开发RAG被文档解析搞崩?试试EasyDoc,免费额度带你起飞。

开发RAG被文档解析搞崩?试试EasyDoc,免费额度带你起飞。

AI进修生
发布于 2025-04-26 20:25:53
发布于 2025-04-26 20:25:53
做 RAG 应用,文档预处理绝对是绕不过的坎。PDF、扫描件、Word 里的奇葩表格、图片、断裂的上下文… 处理这些玩意儿,费时费力还容易心态爆炸。
最近在做一个“中国企业出海策略”的 AI 问答,源数据全是各种 PDF 研究报告和政策文件。试了些开源解析工具,效果差点意思,关键信息抓瞎。
后来有人推荐了 EasyDoc。虽然是闭源产品,但推广期有免费额度,就试了下,感觉确实解决了些痛点。
直接上效果,看它处理复杂图文混排文档怎么样:
示例 1: 图文混排下的精准问答与溯源
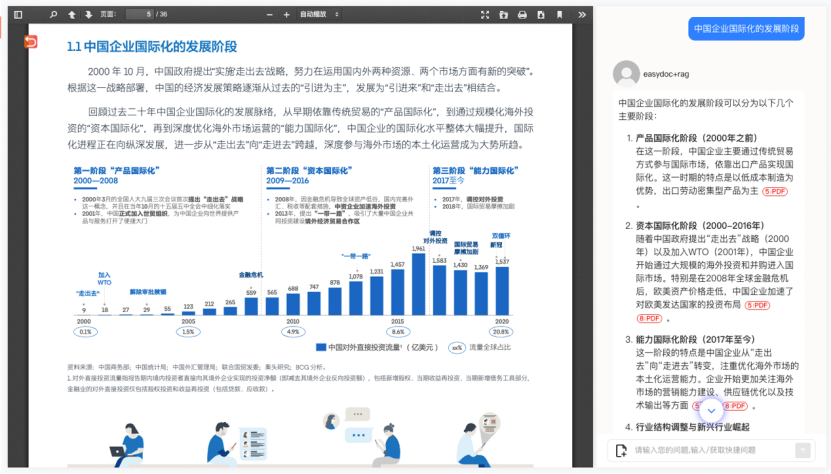
• 挑战: 典型的研究报告页面,大段文字描述“中国企业国际化发展阶段”,旁边配个“中国对外直接投资流量”柱状图,图上还有年份、数值、百分比、注解。传统工具要么忽略图表,要么信息提取不准,要么没法和文字关联。
- • EasyDoc 效果: (看截图右侧 RAG 问答) 它准确总结了几个发展阶段 (产品国际化、资本国际化等),并且 标注了信息来源页码。这说明它能理解图文结合的内容,并进行溯源。
示例 2: 复杂图表信息的精准提取与关联
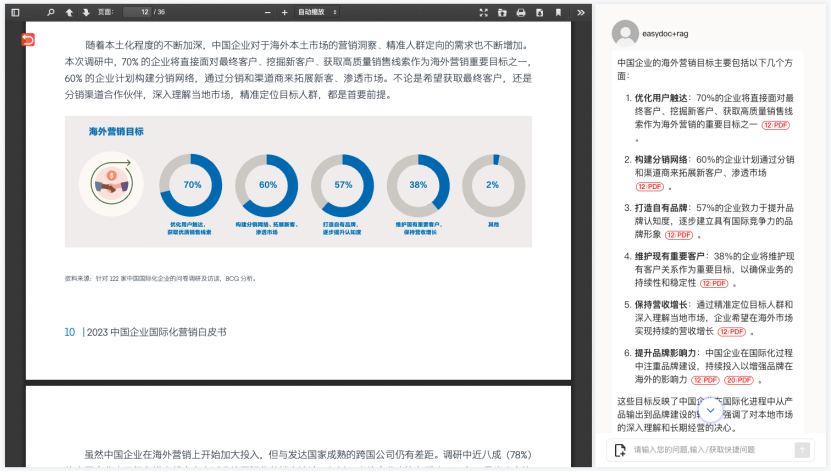
• 挑战: “海外营销目标”部分,文字旁边是一组并列的环形百分比图表,每个图有核心百分比 (70%, 60%, 57%) 和对应的文字说明 (优化用户触达、构建分销网络等)。很多工具读这种图表,要么只认数字,要么只认文字,很难正确匹配并关联上下文。
- • EasyDoc 效果: (看截图右侧 RAG 问答) 它精准提取了 每个图的核心数据和标签 (如 “优化用户触达:70%”、“构建分销网络:60%”、“打造自有品牌:57%”),并把这些信息和页面上对目标的详细描述关联起来,同样 清晰标注了来源页码 (12: PDF)。这说明它能理解并列图表结构,并智能关联上下文,避免模型“看图说话”式的错误。
所以,EasyDoc 到底是啥?
简单说,它是个智能文档解析引擎,专门为 AI 应用处理文档数据。支持 PDF, Word, PPT, TXT 等,输出适合 LLM 使用的 JSON 格式。

EasyDoc 的几个核心优势:
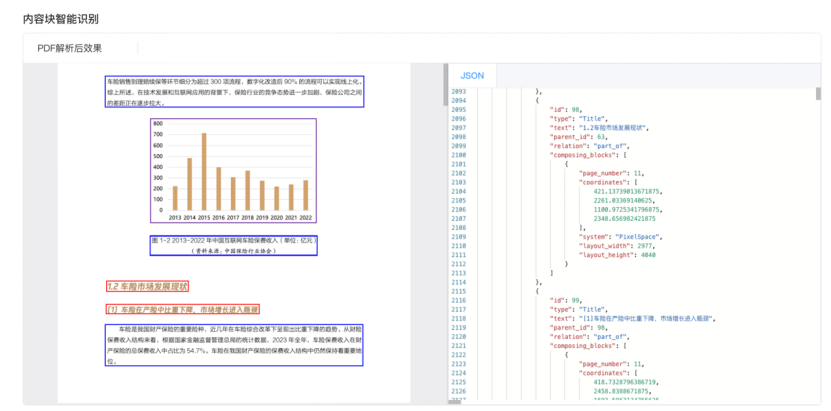
- 1. 内容块智能识别: 基于语义识别内容块,提取完整知识单元,提升 RAG 质量。
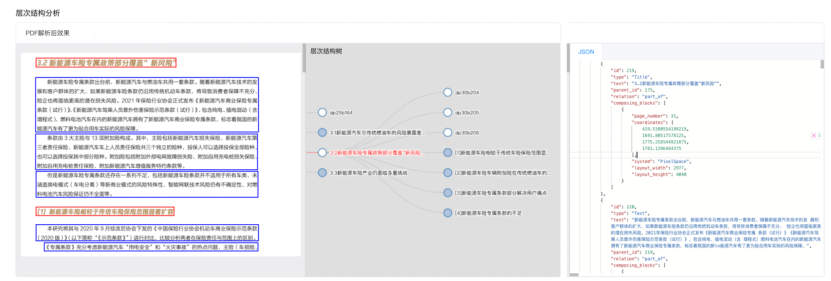
- 2. 层次结构分析: 能解析文档结构 (如章节条款),输出带层级关系的数据 (通过
parent_id追踪),方便 AI 理解上下文。
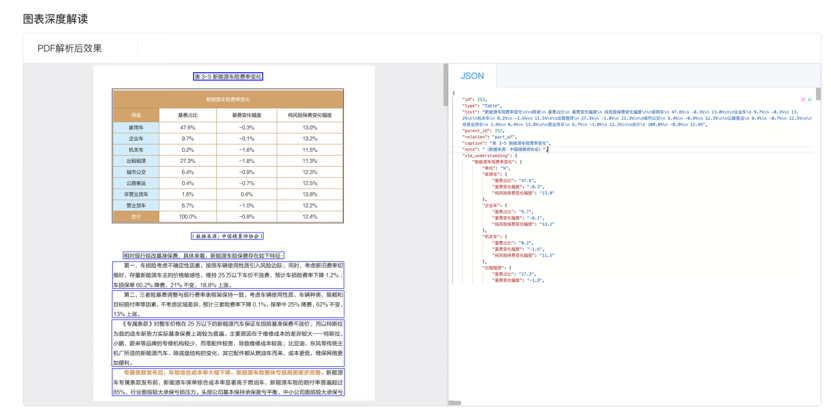
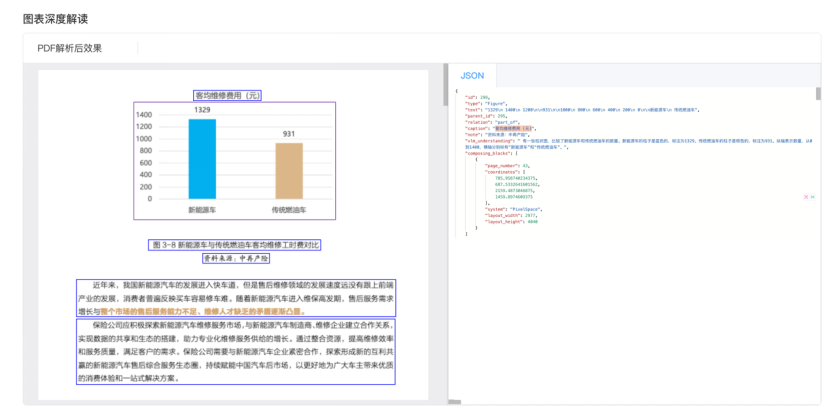
- 3. 表格和图片深度解读: 不光提取,还能理解表格和图片内容,输出结构化数据和语义解读 (结果体现在
vlm_understanding字段)。
API 调用方式挺直接:
提供三种模式:
• Lite 模式: 基础文本提取,适合快速开发和验证。
curl --location --request POST 'https://api.easydoc.sh/api/v1/parse' \
--header 'api-key: <YOUR_API_KEY>' \
--form 'file=@"<YOUR_FILE_PATH>"' \
--form 'mode="lite"'• Pro 模式: 保留完整文档层次结构,为 RAG 优化。
curl --location --request POST 'https://api.easydoc.sh/api/v1/parse' \
--header 'api-key: <YOUR_API_KEY>' \
--form 'file=@"<YOUR_FILE_PATH>"' \
--form 'mode="pro"'• Premium 模式: 解锁表格和图片深度解析,适合复杂数据处理。
curl --location --request POST 'https://api.easydoc.sh/api/v1/parse' \
--header 'api-key: <YOUR_API_KEY>' \
--form 'file=@"<YOUR_FILE_PATH>"' \
--form 'mode="premium"'本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号