Nvidia探索光交换OCS在数据中心及高性能计算集群中的应用


这个工作是Nvidia最近在Optica旗下的JOCN期刊上发表的一篇邀请文章(https://doi.org/10.1364/JOCN.534317),主要内容今年在OFC都讲过,有些公众号也介绍过了。主要通过将OCS引入到L1物理层,实现物理层的可重构、可编程,能够实现数据中心的高效率自动故障恢复以及在深度学习训练中实现拓扑精简和优化。这里做个简单翻译重温一下,细节大家可以看看原文
1. 研究背景与意义 深度学习的发展促使训练计算能力需求急剧增长,每6个月所需浮点运算次数(FLOPs)翻倍,远超单个GPU扩展速率。这要求通过高速链路互连的横向扩展系统来维持高GPU利用率,如NVIDIA DGX SuperPOD参考架构可集成大量GPU,但网络特性对系统性能、功耗、成本和可用性影响显著。光交换技术能够提供物理层可重构性和可编程性,为应对这些挑战带来可能,从而推动了本研究对其在数据中心和高级计算系统中的应用探索,特别是在AI/HPC集群中将软件定义网络(SDN)可编程性扩展到物理层(L1)的研究。 2. 相关工作 过去几十年,计算需求增长促使许多研究致力于将光OCS融入数据中心/高性能计算环境,早期如Helios和c - Through等提案,以及众多展示光交换潜在优势的论文,网络重新配置时间可达纳秒到微秒范围。然而,高速光交换面临硬件成熟度低、系统时钟同步复杂等挑战,尽管如此,谷歌近期工作推动了OCS在数据中心的部署,最新研究也聚焦于OCS在机器学习应用系统中的使用,如TPU V4的相关研究展示了新的架构优化。 3. 光交换在AI/HPC网络架构中的应用 ◆ 系统级效益与集成方案 引入OCS可使高性能计算系统网络具备物理层可重构和可编程能力,重点关注在AI集群中胖树(FT)架构下的应用。OCS可增强现有网络或构建精简网络,增强现有网络时投资成本增加但能利用拓扑重配置好处且可恢复传统拓扑;构建精简网络则可降低功耗、成本、硬件复杂度和延迟,提升整体网络可用性,但需考虑目标工作负载和流量模式。
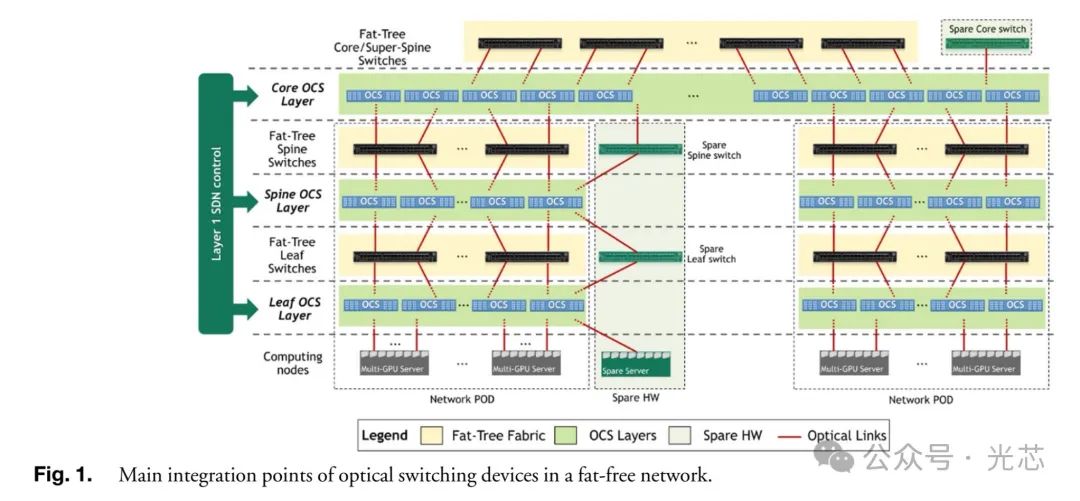
◆ OCS集成的位置与功能
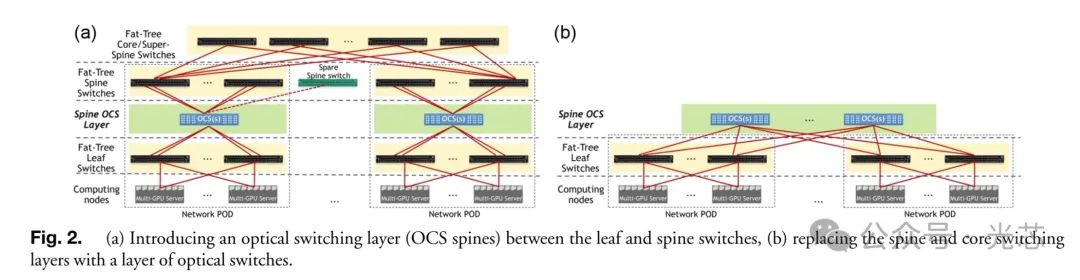
在通用三级胖树拓扑中,OCS有多种集成点,如在叶层和脊层间添加OCS层(脊OCS层)可保持胖树拓扑并实现隔离、冗余和拓扑调整;用OCS替换核心和脊交换机(OCS脊层)可构建精简网络。这些集成方式能实现拓扑重配置、提供网络弹性、隔离网络部分、改变拓扑结构等功能,以适应不同工作负载需求。
4. 将SDN扩展到网络L1层 讲控制面软件扩展作为L1 SDN控制器,通过基于图的数据模型管理物理拓扑,包括对网络物理层连接性建模、监测网络元素状态、与L2 SDN控制器集成、实现多供应商OCS控制平面互操作性、高效扩展到数千节点及低延迟操作等功能,还可根据应用场景增加故障检测与恢复、作业流量模式映射等功能。
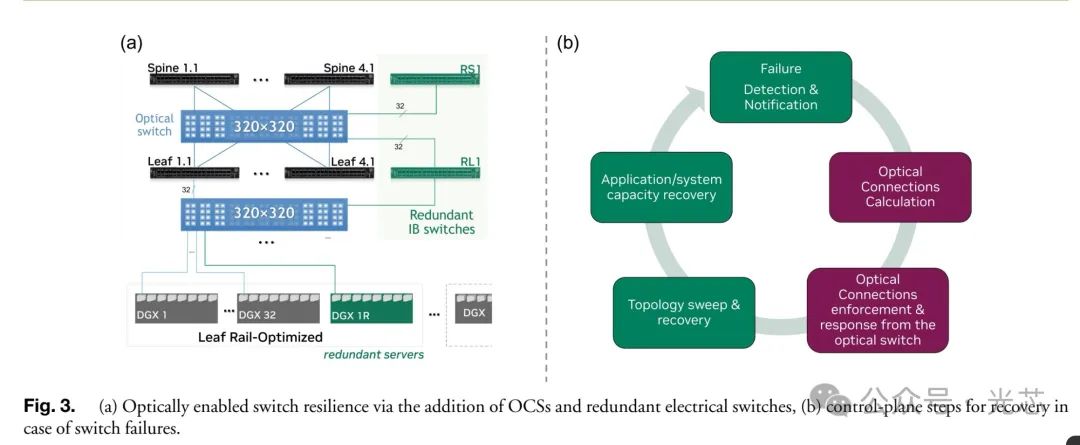
5. 光交换故障恢复实验 ◆ 基于OCS的故障恢复
多节点AI/HPC应用严重依赖大型网络,并且在网络元素发生故障时极易崩溃。在大型系统中,交换机或收发器每3到120小时可能发生故障[,这会导致重大的系统影响,由于系统在下次维护事件之前不可用,从而减少收入。具有数万个端点的系统的平均故障间隔时间(MTBF)将以分钟为单位测量。回滚到最新检查点的常见策略加剧了损失,因为它丢弃了检查点之后执行的所有计算。 目前大型系统网络中的故障恢复主要集中在L3支持上,即尽可能调整路由配置以排除故障路径,因为几乎没有或根本没有能力实时更改实际物理连接。本研究利用L1可编程数据平面和OCS,通过在交换层间添加OCS及冗余交换机,动态重配置网络实现高效自动故障恢复。在小规模DL测试平台(含DGX服务器和IB交换机)实验中,成功验证了该方法能在几秒内恢复集群性能,适用于多种应用和基准测试。
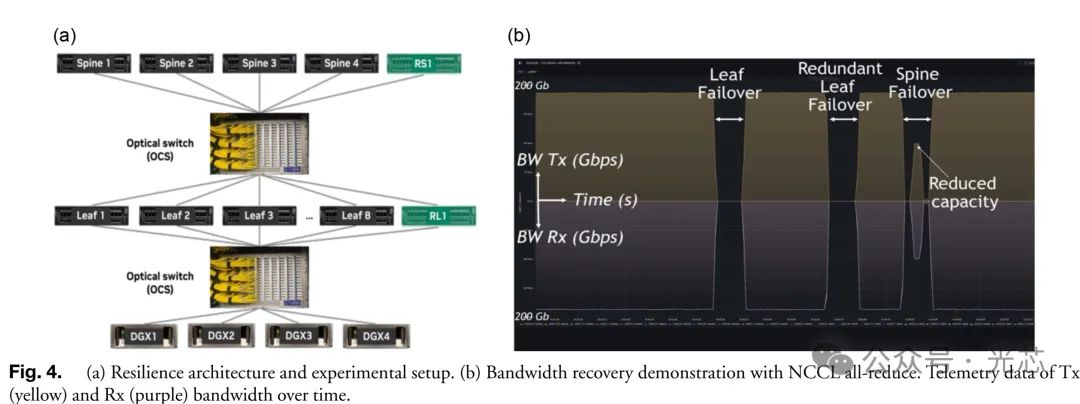
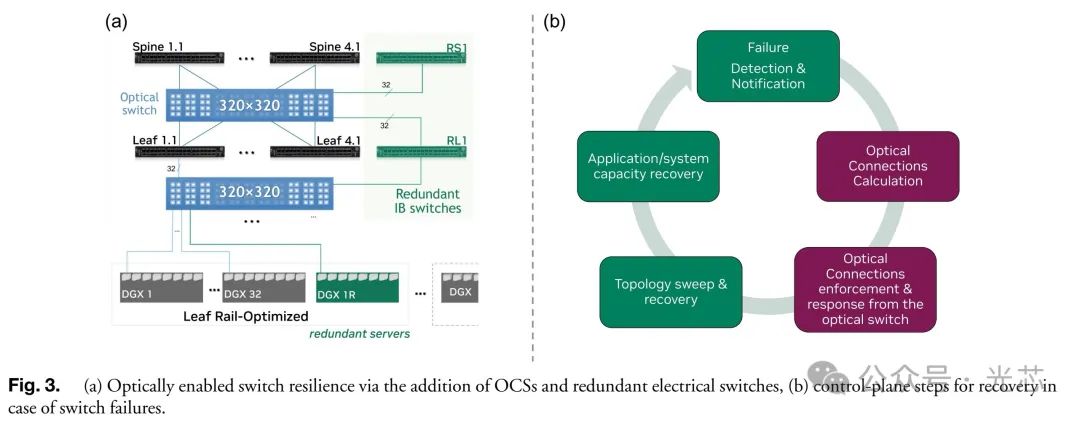
具体实验是部署了4个NVIDIA DGX A100服务器;14个IB Quantum交换机,包括8个叶交换机、4个脊交换机、1个冗余叶交换机(RL)和1个冗余脊交换机(RS)。服务器和交换机共使用114个CWDM 200 Gb/s 光模块。使用Polatis的320端口商用OCS用于服务器到叶交换机和叶交换机到脊交换机的连接,该OCS由定制的L1控制平面软件控制,用于物理层资源管理。启用弹性功能后,无论是叶交换机还是脊交换机故障,集群都能在几秒内恢复全部性能。例如,在使用NCCL all-reduce基准测试时,叶交换机故障导致的应用崩溃和脊交换机故障导致的性能下降问题,均能快速恢复。
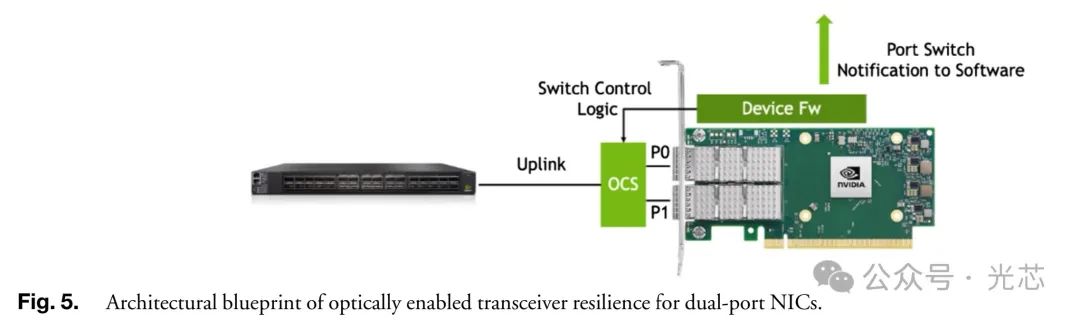
◆ NIC端基于1×2光开关的保护倒换 使用少端口1×N光开关(如1×2光开关)用于服务器NIC端收发器弹性,放置在NIC端口插件和交换机上行链路间,备份端口仅在故障时启用,不增加上行链路交换机端口负担。实验基于此构建环境,扩展NIC固件支持,测量链路故障恢复时间(如NVIDIA CX6 NIC 100G以太网端口约4秒),应用性能短暂波动后可恢复正常,在不同网络设置下均实现有效恢复。

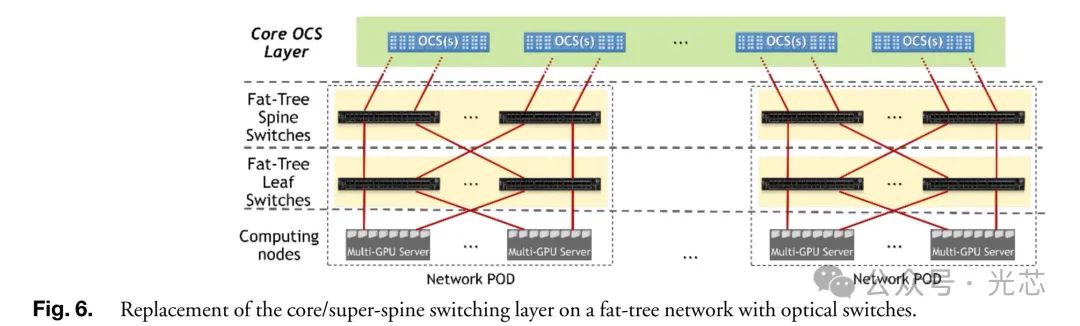
6. 基于OCS的深度学习训练 ◆ 替换核心交换层 将OCS集成在胖树拓扑核心层是实现光交换好处的重要步骤,可转化拓扑为可重构DF +,实现更优能效、更低成本和时延,支持可编程分配组间链路,提供拓扑定制和网络隔离,如适应特定流量模式和不同租户/应用需求。
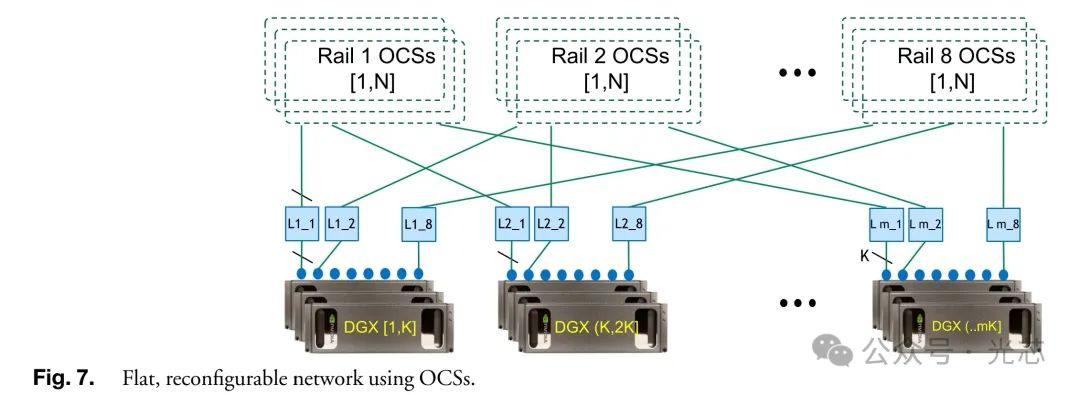
◆ 基于OCS的精简网络 针对LLM和DLRM等深度学习工作负载,设计扁平、低成本(降低30%)、低功耗(降低50%)和低延迟网络,通过可编程数据平面根据作业通信模式调整拓扑。如DLRM全对全模式采用完全图拓扑,LLM作业采用环面拓扑,通过合理分配服务器和交换机资源,实现全带宽通信。模拟分析显示,在资源利用率方面与胖树拓扑集群相近,同时减少了网络跳数和延迟,对作业执行时间的影响正在研究。
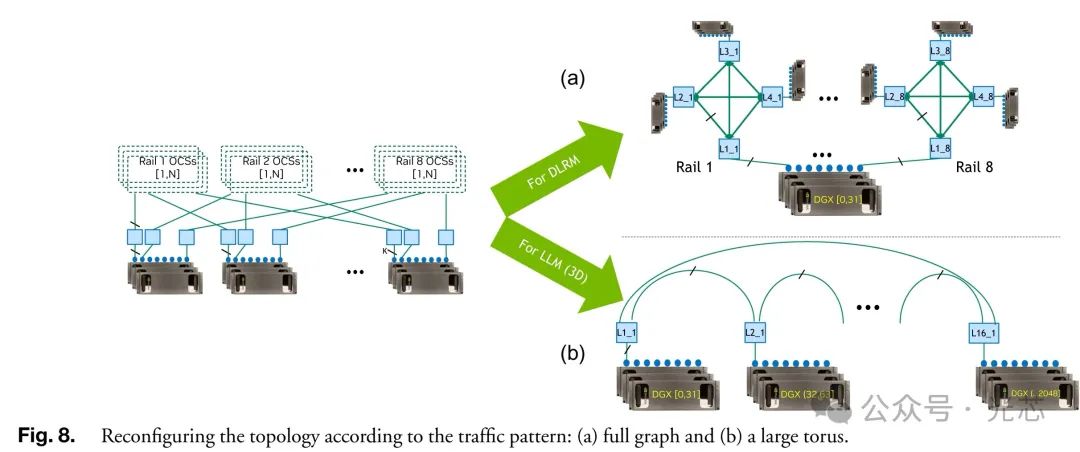
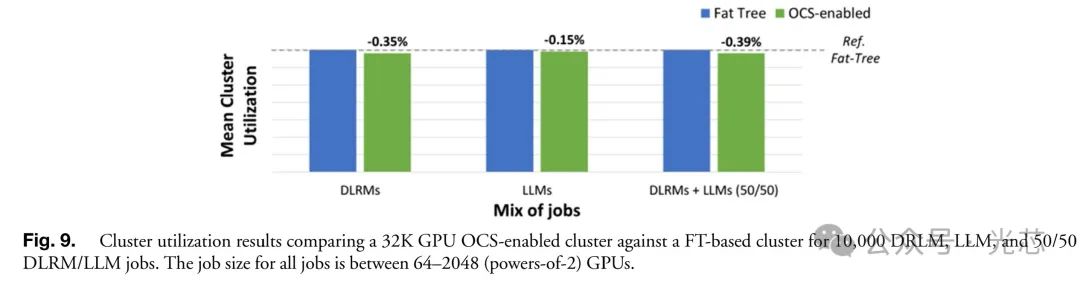
在仿真分析中,对于包含32K GPU节点的OCS集群与理想胖树架构集群对比,在处理10,000个作业(包括仅LLM、仅DLRM或两者混合的作业)时,OCS集群的利用率与参考胖树系统相比,在DLRM、LLM以及它们的混合场景下均保持在1%以内(图9)。
7. OCS技术与生态系统 ◆ 现状与挑战 OCS在数据中心和AI系统中部署增加,但技术仍不成熟,面临插入损耗大(消耗链路预算)、成本高、可靠性待提高等问题,且与收发器交互存在波长选择、光纤扇出和双向传输等方面的权衡。
◆ 发展方向 需提升光收发器与OCS兼容性,降低OCS成本(遵循成本降低曲线,集成光技术有望带来更大成本收益),提高可靠性(优化各构建模块,考虑芯片增益和放大器设计,改进系统设计),以加速OCS在数据中心和AI系统中的广泛应用。 8. 研究结论
光交换OCS成功将SDN可编程性扩展到物理层,实现实时故障转移(如在IB交换机故障时快速恢复集群性能)和优化拓扑以适应流量模式(如在LLM和DLRM训练中的应用)。持续投资OCS技术对降低成本、减少插入损耗和提高可靠性至关重要,这将进一步推动其在数据中心和AI系统中的广泛应用,为大规模计算系统的发展提供有力支持。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号