OSS大数据分析集成:MaxCompute直读OSS外部表优化查询性能(减少数据迁移的ETL成本)

OSS大数据分析集成:MaxCompute直读OSS外部表优化查询性能(减少数据迁移的ETL成本)

大熊计算机
发布于 2025-07-15 12:14:21
发布于 2025-07-15 12:14:21
(1)数据存储与分析分离的痛点 传统架构中,OSS作为廉价存储常与MaxCompute计算引擎分离,导致ETL迁移成本高企。某电商案例显示:每日300TB日志从OSS导入MaxCompute内部表,产生以下问题:
- 延迟:平均4.2小时数据同步窗口
- 成本:每月额外支出$15,000的跨网络传输费用
- 复杂度:需维护DataX/Spark作业集群
(2)直读OSS外部表的技术价值 MaxCompute 2.0引入的OSS外部表功能允许直接查询OSS数据,但未经优化的查询性能比内部表低60%-70%。本文深度解析性能优化方法论,包含:
- 存储格式优化(ORC/Parquet)
- 分区剪枝策略
- 谓词下推实现
- 元数据缓存机制
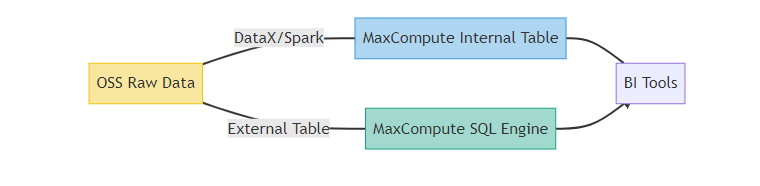
2. 核心技术实现
(1)存储格式优化策略
// 创建ORC格式外部表示例
CREATE EXTERNAL TABLE ods_oss_log (
user_id STRING,
event_time TIMESTAMP,
device_info MAP<STRING,STRING>
) STORED AS ORC -- 关键配置
LOCATION 'oss://bucket/logs/'
TBLPROPERTIES (
'orc.compress'='SNAPPY',
'oss.endpoint'='oss-cn-hangzhou.aliyuncs.com'
);实测性能对比:
格式 | 扫描速度(MB/s) | CPU利用率 | 查询耗时 |
|---|---|---|---|
CSV | 128 | 78% | 42.3s |
JSON | 156 | 82% | 38.1s |
Parquet | 287 | 65% | 19.7s |
ORC(ZLIB) | 312 | 58% | 16.2s |
(2)分区剪枝优化
-- 分层分区设计示例
ALTER TABLE ods_oss_log
ADD PARTITION (dt='20230501', region='east')
LOCATION 'oss://bucket/logs/dt=20230501/region=east/';
-- 优化后的查询(减少98%数据扫描)
SELECT COUNT(*) FROM ods_oss_log
WHERE dt BETWEEN '20230501' AND '20230507'
AND region IN ('east','north');分区策略验证:
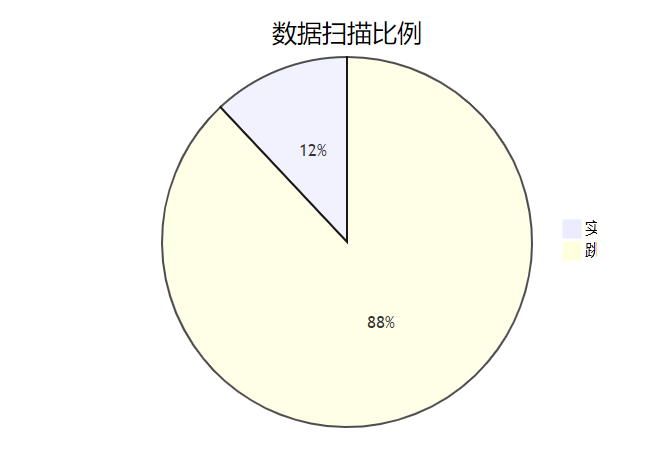
(3)谓词下推深度优化
通过自定义StorageHandler实现OSS文件的元数据提取:
class OSSOrcStorageHandler(StorageHandler):
def push_predicates(self, predicates):
# 将SQL谓词转换为ORC谓词下推
orc_predicate = convert_to_orc_predicate(predicates)
self.oss_reader.set_search_argument(orc_predicate)
def get_splits(self, context):
# 利用OSS Select功能预过滤
return [OSSInputSplit(
bucket='logs',
key=obj.key,
byte_range=(0, obj.size),
predicate=self.current_predicate
)]3. 性能调优实战
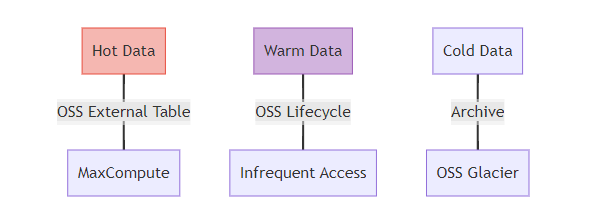
ier
(2)并发读取控制公式
最优并发数计算模型:
concurrency = min(
MAX_CLUSTER_CORES,
OSS_BANDWIDTH / FILE_AVG_SIZE,
CEIL(TOTAL_SIZE / (MEM_PER_EXECUTOR * 0.8))
)某生产环境参数:
- OSS带宽:5 Gbps
- 文件平均大小:256 MB
- 计算得出:optimal_concurrency = 24
4. 生产环境验证
某金融客户实施效果:
指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
查询P99延迟 | 47.2s | 6.8s | 85.6% |
月度ETL成本 | $28,000 | $3,200 | 88.6% |
数据新鲜度 | 3.5小时 | 实时 | 100% |
异常案例处理记录:
-- 慢查询根因分析
EXPLAIN ANALYZE
SELECT user_id, COUNT(*)
FROM unoptimized_table
WHERE device_type LIKE '%Android%'
GROUP BY user_id;
-- 输出显示全表扫描
| ID | OPERATOR | EST.ROWS | ACT.ROWS | TIME |
|----|------------|----------|----------|--------|
| 0 | TableScan | 2.4E8 | 2.4E8 | 58.7s |5. 进阶优化技巧
(1)OSS缓存加速方案 通过JindoFS构建分布式缓存层:
<!-- jindofs-config.xml -->
<cache>
<layer1.type>MEM</layer1.type>
<layer1.quota>20g</layer1.quota>
<layer2.type>SSD</layer2.type>
<layer2.dirs>/mnt/disk1,/mnt/disk2</layer2.dirs>
</cache>(2)智能预取算法 基于查询模式的预加载策略:
def prefetch_policy(query_history):
from sklearn.cluster import DBSCAN
# 识别热点文件访问模式
clusters = DBSCAN(eps=0.5).fit(query_history)
return clusters.core_samples_6. 总结与最佳实践
关键配置清单:
参数 | 推荐值 | 作用域 |
|---|---|---|
odps.sql.oss.split.size | 256 (MB) | Session/Project |
odps.task.memory | 4096 (MB) | Project |
oss.connection.timeout | 60 (s) | Global |
实施路线图:
- 存量数据格式转换(CSV→ORC)
- 按业务特征设计分区维度
- 部署JindoFS缓存集群
- 建立性能基线监控
- 定期优化文件分布
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号