编译原理工程实践—03使用递归下降算法实现简易语法分析器
原创

编译原理工程实践—03使用递归下降算法实现简易语法分析器
语法分析的目的是为了继续识别出程序结构,方便计算机的理解和执行。本章将在前面词法分析器基础上,实现一个简单的语法分析器,进一步处理解析出的 Token,最终生成一棵抽象语法树 AST。
1. 嵌套文法解析变量声明语句
语法分析使用的是 递归下降算法(Recursive Descent Parsing)"。具体的执行逻辑是:首先准备好各类语法规则解析函数,如变量声明语句、表达式语句、操作符语句等;语法分析时,调用这些函数和 Token 串做模式匹配,匹配成功则返回一个 AST 节点,否则返回 null;若中途检测出和语法规则不符则抛出编译错误。
参考下面的这个案例:针对语句 var a = 1+2*3;,语法分析器的文法规则调用顺序为 VariableDeclaration(变量声明语句) => VariableDeclarator(变量声明符) => 运算符(+) => 运算符(*)。
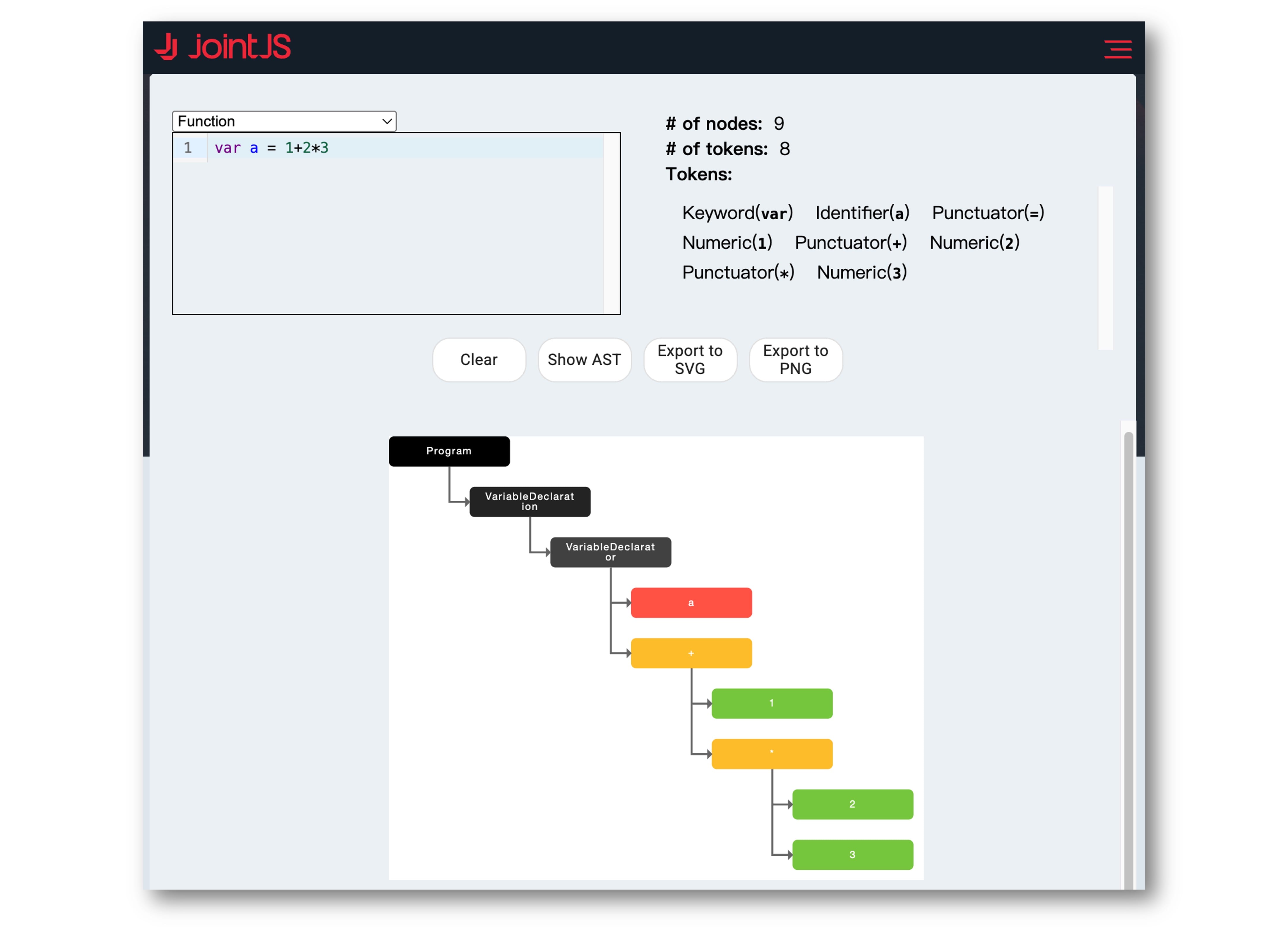
需要注意的是,这里的文法调用在程序里的体现并不是顺序调用,而是自顶向下嵌套调用,即上级文法嵌套下级文法,上级的算法调用下级的算法,表现在生成的 AST 中,上级算法生成上级节点,下级算法生成下级节点,这让 "下降" 理解起来非常直观。这也让递归下降算法实现起来比较简单,因为程序结构基本上是和文法规则同构的。接下来继续讲述这种嵌套文法对运算优先级、结合性的支持。
2. 上下文无关文法及文法产生式推导
上面提到的嵌套文法在编译领域更专业的名称是"上下文无关文法(Context-free Grammar, CFG)",这里上下文无关是指在任何情况下文法的推导规则都是一样的。
通过文法嵌套,能够轻松实现对 运算优先级 的支持!在上面的 var a = 1+2*3; 案例中,由于乘法规则是加法规则的子规则,所以在 AST 中乘法节点一定是加法节点的子节点,从而被优先计算。对于表达式的求值计算,只需要对根节点递归求值即可。需要注意的是,加法规则中仍然递归引用了加法规则,因此上下文无关文法能够形成所有可能的算术表达式。
不难发现,上下文无关文法的递归调用特性使其比正则文法的表达能力更强、更灵活。目前大多数计算机语言的语法都能用上下文无关文法来表达。
为了更方便地表达上下文无关文法,开发者常会使用 巴科斯范式(BNF) 写法,或是支持正则表达式写法的 扩展巴科斯范式(EBNF) 写法。例如算术表达式的文法规则可以写成:
add ::= mul | add + mul
mul ::= pri | mul * pri
pri ::= Id | Num | (add)优先级 pri>mul>add,add中调用mul,mul中调用pri。按照上述的文法产生式,add 可替换为 mul 或 add + mul。下面演示 1+2*3 和 1+2+3 两个算术表达式的"推导"过程,文法的推导就是把非终结符不断替换为非终结符的过程,这些终结符对应了词法分析的产物 Token!
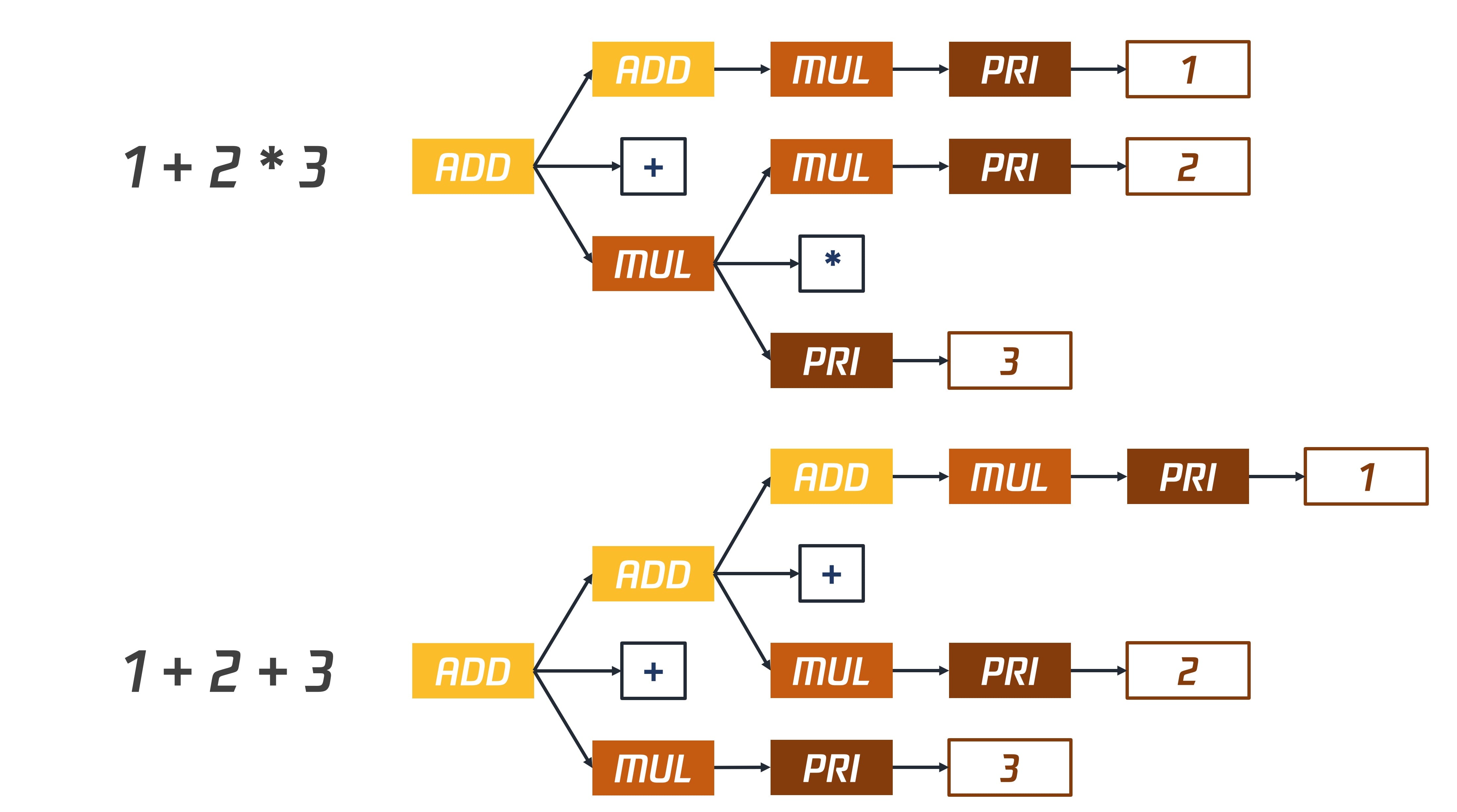
3. 优先级(Priority)的文法表达
在文法产生式中可以用上下层来表达优先级关系:
exp -> or | or = exp
or -> and | or || and
and -> equal | and && equal
equal -> rel | equal == rel | equal != rel
rel -> add | rel > add | rel < add | rel >= add | rel <= add
add -> mul | add + mul | add - mul
mul -> pri | mul * pri | mul / pri
# 在最高优先级中处理括号逻辑,此处用括号包裹表达式以递归地引用表达式
pri -> Id | Literal | (exp)上面表达的优先级从低到高分别为:赋值运算(exp)、逻辑运算(or)、逻辑运算(and)、相等比较(equal)、大小比较(rel)、加法运算(add)、乘法运算(mul)和基础表达式(pri)。
4. 结合性(Associativity)的处理
常见的算术运算是左结合的,但也有部分运算是右结合的,例如 x = y = 10。
处理方法也很简单,左结合的运算符,递归项放左边;右结合的运算符,递归项放右边。
5. 尾递归消除"左递归"问题
左递归(Left Recursive) 是二元表达式语法规则中的经典问题,即如果产生式的第一个元素是其自身,程序会无限地递归自身造成死循环,因此二元表达式的第一个元素不能设置为自身相同文法。例如,提及 add 文法规则,第一印象大多为:
add -> add + mul不难想到,可以改变递归项顺序规避左递归问题:
add -> mul + add使用 TypeScript 来实现,代码为:
private additive(tokens: TokenReader): SimpleASTNode {
// 出现结合性错误
const child1: SimpleASTNode = this.multiplicative(tokens); // left
let node: SimpleASTNode = child1;
const token = tokens.peek();
if (child1 !== null && token !== null) {
if (token.getType() === TokenType.Plus) { // +
const opToken = tokens.read();
const child2 = this.additive(tokens); // right
if (child2 !== null) {
node = new SimpleASTNode(ASTNodeType.Additive, opToken!.getText());
node.addChild(child1);
node.addChild(child2);
} else {
throw new Error('invalid additive expression, expecting the right part.');
}
}
}
if (node === null) {
throw new Error('additive expression expected');
}
}显而易见,这出现了结合性问题,如 1+2+3 的实际顺序为 1+(2+3),输出AST:
Programm Calculator
Additive +
IntLiteral 1
Additive +
IntLiteral 2
IntLiteral 3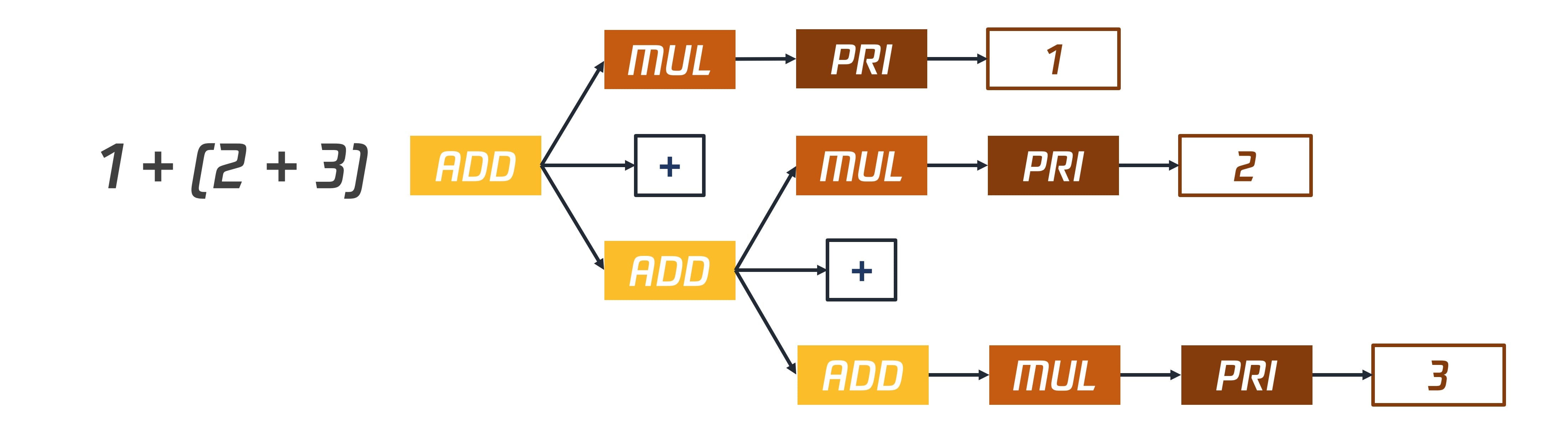
这里的矛盾点在于:常见的算术运算是左结合的,存在左递归问题!
在前面的设计里,是通过文法规则的设计避免了左递归与结合性错误的矛盾:
add -> mul | add + mul其实,还可以用一个标准的方法将左递归文法改写成非左递归的文法:
add -> mul add'
add' -> + mul add' | ε其中 ε 表示空集,可以用EBNF写法简写为:
add -> mul (+ mul)*对于 (+ mul)* 部分可以使用一个循环而非一次次的递归调用:
mul();
while(next token is +) {
mul();
createAddNode...
}编译程序通常都会把尾递归转化为一个循环语句,循环语句对系统资源的开销更低,这间接实现了编译优化!使用 TypeScript 实现为:
private additive(tokens: TokenReader): SimpleASTNode {
// add -> mul (+ mul)*
let child1: SimpleASTNode = this.multiplicative(tokens); // 应用add规则
let node: SimpleASTNode = child1;
if (child1) {
// 尾递归优化为循环,系统开销更低
while (true) {
// 循环应用add'规则
let token = tokens.peek();
if (token && token.getType() === TokenType.Plus) { // +
token = tokens.read(); // 读出加号
const child2 = this.multiplicative(tokens); // 计算下级节点
if (child2) {
node = new SimpleASTNode(ASTNodeType.Additive, token!.getText());
node.addChild(child1); //注意,新节点在顶层,保证正确的结合性
node.addChild(child2);
child1 = node; // 核心,实现左结合
} else {
throw new Error('invalid additive expression, expecting the right part.');
}
} else {
break;
}
}
}
return node;
}此时对于表达式 1+2+3 输出了正确的 AST:
Programm Calculator
Additive +
Additive +
IntLiteral 1
IntLiteral 2
IntLiteral 37. 递归下降中利用"回溯"匹配赋值语句
在递归下降算法匹配的过程中,经常需要做一些"试探"性匹配,成功则继续向下执行,失败了则需要"回溯"到试探开始前的位置,原样恢复后继续尝试其他规则。递归下降算法的实现比较简单,它通过试探和回溯机制,虽然会做一些无用功,但总能找到正确的匹配!
使用回溯机制可以实现赋值语句的匹配,TypeScript 代码实现如下:
public assignmentStatement(tokens: TokenReader): SimpleASTNode | null {
let node: SimpleASTNode | null = null;
let token: Token | null = tokens.peek(); // 预读当前token
if (token && token.getType() === TokenType.Identifier) {
token = tokens.read(); // 读入标识符
node = new SimpleASTNode(ASTNodeType.AssignmentStmt, token!.getText());
token = tokens.peek(); // 预读判断等号
if (token && token.getType() == TokenType.Assignment) {
tokens.read(); // 取出等号
const child = this.additive(tokens);
if (child == null) {
// 出错,等号右面没有一个合法的表达式
throw new Error('invalide assignment statement, expecting an expression');
} else {
node.addChild(child); // 添加子节点
token = tokens.peek(); // 预读判断分号
if (token && token.getType() == TokenType.SemiColon) {
tokens.read(); // 消耗掉分号
} else {
// 出错,缺少分号
throw new Error('invalid statement, expecting semicolon');
}
}
} else {
tokens.unread(); // 回溯,吐出之前消化掉的标识符
node = null;
}
}
return node;
}8. 源码实现简易语法分析器
经过上述分析,已经可以轻松实现一个简单的语法分析器了,我们用 TypeScript 来实现 SimpleParser 类,能够解析简单的表达式、变量声明和初始化语句、赋值语句,生成简化的AST,核心在于解决二元表达式中的难点: 确保正确的优先级和结合性,以及消除左递归。
/**
* 一个简单的语法解析器
* 基于递归下降算法和上下文无关文法, 生成简化的AST
* 能够解析简单的表达式、变量声明和初始化语句、赋值语句
* 核心在于解决二元表达式中的难点: 确保正确的优先级和结核性,以及消除左递归
* 关注赋值表达式,使用了"回溯"
*
* 支持的语法规则:
* programm -> intDeclare | expressionStatement | assignmentStatement
* intDeclare -> 'int' Id ( = additive) ';'
* expressionStatement -> addtive ';'
* addtive -> multiplicative ( (+ | -) multiplicative)*
* multiplicative -> primary ( (* | /) primary)*
* primary -> IntLiteral | Id | (additive)
*/
import SimpleLexer, { Token, TokenReader, TokenType, testLexer } from '../SimpleLexer';
/**
* AST节点类型枚举
*/
enum ASTNodeType {
Programm = 'Programm', // 程序入口,根节点
IntDeclaration = 'IntDeclaration', // 整型变量声明
ExpressionStmt = 'ExpressionStmt', // 表达式语句,即表达式+分号
AssignmentStmt = 'AssignmentStmt', // 赋值语句
Primary = 'Primary', // 基础表达式
Multiplicative = 'Multiplicative', // 乘法(除法)表达式
Additive = 'Additive', // 加法(减法)表达式
Identifier = 'Identifier', // 标识符
IntLiteral = 'IntLiteral', // 整型字面量
}
/**
* AST节点
*/
interface ASTNode {
getParent(): ASTNode | null;
getChildren(): ASTNode[];
getType(): ASTNodeType;
getText(): string;
}
/**
* 简单的AST节点实现
*/
class SimpleASTNode implements ASTNode {
private parent: ASTNode | null = null;
private children: ASTNode[] = [];
private readonly nodeType: ASTNodeType; // AST节点类型
private readonly text: string; // 初始化的文本参数,如整型变量声明时的变量名
constructor(nodeType: ASTNodeType, text: string) {
this.nodeType = nodeType;
this.text = text;
}
getParent(): ASTNode | null {
return this.parent;
}
getChildren(): ASTNode[] {
return [...this.children]; // 返回副本
}
getType(): ASTNodeType {
return this.nodeType;
}
getText(): string {
return this.text;
}
addChild(child: SimpleASTNode): void {
this.children.push(child);
child.parent = this;
}
}
class SimpleParser {
/**
* 解析脚本,并返回根节点
* @param {string} code 脚本代码
* @returns {ASTNode} AST根节点
* @throws 解析错误时抛出异常
*/
public parse(code: string): ASTNode {
// 词法解析
const lexer = new SimpleLexer();
const tokens = lexer.tokenize(code);
// 语法解析
const rootNode = this.prog(tokens);
return rootNode;
}
/**
* 语法解析:根节点
* @param {TokenReader} tokens Token读取器
* @returns {SimpleASTNode} AST节点
* @throws 解析错误时抛出异常
*/
private prog(tokens: TokenReader): SimpleASTNode {
const node = new SimpleASTNode(ASTNodeType.Programm, 'demo');
while (tokens.peek()) {
let child: SimpleASTNode | null = this.intDeclare(tokens);
if (child === null) {
child = this.expressionStatement(tokens);
}
if (child === null) {
child = this.assignmentStatement(tokens);
}
if (child) {
node.addChild(child);
} else {
throw new Error('unknown statement');
}
}
return node;
}
/**
* 表达式语句,即表达式后面跟个分号。
* @return
* @throws Exception
*/
public expressionStatement(tokens: TokenReader): SimpleASTNode | null {
const pos = tokens.getPosition();
let node: SimpleASTNode | null = this.additive(tokens);
if (node) {
const token = tokens.peek();
if (token && token.getType() === TokenType.SemiColon) {
tokens.read();
} else {
node = null;
tokens.setPosition(pos); // 回溯
}
}
return node; //直接返回子节点,简化了AST。
}
/**
* 赋值语句
* @param {TokenReader} tokens Token读取器
* @return { SimpleASTNode | null } AST节点
* @throws 解析错误时抛出异常
*/
public assignmentStatement(tokens: TokenReader): SimpleASTNode | null {
let node: SimpleASTNode | null = null;
let token: Token | null = tokens.peek(); // 预读当前token
if (token && token.getType() === TokenType.Identifier) {
token = tokens.read(); // 读入标识符
node = new SimpleASTNode(ASTNodeType.AssignmentStmt, token!.getText());
token = tokens.peek(); // 预读判断等号
if (token && token.getType() == TokenType.Assignment) {
tokens.read(); // 取出等号
const child = this.additive(tokens);
if (child == null) {
// 出错,等号右面没有一个合法的表达式
throw new Error('invalide assignment statement, expecting an expression');
} else {
node.addChild(child); // 添加子节点
token = tokens.peek(); // 预读判断分号
if (token && token.getType() == TokenType.SemiColon) {
tokens.read(); // 消耗掉分号
} else {
// 出错,缺少分号
throw new Error('invalid statement, expecting semicolon');
}
}
} else {
tokens.unread(); // 回溯,吐出之前消化掉的标识符
node = null;
}
}
return node;
}
/**
* 整型变量声明语句
* @param {TokenReader} tokens Token读取器
* @returns {SimpleASTNode} AST节点
* @throws 解析错误时抛出异常
*/
public intDeclare(tokens: TokenReader): SimpleASTNode | null {
let node: SimpleASTNode | null = null;
let token: Token | null = tokens.peek(); // 预读当前token
// 流程解读:解析变量声明语句时(如 int a = b+1)
// [1] 匹配int关键字:先判断第一个 token 是否为 int
if (token?.getType() === TokenType.Int) {
token = tokens.read(); // 消耗掉int
// [2] 匹配标识符:若 int 后匹配到变量名称标识符,则创建 AST 节点
if (tokens.peek()?.getType() === TokenType.Identifier) {
token = tokens.read(); // 消耗掉标识符
// 创建 ast 节点,并传入变量名
node = new SimpleASTNode(ASTNodeType.IntDeclaration, token!.getText());
// [3] 匹配等号:判断后面是否跟了初始化部分,即等号加一个表达式
token = tokens.peek();
if (token && token.getType() === TokenType.Assignment) {
tokens.read(); // 消耗掉等号
// [4] 匹配表达式
const child = this.additive(tokens);
if (child === null) {
throw new Error('invalide variable initialization, expecting an expression');
} else {
node.addChild(child);
}
}
} else {
throw new Error('variable name expected');
}
if (node) {
token = tokens.peek();
if (token && token.getType() === TokenType.SemiColon) {
tokens.read();
} else {
throw new Error('invalid statement, expecting semicolon');
}
}
}
return node;
}
/**
* 语法解析:加法表达式
* 包含减法,因为减法是特殊的加法
* @param {TokenReader} tokens Token读取器
* @returns {SimpleASTNode} AST节点
* @throws 解析错误时抛出异常
*/
private additive(tokens: TokenReader): SimpleASTNode {
// add -> mul (+ mul)*
let child1: SimpleASTNode = this.multiplicative(tokens); // 应用add规则
let node: SimpleASTNode = child1;
if (child1) {
// 尾递归优化为循环,系统开销更低
while (true) {
// 循环应用add'规则
let token = tokens.peek();
if (token && (token.getType() === TokenType.Plus || token.getType() === TokenType.Minus)) {
token = tokens.read(); // 读出加号
const child2 = this.multiplicative(tokens); // 计算下级节点
if (child2) {
node = new SimpleASTNode(ASTNodeType.Additive, token!.getText());
node.addChild(child1); //注意,新节点在顶层,保证正确的结合性
node.addChild(child2);
child1 = node; // 核心,实现左结合
} else {
throw new Error('invalid additive expression, expecting the right part.');
}
} else {
break;
}
}
}
return node;
}
/**
* 语法解析:乘法表达式
* 包含除法,因为除法是特殊的乘法
* @param {TokenReader} tokens Token读取器
* @returns {SimpleASTNode} AST节点
* @throws 解析错误时抛出异常
*/
private multiplicative(tokens: TokenReader): SimpleASTNode {
// mul -> pri (* pri)*
let child1: SimpleASTNode = this.primary(tokens);
let node: SimpleASTNode = child1;
while (true) {
let token = tokens.peek();
if (token && (token.getType() == TokenType.Star || token.getType() == TokenType.Slash)) {
token = tokens.read();
const child2 = this.multiplicative(tokens);
if (child2) {
node = new SimpleASTNode(ASTNodeType.Multiplicative, token!.getText());
node.addChild(child1);
node.addChild(child2);
child1 = node;
} else {
throw new Error('invalid multiplicative expression, expecting the right part.');
}
} else {
break;
}
}
return node;
}
/**
* 语法解析:基础表达式
* @param tokens Token读取器
* @returns AST节点
* @throws 解析错误时抛出异常
*/
private primary(tokens: TokenReader): SimpleASTNode {
// pri -> Id | Num | (add)
let node: SimpleASTNode | null = null;
let token = tokens.peek();
if (token !== null) {
if (token.getType() === TokenType.IntLiteral) {
token = tokens.read();
node = new SimpleASTNode(ASTNodeType.IntLiteral, token!.getText());
} else if (token.getType() === TokenType.Identifier) {
token = tokens.read();
node = new SimpleASTNode(ASTNodeType.Identifier, token!.getText());
} else if (token.getType() === TokenType.LeftParen) {
tokens.read();
// 处理(add)
node = this.additive(tokens);
if (node !== null) {
token = tokens.peek();
if (token !== null && token.getType() === TokenType.RightParen) {
tokens.read();
} else {
throw new Error('expecting right parenthesis');
}
} else {
throw new Error('expecting an additive expression inside parenthesis');
}
}
}
if (node === null) {
throw new Error('primary expression expected');
}
return node;
}
/**
* 打印输出AST的树状结构
* @param {ASTNode} node AST节点
* @param {string} indent 缩进字符串
*/
public dumpAST(node: ASTNode, indent: string): void {
console.log(indent + node.getType() + ' ' + node.getText());
for (const child of node.getChildren()) {
this.dumpAST(child, indent + '\t');
}
}
}
export default SimpleParser;
export { ASTNodeType };
export type { ASTNode };编写测试函数:
const testSimpleCalculator = () => {
const parser = new SimpleParser();
let script: string;
let tree: ASTNode;
try {
script = 'int age = 1+2+3;';
console.log('解析:' + script);
tree = parser.parse(script);
parser.dumpAST(tree, '');
} catch (e) {
console.log(e);
}
};
// 运行测试
testSimpleCalculator();输出结果为:
解析:int age = 1+2+3;
Programm demo
IntDeclaration age
Additive +
Additive +
IntLiteral 1
IntLiteral 2
IntLiteral 3优先级、结合性未出现问题,至此,一个简单的语法分析器开发完成。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号