面向API开发者的智能聊天机器人解析

面向API开发者的智能聊天机器人解析

用户11867067
发布于 2025-10-10 18:15:07
发布于 2025-10-10 18:15:07
一、技术背景:从工具到生态的演进
智能聊天机器人的规模化落地,依赖于大模型 API 生态 + 云基础设施的双重成熟:
OpenAI API 的技术突破:相较于早期的规则式机器人(需手动编写所有对话逻辑),OpenAI 的 API 提供了 “通用对话能力”—— 基于 GPT 系列预训练模型,支持零样本 / 少样本学习,无需针对每个场景单独训练,大幅降低开发门槛。
云雾平台的技术支撑:作为国内合规的云服务平台,其核心优势在于:
低延迟接入:通过国内节点部署,API 调用延迟控制在 100-300ms,满足实时对话需求;
高可用性:采用多区域容灾备份、负载均衡架构,服务可用性达 99.9%,避免单点故障;
合规适配:符合《生成式人工智能服务管理暂行办法》,内置内容安全过滤机制,降低业务风险。
二、核心原理:NLP 技术栈与平台协同逻辑
智能聊天机器人的核心是 “理解 - 生成” 的闭环,其技术栈可拆解为三层:

预训练模型工作流:GPT-3 采用 “无监督预训练 + 有监督微调” 模式 —— 预训练阶段学习通用语言规律,微调阶段适配对话场景,确保回复的连贯性与相关性;
API 参数优化:代码中engine="davinci"选择的是 GPT-3 系列中能力最强的模型(适用于复杂对话),若需平衡成本与效率,可选用curie(速度快 3 倍,成本低 10 倍);max_tokens=150需根据场景调整(如客服场景设 200-300,避免回复不完整)。
三、代码实现:工程化优化与错误处理
原示例代码为基础版本,工程化场景下需补充错误处理、参数配置、日志记录等模块,以下为优化后的代码:
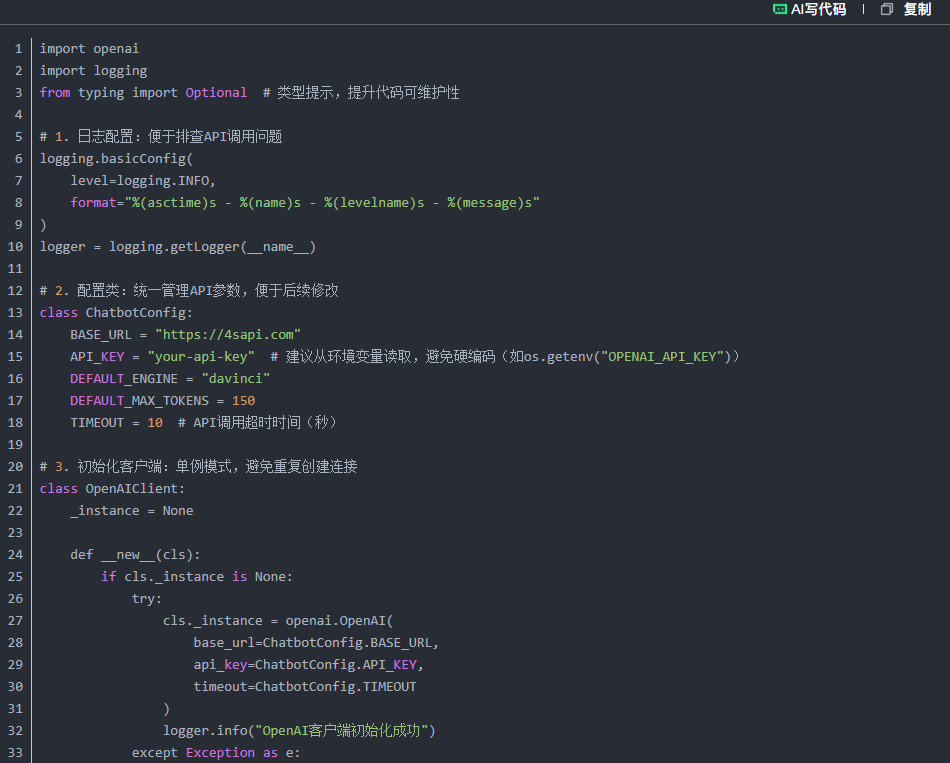
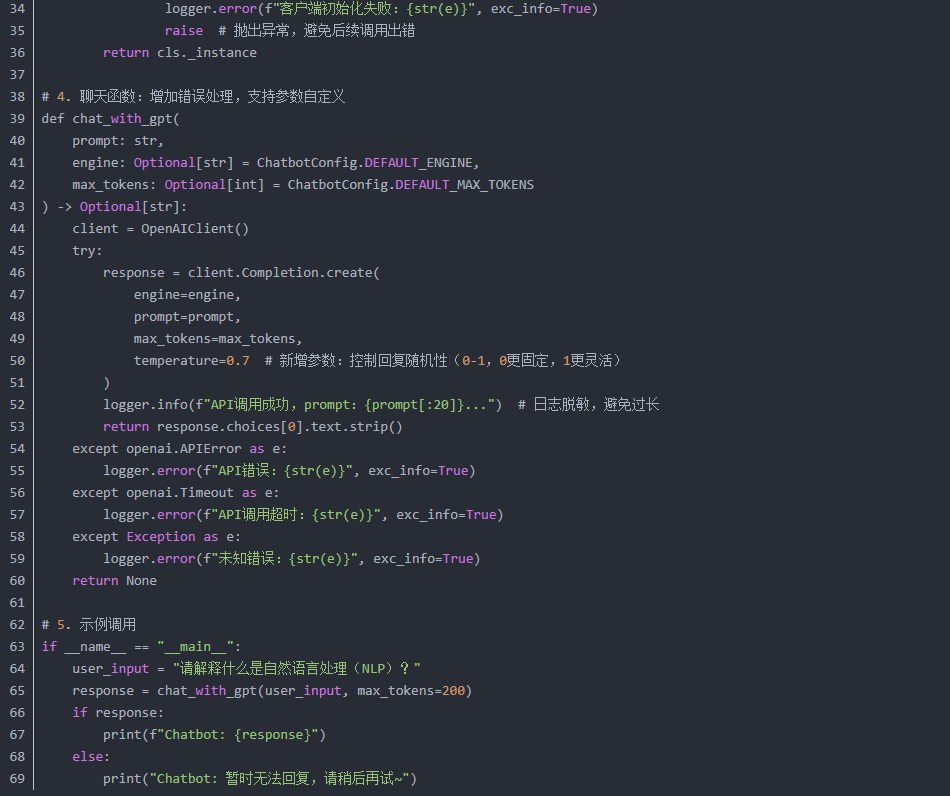
四、代码解析:工程化设计思路
配置解耦:通过ChatbotConfig类管理参数,后续修改base_url或max_tokens时,无需改动业务逻辑;
单例客户端:OpenAIClient采用单例模式,避免重复创建 HTTP 连接,减少资源消耗;
错误兜底:捕获APIError(模型服务错误)、Timeout(网络超时)等异常,返回友好提示,提升用户体验;
日志监控:记录关键操作(如客户端初始化、API 调用),便于线上问题排查。
五、实践建议:技术与合规双维度优化
性能优化:
批量调用:若需处理多用户请求,可使用batch接口(云雾平台支持),降低调用频次;
缓存策略:对高频重复问题(如 “客服工作时间”),缓存回复结果,减少 API 调用成本。
合规与隐私:
数据脱敏:用户输入中的手机号、身份证号等敏感信息,需先脱敏(如替换为 “*”)再传入 API;
内容审核:利用云雾平台内置的内容安全接口,对机器人回复进行二次审核,避免违规内容。
功能扩展:
多轮对话:通过context参数传递历史对话记录(如prompt = f"历史对话:{history}\n用户新问题:{user_input}"),实现连续对话;
多模态集成:结合语音转文字(ASR)、文字转语音(TTS)接口,实现 “语音聊天机器人”。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号