腾讯技术面:聊聊Go语言最强ORM框架GORM

腾讯技术面:聊聊Go语言最强ORM框架GORM

腾讯云开发者
发布于 2025-09-03 20:03:35
发布于 2025-09-03 20:03:35
gorm库是go语言中一个非常强大的ORM(对象关系映射)库,它能够帮助我们很好的操作数据库和映射数据库表为go对象。在技术面试中,gorm的使用与设计理念也常作为面试题出现。这篇文章将介绍gorm库的相关概念、整体结构、内部逻辑,带你全方位掌握gorm库。此外,文章还会列出在使用gorm库时容易踩的坑、实用小技巧以及一些小知识。最后要提醒一下,本文不会过多介绍gorm的使用,更多的会注重gorm的内部逻辑。建议没有使用过gorm的大佬先收藏,等使用一段时间gorm后再回看,效果更佳。
01、gorm概述
1.1 ORM(对象关系映射)
ORM是一种编程技术,针对各类语言,ORM框架可以将数据库表和代码中的类(结构体)建立映射,从而支持开发者通过操作对象完成对数据库的CURD。如下图所示,ORM框架实际上就是编程对象和数据库记录之间相互转换的一个中间工具。
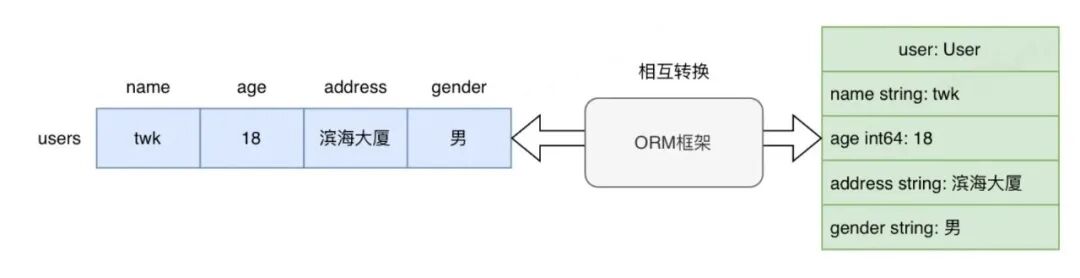
ORM的三大核心思想
- 数据库表和类(结构体)映射。
- 表中列字段和类(结构体)属性映射。
- 对象操作转换为SQL语句。
三大核心思想实际就是对应了数据库的三个核心模块:表结构、列结构、SQL
ORM框架的优点
- 避免手写SQL语句,提高开发效率。
- 规避了手写SQL语句容易出错的问题。
- 支持多种数据库,代码具有移植性。
ORM框架的缺点
- ORM框架自动生成的SQL语句不如手写SQL高效。
- 存在学习成本,需要开发者了解对应ORM框架的使用规则。
在了解ORM的思想和优缺点后就能明白为什么现在ORM框架如此流行,相比其优点,缺点可以说是鸡蛋里面挑骨头了。目前各个语言都有自己比较流行的ORM框架,Java有Mybatis工具、Python有Django ORM,Golang则对应本文的主角Gorm。
1.2 gorm代码架构
gorm库也是ORM框架的实现之一,目前支持多种数据库,包括MySQL、PostgreSQL、SQLite等。实际上gorm库可以视为一个帮助我们写SQL的工具,gorm库内部会把方法调用链转换为SQL语句。gorm库实现帮助我们写SQL语句的功能,它至需要完成这些功能:
- 建立并维护服务与数据库的连接。
- go结构体和数据库表的映射转换。
- SQL和方法调用之间的映射转换。
- 发送SQL语句并解析返回结果。
要完成的这些功能一定程度上也决定了gorm库代码架构的设计,gorm库代码架构如下图。
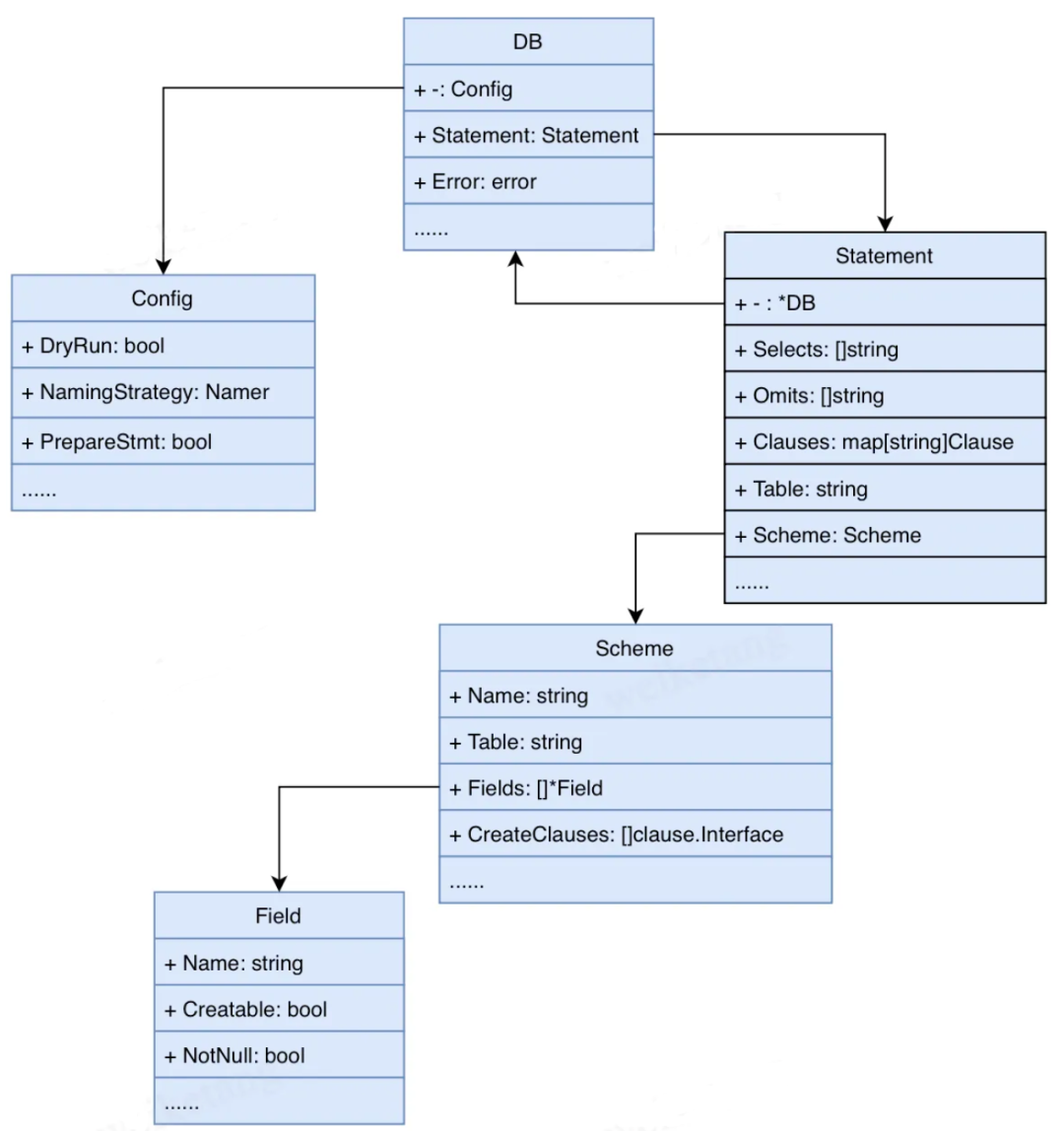
gorm将服务与数据库的连接实例化为了一个DB对象。其中,数据库配置被映射为Config对象存储在DB对象中。配置包括:DryRun(试运行)、NamingStrategy(命名策略)、PrepareStmt(预编译语句)。
至于SQL语句,gorm库将SQL语句映射为Statement结构体。其中,当调用Select、Omit等方法时gorm会将选中、忽略的属性列存储在Statement对象的Selects、Omits属性中。同时将Where方法调用中的条件映射为Clause对象存储在Clauses属性中。对于表名这些配置也有对应的成员属性存储,Statement结构体的设计几乎能够完成所有SQL语句的映射转换。
Statement对象光存储SQL语句还不够,它还需要理解对象和记录的映射关系,从而才能构造完整的SQL语句和解析数据库返回的结果。因此,Statement对象内部提供了Scheme结构体来建立记录和对象之间的映射。 gorm库可以解析不同类型的go对象,并统一转换为Scheme对象存储。Scheme对象存储了表名称、列信息等表结构信息,其中列信息在gorm库中对应Field结构体。Field结构体会保存该列的Name、Type、Not Null、Primary Key等信息。
总而言之,gorm库实际上就是将SQL的所有语法规则代码化了,gorm库方法的调用过程就是写SQL的过程。 gorm库中结构体和数据库的映射关系如下:
- DB对象:服务和数据库的连接,负责连接的建立、维护、关闭。
- Config对象:用户的配置信息,管理用户自定义的配置信息。
- Statement对象:映射SQL语句,将gorm库中方法调用转换为SQL语句。
- Scheme对象:映射数据表,是go对象和数据表相互转换的中介。
- Field对象:映射列信息,是go对象属性和数据列信息之间相互转换的中介。
gorm库中的方法大致可以分为两类:过程方法和结尾方法。顾名思义方法调用链中间的方法都是过程方法,方法调用链路最后的方法则是结尾方法。过程方法一般只有构建Statement对象的功能,也就是写SQL的功能,常见的过程方法有Where、Select、Omit、Model等。
而结尾方法不仅会构建完整Statement对象,还会将其转换为SQL语句并发送到数据库执行并接受数据库处理响应,最终还会解析响应。常用的结尾方法有Update、Find、Delete、Create等,实际上也就是CURD功能。
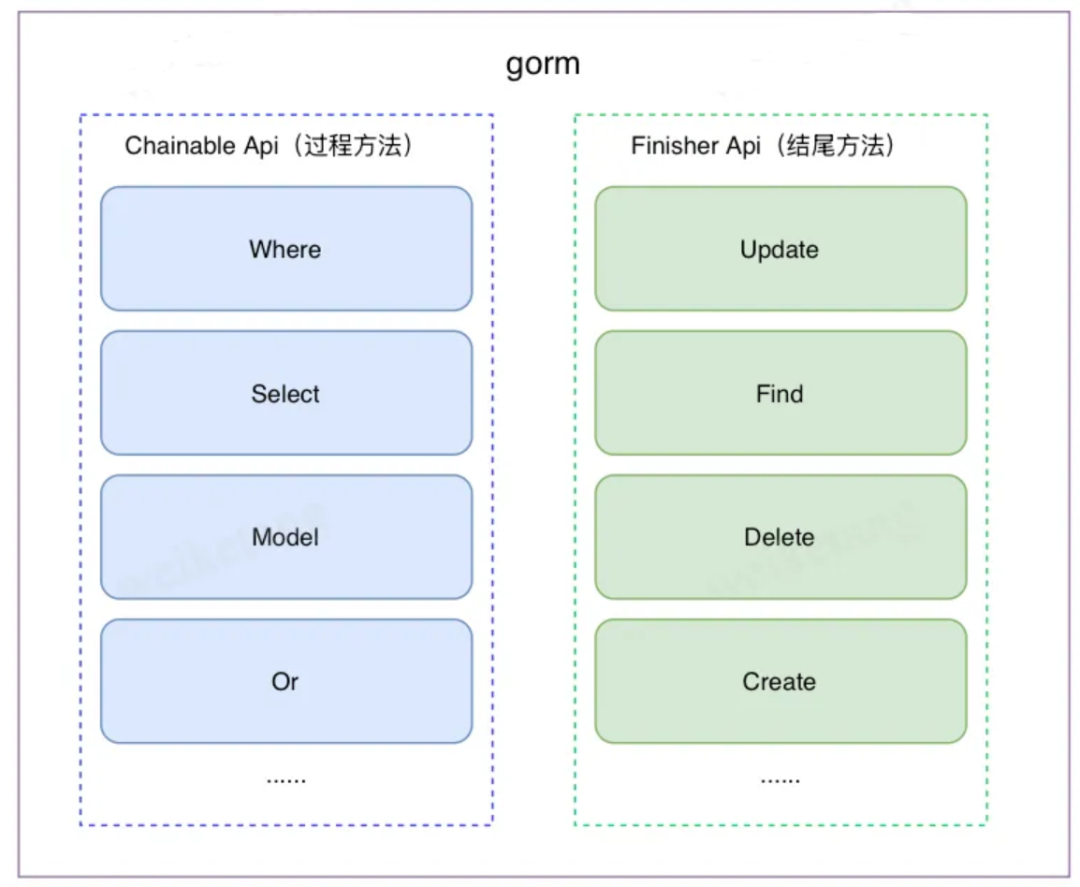
1.3 trpc-go/gorm和gorm的关系
公司的 trpc-go/trpc-database/gorm 包(下面简称trpc-go/gorm)也开放了gorm库接入trpc-go框架的能力。trpc-go/gorm包并不是重新实现了gorm库,其只是对gorm库的进一步封装。trpc-go/gorm包有以下功能:
- 进一步封装了gorm库的使用,使得建立数据库连接更便捷。
- 将基于gorm库的数据库连接集成到trpc-go服务,允许开发者使用trpc框架配置配置相关设置。
- 提供了北极星动态寻址能力,使得服务切换数据库时更加便捷。
02、一条SQL语句的执行
像下面这种使用gorm库执行CURD操作的代码在平时的工作中比比皆是,但是这一连串方法调用链背后的逻辑于我来说是一知半解的。秉持着了解工具才能更好的使用工具的想法,下面会探究一下代码的内部逻辑。
var user User
db := db.Model(user).Select("age", "name").Where("age = ?", 18).Or("name = ?", "tencent").Find(&user)
if err := db.Error; err != nil {
log.Printf("Find fail, err: %v", err)
}gorm执行语句全过程:
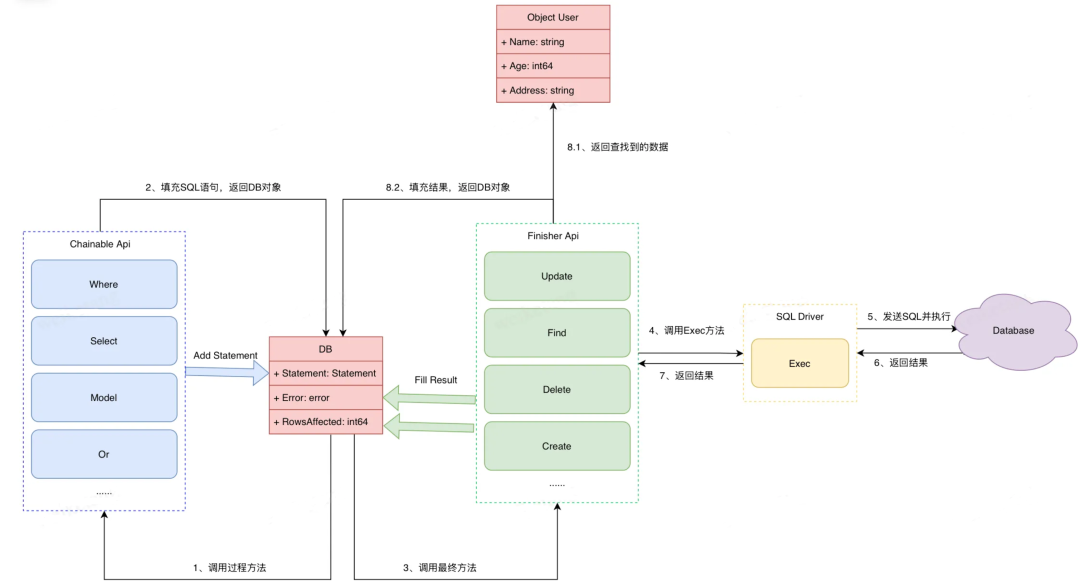
前置工作:调用Open方法根据传入配置、不同类型的数据库驱动创建DB对象并初始化。
1、调用DB对象的过程方法,使用Select选择要返回的属性字段age和name、使用Where + Or指定查询条件"age = 18 OR name = 'tencent'"。
2、过程方法会填充DB.Statement属性,并将DB对象返回。可以看到Select方法实际上是将入参添加到Statement.Selects属性中,Where方法则是解析查询条件并添加到Statement.Clauses属性中。
func (db *DB) Select(query interface{}, args ...interface{}) (tx *DB) {
tx := db.getInstance()
switch v.(type){
case string:
for _, arg := range args {
switch arg = arg.(type) {
case string:
tx.Statement.Selects = append(tx.Statement.Selects, arg)
case []string:
tx.Statement.Selects = append(tx.Statement.Selects, arg...)
case default:
...
}
}
case default:
// 略
}
}
func (db *DB) Where(query interface{}, args ...interface{}) (tx *DB) {
tx = db.getInstance()
// 解析查询条件并将查询条件添加到Statement.Clauses中
if conds := tx.Statement.BuildCondition(query, args...); len(conds) > 0 {
tx.Statement.AddClause(clause.Where{Exprs: conds})
}
return
}3、调用DB对象的最终方法Find方法,查询符合条件的记录。
4、最终Find方法在完成SQL语句的组装工作后会调用底层数据库驱动的Exec方法。
5、Exec方法会将SQL语句发送到指定DSN的数据库中。
6、数据库会执行SQL语句,并将结果返回。
7、同上返回结果
8-1、解析返回的结果,将对应字段填充到目标对象user对应属性中。
8-2、将影响行数、错误填充到DB对象中并返回DB对象。
3-8步操作基本上都是在Find结尾方法中完成的,下列给出压缩过后的Find函数代码。
(db *DB) Find(dest interface{}, conds ...interface{}) (tx *DB){
tx = db.getInstance()
if len(conds) > 0 {
// 解析Find方法自带的条件
if exprs := tx.Statement.BuildCondition(conds[0], conds[1:]...); len(exprs) > 0 {
tx.Statement.AddClause(clause.Where{Exprs: exprs})
}
}
tx.Statement.Dest = dest
// 构建SQL语句
BuildQuerySQL(tx)
// 若设置DryRun为true,则只输出SQL语句不执行
if tx.DryRun || tx.Error != nil {return}
// 将SQL语句发送到对应数据库执行并接收返回结果
rows, err := tx.Statement.ConnPool.QueryContext(tx.Statement.Context, tx.Statement.SQL.String(), db.Statement.Vars...)
if err != nil {
db.AddError(err)
return
}
// 解析结果并封装到tx.Statement.Dest中
gorm.Scan(rows, tx, 0)
if db.Statement.Result != nil {
db.Statement.Result.RowsAffected = db.RowsAffected
}
}03、gorm库用法查漏补缺
该部分介绍一些我觉得gorm库比较好用的功能和一些gorm库小知识。
3.1 模型定义
1、小知识:默认情况下gorm库会以什么样的规则将结构体映射到某一张表?
结构体名称转换为表名称通常使用蛇形命名法转换,此外gorm库还会自动将名称设置为复数。当然,对于那些单复数相同的名词gorm是区分不出来的。如:Good->goods,gorm转复数只会无脑加s。那有什么办法可以让gorm只使用蛇形命名法而不加复数吗?有的兄弟,有的。如下代码,只要我们在创建数据库连接时进行配置,即可关闭gorm的复数表名功能:
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
NamingStrategy: schema.NamingStrategy{
SingularTable: true, // 关闭复数表名
},
})2、小知识:gorm库中提供了一个结构体Model,其作用是什么?
Model结构体包含了四个比较常用的字段ID、CreateAt、UpdateAt和DeleteAt。为了提供便利,gorm库定义了Model结构体,当我们需要使用这些字段时,直接将Model结构体嵌入表对应的结构体中即可。此外,当Model中的DeleteAt嵌入结构体后会自动开启软删除功能,当我们删除一条记录时将执行逻辑删除,即只设置DeleteAt属性的时间,而不执行物理删除。
type Model struct {
ID uint `gorm:"primarykey"`
CreatedAt time.Time
UpdatedAt time.Time
DeletedAt DeletedAt `gorm:"index"`
}3、功能:对于一些包含属性比较多的结构体,如果将属性平铺结构体会很长。此时若部分属性之间具有数据泥团的特征,则可以封装为当前结构体的内嵌结构体,并使用gorm的embed标签标识。使用embed后的结构体和平铺属性的结构体是等价的。此外,embed内嵌的结构体还能使用embeddedPrefix标签统一指定部分属性的前缀。如下列代码中Blog1和Blog2结构体是等价的。
type Author struct {
Name string `gorm:"column:name"`
Email string `gorm:"column:email"`
}
// 使用gorm embed功能
type Blog1 struct {
ID int `gorm:"column:id"`
Author Author `gorm:"embedded";embeddedPrefix:author_`
Upvotes int32 `gorm:"column:upvotes"`
}
// 属性平铺
type Blog2 struct {
ID int `gorm:"column:id"`
Upvotes int32 `gorm:"column:upvotes"`
Name string `gorm:"column:author_name"`
Email string `gorm:"column:author_email"`
}3.2 查询
1、小知识:First、Take、Last与Find的区别?
四者都是用于查询数据的,它们的区别在于
- 前三个在找不到数据时会返回ErrRecordNotFound错误,而Find不会。
- First、Last会根据主键进行排序然后通过limit 1返回第一条记录,Find则是查询满足条件的所有记录,然后在代码层面映射第一条记录到结果对象中,相较前两者的性能较低。
var users []User
// First 查询第一条符合条件的记录,SQL 会自动加 LIMIT 1
db.Where("age > ?", 18).First(&user)
// SELECT * FROM users WHERE age > 18 ORDER BY id LIMIT 1;
// Find 查询所有符合条件的记录
db.Where("age > ?", 18).Find(&users)
// SELECT * FROM users WHERE age > 18;Find方法使用场景:
- 当查询条件为主键、唯一键且等值查询时使用Find。可以避免ErrRecordNotFound错误的额外判断。
- 当查询满足某条件的多个对象时使用Find,可以一次性查找出满足条件的所有记录。
First、Last、Take使用场景:
- 当查询条件是范围查询且只需要查询一条记录时使用First、Last、Take。这种场景Find会查询所有满足条件的记录,而这三个方法会设置Limit 1。因此,能查询到的数据越多,First等方法性能相较Find就越好。
2、小知识:对于查询条件较为简单的SQL语句,可以直接使用Find内联查询代替Find + Where。
// 下列两条查询SQL是等价的
db.Find(&user, "status = ? and update_time < ?", 1, time.Now())
db.Where("status = ? and update_time < ?", 1, time.Now()).Find(&user)3、小知识:在只需要查询表中某一列的场景中,可以使用Pluck来代替Select + Find。
var ages []int64
// 下列两条查询SQL是等价的
db.Model(&User{}).Pluck("age", &ages)
db.Model(&User{}).Select("age").Find(&ages)3.3 更新
1、小坑!:Update函数在更新记录时只会更新非零字段,因此对于属性中包含bool类型的记录需要小心。一旦遇到这种情况,应该使用Select + Update语句进行特定字段更新或者使用map[string]interface{} kv对结构进行更新。这个坑点几乎所有刚用gorm库的人都会踩上一脚,值得注意。
// 根据 `struct` 更新属性,只会更新非零值的字段
db.Model(&user).Updates(User{ID: 111, Name: "hello", Age: 18, Active: false})
// UPDATE users SET name='hello', age=18 WHERE id = 111;
db.Model(&user).Updates(map[string]interface{}{"id": 111, "name": "hello", "age": 18, "active": false})
// UPDATE users SET name='hello', age=18, active=false WHERE id=111;
db.Model(&user).Select("name", "age", "active").Updates(User{ID: 111, Name: "hello", Age: 18, Active: false})
// UPDATE users SET name='hello', age=18, active=false WHERE id=111;2、小知识:使用gorm时,全局删除和全局更新操作都是被禁止的。但是,gorm也留了后门给用户,在某些必要场景下若需要开启全局更新和全局删除则将配置中的AllowGlobalUpdate置为true即可。
mysqlDB := mysql.Open("root:xxxxxxxx@tcp(127.0.0.1:3306)/smallProgram?charset=utf8mb4&parseTime=True&loc=Local")
db, err := gorm.Open(mysqlDB, &gorm.Config{
AllowGlobalUpdate: true,
})3.4 其他功能
1、小知识:在某些情况下,没有可供随意蹂躏的测试环境进行测试。若直接调用gorm库生成的SQL语句又怕出错导致脏数据,此时如何检查gorm生成的SQL语句?gorm库提供了DryRun(试运行)配置,当该功能开启时gorm库的结尾方法只会打印SQL语句而不会真正的执行。这样开发者就可以在SQL执行前先核查SQL的正确性了,大大降低了出错的风险。特别是对于删除SQL,强烈建议开启软删除 + DryRun功能进行检查。
mysqlDB := mysql.Open("root:twk123456@tcp(127.0.0.1:3306)/smallProgram?charset=utf8mb4&parseTime=True&loc=Local")
db, err := gorm.Open(mysqlDB, &gorm.Config{
DryRun: true,
})04、gorm常见问题讨论
4.1 为什么使用gorm创建对象时,时间为什么时对时错?为什么会少了八小时?
通常在建立数据库连接时,DSN建议添加上loc=Local选项。要是不加上,等到插入数据时你就会发现!我在代码里打印日志明明生成的是当前时间,为什么存储到数据库中去就少了八个小时?
root:xxxxxxx@tcp(127.0.0.1:3306)/smallProgram?charset=utf8mb4&parseTime=True&loc=Local
实际上,不加loc=Local参数时,gorm默认数据库时区为UTC时间。但是代码调用time.Now()生成的时间是CST(北京时间),CST为UTC+8,即UTC时间往后推八小时。因此,gorm在处理时间属性时会减去偏移的时间(多出来的八小时)再发送给数据库,最终导致存储在数据库中的时间就少了八小时。
那为什么添加loc=Local参数就可以保证时间正确了呢?
添加loc参数后,当gorm解析到loc属性为Local时会去访问磁盘中/etc/localtime文件,从而知道当前系统是UTC+N。此时,gorm会视数据库时区为UTC+N时间,从而和time.Now()使用的时区一致。最终在处理时间属性时,偏移时间即为0,从而可以把时间属性原封不动的存储到数据库中展示。

gorm具体处理步骤如下(比较详细,选读):
1)建立连接时,会将DSN中的loc选项存储起来
func parseDSNParams(cfg *Config, params string) (err error) {
for _, v := range strings.Split(params, "&") {
key, value, found := strings.Cut(v, "=")
if !found {continue}
switch key{
case "loc":
// 存储设置的Loc属性,通常设置为Local
cfg.Loc, err = time.LoadLocation(value)
if err != nil {
return
}
......
}
}
}2)在处理time.Time类型属性时,会先将loc信息设置到该属性中。
// 设置loc属性为localLoc
func (t Time) In(loc *Location) Time {
if loc == nil {
panic("time: missing Location in call to Time.In")
}
t.setLoc(loc)
return t
}3)而loc属性的值localLoc又是如何知道当前系统在哪一时区的呢?localLoc属性会在第一次被获取时初始化,即从系统的/etc/localtime文件中解析并读取当前系统的时区信息。代码解析放在4)中
4)设置完成loc信息后,time.Time属性计算absSec(绝对秒)会发生变化。实际上就会变成UTC absSec + 偏移秒数。东八区偏移秒数即为28800 = 60*60*8。而Year、Month、Day都是从absSec衍生而来的,自然存储在数据库的格式化时间就变化了。
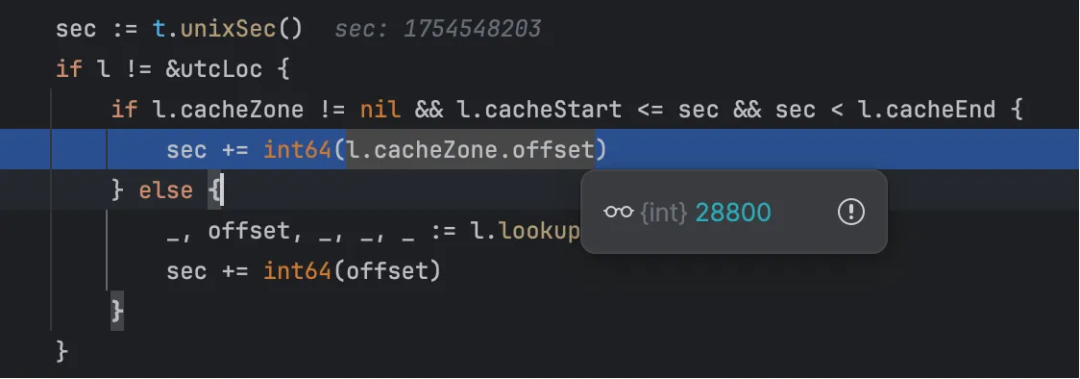
func (t Time) absSec() absSeconds {
l = t.loc
if l == nil || l == &localLoc{
l = l.get()
}
sec := t.unixSec()
if l != &utcLoc {
if l.cacheZone != nil && l.cacheStart <= sec && sec < l.cacheEnd {
// 一般情况,设置了CST时间后,会走这个分支添加偏移量
sec += int64(l.cacheZone.offset)
} else {
_, offset, _, _, _ := l.lookup(sec)
sec += int64(offset)
}
}
return absSeconds(sec + (unixToInternal + internalToAbsolute))
}
var Local *Location = &localLoc
var localLoc Location
// 初始化并返回time库固有的localLoc对象
func (l *Location) get() *Location {
if l == nil {
return &utcLoc
}
// 第一次获取localLoc进行初始化
if l == &localLoc {
localOnce.Do(initLocal)
}
return l
}
// 初始化localLoc对象,主要就是读取系统文件并解析出时区信息
func initLocal() {
tz, ok := syscall.Getenv("TZ")
switch {
case !ok:
// 读取系统的/etc/localtime文件并解析
z, err := loadLocation("localtime", []string{"/etc"})
if err == nil {
localLoc = *z
localLoc.name = "Local"
return
}
.......
}4.2 gorm中的软删除是如何实现的?为什么配置了软删除字段后Delete操作会变化?
首先,我们需要了解如何启动gorm的软删除?要启动软删除需要
- 在对应的数据库表中添加deleted_at属性列;
- 在表映射的go对象中添加DeleteAt字段并使用gorm提供的DeleteAt类型,完成上述两步之后即可开启gorm的软删除功能。
那为什么添加了该属性之后会导致Delete操作发送变化呢?gorm库在代码层面又是如何实现功能的切换呢?
在gorm的Delete函数中,如果没有启用软删除功能,那么进入到Delete函数时SQL语句是空的。此时会根据对应Where条件创建Delete语句,这时的Delete语句是会物理上删除数据库记录的。若开启了软删除功能,在解析表对应的go对象时gorm会感知到DeletedAt属性的存在,并向DeleteClauses添加对应的Clauses。这些Clauses会在Delete函数被遍历并添加到SQL语句中,而软删除字段类型实现了StatementModifier接口,因此在AddClause方法中可以提前修改并创建对应的SQL语句,从而在Delete方法中就可以绕过普通的Delete语句的拼接。此时Statement中保存的Delete SQL语句实际上是update语句,该语句会将满足条件记录的deleted_at属性更新为当前时间而不真正的删除记录。
func Delete(config *Config) func(db *gorm.DB) {
return func(db *gorm.DB){
// 开启软删除会走该分支,AddClause方法会填写SQL语句,导致删除实际为Update语句
if db.Statement.Schema != nil {
for _, c := range db.Statement.Schema.DeleteClauses {
db.Statement.AddClause(c)
}
}
// 未开启软删除走该分支,执行真正的Delete语句
if db.Statement.SQL.Len() == 0 {
......
db.Statement.Build(db.Statement.BuildClauses...)
}
if db.DryRun || db.Error != nil {return}
// 发送SQL语句至数据库允许并接收返回结果
result, err := db.Statement.ConnPool.ExecContext(db.Statement.Context, db.Statement.SQL.String(), db.Statement.Vars...)
......
}
}4.3 创建中的批量创建逻辑是怎么样的?和普通创建有什么不同?
在gorm初始化时,mysql驱动会就注册Create的钩子函数。实际上gorm提供的Create和CreateBatch底层都是mysql驱动的Create钩子函数。在该函数内会维护一个Values对象,其中包含了两个成员Columns []Column和Values [][]interface{}。前者会保存对象创建时需要设置的列(属性),后者则是一个二维数组。当调用的是gorm中的Create方法时,则只会填充Columns[0],若调用的是CreateBatch则会填充Column[0-(BatchSize - 1)]。最后Statement对象会根据Values对象生成对应的SQL语句进行执行。
type Values struct {
Columns []Column
Values [][]interface{}
}
func ConvertToCreateValues(stmt *gorm.Statement) (values clause.Values) {
......
// 设置Columns长度为数据库表属性个数
values = clause.Values{Columns: make([]clause.Column, 0, len(stmt.Schema.DBNames))}
switch stmt.ReflectValue.Kind() {
case reflect.Slice, reflect.Array:
// 设置批量对象的属性值
values.Values = make([][]interface{}, stmt.ReflectValue.Len())
for i := 0; i < stmt.ReflectValue.Len(); i++ {
// 读取批量对象中指定索引对应对象
rv := reflect.Indirect(stmt.ReflectValue.Index(i))
values.Value[i] = make([]interface{}, len(values.Columns))
// 遍历对象所有属性,将所有属性的值设置到第i个对象中
for idx, column := range values.Columns {
field := stmt.Schema.FieldsByDBName[column.Name]
values.Values[i][idx], _ = field.ValueOf(stmt,Context, rv)
}
}
case reflect.Struct:
// 设置单个对象的属性值
values.Values = [][]interface{}{make([]interface{}, len(values.Columns))}
for idx, column := range values.Columns {
field := stmt.Schema.FieldsByDBName[column.Name]
values.Values[0][idx], _ = field.ValueOf(stmt,Context, rv)
}
}
}4.4 gorm中的事务是如何处理的?
相信有不少同学和我之前一样,认为gorm中的事务就是将大量sql先维护在服务中,在事务执行提交时再统一发送到数据库中去执行。如果真是如此,如下面代码所示,那么gorm在启动事务后执行Select、Update语句怎么可以同步获取到处理结果呢?因此,这说明gorm对于事务的处理并不是上述描述的那样。实际上gorm是每执行一个命令函数就向数据库发送一条SQL,事务的功能是通过数据库保证的,gorm库并没有对应的逻辑实现事务。
当我们执行db.Begin()时,gorm库会帮我们发送“Start Transaction”这条SQL语句到数据库中执行,在我们执行相应的Select、Update命令时也会生成对应的SQL语句并发送到数据库中执行。最后,当我们执行tx.Commit()时,gorm库会发送“COMMIT”到数据库中执行,从而完成整个事务的运行。
tx := db.Begin()
err := tx.Select("name", "age").Where("id = ?", 1).Find(&user).Error
if err != nil {
return err
}
tx.Commit()
// 截取部分go-sql-driver/mysql库逻辑
func (mc *mysqlConn) begin(readOnly bool) (driver.Tx, error) {
if mc.closed.Load() {
return nil, driver.ErrBadConn
}
var q string
if readOnly {
q = "START TRANSACTION READ ONLY"
} else {
q = "START TRANSACTION"
}
err := mc.exec(q)
if err == nil {
return &mysqlTx{mc}, err
}
return nil, mc.markBadConn(err)
}4.5 gorm中的插入语句是如何判断主键和唯一键冲突的?
有时我们会使用如下语句来保证插入对象在发生主键或唯一键冲突时的更新策略,那么gorm库是如何感知是否发生冲突的呢?实际上gorm并不感知是否发生键冲突,感知的逻辑和按照具体策略更新的逻辑都是数据库实现的。gorm的任务只是替我们写SQL语句,实际上只是在SQL语句中添加了ON DUPLICATE KEY UPDATE xxxxx 表示键冲突更新策略。至于根据是否冲突执行插入还是更新操作,这是数据库的工作,gorm库并不关心。
ZoneGorm.WithContext(ctx).Clauses(clause.OnConflict{
UpdateAll: true,
}).CreateInBatches(&infos, 50).Error
// 生成的SQL语句
INSERT INTO new_direct_buy_shop_product_info (Field1, Field2, ...)
VALUES (?, ?), (?, ?), ...
ON DUPLICATE KEY UPDATE
id = id, Field1 = Field1, Field2 = Field24.6 DryRun功能是如何实现的?
DryRun中文意思为试运行,当把DryRun配置设置为True时,gorm库在执行final method时不会真正执行SQL语句,只会打印SQL语句。实际上对于gorm库中的所有final method,如:Select、Update等,其中的逻辑都是先构建SQL语句、然后调用数据库驱动的Exec方法执行SQL语句。DryRun置为true时,实际就是在这两步中间插入了Return。在构建完成SQL语句后Return,在外部方法打印SQL语句。这就是DryRun功能的实现逻辑。下面以gorm库的Create方法为例:
// Create create hook
func Create(config *Config) func(db *gorm.DB) {
return func(db *gorm.DB){
......
if db.Statement.SQL.Len() == 0 {
// SQL语句构建
db.Statement.Build(db.Statement.BuildClauses...)
}
// 判断是否开启试运行功能
isDryRun := !db.DryRun && db.Error == nil
if !isDryRun {
return
}
// 实际发送SQL到数据库执行的函数
rows, err := db.Statement.ConnPool.QueryContext(
db.Statement.Context, db.Statement.SQL.String(), db.Statement.Vars...,
)
......
}
}-End-
原创作者|唐伟科
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号