AIGC技术深度解析:生成式AI的革命性突破与产业应用实战
原创
AIGC技术深度解析:生成式AI的革命性突破与产业应用实战
原创
Jaxonic
发布于 2025-09-21 22:20:08
发布于 2025-09-21 22:20:08

🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
作为一名深耕AI领域多年的技术探索者,我见证了人工智能从规则驱动到数据驱动,再到如今生成式AI的华丽转身。AIGC(AI Generated Content)作为当前最炙手可热的技术浪潮,正在重新定义内容创作的边界。从GPT系列的文本生成到DALL-E的图像创作,从Stable Diffusion的艺术创新到Sora的视频革命,生成式AI正以前所未有的速度改变着我们的工作方式和创作模式。
在我的技术实践中,我深刻体会到AIGC不仅仅是一项技术突破,更是一场认知革命。它让机器具备了"创造力",能够理解人类的意图并生成符合预期的内容。这种能力的背后,是Transformer架构的深度优化、大规模预训练的数据积累,以及强化学习与人类反馈的精妙结合。作为技术从业者,我们需要深入理解其核心原理,掌握实际应用技巧,并思考如何在自己的业务场景中发挥AIGC的最大价值。
本文将从技术架构、核心算法、应用实践和未来趋势四个维度,全面解析AIGC技术的精髓。我将结合自己的项目经验,分享在文本生成、图像创作、代码辅助等场景下的实战心得,帮助读者构建完整的AIGC技术认知体系,为在这个AI原生时代的技术浪潮中乘风破浪做好准备。
1. AIGC技术概览与发展历程
1.1 什么是AIGC
AIGC(Artificial Intelligence Generated Content)是指利用人工智能技术自动生成内容的技术范式。与传统的PGC(专业生产内容)和UGC(用户生产内容)不同,AIGC通过深度学习模型理解和学习大量数据中的模式,从而能够创造出全新的、符合人类预期的内容。
# AIGC核心工作流程示例
class AIGCPipeline:
def __init__(self, model_type="text"):
self.model_type = model_type
self.tokenizer = None
self.model = None
def load_model(self, model_path):
"""加载预训练模型"""
if self.model_type == "text":
from transformers import GPT2LMHeadModel, GPT2Tokenizer
self.tokenizer = GPT2Tokenizer.from_pretrained(model_path)
self.model = GPT2LMHeadModel.from_pretrained(model_path)
elif self.model_type == "image":
from diffusers import StableDiffusionPipeline
self.model = StableDiffusionPipeline.from_pretrained(model_path)
def generate_content(self, prompt, max_length=100):
"""生成内容的核心方法"""
if self.model_type == "text":
# 文本生成流程
inputs = self.tokenizer.encode(prompt, return_tensors='pt')
outputs = self.model.generate(
inputs,
max_length=max_length,
temperature=0.8, # 控制创造性
do_sample=True, # 启用采样
pad_token_id=self.tokenizer.eos_token_id
)
return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
elif self.model_type == "image":
# 图像生成流程
image = self.model(prompt).images[0]
return image
# 使用示例
aigc = AIGCPipeline("text")
aigc.load_model("gpt2")
result = aigc.generate_content("人工智能的未来发展趋势是")
print(result)1.2 AIGC发展时间线
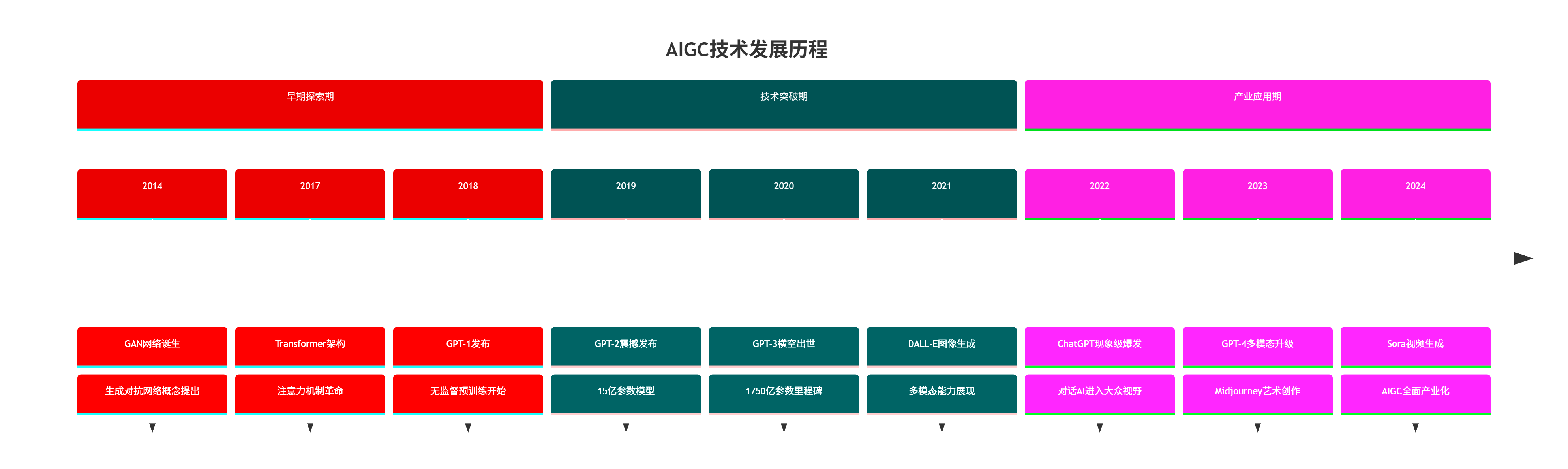
2. AIGC核心技术架构深度解析
2.1 Transformer架构:AIGC的技术基石
Transformer架构是现代AIGC技术的核心基础,其自注意力机制使模型能够并行处理序列数据,大大提升了训练效率和生成质量。
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
"""多头注意力机制实现"""
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""缩放点积注意力计算"""
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 应用掩码(用于防止未来信息泄露)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# Softmax归一化
attention_weights = torch.softmax(scores, dim=-1)
# 加权求和
output = torch.matmul(attention_weights, V)
return output, attention_weights
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 线性变换并重塑为多头形式
Q = self.W_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 计算注意力
attention_output, attention_weights = self.scaled_dot_product_attention(Q, K, V, mask)
# 重塑并通过输出层
attention_output = attention_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
output = self.W_o(attention_output)
return output, attention_weights
class TransformerBlock(nn.Module):
"""Transformer基础块"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# 前馈网络
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# 自注意力 + 残差连接
attn_output, _ = self.attention(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 前馈网络 + 残差连接
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x2.2 生成式模型的数学原理
AIGC的核心在于学习数据分布并从中采样生成新内容。以文本生成为例,模型需要学习条件概率分布:
$$P(xt|x_1, x_2, ..., x{t-1}) = \text{softmax}(W \cdot h_t + b)$$
其中 $h_t$ 是第t个时间步的隐藏状态,通过Transformer编码得到。
class GPTModel(nn.Module):
"""简化版GPT模型实现"""
def __init__(self, vocab_size, d_model, num_heads, num_layers, max_seq_len):
super(GPTModel, self).__init__()
self.d_model = d_model
self.max_seq_len = max_seq_len
# 词嵌入和位置编码
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.position_embedding = nn.Embedding(max_seq_len, d_model)
# Transformer层堆叠
self.transformer_blocks = nn.ModuleList([
TransformerBlock(d_model, num_heads, d_model * 4)
for _ in range(num_layers)
])
# 输出层
self.ln_f = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, vocab_size, bias=False)
def forward(self, input_ids):
seq_len = input_ids.size(1)
# 创建位置索引
position_ids = torch.arange(0, seq_len, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
# 嵌入层
token_embeddings = self.token_embedding(input_ids)
position_embeddings = self.position_embedding(position_ids)
x = token_embeddings + position_embeddings
# 创建因果掩码(防止看到未来信息)
mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0).unsqueeze(0)
# 通过Transformer层
for transformer in self.transformer_blocks:
x = transformer(x, mask)
# 最终输出
x = self.ln_f(x)
logits = self.head(x)
return logits
def generate(self, input_ids, max_new_tokens=50, temperature=1.0):
"""文本生成方法"""
self.eval()
with torch.no_grad():
for _ in range(max_new_tokens):
# 获取当前序列的logits
logits = self.forward(input_ids)
# 只关注最后一个token的预测
logits = logits[:, -1, :] / temperature
# 采样下一个token
probs = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
# 拼接到输入序列
input_ids = torch.cat([input_ids, next_token], dim=1)
# 防止序列过长
if input_ids.size(1) > self.max_seq_len:
input_ids = input_ids[:, -self.max_seq_len:]
return input_ids3. AIGC技术架构图谱
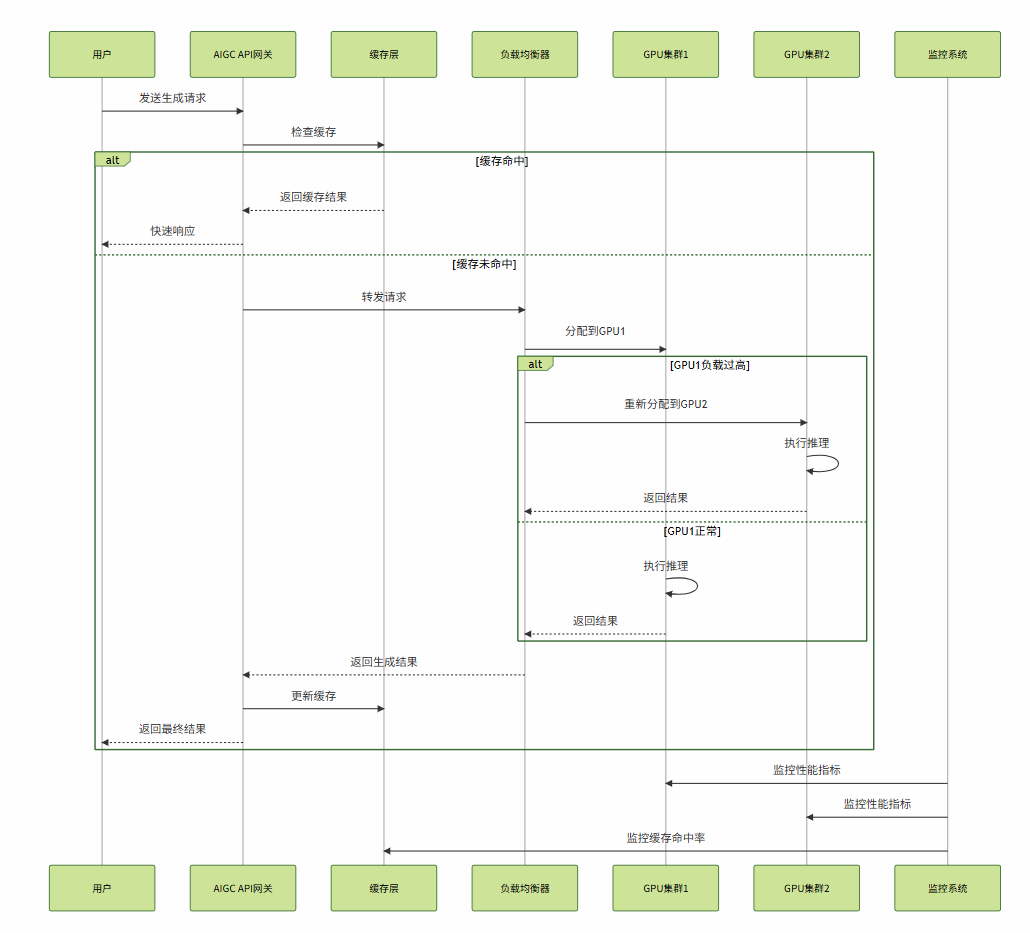
4. 主流AIGC模型对比分析
模型类别 | 代表模型 | 参数规模 | 主要能力 | 应用场景 | 技术特点 |
|---|---|---|---|---|---|
文本生成 | GPT-4 | 1.76T | 文本理解与生成 | 对话、写作、编程 | Transformer架构,RLHF训练 |
图像生成 | DALL-E 3 | 未公开 | 文本到图像 | 艺术创作、设计 | 扩散模型,CLIP引导 |
代码生成 | GitHub Copilot | 12B | 代码补全与生成 | 编程辅助 | 基于Codex,代码专用训练 |
多模态 | GPT-4V | 1.76T | 视觉理解与推理 | 图像分析、VQA | 视觉编码器+语言模型 |
视频生成 | Sora | 未公开 | 文本到视频 | 视频制作、动画 | 扩散Transformer,时空建模 |
5. AIGC实战应用场景
5.1 智能内容创作系统
class ContentCreationSystem:
"""智能内容创作系统"""
def __init__(self):
self.text_model = None
self.image_model = None
self.code_model = None
def setup_models(self):
"""初始化各类模型"""
# 文本生成模型
from transformers import pipeline
self.text_model = pipeline("text-generation",
model="gpt2-medium",
device=0 if torch.cuda.is_available() else -1)
# 图像生成模型
from diffusers import StableDiffusionPipeline
self.image_model = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5"
)
# 代码生成模型
self.code_model = pipeline("text-generation",
model="microsoft/CodeGPT-small-py")
def create_blog_post(self, topic, style="technical"):
"""自动生成博客文章"""
# 生成文章大纲
outline_prompt = f"为'{topic}'主题创建一个详细的技术博客大纲:"
outline = self.text_model(outline_prompt,
max_length=200,
temperature=0.7)[0]['generated_text']
# 生成文章内容
content_sections = []
sections = self._parse_outline(outline)
for section in sections:
section_prompt = f"详细阐述以下技术要点:{section}"
section_content = self.text_model(section_prompt,
max_length=500,
temperature=0.8)[0]['generated_text']
content_sections.append(section_content)
return {
"outline": outline,
"content": content_sections,
"word_count": sum(len(section.split()) for section in content_sections)
}
def generate_code_examples(self, description, language="python"):
"""生成代码示例"""
code_prompt = f"# {description}\n# Language: {language}\n"
generated_code = self.code_model(code_prompt,
max_length=150,
temperature=0.3)[0]['generated_text']
# 代码质量检查
quality_score = self._evaluate_code_quality(generated_code)
return {
"code": generated_code,
"language": language,
"quality_score": quality_score,
"suggestions": self._get_code_suggestions(generated_code)
}
def create_visual_content(self, text_description, style="realistic"):
"""生成配图"""
# 优化提示词
enhanced_prompt = f"{text_description}, {style} style, high quality, detailed"
# 生成图像
image = self.image_model(enhanced_prompt,
num_inference_steps=50,
guidance_scale=7.5).images[0]
return image
def _parse_outline(self, outline_text):
"""解析文章大纲"""
lines = outline_text.split('\n')
sections = [line.strip() for line in lines if line.strip() and
(line.startswith('##') or line.startswith('-'))]
return sections[:5] # 限制章节数量
def _evaluate_code_quality(self, code):
"""评估代码质量"""
quality_factors = {
'has_comments': '# ' in code or '"""' in code,
'proper_naming': any(c.islower() for c in code),
'no_syntax_errors': True, # 简化检查
'follows_pep8': '\n' in code and ' ' in code
}
return sum(quality_factors.values()) / len(quality_factors)
def _get_code_suggestions(self, code):
"""获取代码改进建议"""
suggestions = []
if '# ' not in code:
suggestions.append("添加注释提高代码可读性")
if 'def ' in code and 'return' not in code:
suggestions.append("考虑添加返回值")
return suggestions
# 使用示例
creator = ContentCreationSystem()
creator.setup_models()
# 创建技术博客
blog_result = creator.create_blog_post("深度学习优化技巧")
print(f"生成文章字数: {blog_result['word_count']}")
# 生成代码示例
code_result = creator.generate_code_examples("实现一个简单的神经网络")
print(f"代码质量评分: {code_result['quality_score']:.2f}")5.2 AIGC性能优化策略
%%{init: {'theme':'base', 'themeVariables': { 'primaryColor': '#2ed573', 'primaryTextColor': '#fff', 'primaryBorderColor': '#7bed9f', 'lineColor': '#5f27cd', 'secondaryColor': '#ff6348', 'tertiaryColor': '#ffa502'}}}%%
sequenceDiagram
participant U as 用户
participant API as AIGC API网关
participant Cache as 缓存层
participant LB as 负载均衡器
participant GPU1 as GPU集群1
participant GPU2 as GPU集群2
participant Monitor as 监控系统
U->>API: 发送生成请求
API->>Cache: 检查缓存
alt 缓存命中
Cache-->>API: 返回缓存结果
API-->>U: 快速响应
else 缓存未命中
API->>LB: 转发请求
LB->>GPU1: 分配到GPU1
alt GPU1负载过高
LB->>GPU2: 重新分配到GPU2
GPU2->>GPU2: 执行推理
GPU2-->>LB: 返回结果
else GPU1正常
GPU1->>GPU1: 执行推理
GPU1-->>LB: 返回结果
end
LB-->>API: 返回生成结果
API->>Cache: 更新缓存
API-->>U: 返回最终结果
end
Monitor->>GPU1: 监控性能指标
Monitor->>GPU2: 监控性能指标
Monitor->>Cache: 监控缓存命中率6. AIGC技术发展趋势与挑战
6.1 技术发展趋势分析
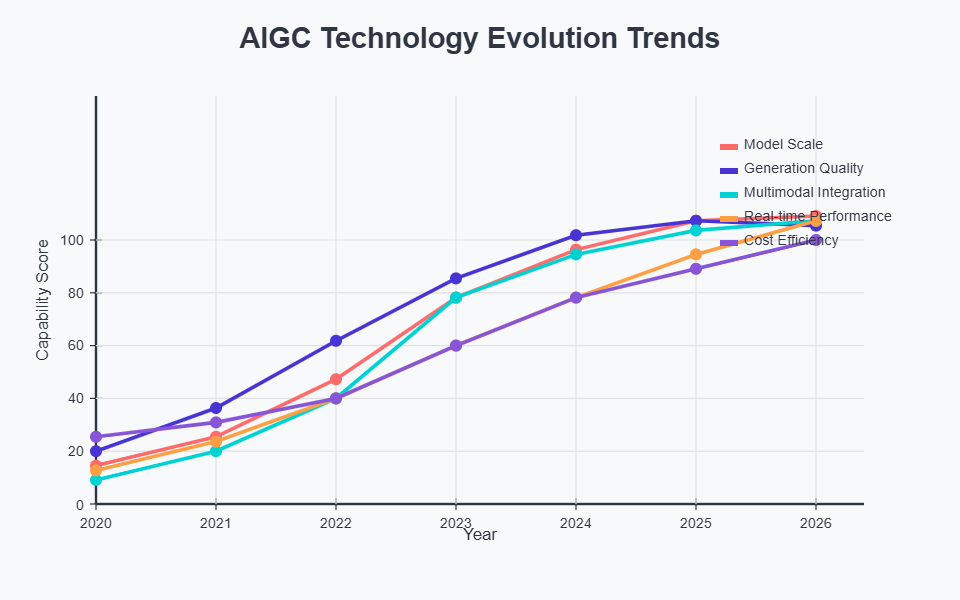
6.2 面临的技术挑战
"AIGC技术的发展不仅仅是模型规模的扩大,更重要的是如何在保证生成质量的同时,解决可控性、安全性和效率性的平衡问题。真正的突破在于让AI不仅能够生成内容,更能够理解和遵循人类的价值观与创作意图。" —— AI研究前沿观点
class AIGCChallengeAnalyzer:
"""AIGC技术挑战分析器"""
def __init__(self):
self.challenges = {
"hallucination": "幻觉问题",
"bias": "偏见与公平性",
"controllability": "可控性不足",
"efficiency": "计算效率",
"safety": "内容安全性",
"copyright": "版权争议"
}
def analyze_hallucination_mitigation(self):
"""分析幻觉问题缓解策略"""
strategies = {
"retrieval_augmented": {
"description": "检索增强生成",
"implementation": "结合外部知识库验证",
"effectiveness": 0.75
},
"uncertainty_estimation": {
"description": "不确定性估计",
"implementation": "输出置信度分数",
"effectiveness": 0.65
},
"multi_agent_verification": {
"description": "多智能体验证",
"implementation": "多个模型交叉验证",
"effectiveness": 0.80
}
}
return strategies
def bias_detection_framework(self, generated_content):
"""偏见检测框架"""
bias_indicators = {
"gender_bias": self._check_gender_bias(generated_content),
"racial_bias": self._check_racial_bias(generated_content),
"cultural_bias": self._check_cultural_bias(generated_content)
}
overall_bias_score = sum(bias_indicators.values()) / len(bias_indicators)
return {
"bias_score": overall_bias_score,
"detailed_analysis": bias_indicators,
"recommendations": self._get_bias_mitigation_suggestions(bias_indicators)
}
def _check_gender_bias(self, content):
"""检查性别偏见"""
# 简化的偏见检测逻辑
gender_terms = ["he", "she", "man", "woman", "male", "female"]
gender_count = sum(1 for term in gender_terms if term.lower() in content.lower())
return min(gender_count / 10, 1.0) # 归一化到0-1
def _check_racial_bias(self, content):
"""检查种族偏见"""
# 实际应用中需要更复杂的NLP分析
return 0.1 # 占位符
def _check_cultural_bias(self, content):
"""检查文化偏见"""
return 0.15 # 占位符
def _get_bias_mitigation_suggestions(self, bias_indicators):
"""获取偏见缓解建议"""
suggestions = []
if bias_indicators["gender_bias"] > 0.5:
suggestions.append("使用性别中性语言")
if bias_indicators["racial_bias"] > 0.3:
suggestions.append("增加多元化训练数据")
return suggestions
# 使用示例
analyzer = AIGCChallengeAnalyzer()
strategies = analyzer.analyze_hallucination_mitigation()
print("幻觉缓解策略:", strategies)7. AIGC产业应用前景展望
7.1 行业应用分布
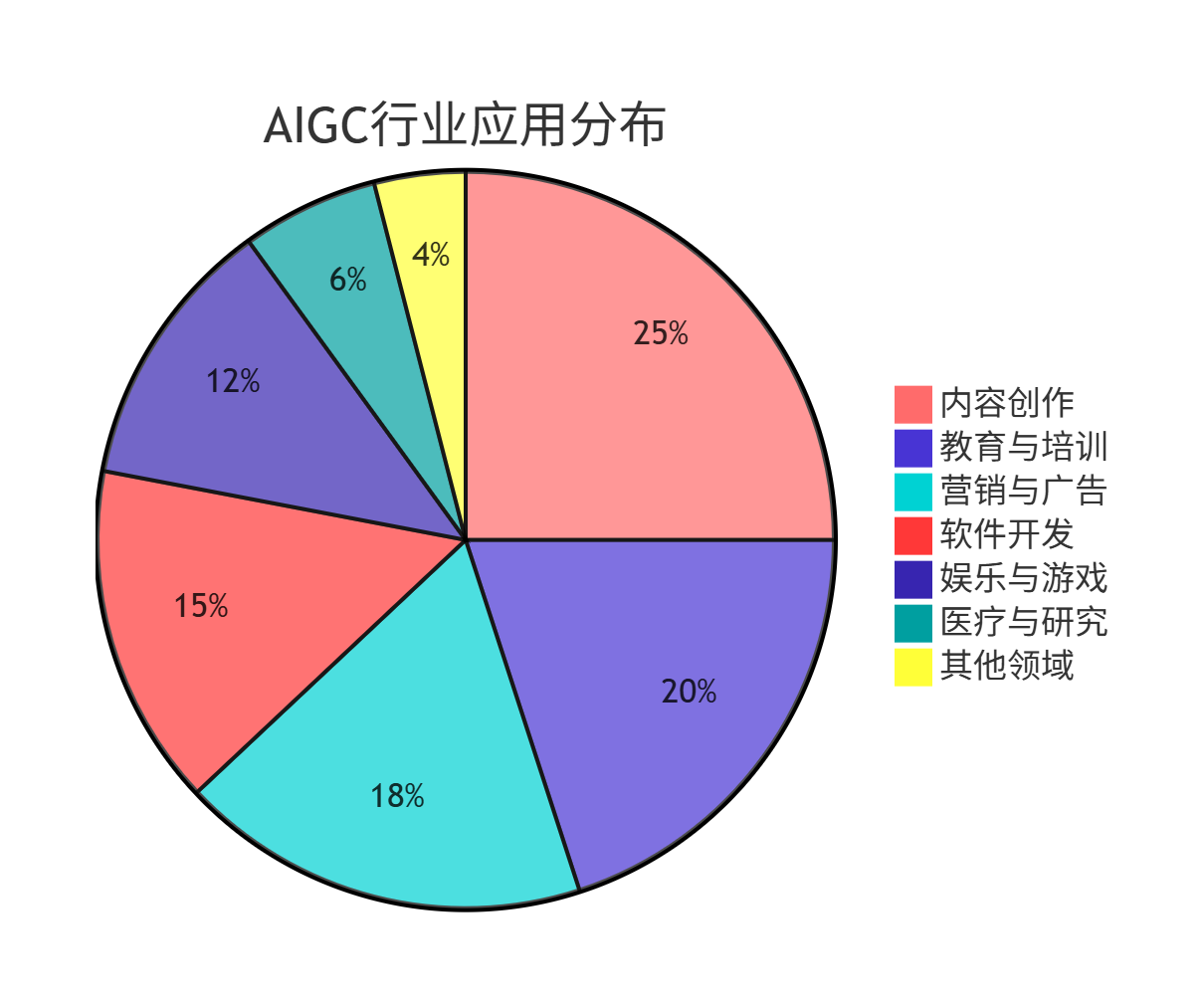
7.2 未来发展路线图
8. AIGC实践建议与最佳实践
8.1 模型选择与部署策略
class AIGCDeploymentOptimizer:
"""AIGC部署优化器"""
def __init__(self):
self.deployment_configs = {}
self.performance_metrics = {}
def recommend_deployment_strategy(self, use_case, constraints):
"""推荐部署策略"""
strategies = {
"high_throughput": {
"model_size": "large",
"batch_processing": True,
"gpu_memory": ">=24GB",
"latency_tolerance": "high"
},
"low_latency": {
"model_size": "medium",
"batch_processing": False,
"gpu_memory": ">=8GB",
"latency_tolerance": "low"
},
"cost_optimized": {
"model_size": "small",
"batch_processing": True,
"gpu_memory": ">=4GB",
"latency_tolerance": "medium"
}
}
# 根据约束条件选择最佳策略
best_strategy = self._select_optimal_strategy(use_case, constraints, strategies)
return best_strategy
def optimize_inference_pipeline(self, model_config):
"""优化推理管道"""
optimizations = []
# 模型量化
if model_config.get("enable_quantization", False):
optimizations.append({
"type": "quantization",
"method": "int8",
"speedup": 2.0,
"memory_reduction": 0.5
})
# 动态批处理
if model_config.get("dynamic_batching", False):
optimizations.append({
"type": "dynamic_batching",
"max_batch_size": 32,
"throughput_improvement": 3.0
})
# KV缓存优化
optimizations.append({
"type": "kv_cache",
"cache_size": "auto",
"memory_efficiency": 0.3
})
return optimizations
def monitor_performance(self, deployment_id):
"""性能监控"""
metrics = {
"latency_p95": self._measure_latency_p95(deployment_id),
"throughput_qps": self._measure_throughput(deployment_id),
"gpu_utilization": self._measure_gpu_usage(deployment_id),
"memory_usage": self._measure_memory_usage(deployment_id),
"error_rate": self._measure_error_rate(deployment_id)
}
# 性能告警
alerts = self._check_performance_alerts(metrics)
return {
"metrics": metrics,
"alerts": alerts,
"recommendations": self._get_optimization_recommendations(metrics)
}
def _select_optimal_strategy(self, use_case, constraints, strategies):
"""选择最优策略"""
# 简化的策略选择逻辑
if constraints.get("budget") == "low":
return strategies["cost_optimized"]
elif constraints.get("latency_requirement") == "strict":
return strategies["low_latency"]
else:
return strategies["high_throughput"]
def _measure_latency_p95(self, deployment_id):
"""测量P95延迟"""
return 150 # ms,示例值
def _measure_throughput(self, deployment_id):
"""测量吞吐量"""
return 50 # QPS,示例值
def _measure_gpu_usage(self, deployment_id):
"""测量GPU使用率"""
return 0.75 # 75%,示例值
def _measure_memory_usage(self, deployment_id):
"""测量内存使用"""
return 0.60 # 60%,示例值
def _measure_error_rate(self, deployment_id):
"""测量错误率"""
return 0.01 # 1%,示例值
def _check_performance_alerts(self, metrics):
"""检查性能告警"""
alerts = []
if metrics["latency_p95"] > 200:
alerts.append("高延迟告警")
if metrics["gpu_utilization"] > 0.9:
alerts.append("GPU使用率过高")
return alerts
def _get_optimization_recommendations(self, metrics):
"""获取优化建议"""
recommendations = []
if metrics["gpu_utilization"] < 0.5:
recommendations.append("考虑增加批处理大小")
if metrics["latency_p95"] > 100:
recommendations.append("启用模型量化或使用更小模型")
return recommendations
# 使用示例
optimizer = AIGCDeploymentOptimizer()
strategy = optimizer.recommend_deployment_strategy(
use_case="content_generation",
constraints={"budget": "medium", "latency_requirement": "normal"}
)
print("推荐部署策略:", strategy)总结
作为一名在AI领域深耕多年的技术实践者,我深刻感受到AIGC技术带来的革命性变化。从最初的规则驱动系统到如今的生成式AI,我们见证了人工智能从"理解"到"创造"的华丽蜕变。AIGC不仅仅是技术的进步,更是人机协作模式的重新定义。
在我的实际项目经验中,AIGC技术的应用已经从实验室走向了生产环境。无论是智能客服系统中的对话生成,还是内容平台的自动化创作,AIGC都展现出了惊人的潜力。但同时,我也深刻认识到技术应用中面临的挑战:如何确保生成内容的准确性、如何处理模型的偏见问题、如何在效率与质量之间找到平衡点。
通过本文的深入分析,我们可以看到AIGC技术的核心在于Transformer架构的不断优化和大规模预训练的数据积累。从GPT系列的文本生成到Stable Diffusion的图像创作,从GitHub Copilot的代码辅助到Sora的视频生成,每一次技术突破都在推动着AIGC应用边界的扩展。
展望未来,我认为AIGC技术将朝着更加智能化、个性化和可控化的方向发展。多模态融合将成为主流趋势,实时交互能力将得到显著提升,而成本效率的优化将使AIGC技术更加普及。作为技术从业者,我们需要保持对新技术的敏感度,同时也要关注技术伦理和社会责任。
在这个AI原生的时代,掌握AIGC技术不仅是技术能力的体现,更是适应未来工作模式的必备技能。让我们携手在这个充满无限可能的技术领域中,用代码和创意共同书写属于我们这个时代的技术传奇。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- Attention Is All You Need - Transformer原论文
- GPT-4 Technical Report - OpenAI官方技术报告
- Stable Diffusion - 开源图像生成模型
- AIGC技术发展白皮书 - 中国信通院
- Hugging Face Transformers - 开源模型库
关键词标签
#AIGC #生成式AI #Transformer #深度学习 #人工智能
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号