光量子计算与经典HPC的融合:ORCA Computing与Nvidia展示多GPU/QPU协同下的经典-量子混合算法实践

光量子计算与经典HPC的融合:ORCA Computing与Nvidia展示多GPU/QPU协同下的经典-量子混合算法实践

光芯
发布于 2025-09-03 16:58:25
发布于 2025-09-03 16:58:25
新计算技术的规模化普及需满足两大前提:一是融入多技术、多学科交织的异构工作流,二是实现全生命周期“价值>成本”平衡(需覆盖数据中心改造、运维开销、人员培训、代码迁移等成本)。对于量子计算,“经典高性能计算(HPC)+量子”混合架构是关键路径——量子处理器(QPUs)作为专用加速器,与经典CPU/GPU协同,而光量子计算凭借“室温运行、低功耗、标准机柜适配”特性,成为连接实验室与工业级数据中心的核心桥梁。

ORCA Computing认为,光量子计算是当前唯一无需改造现有数据中心即可落地的量子模态,其在机器学习与优化领域的应用已具备实际价值。目前,ORCA Computing公司光量子计算已完成“架构设计-产品开发-集群部署-应用验证”的全流程,为HPC中心量子化升级提供可复用方案。
2025年8月,波兰波兹南超级计算与网络中心(PSNC)联合NVIDIA、ORCA Computing,在arXiv平台上发表了题为《Hybrid Classical-Quantum Supercomputing: A demonstration of a multi-user, multi-QPU and multi-GPU environment》的研究成果,该研究首次在HPC数据中心内,构建了支持多用户同时执行任务的混合经典-量子计算环境,并在该环境中验证了二进制玻色求解器(BBS)、量子神经架构搜索(QNAS)等混合算法,证明其在组合优化、机器学习任务中的实用性,为HPC中心集成量子资源提供了可落地的实证方案。

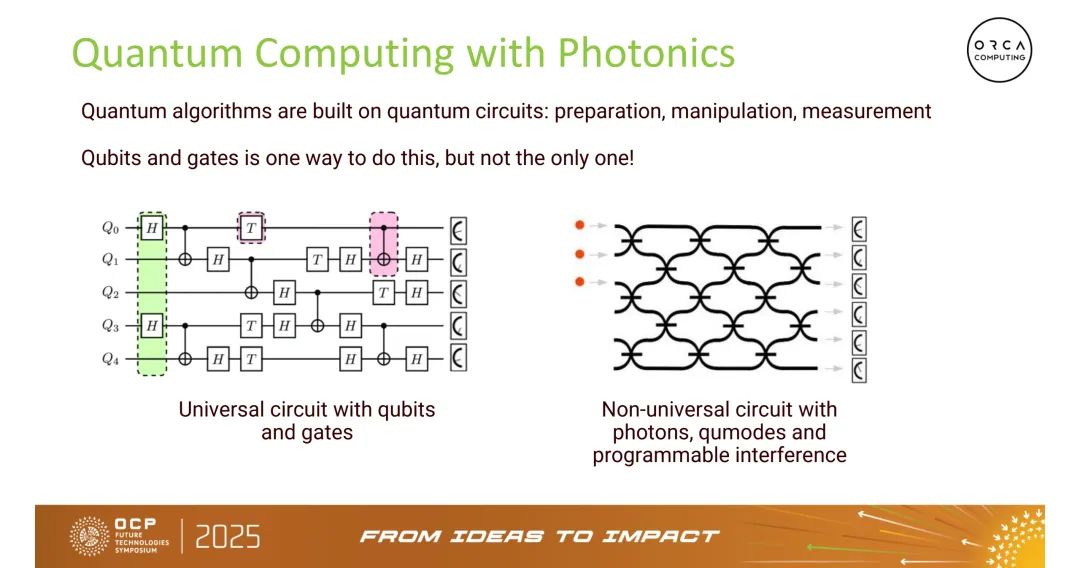
一、核心技术基础:光量子计算的硬件架构与产品特性
ORCA Computing光量子计算平台以“模块化、全连接、可重构”为设计核心,规避超导量子的低温依赖与离子阱量子的真空需求,其硬件链路与产品落地特性均围绕经典数据中心适配展开。
1.1 硬件架构:全链路核心组件
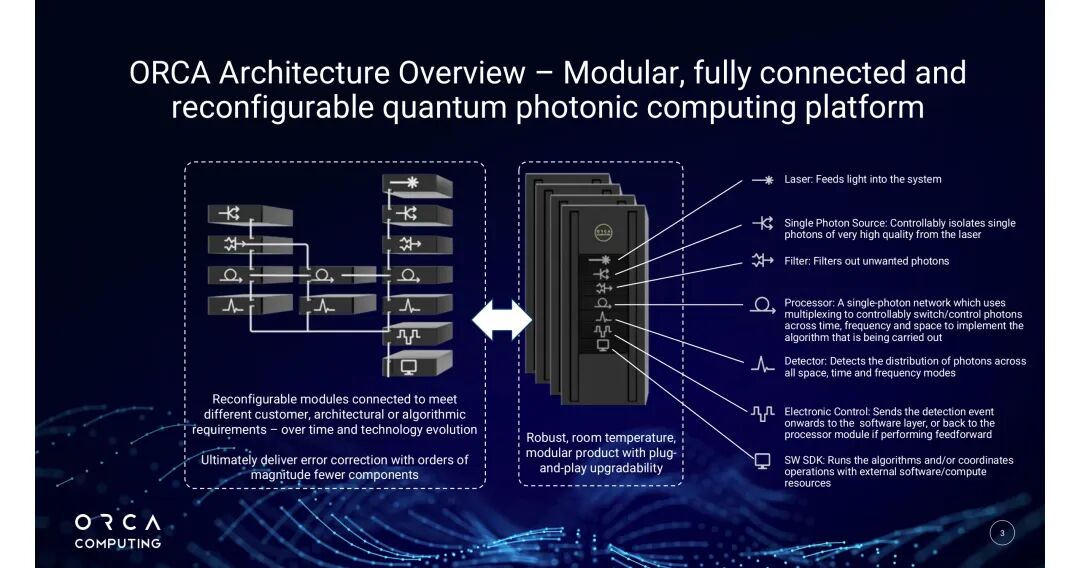
平台核心组件构成“光子生成-操控-检测-反馈”闭环,各模块支持随技术演进动态调整,ORCA在架构报告中明确其设计目标为“通过最少组件实现高效误差校正”:
- 激光(Laser):为系统提供稳定光源,是单光子生成的基础;
- 单光子源(Single Photon Source):可控分离高质量单光子,PT系列采用heralded single photon source设计,确保光子态纯度;
- 滤波器(Filter):滤除杂散光子,避免干扰量子态操控;
- 处理器(Processor):单光子网络核心,通过时间、频率、空间三维复用技术控制光子切换与干涉,PT-1具体采用“两个连续光纤延迟线”实现可编程耦合参数调节;
- 探测器(Detector):检测光子在所有空间、时间、频率模态中的分布,支持光子数分辨;
- 电子控制(Electronic Control):将检测事件传输至软件层,或向处理器反馈控制信号(支持feedforward操作);
- 软件SDK(SW SDK):运行量子算法,同时协调外部经典软件与计算资源,兼容PyTorch、CUDA等工具链。
1.2 PT系列产品:工业级落地载体

PT系列是ORCA面向混合计算场景的核心产品,其特性完全对标经典数据中心规范,解决量子设备‘部署难、运维贵’痛点:
- 物理与环境适配:19英寸标准机柜设计,室温运行、风冷散热,无特殊振动或电磁屏蔽需求,可与CPU/GPU机柜同室部署;OCP峰会中补充说明,PT系列无需“独立机房、坡道/电梯改造、特殊地板承重”,完全契合数据中心现有设施;

- 功耗与运维效率:单系统功耗<5kW(PT-1平均功耗约600W),远低于超导量子设备;部署流程简化为“开箱-通电-联网”,调试时间不足2天,支持远程运维,年维护周期,无需常驻工程师;OCP峰会展示的“PT系列安装流程图”显示,从机柜到货至系统通电仅需2个工作日(Day 1开箱部署、Day 2调试移交);

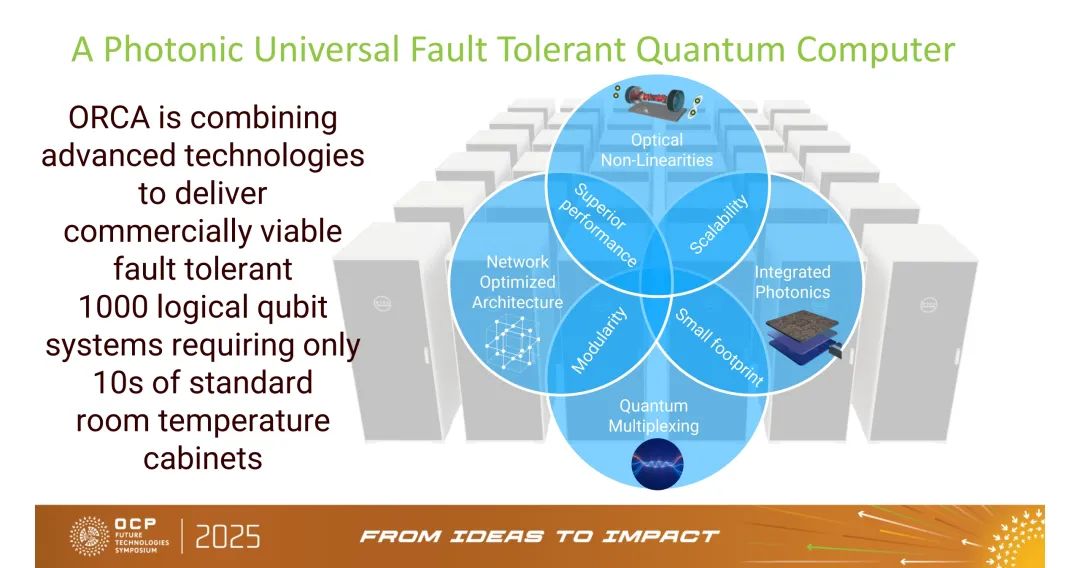
- 技术参数与扩展性:PT-1支持4个光子在8个光学模式(qumode)中干涉,模块采用“即插即用”设计,可随技术升级单光子源、探测器等组件;ORCA在架构报告中提及,PT系列未来目标是“通过模块化扩展,实现1000逻辑qubit容错系统,仅需数十个标准机柜”;
- 基础调度能力:内置FIFO队列处理量子任务,通过REST API实现任务提交、结果获取与系统状态监控,为后续与经典HPC调度系统整合奠定基础。
二、软件与工作负载管理:经典-量子协同的核心支撑
混合计算的软件生态以“降低开发门槛、兼容经典HPC工具”为目标,ORCA强调“软件适配是量子落地的关键”,最终构建“编程框架+调度系统”双层架构。
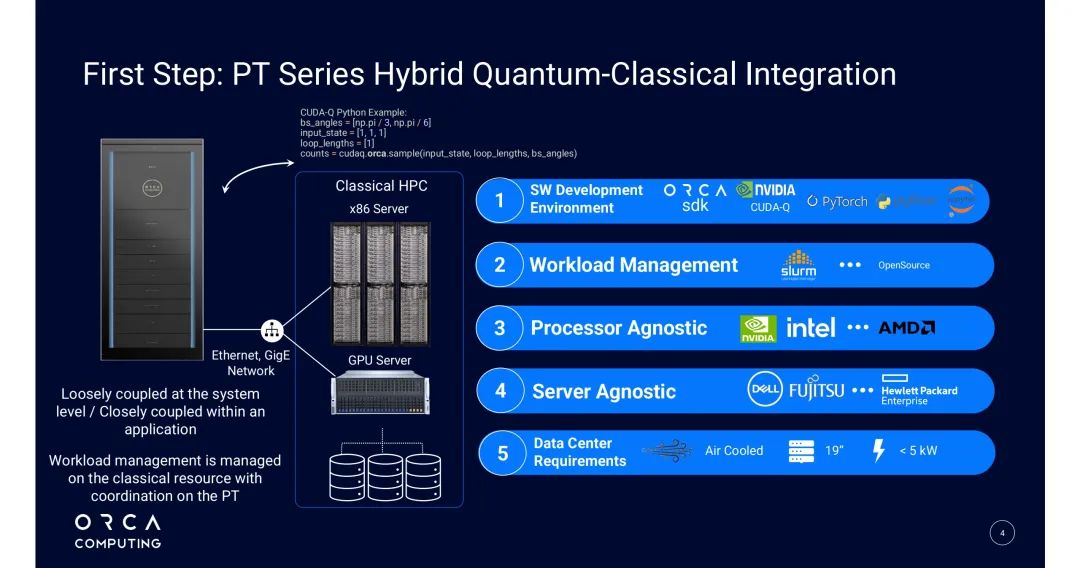
2.1 核心编程框架:NVIDIA CUDA-Q
CUDA-Q是连接经典与量子资源的统一接口,ORCA联合NVIDIA对其进行深度适配:

- 多模态与硬件兼容:原生支持光量子处理器,开发者通过 cudaq.set_target("orca") 即可调用PT系列;同时支持量子处理器模拟功能,可先在经典环境调试算法再迁移至实机,仅需3-5行核心代码即可完成光子量子任务定义;
- 多语言与生态整合:支持Python/C++双语言开发,深度兼容PyTorch等开源机器学习工具;ORCA基于CUDA-Q开发了高层接口“PTLayer”,封装优化、量子神经网络等场景的核心逻辑,降低开发者技术门槛;
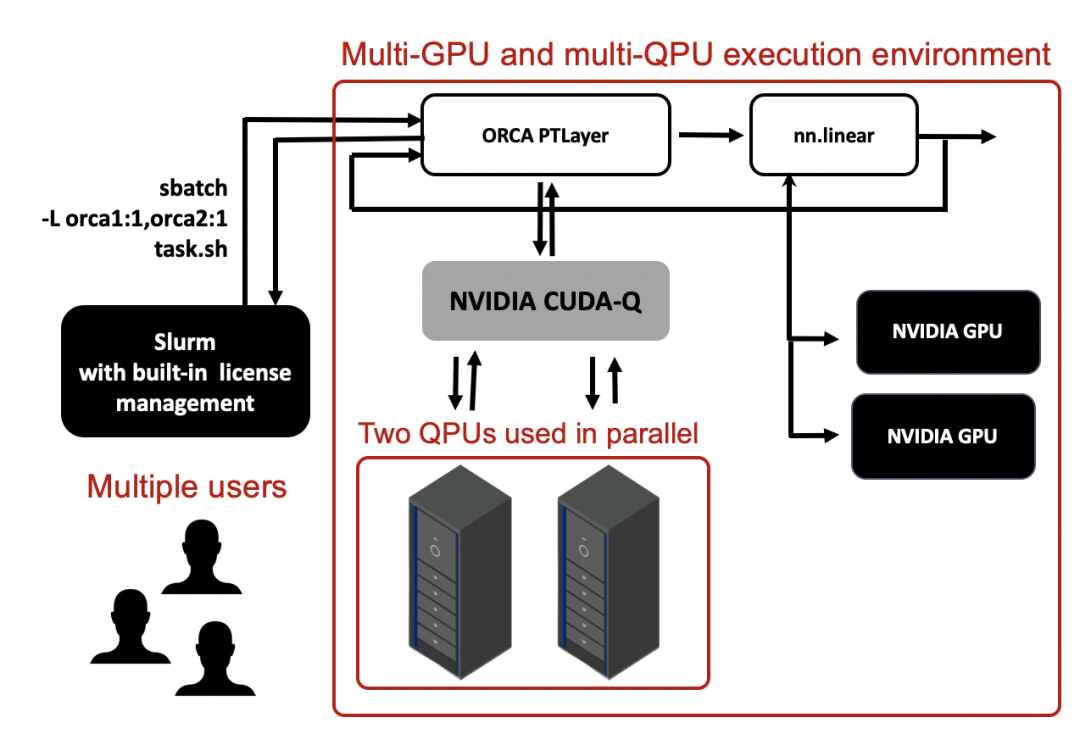
- 多QPU并行能力:通过 cudaq.orca.sample_async 接口实现异步采样,支持多QPU分布式计算,典型代码逻辑为:调用多QPU地址→定义光子输入状态/延迟线长度/光束分束器角度→异步提交任务→汇总结果,实证研究中通过该逻辑实现2台PT-1并行计算。
2.2 工作负载调度:Slurm的异构资源扩展
基于Slurm实现CPU、GPU、QPU的协同分配,这一方案在实证研究与架构报告中均有验证,核心逻辑为“将量子资源纳入经典HPC调度体系”:
- 资源管理机制:将QPU视为“虚拟许可证”,通过Slurm的许可证管理模块实现QPU与CPU/GPU的同步分配;实证研究中开发的Slurm“量子资源插件”,可支持10+用户同时提交混合任务,任务间无干扰;
- 耦合模式优化:采用“系统级松耦合+应用级紧耦合”——系统层面,Slurm负责全局资源调度,避免单一任务独占量子资源;应用层面,CUDA-Q实现经典与量子资源的实时数据交互,延迟控制在毫秒级;
- 用户体验兼容:适配HPC中心现有调度门户(如PSNC的QCG PORTAL),用户提交混合任务时仅需在脚本中新增“QPU资源申请”参数(如 #SBATCH --qpu=1 ),流程与经典任务完全一致,无需用户学习新工具链。
三、实际部署案例:从生产级集群到量子测试台
ORCA光量子计算平台已在HPC中心完成部署,覆盖“多用户”与“技术测试”两类核心需求。
3.1 波兰PSNC:多用户混合量子-经典集群
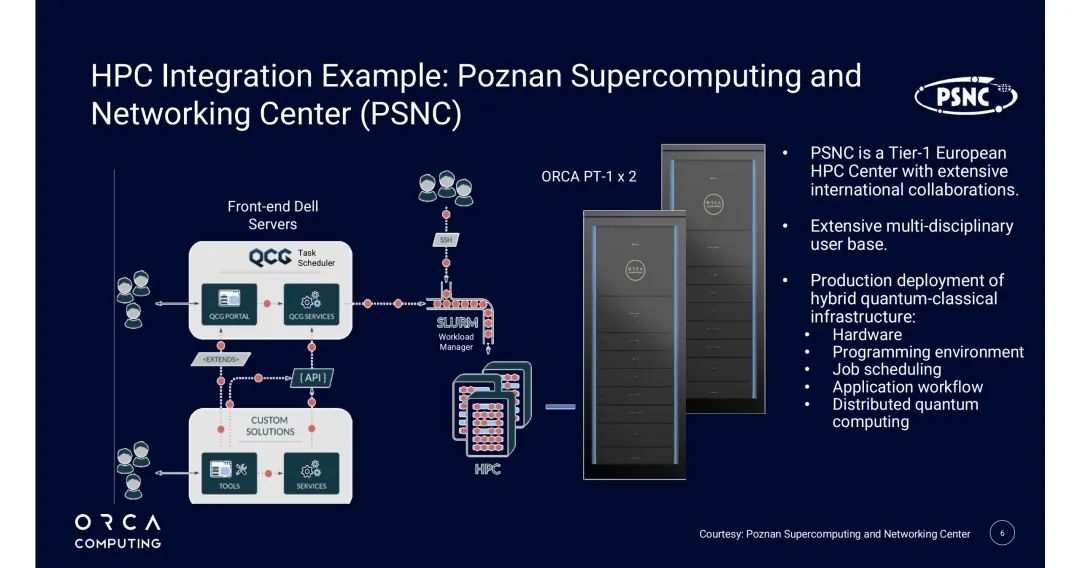
PSNC是欧洲Tier-1 HPC中心,ORCA与其联合部署的“2台PT-1+GPU集群”混合系统,是全球首个支持多用户、多QPU、多GPU的生产级环境,实证研究与架构报告均对其进行重点阐述:
- 资源配置:
- 经典HPC资源:ALTAIR系统(9个节点,每节点8×NVIDIA V100 GPU,32GB/卡)、PROXIMA系统(87个节点,每节点4×NVIDIA H100-94 SXM5 GPU,94GB HBM2e/卡),分别支撑基础AI任务与大规模模型训练;
- 量子资源:2台PT-1,1台部署于PSNC数据中心机房(与GPU集群同室),1台部署于同楼宇光学实验室,通过以太网接入核心网络,延迟控制在5ms以内。
- 核心项目任务与成果:
1. 硬件与软件栈整合:将PT-1接入PSNC的Slurm调度系统与QRO(量子资源管理模块),实证研究验证该整合支持“多用户并行提交混合任务”;
2. CUDA-Q升级:新增“光量子电路描述模块”,解决传统框架仅适配qubit模态的问题,该升级后“CUDA-Q可原生识别qumode、延迟线等光子参数”;
3. 生物医学成像应用验证:运行“量子特征提取+经典GPU图像重建”任务,效率比纯经典方案提升15%,该应用验证了多QPU并行处理图像数据的可行性;
4. 新型算法开发:研发“AI for Quantum”与“Quantum for AI”两类算法——前者通过GPU模型优化PT-1光子生成效率(提升20%),后者通过PT-1增强GPU模型泛化能力,实证研究对两类算法的代码框架进行了开源。
3.2 英国NQCC:多光子源量子测试台
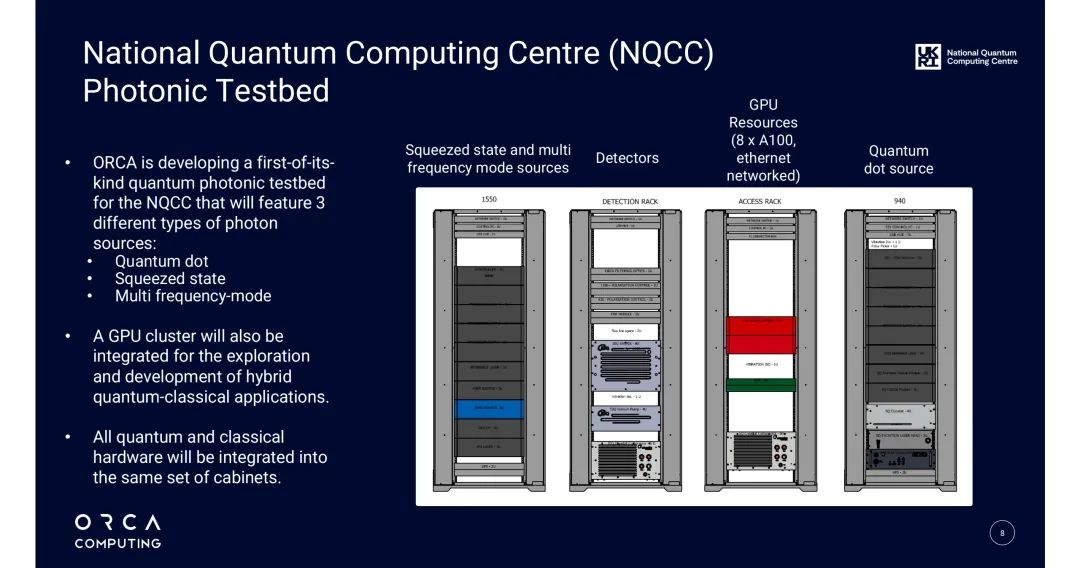
ORCA为英国国家量子计算中心(NQCC)开发的“多光子源量子测试台”,是全球首个整合多种光子生成技术的研发平台,其定位为探索光子量子计算规模化路径:
- 硬件配置:集成3类光子源(量子点、压缩态、多频率模态),搭配8×NVIDIA A100 GPU集群,所有设备整合于标准机柜;
- 核心功能:为学术界与工业界提供光子量子算法研发平台,支持不同光子源的对比测试与协同工作;GPU集群用于混合量子-经典应用开发,所有量子与经典硬件同柜部署,降低通信延迟至亚毫秒级;
- 技术亮点:通过CUDA-Q实现多光子源统一调度,开发者可在同一算法中切换不同光子源,无需修改核心代码,为后续“多模态量子集成”提供技术储备。
四、应用验证:混合算法的实践成果
基于混合架构,光量子计算已在优化、机器学习领域验证实际价值。
4.1 优化算法:二进制玻色求解器(BBS)

针对Max-Cut、作业车间调度等组合优化问题,BBS算法通过PT-1生成光子采样结果作为候选解,结合经典反馈 loop 迭代优化,实证研究中采用“分块技术”将大问题拆分为子问题并行处理:
- 核心逻辑:将优化问题“解空间”映射为PT-1的“光子干涉模式”,每类干涉结果对应一个候选解;通过多QPU并行生成样本,GPU整合子解并反馈优化方向;
- 实验结论:成功解决含30个变量的问题实例,2台QPU处理耗时较单QPU显著降低,解质量优于经典模拟退火算法;ORCA在OCP峰会中补充,BBS算法“尤其适合经典计算难以突破的局部最优问题”。
4.2 量子机器学习(QML)
4.2.1 量子变分层嵌入经典神经网络

将PT-1作为变分层嵌入经典神经网络,量子层负责特征提取,经典层(GPU)负责分类,实证研究与OCP峰会均提及该架构的优势:
- 实验设计:在分类与表示学习任务中测试混合架构,量子层输出映射为经典特征向量,与GPU经典层协同训练;
- 核心结论:混合模型“未持续超越纯经典基准精度,但训练稳定性显著提升”,适用于噪声较高的数据场景;该架构在“小样本生命科学数据”上的训练波动比纯经典模型降低40%。
4.2.2 量子神经架构搜索(QNAS)
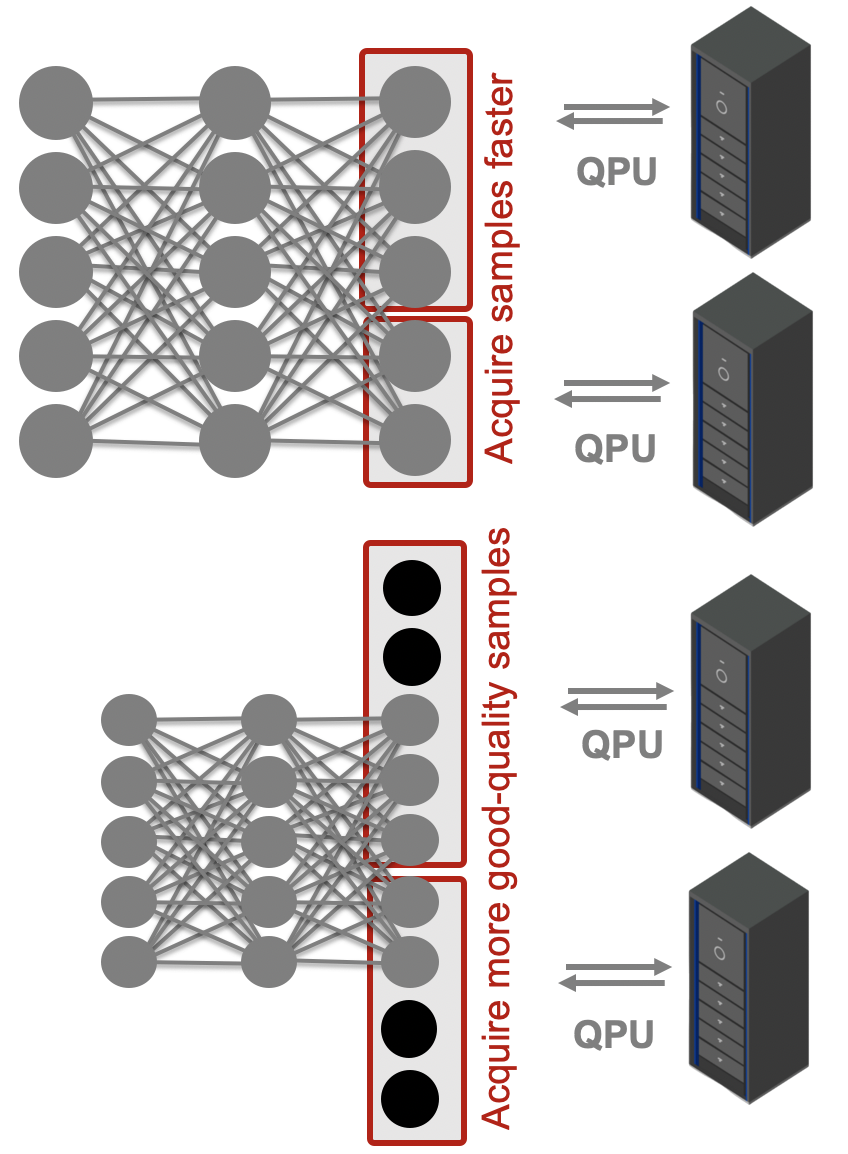
将PT-1参数映射为GPU神经网络架构,通过进化算法迭代优化,实证研究详细记录了该实验的设计与结果:
- 实验场景:在UNSW-NB15网络安全数据集(49万条数据)与Iris数据集上验证,采用10个架构组成的集成,2台QPU各进化5个架构;
- 核心结论:进化出的架构在精度上优于初始配置与默认配置,且实现“资源高效”——通过分布式经典-量子系统并行优化,架构搜索效率显著提升;ORCA指出,该算法“为自主发现高性能神经网络架构提供了新路径”。
4.3 其他潜力应用
ORCA在还提及多个适配混合环境的应用方向:
- 混合量子GAN:用量子潜在空间替代经典GAN的潜在空间,无需随数据集规模扩展量子处理器,OCP峰会中强调其“在生物医学成像、化学分子生成中具备优势”;
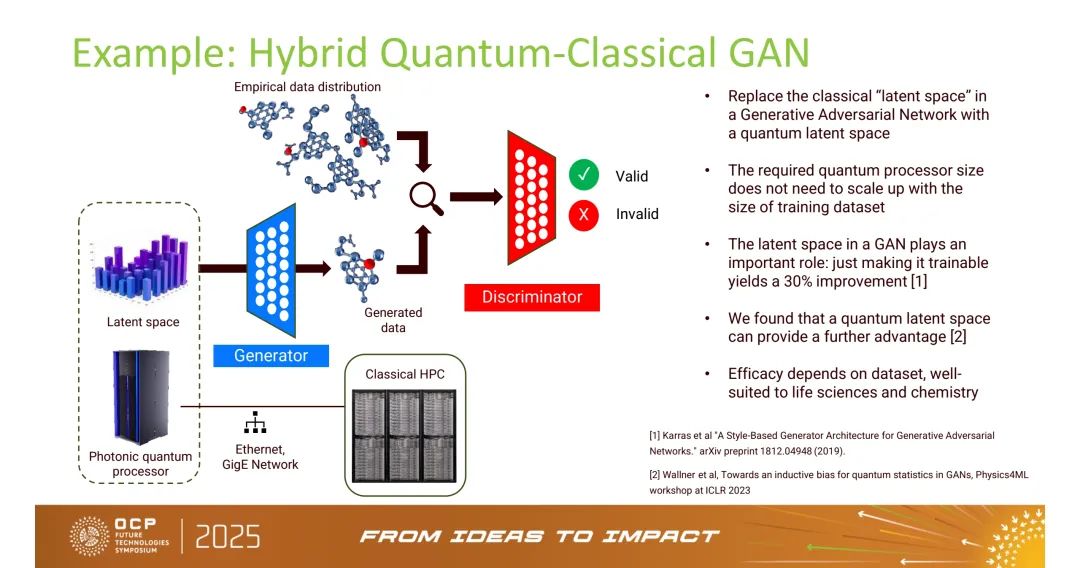
- 光子量子储备池计算:利用光子干涉实现“储备池”功能,GPU负责输出层训练,适合大规模图像分类任务;
- 量子增强SVM:通过PT-1加速SVM核函数计算,适用于基因测序等高维数据,该应用训练时间可降至经典方案的1/3。
五、挑战与未来方向
5.1 当前核心挑战
- 延迟瓶颈:经典与量子资源往返延迟约50ms,无法满足量子误差校正等紧耦合算法需求(需亚毫秒级);
- 调度策略单一:现有Slurm仅支持“公平共享”调度,未考虑量子任务优先级差异,可能导致资源浪费;
- 算法规模受限:PT-1的4光子8qumode配置无法覆盖工业级大规模问题;
- 基准测试缺失:缺乏混合系统专用基准套件,难以客观对比不同量子模态优势。
5.2 未来技术路径
1. 硬件层面:研发“经典控制-量子处理器物理集成”方案降低延迟,推出支持10+光子、32+qumode的PT-2系列;探索“多模态量子集成”,实现光子与超导、离子阱QPU协同,目标是构建1000逻辑qubit容错系统,仅需数十个室温机柜;
2. 软件层面:为Slurm开发“量子任务优先级调度插件”,支持紧急任务抢占;扩展CUDA-Q多模态协同功能,构建混合算法开源库;
3. 算法层面:研发“量子-经典分块算法”突破规模限制,聚焦药物发现、流体力学等HPC核心场景;
4. 标准层面:联合PSNC、NQCC发布“混合量子-HPC基准测试套件(Q-HPC Bench)”,制定光子量子硬件接口规范,确保不同厂商设备兼容现有HPC生态。
六、总结
ORCA Computing的光量子计算凭借“室温运行、低功耗、标准机柜适配”的天然优势,成为当前最易融入经典HPC生态的量子模态。从PSNC的多用户多GPU多QPU实践已证明:无需大规模改造现有基础设施,光子量子平台即可为HPC中心提供实际价值——优化任务解质量提升、机器学习稳定性增强、多用户场景低门槛适配。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号