ACL 2025 高分接收 | 高感情语音技术:逻辑智能小语种TTS破局之道

ACL 2025 高分接收 | 高感情语音技术:逻辑智能小语种TTS破局之道

机器之心
发布于 2025-05-27 09:22:00
发布于 2025-05-27 09:22:00
该工作由北京深度逻辑智能科技有限公司×宁波东方理工EIT-NLP实验室联合完成。
语音合成(TTS)技术近十年来突飞猛进,从早期的拼接式合成和统计参数模型,发展到如今的深度神经网络与扩散、GAN 等先进架构,实现了接近真人的自然度与情感表达,广泛赋能智能助手、无障碍阅读、沉浸式娱乐等场景。
然而,这一繁荣几乎局限于英语、普通话等资源充沛的大语种;全球一千多种小语种由于语料稀缺、文字无空格或多音调等复杂语言学特性,在数据收集、文本前端处理和声学建模上都面临巨大挑战,导致高质量 TTS 迟迟无法落地。破解「小语种困境」既是学术前沿课题,也是实现数字包容与多语文化传播的关键。
面对这一挑战,逻辑智能团队提出了一种针对低资源语言 TTS 的解决方案并应用于泰语 TTS 合成,该工作已经被 ACL 2025 Industry track 正式接收!

- 论文标题:Scaling Under-Resourced TTS: A Data-Optimized Framework with Advanced Acoustic Modeling for Thai
- 论文地址:https://arxiv.org/abs/2504.07858
- 效果试听:https://luoji.cn/static/thai/demo.html
这项工作提出了一种数据优化驱动的声学建模框架的创新方案,通过从语音、文本、音素、语法等多个维度构建系统化的泰语数据集,并结合先进的声学建模技术,成功实现了在有限资源下的高质量 TTS 合成效果。
此外,该框架还具备 zero-shot 声音克隆的能力,展示了优异的跨场景适用性,为行业提供了一种在数据稀少环境下高效构建小语种 TTS 系统的有效范式,对推动全球小语种 TTS 技术的落地与普及具有重要的启示和借鉴意义。
数据优化驱动的声学建模框架方案
该工作遵循数据驱动模型能力的整体思路:
- 首先从源头切入,系统化采集并标注跨领域语音、文本与语言学信息,构建覆盖广、颗粒度细的多维泰语语料库;
- 随后通过 LLM 增强的停顿预测、词切分与混合式 G2P,将原始文本稳健转换为结构化的「音素-声调」序列;
- 最后在此精炼输入之上,引入声调感知的 Phoneme-Tone BERT 与多源特征驱动的 GAN 解码器,实现高保真、低延迟的语音合成,并支持零样本声音克隆。
整套框架以数据质量为核心抓手、以模块化设计保障可扩展性,为解决小语种 TTS「数据稀缺 + 语言复杂」双重瓶颈提供了一条可复制、可落地的工程化路径。
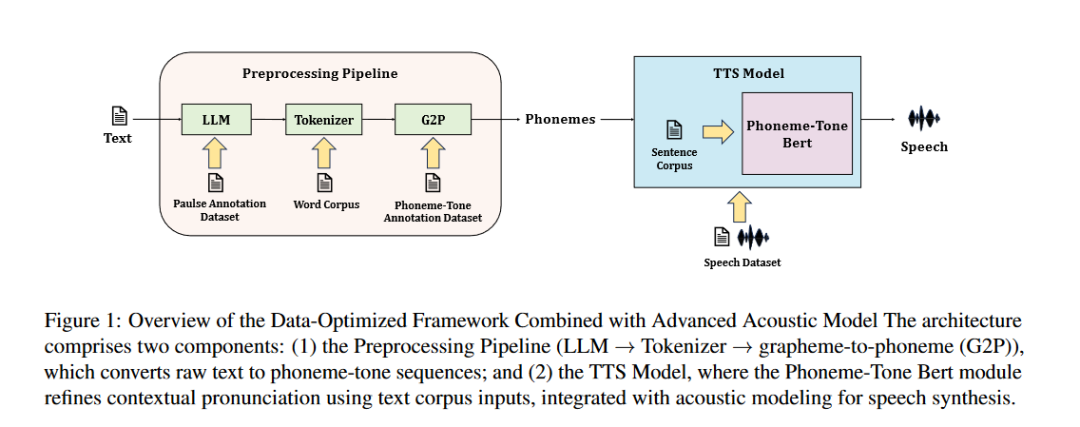
泰语专项数据集构建
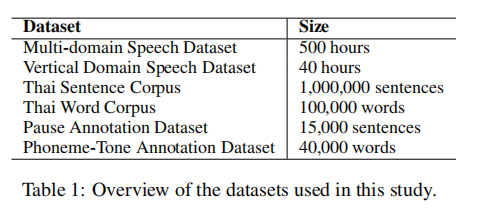
该工作构建了一套专为低资源泰语 TTS 设计的多维数据集,涵盖语音、文本和注释三大类:
- 语音数据——500 小时来自新闻、社媒、播客等多领域语料,外加 40 小时金融、医疗、教育、法律等垂直领域语料,兼顾通用合成与专业术语发音;
- 文本数据——100 万句句子语料用于训练 Phoneme-Tone BERT 提升上下文韵律建模,10 万词词表用于训练分词器,解决泰语无空格书写难题;
- 注释数据——1.5 万句停顿标注确保精准断句,4 万词音素-声调标注强化 G2P 与五声调建模。该数据集既保证了规模,又注重多域覆盖和细粒度语言监督,为在资源稀缺环境下实现工业级泰语 TTS 与零样本声音克隆奠定了坚实基础。
先进的预处理流程
该工作设计了一套强大的预处理流程。预处理流水线最大的亮点在于「三步一体、逐层解耦」地化解泰语文本的无标点、无空格、声调复杂三重难题:
- 首先通过 SFT 微调的 Typhoon2 LLM,对 1.5 万句人工标注语料学习停顿规律,在原始文本中智能插入停顿标签以更好地建模口语韵律;
- 随后在扩充至 10 万词的分词词典支撑下,改进版 pythainlp Tokenizer 将连续书写的泰文字流精准切分,为领域专有词提供稳健支持;
- 最后利用 4 万词的音素-声调注释库,结合规则+Transformer 混合式 G2P,把每个词映射成带五声调标记的 IPA 音素序列。
该流水线不仅输出结构化的「音素-声调」序列,大幅降低后续声学模型学习难度,也为其他低资源音调语言提供了可复用的文本前端范式。
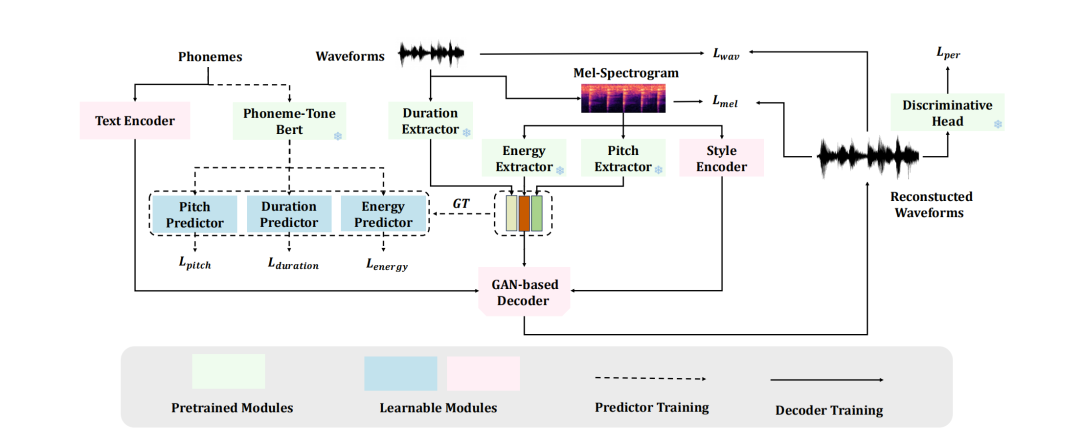
卓越的 TTS 模型架构
该工作的 TTS 模型集成了「多源特征 × 声调感知 × 零样本克隆」的组合设计:
- 首先利用多语种预训练模型提取时长、音高、能量等强鲁棒特征,并以风格编码器压缩说话人/情感信息,为后续零样本克隆奠定基础;
- 其次,通过 Phoneme-Tone BERT 在音素序列中显式融入五声调,精准捕捉泰语语义-韵律关联;
- 最后以 GAN 解码器直接从音素与预测特征合成波形,联合时域、频域与感知损失实现高保真、低延迟合成。
整体采取「先独立训练预测器,再与解码器联合微调」的策略,兼顾稳定性与音质,使模型达到 SOTA 表现并支持零样本声音克隆。
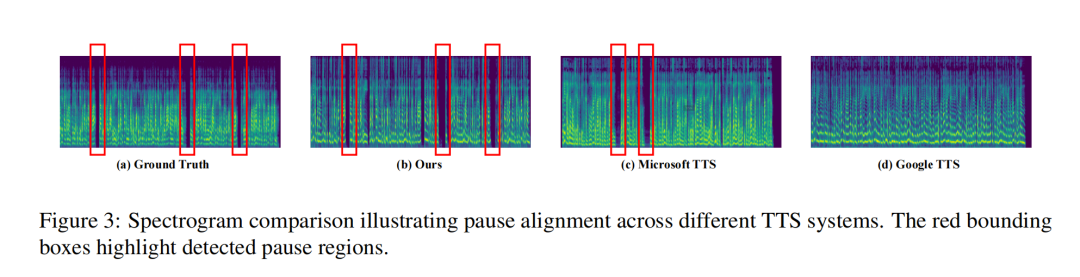
实验效果
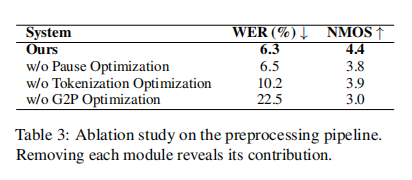
- 预处理链路有效性:消融实验表明,停顿预测、分词优化和 G2P 优化缺一不可;当分别移除这三项时,系统的 WER 从 6.3% 依次升至 6.5%、10.2% 与 22.5%,自然度评分 NMOS 从 4.4 下降到 3.8、3.9 与 3.0,尤其 G2P 的影响最大,证明精确声调与音素映射是泰语 TTS 的质量瓶颈。
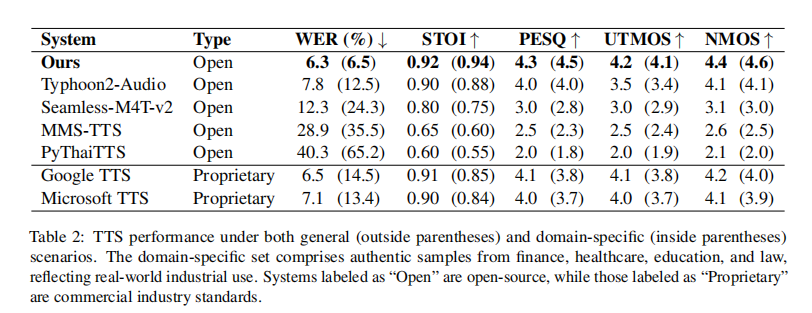
- 通用与行业场景综合表现:在公开基准 TSync2 和金融、医疗、教育、法律四大真实业务脚本上,模型始终保持最低 WER 与最高 NMOS,不仅超越开源系统,也优于 Google TTS、Microsoft TTS 等商业方案;特别是在专业术语发音与语速控制上,用户反馈显示本系统误读率更低、韵律更自然,验证了该框架对多场景的强鲁棒性与可落地性。
- 零样本声音克隆能力:在仅提供几秒参考音的条件下,模型即可生成目标说话人高保真语音,取得 SIM 0.91 和 SMOS 4.5,显著超过 OpenVoice 的 0.85 与 4.0;嵌入可视化进一步展示了对说话人 timbre 的准确聚类,表明「声调感知 + 多源特征」设计能够在低资源环境下实现工业级的声音克隆体验。

转载请联系本公众号获得授权
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号