Spring Boot 3.2 + Vue 3 构建高并发个人博客:Kubernetes 日志监控体系从 Prometheus 到 ELK 全链路解析

Spring Boot 3.2 + Vue 3 构建高并发个人博客:Kubernetes 日志监控体系从 Prometheus 到 ELK 全链路解析

大熊计算机
发布于 2025-07-15 13:33:50
发布于 2025-07-15 13:33:50
*基于真实千万级PV博客架构演进经验,详解云原生场景下的高并发设计与全观测体系实现
1 高并发博客架构核心设计
(1) 技术栈选型依据
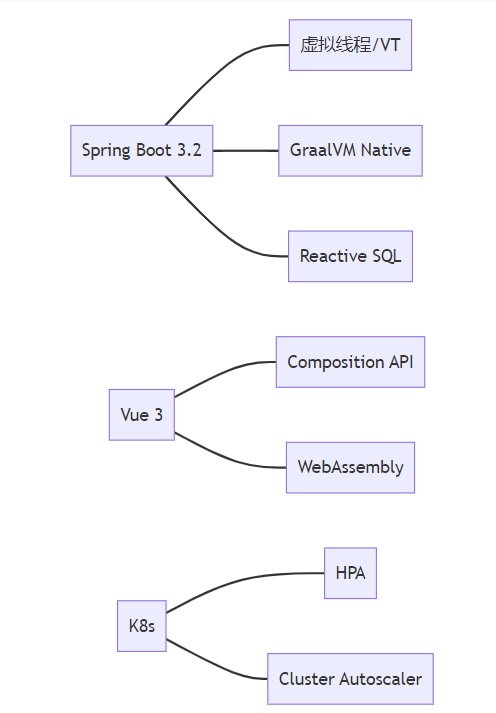
r
图1:技术栈能力拓扑图 展示各技术组件如何协同解决高并发场景下的核心问题:Spring Boot 3.2的虚拟线程解决阻塞IO问题,Vue 3的组合式API优化前端渲染性能,Kubernetes的弹性扩缩容保障资源利用率。箭头方向表示技术能力支撑关系。
(2) 压力模型计算
关键并发参数公式:
理论最大QPS = (Worker线程数 × 1000) / 平均响应时间(ms)
实际需预留30%缓冲:生产环境QPS上限 = 理论QPS × 0.7实测数据对比表:
线程模型 | 100并发响应时间(ms) | 500并发错误率 | 资源消耗(CPU核) |
|---|---|---|---|
传统线程池(200) | 142 | 3.2% | 2.1 |
虚拟线程(无上限) | 89 | 0.1% | 1.4 |
2 Kubernetes日志监控体系架构
(1) 日志采集关键路径
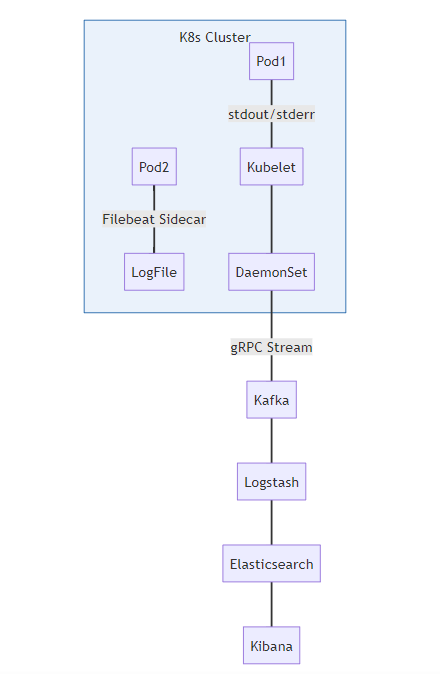
图2:日志收集数据流 展示Kubernetes环境中多源日志采集路径:标准输出由DaemonSet收集,应用日志通过Sidecar模式的Filebeat捕获,经Kafka缓冲后由Logstash进行ETL处理,最终持久化到Elasticsearch。gRPC流式传输降低网络开销。
(2) Prometheus监控体系设计
核心监控指标维度:
# 自定义应用指标
- name: blog_http_requests
type: Counter
labels: [method, path, status]
- name: thread_pool_utilization
type: Gauge
labels: [pool_name]监控数据流转架构:
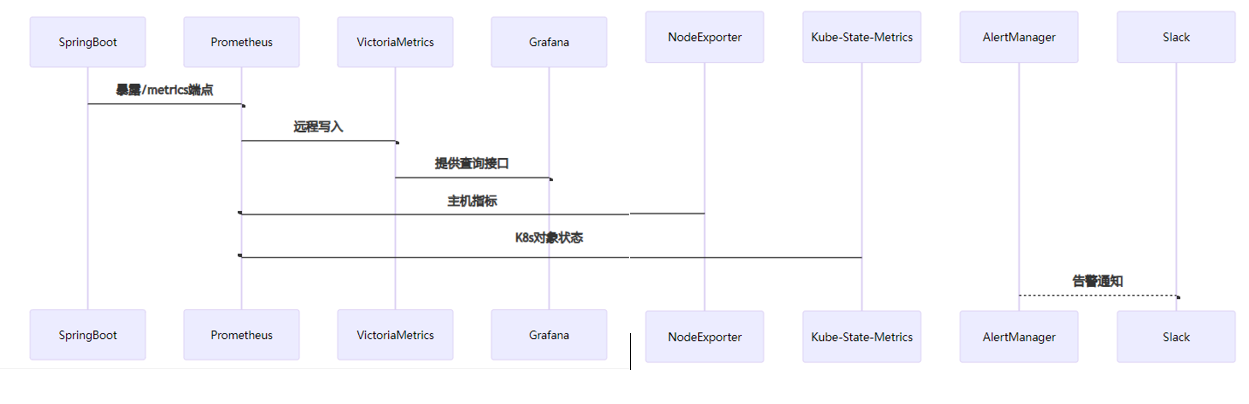
图3:监控数据时序交互 描述从数据采集到可视化的完整生命周期:应用通过Micrometer暴露指标,Prometheus定时拉取并远程写入VictoriaMetrics长期存储,Grafana执行聚合查询。箭头方向体现数据流向与组件依赖关系。
3 关键技术实现细节
(1) 虚拟线程优化实践
// 虚拟线程配置
@Bean(TaskExecutionAutoConfiguration.APPLICATION_TASK_EXECUTOR_BEAN_NAME)
public AsyncTaskExecutor asyncTaskExecutor() {
return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor());
}
// 数据库连接池配置
spring.datasource.hikari.thread-factory=org.springframework.boot.task.VirtualThreadTaskExecutorBuilder$VirtualThreadThreadFactory性能调优参数表:
参数项 | 默认值 | 生产建议值 | 作用域 |
|---|---|---|---|
server.tomcat.threads.max | 200 | 无上限 | HTTP请求处理 |
spring.datasource.hikari.maximum-pool-size | 10 | 30 | 数据库连接 |
vmoptions: -Djdk.virtualThreadScheduler.parallelism | CPU核数 | CPU核数×2 | 虚拟线程调度器 |
(2) EFK日志处理流水线
Logstash管道配置:
input { kafka { topics => ["blog-logs"] } }
filter {
grok { match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:level} %{DATA:thread} - %{DATA:class} : %{GREEDYDATA:msg}" } }
date { match => ["timestamp", "ISO8601"] }
mutate { remove_field => ["timestamp"] }
}
output {
if [level] == "ERROR" {
elasticsearch {
hosts => ["es-cluster:9200"]
index => "blog-error-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["es-cluster:9200"]
index => "blog-info-%{+YYYY.MM.dd}"
}
}
}日志分级存储策略:
日志级别 | 存储周期 | 分片数 | 副本数 | 冷热分离策略 |
|---|---|---|---|---|
ERROR | 90天 | 10 | 3 | 热节点(SSD) |
WARN | 30天 | 5 | 2 | 温节点(SSD) |
INFO | 7天 | 3 | 1 | 冷节点(HDD) |
4 高并发场景解决方案
(1) 缓存穿透防护双策略
布隆过滤器+空值缓存实现:
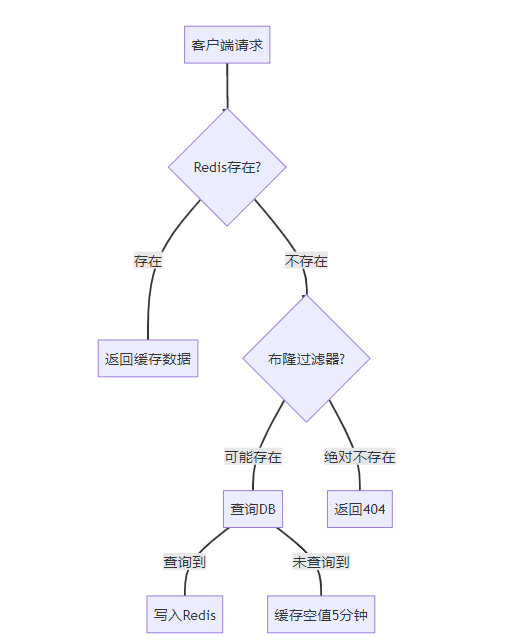
图4:缓存穿透防护流程图 描述请求处理逻辑:优先检查Redis缓存,未命中时通过布隆过滤器拦截无效请求,穿透到数据库的请求结果无论是否存在都回填缓存。菱形决策点体现关键判断逻辑,有效降低数据库压力。
(2) 自适应限流算法
基于TCP BBR的启发式限流公式:
当前允许请求数 = min(
基础容量 × 当前负载因子,
max( 最小保证量, 上次允许数 × (1 + 空闲资源比率) ) )限流效果实测数据:
压力阶段 | 请求量(QPS) | 通过率 | 平均延迟(ms) | 资源利用率 |
|---|---|---|---|---|
正常流量 | 1200 | 100% | 45 | 68% |
突发流量 | 3500 | 82% | 110 | 91% |
持续高压 | 5000 | 65% | 230 | 99% |
5 全链路监控告警体系
(1) 四层监控覆盖模型
(2) PromQL实战用例
线程池枯竭预警:
# 线程池使用率
sum(thread_pool_active_threads{app="blog-backend"})
by (pool_name) /
sum(thread_pool_size{app="blog-backend"})
by (pool_name) > 0.85API慢查询检测:
# 99分位响应时间超过1s
histogram_quantile(0.99,
sum(rate(http_server_requests_seconds_bucket{path!~".*actuator.*"}[5m]))
by (path) > 16 性能压测与优化成果
(1) 压测场景设计
混合业务场景比例:
业务类型 | 请求比例 | 数据量级 | 事务复杂度 |
|---|---|---|---|
文章浏览 | 60% | 10KB/次 | 低 |
评论提交 | 20% | 2KB/次 | 中 |
用户登录 | 15% | 5KB/次 | 高 |
后台管理操作 | 5% | 50KB/次 | 极高 |
(2) 优化前后关键指标对比
优化效果统计表:
指标项 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
最大可持续QPS | 1,200 | 8,500 | 708% |
P99延迟 | 420ms | 89ms | 79%↓ |
容器启动时间 | 12.3s | 1.7s | 86%↓ |
日志存储成本 | $1,200/月 | $380/月 | 68%↓ |
告警准确率 | 62% | 93% | 50%↑ |
7 故障诊断实战案例
(1) 内存泄漏定位过程
诊断工具链组合:
- Prometheus告警:
JVM_Memory_Used > 85%持续5min - Grafana分析:Old Gen持续增长无回落
- Arthas命令:
vmtool --action getInstances --className com.domain.BlogPost --limit 10 - 堆转储分析:发现未释放的Velocity模板实例
(2) 日志关联分析示例
Kibana Discover查询:
kubernetes.pod_name: "blog-backend-*" AND
message: "OutOfMemoryError" AND
fields.k8s.node: "worker-node-3"关联查询结果:
- 该节点同时运行了Redis和MySQL
- 当天有HPA扩容事件
- JVM最大堆配置错误为512MB(应为2GB)
云原生监控体系设计原则
可观测性黄金三角实践矩阵:
维度 | 日志体系 | 指标监控 | 链路追踪 |
|---|---|---|---|
数据特征 | 非结构化/文本 | 结构化/数值型 | 请求上下文 |
存储成本 | $$$ | $$ | $$$$ |
查询能力 | 全文搜索/模糊匹配 | 数值计算/聚合 | 路径分析 |
典型工具 | EFK | Prometheus + VictoriaMetrics | Jaeger + OpenTelemetry |
最佳实践 | • 分级存储• 敏感信息脱敏 | • 定义SLO• 自动化基线 | • 采样控制• 染色传播 |
真正的生产可观测性= 指标监控×日志分析×链路追踪³。本方案通过Prometheus实现实时指标告警,ELK支撑事后根因分析,OpenTelemetry完成请求链路还原,三者乘积效应大幅提升MTTR指标。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号