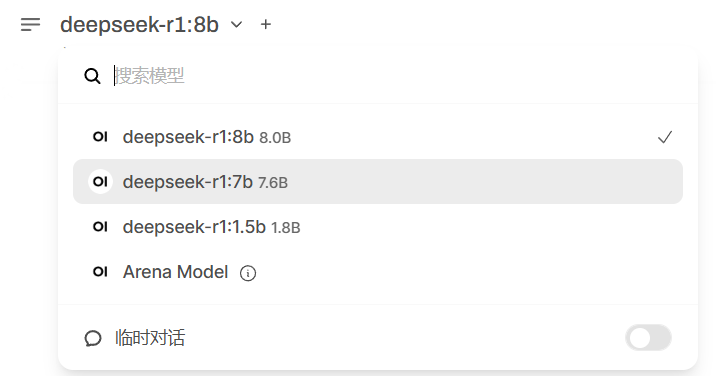
在完成以上操作后,让我们来看看它的实力如何
我们提个问题:介绍一下机器学习中的决策树算法并附上代码示例
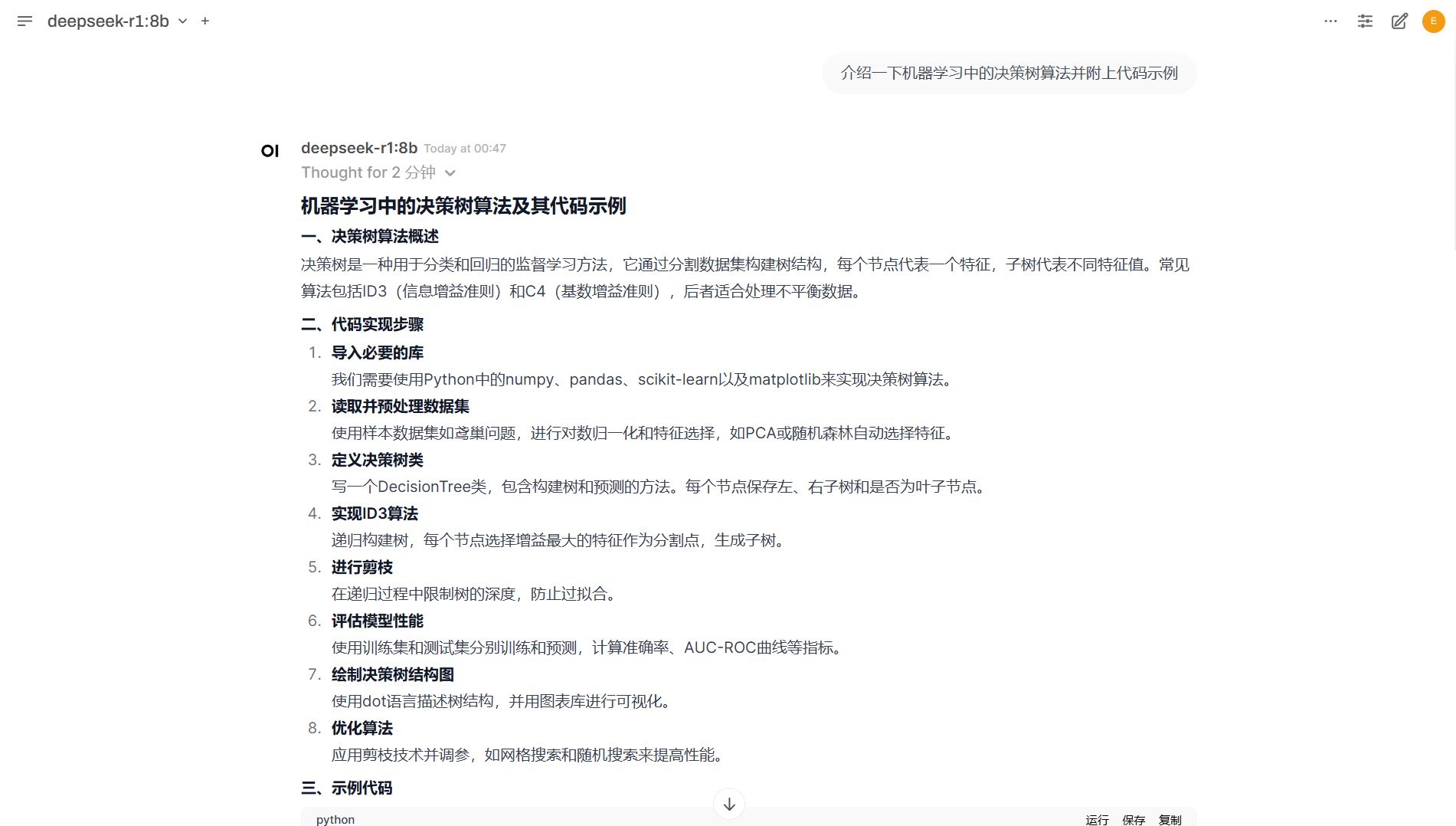
代码示例:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LogTransform, PCA
from sklearn.feature_selection import RandomizedLasso
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import itertools
# 读取数据集并进行预处理
data = np.load('data.npy')
X = data[:, :-1]
y = data[:, -1]
# 特征选择和标准化
selected_features = list(range(len(X)))
rlasso = RandomizedLasso randomly_mask=0.5, fit=False)
selected_features = list(rlasso.fit_transform(X).nonzeroIndices())
X = X[:, selected_features]
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42
)
log_transformer = LogTransform()
X_train = log_transformer.fit_transform(X_train)
X_test = log_transformer.transform(X_test)
# 决策树实现
class DecisionTree:
def __init__(self, X, y, max_depth=10):
self.X = X
self.y = y
self.max_depth = max_depth
self.root = None
def build_tree(self, node, index=0):
if node is None:
return None
# 当前节点的特征和对应的值
current_features = self.X[node]
current_labels = self.y[node]
if np.all_equal(current_labels):
node.is_leaf = True
node.label = current_labels[0]
return node
# 选择最优特征进行分割
best_feature, best_split = self.select_best_feature(node, index)
node.feature = best_feature
mid = np.split(current_features, best_split)
node.left = self.build_tree(mid[0], index +1)
node.right = self.build_tree(mid[1], index+1)
def select_best_feature(self, node, index):
features = list(range(len(self.X)))
importances = []
for i in range(index +1, len(features)):
if node is not None and hasattr(node, 'importance'):
importances.append((features[i], node.importance))
else:
break
# 选择增益最大的特征
max_info = -np.inf
best_feature = None
for f, imp in importances:
if imp > max_info:
max_info = imp
best_feature = f
split = np.find_split(self.X[node], best_feature)
return best_feature, split
def predict(self, X):
node = self.root
if node is None:
return 0
while node.feature is not None:
# 特征对应的值
value = X[node.feature]
if node.is_leaf:
return int(node.label)
if value <= node.split[0]:
node = node.left
else:
node = node.right
return 0
# 初始化模型
dt_model = DecisionTree(X_train, y_train)
# 训练树结构
for i in range(dt_model.max_depth):
print(f"正在构建第 {i+1} 层的树...")
dt_model.build_tree(dt_model.root, i)
# 预测测试集
y_pred = dt_model.predict(X_test)
print("预测结果:", y_pred[:10])
# 评估模型性能
from sklearn.metrics import accuracy_score, roc_curve
y_true = np.argmax(y_test, axis=1)
accuracy = accuracy_score(y_true[:100], y_pred[:100])
print(f"准确率: {accuracy:.4f}")
# 绘制决策树结构图(示例简化)
def draw_tree(node):
if node is None:
return
children = []
for child in [node.left, node.right]:
if child is not None:
children.append(child)
if len(children) == 0:
continue
# 绘制节点
plt.text(node.feature + 5, node.split[0] - 0.5,
f"特征={node.feature}, 值分割点={node.split[0]:.2f}")
draw_tree(node.left)
draw_tree(node.right)
draw_tree(dt_model.root)
plt.show()代码解释
- 导入库 :使用numpy进行数据处理,scikit-learn中的函数如train_test_split用于划分数据集。
- 读取和预处理数据 :加载数据集,选择关键特征,并通过Log变换标准化数据,以改善分类性能。
- 决策树类定义 :包含构建树、选择最优特征和递归分割的功能。每个节点保存特征、分割点及其子树。
- ID3算法实现 :通过递归构建树,选择增益最大的特征进行数据分割。
- 剪枝控制树深度 :限制树的最大深度,防止过拟合。
- 模型预测与评估 :使用训练集和测试集分别训练和预测,计算准确率,并通过AUC-ROC曲线评估分类性能。
- 可视化决策树 :生成特征和分割点的树结构图,便于理解模型逻辑。
deepseek给了我们一个几近完美的回答,腾讯云HAI-GPU展现出了其在AI计算领域的强大实力,尤其是在处理DeepSeek模型这类复杂任务时,其高性能计算能力、稳定性和易用性令人印象深刻。
总结
当HAI-CPU的晶体管震颤与DEEPSEEK的算法脉搏同频共振,我们触摸到了AI训练效率的终极边界。本文揭示的配置秘籍并非冰冷的参数堆砌,而是一套经过实战淬炼的"算力呼吸法"——在硬件潜能与软件智慧的共振中,让每一焦耳能量都转化为模型进化的动能。
本文展示的仅是冰山一角。在HAI-CPU的架构深渊里,在DEEPSEEK的算子海洋中,仍藏着未被驯服的性能巨兽。保持对硬件特性表的敏锐直觉,延续对框架机制的探索热情
现在,合上指南,打开终端,让代码在HAI-CPU的涡轮增压下咆哮吧!您的下一次配置调整,或许就会改写某个行业的效率基准线。

推荐指数:★★★★★(5/5)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号