九、HQL DQL七大查询子句

九、HQL DQL七大查询子句

IvanCodes
发布于 2025-09-28 11:41:56
发布于 2025-09-28 11:41:56
Apache Hive 的强大之处在于其类 SQL 的查询语言 HQL,它使得熟悉 SQL 的用户能够轻松地对存储在大规模分布式系统(如 HDFS)中的数据进行复杂的查询和分析。一个典型且完整的 HQL 查询语句,通常由一系列有序的子句构成。理解并熟练运用这些核心子句,是高效进行数据探索和提取的基础。我们这次重点剖析 HQL 中最常用也最核心的七个查询子句及其执行顺序。
在这里插入图片描述
在这里插入图片描述
Hive HQL 七大查询子句及其执行顺序概述
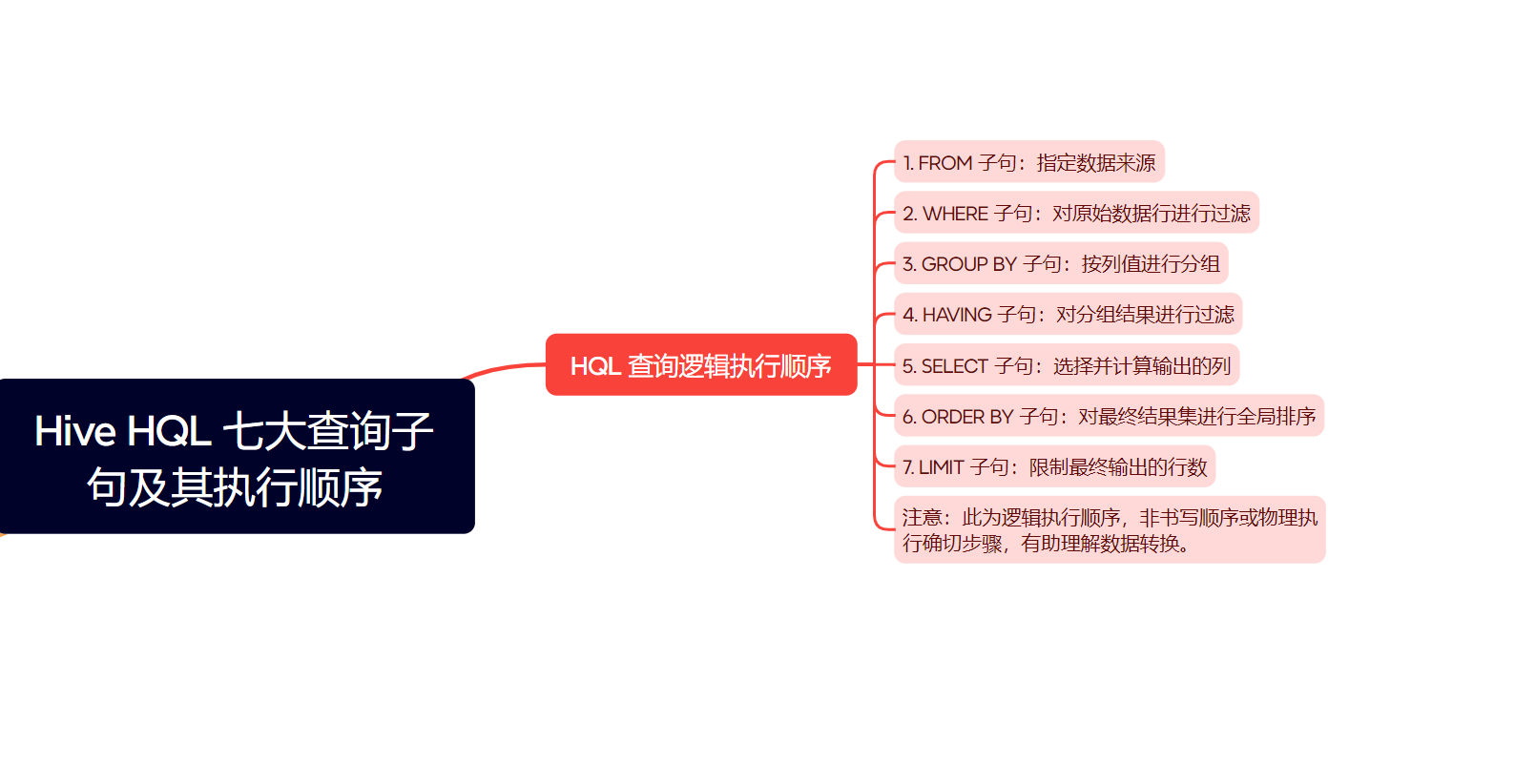
一个完整的 HQL 查询语句,其逻辑上的执行顺序(注意:这不完全等同于SQL 语句的书写顺序,也不代表 Hive 引擎物理执行的确切步骤,但有助于理解数据如何被逐步筛选和转换)通常如下:
FROM子句:指定数据来源的表或视图。WHERE子句:对FROM子句中产生的原始数据行进行过滤。GROUP BY子句:将经过WHERE过滤后的数据行,按照一个或多个列的值进行分组。HAVING子句:对GROUP BY子句产生的分组结果进行过滤。SELECT子句:选择并计算最终要输出的列。ORDER BY子句:对SELECT子句产生的最终结果集进行全局排序。LIMIT子句:限制ORDER BY排序后(或未排序时)最终输出的行数。
接下来,我们将逐一详细解析这些子句。
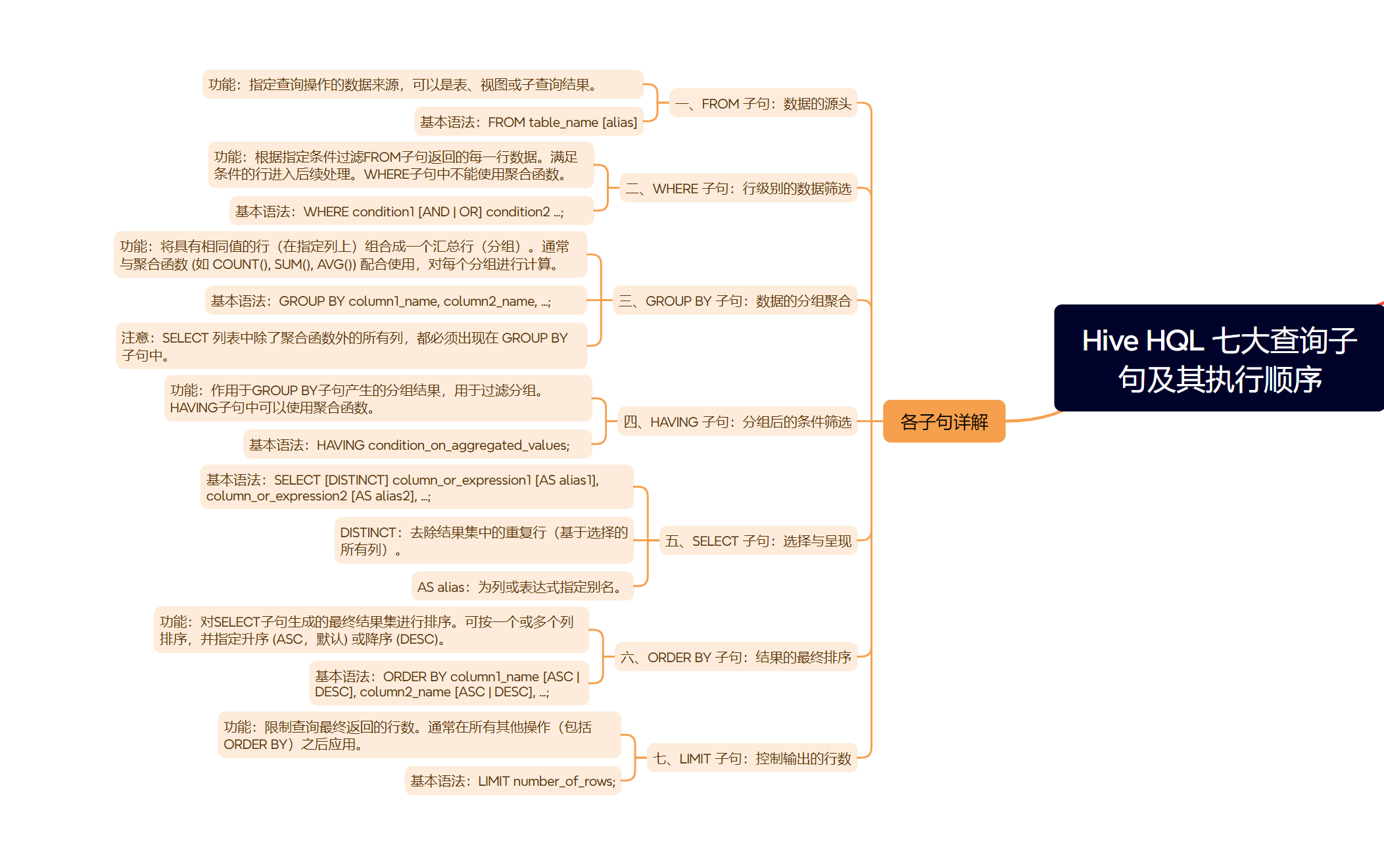
一、FROM 子句:数据的源头
功能:指定查询操作的数据来源。可以是一个表,或者是一个子查询的结果(尽管我们这次练习题会尽量避免复杂子查询)。 基本语法:
FROM table_name [alias]案例:
-- 从单个表查询所有列
SELECT * FROM employees;
-- 从单个表查询,并给表起别名
SELECT e.name FROM employees e;二、WHERE 子句:行级别的数据筛选
功能:根据指定的条件过滤 FROM 子句返回的每一行数据。只有满足条件的行才会进入后续的处理阶段。WHERE 子句中不能使用聚合函数。
基本语法:
WHERE condition1 [AND | OR] condition2 ...;案例:查询部门为 ‘Sales’ 或 ‘Marketing’ 的员工
SELECT name, department
FROM employees
WHERE department = 'Sales' OR department = 'Marketing';案例:查询薪水在 50000 到 70000 之间(包含边界)的员工
SELECT name, salary
FROM employees
WHERE salary >= 50000 AND salary <= 70000;
-- 或者使用 BETWEEN
-- WHERE salary BETWEEN 50000 AND 70000;三、GROUP BY 子句:数据的分组聚合
功能:将具有相同值的行(在指定的列上)组合成一个汇总行(一个分组)。通常与聚合函数(如 COUNT(), SUM(), AVG(), MAX(), MIN())配合使用,对每个分组进行计算。
基本语法:
GROUP BY column1_name, column2_name, ...;案例:统计每个部门的员工数量
SELECT department, COUNT(*) AS num_employees
FROM employees
GROUP BY department;注意:SELECT 列表中除了聚合函数外的所有列,都必须出现在 GROUP BY 子句中。
四、HAVING 子句:分组后的条件筛选
功能:与 WHERE 子句类似,但 HAVING 作用于 GROUP BY 子句产生的分组结果。它用于过滤分组,只有满足 HAVING 条件的分组才会被保留。HAVING 子句中可以使用聚合函数。
基本语法:
HAVING condition_on_aggregated_values;案例:找出员工数量超过10人的部门
SELECT department, COUNT(*) AS num_employees
FROM employees
GROUP BY department
HAVING COUNT(*) > 10;总结:WHERE 先过滤行,再 GROUP BY 分组;HAVING 后过滤分组。
五、SELECT 子句:选择与呈现
功能:指定最终查询结果中包含哪些列。可以直接选择表中的列,也可以使用表达式、函数(包括聚合函数)来计算新的列。SELECT 子句在逻辑上是在 FROM, WHERE, GROUP BY, HAVING 之后执行的。
基本语法:
SELECT [DISTINCT] column_or_expression1 [AS alias1], column_or_expression2 [AS alias2], ...;DISTINCT: 去除结果集中的重复行(基于选择的所有列)。AS alias: 为列或表达式指定别名。 案例:查询员工姓名,并将薪水乘以1.1作为“预期薪水”显示
SELECT
name,
salary,
salary * 1.1 AS expected_salary
FROM employees;案例:查询所有不同的部门名称
SELECT DISTINCT department
FROM employees;六、ORDER BY 子句:结果的最终排序
功能:对 SELECT 子句生成的最终结果集进行排序。可以按一个或多个列排序,并指定升序 (ASC,默认) 或降序 (DESC)。ORDER BY 通常是查询中资源消耗较大的操作之一,因为它需要对所有结果数据进行全局排序。
基本语法:
ORDER BY column1_name [ASC | DESC], column2_name [ASC | DESC], ...;案例:查询所有员工,按入职日期 (hire_date) 从新到旧排列
SELECT name, hire_date
FROM employees
ORDER BY hire_date DESC;七、LIMIT 子句:控制输出的行数
功能:限制查询最终返回的行数。它通常在所有其他操作(包括 ORDER BY)之后应用。
基本语法:
LIMIT number_of_rows;案例:查询薪水最低的3名员工的信息
SELECT name, salary, department
FROM employees
ORDER BY salary ASC
LIMIT 3;结语:七子句的协同与威力
HQL 的这七个核心查询子句,通过不同的组合和嵌套,构成了数据查询和分析的强大能力。理解每个子句的功能及其大致的执行顺序,是编写高效、准确的 HQL 查询的前提。虽然 Hive 底层会通过 MapReduce 或 Tez 对查询进行优化,但清晰的逻辑结构和合理的子句使用,仍然是提升查询性能和可读性的关键。
练习题
假设我们有一个名为 products 的表,其结构如下:
products 表:
product_id INT(产品ID)product_name STRING(产品名称)category STRING(产品类别, 例如: ‘Electronics’, ‘Books’, ‘Clothing’, ‘Home Goods’)price DECIMAL(10,2)(价格)stock_quantity INT(库存数量)release_date DATE(发布日期)
- 题目一:
FROM和SELECT的基本使用 要求:从products表中查询所有产品的产品名称 (product_name) 和价格 (price)。 - 题目二:
WHERE子句筛选 要求:查询products表中所有类别为 ‘Books’ 且价格低于 20.00 的产品信息(所有列)。 - 题目三:
GROUP BY与聚合函数 要求:查询products表,统计每个产品类别 (category) 下有多少种不同的产品(即产品数量num_products)以及这些产品的平均价格 (avg_price)。 - 题目四:
HAVING子句过滤分组结果 要求:基于上一题的结果,只显示那些产品数量超过 5 种,并且平均价格高于 50.00 的产品类别及其统计信息。 - 题目五:
ORDER BY排序输出 要求:查询products表中所有库存数量 (stock_quantity) 大于 0 的产品,按其发布日期 (release_date) 从最新到最旧排序,如果发布日期相同,则按产品名称 (product_name) 字母顺序升序排序。显示产品名称、发布日期和库存数量。 - 题目六:
LIMIT限制结果数量 要求:查询products表中价格最高的前5款产品。显示产品名称和价格。 - 题目七:综合运用所有七个子句(尽可能)
要求:从
products表中找出类别为 ‘Electronics’ 或 ‘Home Goods’,且库存数量 (stock_quantity) 少于 10 件的产品。然后,按类别分组,计算每个类别下这类产品的平均价格。只显示那些平均价格大于 100.00 的类别。最后,将结果按平均价格降序排列,只取排名第一的类别信息(类别名称和平均价格)。
练习题答案
- 题目一答案:
SELECT product_name, price
FROM products;- 题目二答案:
SELECT *
FROM products
WHERE category = 'Books' AND price < 20.00;- 题目三答案:
SELECT category, COUNT(product_id) AS num_products, AVG(price) AS avg_price
FROM products
GROUP BY category;- 题目四答案:
SELECT category, COUNT(product_id) AS num_products, AVG(price) AS avg_price
FROM products
GROUP BY category
HAVING COUNT(product_id) > 5 AND AVG(price) > 50.00;- 题目五答案:
SELECT product_name, release_date, stock_quantity
FROM products
WHERE stock_quantity > 0
ORDER BY release_date DESC, product_name ASC;- 题目六答案:
SELECT product_name, price
FROM products
ORDER BY price DESC
LIMIT 5;- 题目七答案:
SELECT
category,
AVG(price) AS avg_category_price
FROM
products
WHERE
(category = 'Electronics' OR category = 'Home Goods') AND stock_quantity < 10
GROUP BY
category
HAVING
AVG(price) > 100.00
ORDER BY
avg_category_price DESC
LIMIT 1;本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-05-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号